







 本文介绍SparkStreaming,一种高吞吐、容错的实时流数据处理框架,支持多种数据源,如Kafka、Twitter等,通过批处理机制处理实时流数据,提供丰富的DStream操作,包括普通转换、窗口转换和输出操作。
本文介绍SparkStreaming,一种高吞吐、容错的实时流数据处理框架,支持多种数据源,如Kafka、Twitter等,通过批处理机制处理实时流数据,提供丰富的DStream操作,包括普通转换、窗口转换和输出操作。
1、Spark Streaming是一个流处理框架。可以实现高吞吐的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk,Flume,Twitter,ZeroMQ,Kinesis,以及TCP sockets,从数据源获取数据之后,可以使用函数(map、reduce、join和window等)进行复杂算法的处理,最后还可以将处理的结果存储到文件系统中(HDFS)
2、Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
3、对应的批数据,在Spark内核对应一个RDD实例,因此对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。
以Spark Streaming官方提供的WordCount代码为例:
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]): Unit = {
//local[2] 表示在本地启动两个工作线程
val conf = new SparkConf().setMaster("local[2]").setAppName("WordCount")
//Seconds(2) 将每两秒收集的数据当成一批
val ssc = new StreamingContext(conf,Seconds(2))
//要接收流数据的地址和端口号,以及设置内存+磁盘,序列化
val lines = ssc.socketTextStream("192.168.119.136",9999,StorageLevel.MEMORY_AND_DISK_SER)
//对数据进行处理,求出每个单词的count
val rel = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//在控制台打印
rel.print()
//之前的步骤只是创建了流程,程序并没有真正连上数据源,当ssc.start()启动后程序才真正进行所有预期操作
ssc.start()
//调用awaitTermination(),driver将阻塞在这里,直到流式应用意外退出
ssc.awaitTermination()
}
}
-启动后,在服务器中(192.168.119.136)开始传送数据
#nc -l 9999
Spark Streaming DStream
DStream(Discretized Stream)作为Spark Streaming的基础抽象,DStream由一组时间序列上连续的RDD来表示。每个RDD都包含自己特定时间间隔内的数据流。
DStream的操作
与RDD类似,DStream也提供了自己的一系列操作方法,这些操作可以分成三类:普通的转换操作、窗口转换操作和输出操作
1、普通的转换操作
map、flatMap、filter、union、reduce、reduceByKey、join、cogroup
repartition(numPartitions:Int) :通过输入的参数numPartitions的值来改变DStream的分区大小
count() :对源DStream内部的所含有的RDD元素数量进行计数,返回一个内部的RDD只包含一个元素的DStream
countByValue():计算DSStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次
transform(func) :通过对源DStrem的每个RDD应用RDD-to-RDD函数,返回一个新的DStream,这可以用来在DStream做任意RDD操作
updateStateByKey(func):返回一个新状态的DStream,其中每个键的状态是根据前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。
2、窗口转换操作
window(windowLength,slideInterval):返回一个基于源DStream的窗口批次计算后得到的新的DStream。
countByWindow(windowLength,slideInterval):返回基于滑动窗口的DStream中的元素的数量
reduceWindow(func,windowLength,slideInterval):基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream
reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]):基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream
countByValueAndWindow(windowLength,slideInterval, [numTasks]):基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。
3、输出操作
print():在Driver中打印出DStream中的前10个元素
saveAsTtextFiles(prefix,[suffix]):将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名
saveAsObjectFiles(prefix,[suffix]):将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名
saveAsHadoopFiles(prefix, [suffix]):将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名
foreachRDD(func):最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的
案例:
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DStreamTest {
def main(args: Array[String]): Unit = {
//local[2] 表示在本地启动两个工作线程
val conf = new SparkConf().setMaster("local[2]").setAppName("DStreamTest")
//Seconds(3) 将每两秒收集的数据当成一批
val ssc = new StreamingContext(conf,Seconds(3))
//要接收流数据的地址和端口号,以及设置内存+磁盘,序列化
val lines = ssc.socketTextStream(args(0),args(1).toInt,StorageLevel.MEMORY_AND_DISK_SER)
//输出日志文件
ssc.checkpoint(args(2))
//对数据进行处理,求出每个单词的count
val rel = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//输出信息保存路径
rel.saveAsTextFiles(args(3))
//在控制台打印
rel.print()
//之前的步骤只是创建了流程,程序并没有真正连上数据源,当ssc.start()启动后程序才真正进行所有预期操作
ssc.start()
//调用awaitTermination(),driver将阻塞在这里,直到流式应用意外退出
ssc.awaitTermination()
}
}
从IDEA上打成jar包放在服务器上运行
File->Project Structuer->Artifacts-> + ->Jar->Empty->-设置jar包名称->双击SparkTest(项目名)将其移至左侧->Apply->在Main Class:设置主类->OK
其次Build->Build Artcfacts->rebuild
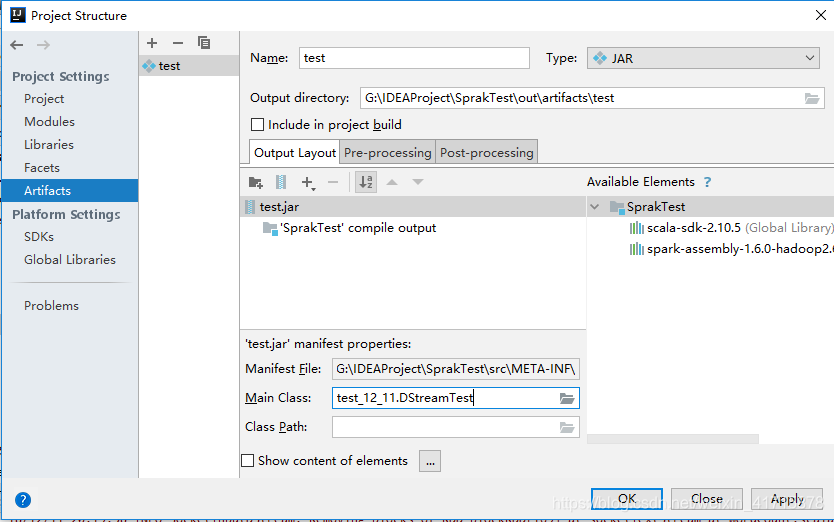
在项目目录找到jar包,导入服务器
//创建目录
# mkdir -p test/data test/check
//在一台服务器中运行
# spark-submit test.jar 0.0.0.0 9999 file:///root/test/check/ file:///root/test/data/
//另开一个窗口来输出信息
# nc -l 0.0.0.0 9999
//如果要取消运行
#ps ef | grep 9999 根据端口号找到该进程
#kill -9 进程号

















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









