




sklearn.metrics
上篇文章本小白学习了混淆矩阵、ROC曲线和AUC面积,就迫不及待想看看sklearn实现的方法,sklearn官网打开,来几个比较常用的方法小试身手。
accuracy_score
分类准确率分数是指分类正确的样本数占总样本总数的比例
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
normalize:默认为true,返回正确分类的比例,如果是false,返回正确分类的数目
>>> import numpy as np
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
2
confusion_matrix
先看个混淆矩阵的例子
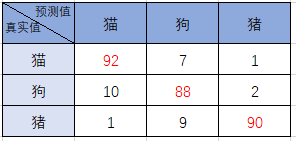
(1)猫预测成猫的有92个,猫预测正狗的有7个,猫预测成猪的有1个
(2)狗预测成猫的有10个,狗预测正狗的有88个,狗预测成猪的有2个
(3)猪预测成猫的有1个,猪预测正狗的有9个,猪预测成猪的有90个
可以看出来对角线上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









