










 本文介绍了两种字符串查询方法:哈希表法和前缀树。哈希表法虽然实现简单,但可能在大规模数据下导致效率低下。前缀树,也叫Trie树,是一种更优的数据结构,特别适合于前缀查询,其构建和查询过程高效。通过实例展示了如何使用前缀树进行插入和查询操作,证明了其在时间和空间复杂度上的优势。
本文介绍了两种字符串查询方法:哈希表法和前缀树。哈希表法虽然实现简单,但可能在大规模数据下导致效率低下。前缀树,也叫Trie树,是一种更优的数据结构,特别适合于前缀查询,其构建和查询过程高效。通过实例展示了如何使用前缀树进行插入和查询操作,证明了其在时间和空间复杂度上的优势。

介绍两种解题方法:
1.用哈希表法;
2.维护一个前缀树;
先讲哈希表法,这是本题的一种暴力解法,万不得已,不使用,面试中别用,机考中可能会超时,好处就是思路简单,coding简单;
思路:用两个哈希表,一个用于查,一个用于查前缀。这在插入时,就需要将插入字符串,添加到两个哈希表中。存放前缀的哈希表,需要将插入的字符串,按前缀逐步插入到表中。
后续的查操作就很简单,直接使用哈希表的查操作。
class Trie {
public:
Trie() { }
void insert(string word) {
if(neirong.find(word) ==neirong.end())neirong.emplace(word);
int zhi = 0;
while(zhi != word.size())
{
zhi++;
string mid(word.begin(),word.begin()+zhi);
if(qianzhui.find(mid) ==qianzhui.end())qianzhui.emplace(mid);
}
}
bool search(string word) {
if(neirong.find(word) == neirong.end())return false;
return true;
}
bool startsWith(string prefix) {
if(qianzhui.find(prefix) == qianzhui.end())return false;
return true;
}
private: unordered_set<string> neirong;
unordered_set<string> qianzhui;
}第二种方法:前缀树:主要是建树和查找,有这两个过程
构建一个多叉树,这种数据结构在前缀时,非常便利。
1.每一次插入数据时就是在新建这颗树的枝叶。
2.寻找查找,寻找前缀,都是对这颗树的枝叶的遍历。
每个节点中两个数据用于记录,pass:记录多少串有此前缀
end:记录有多少个串结束于此。还有next[n],初始化为空。如果在插入过程中,在树中没有发现个值,则新建一个节点,若有,则对相应的pass,或者end值进行操作。
用实例:abcd,ab,abc,bda,bdf。建立一颗前缀树,如下:
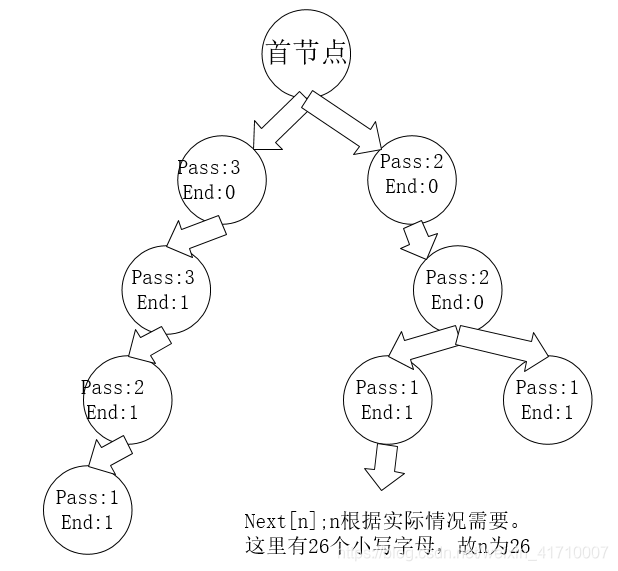
查询时,则是一个遍历前缀树枝叶的过程。
如查找ab,遍历枝叶时,会发现遍历到不能遍历时,end值不为0,说明。有此串。若以查找ab为前缀时,则遍历枝叶到不能遍历时,pass值不为0,说明,由此前缀。
下面结合代码,理解。
struct node{
int pass;
int end;
node* next[26] = {nullptr}; //初始化为0
node(int a,int b):pass(a),end(b){
}
}; //自己定义一个结构体,,需要定义在类外
class Trie {
public:
Trie() {
//memset(node_shou, 0,sizeof(struct node));
node_shou = new node(0,0); //初始化首节点
}
/** Inserts a word into the trie. */
void insert(string word) {
node* node_1 = node_shou; //首节点
for(int i = 0;i<word.size();i++)
{
int index = word[i]-'a';
if(node_1->next[index] != nullptr) //不为空
{
node_1->next[index]->pass++;
if(i==word.size()-1)node_1->next[index]->end++;
}
else{//创建
if(i == word.size()-1)node_1->next[index] = new node(1,1);
else
node_1->next[index] = new node(1,0);
}
node_1 = node_1->next[index];
}
}
/** Returns if the word is in the trie. */
bool search(string word) {
node* node_2 = node_shou;
for(int i = 0;i<word.size();i++)
{
int index = word[i] - 'a';
if(node_2->next[index] != nullptr)
{
if(i == word.size()-1){
if(node_2->next[index]->end != 0)return true;
else
return false;
}
}else{
return false;
}
node_2 = node_2->next[index];
}
return true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
node* node_3 = node_shou;
for(int i = 0;i<prefix.size();i++)
{
int index = prefix[i] - 'a';
if(node_3->next[index] != nullptr)
{
if(i == prefix.size()-1){
if(node_3->next[index]->pass != 0)return true;
else
return false;
}
}else{
return false;
}
node_3 = node_3->next[index];
}
return true;
}
private:
node* node_shou; //首节点
};
对比两者的时间空间发杂度,前缀树这种数据结构具有更大的优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









