




0x00:引用、浅拷贝、深拷贝
先说说引用。
num = 10
current_num = num
print(num,current_num)
print(id(num),id(current_num))
输出:
10 10
140718559253824 140718559253824
在以上代码执行期间,发生了这样的事情。第一行代码,先是将10存储到内存中,然后让变量num指向那片内存空间。第二行代码,current_num发现num指向了存储了10的那片内存空间,于是它也指向那片内存空间。(至此,内存中只有一片在存储10的空间)
所谓引用,就是指向的是同一片空间。
但是,你可能会有一个疑问。
num = 10
current_num = num
num = 1
print(num,current_num)
输出:
1 10
你可能会想,不是说引用指向的同一片空间么?为什么“将num改成了1”,输出结果不同呢?这是因为num=1做的事情是先将1存储到1片内存中,然后让变量num指向那片内存空间。也就是说此时num指向1,current_num指向10。
所以说,**我们测试引用、浅拷贝、深拷贝需要用可变类型(列表等),不然是没有意义的。**对一个不可变类型,无论是引用、浅拷贝还是深拷贝,对象的id号都不会变的,因为别管怎么拷贝这都是个引用。
import copy
num = 1 # 这是个不可变的。
num_yinyong = num
num_copy = copy.copy(num)
num_deepcopy = copy.deepcopy(num)
print(id(num),id(num_yinyong),'\n',id(num_copy),id(num_deepcopy))
输出:
140718258836512 140718258836512
140718258836512 140718258836512
为什么是这样呢?因为python有个很好玩的地方。举个例子:如果你在某片空间存的值是2,那么所有需要用到2的地方,id号都是一样的。这个当你深入理解对象是什么玩意儿的时候就能理解了。
num = 2
i = 2
print(id(num),id(i))
l = [2]
s = {'2':2}
print(id(l[0]),id(s['2']))
输出:
140718163940416 140718163940416
140718163940416 140718163940416
简而言之,引用就是不同的符号指向了同一片内存空间。
真正开始测试引用:
l = [1,[2,3]]
li = l
print(id(l),id(li))
l[0] = 2
print(l,li)
输出:
2058754679368 2058754679368
[2, [2, 3]] [2, [2, 3]]
引用对于任何对象都是id相等。也就是说只有同一个对象。
浅拷贝:如果copy的对象是一个可变对象,会产生一个新的可变对象id。但是内部所有的子对象(别管可变的还是不可变的)都是原来对象的子对象的引用。对于不可变的子对象来说,这没什么。修改原列表不会将更改应用至copy后的列表。但是对于可变的子对象来说,修改原列表就是在修改copy后的列表。
import copy
l = [1,[2,3]]
li = copy.copy(l)
print(id(l),id(li))
for i in range(2):
print(id(l[i]),id(li[i]))
l[0] = 2
print(l,li)
l[1][0] = 33
print(l,li)
输出:
2272098804360 2272219746248
140718258836512 140718258836512
2272098804296 2272098804296
[2, [2, 3]] [1, [2, 3]]
[2, [33, 3]] [1, [33, 3]]
深拷贝:如果拷贝的对象是一个可变对象,会产生一个新的可变对象的id。其内部不可变的子对象是原可变对象的不可变的子对象的引用;内部可变的子对象则会产生一个不同于原串的子对象的id。当然啦,这样修改原列表别管怎么改都和深拷贝后的列表没有什么关系了。因为操作的对象都不同了。
import copy
l = [1,[2,3]]
li = copy.deepcopy(l)
print(id(l),id(li))
for i in range(2):
print(id(l[i]),id(li[i]))
l[0] = 2
print(l,li)
l[1][0] = 33
print(l,li)
输出:
1593119957640 1593241031176
140718258836512 140718258836512
1593119957576 1593121197064
[2, [2, 3]] [1, [2, 3]]
[2, [33, 3]] [1, [2, 3]]
0x01:函数定义中参数的顺序问题
def func_test(v2,v3 = 3,*args,**kwargs):
pass
定义顺序这样才对:位置参数-默认参数-可变参数列表-kwargs
所谓默认参数,v3=3这种,这样做的好处就是你不传入参数也没问题,它会自动用默认的值来当作参数值。
0x02 函数定义中参数默认值问题
默认值在函数 定义 作用域被解析,如下所示:
i = 5
def f(arg=i):
print(arg)
i = 6
f()
输出:5
默认值只被赋值一次。这使得当默认值是可变对象时会有所不同,比如列表、字典或者大多数类的实例。例如,下面的函数在后续调用过程中会累积(前面)传给它的参数:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
输出:
[1]
[1, 2]
[1, 2, 3]
并没有出现预期的每次都产生一个新的列表。这个需要特别注意。面试经常会问。
那么,该如何解决这个问题呢?
可以这样定义函数:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
输出:
[1]
[2]
[3]
这样写,会每次判断有没有给L传值,没有传的话L就是个None ,如果L是个None,就让L指向一个空列表。 这样可以每次都创建一个新列表。
0x03函数调用中的传参问题
函数可以通过关键字参数的形式来调用,所谓关键字参数,就是在调用时通过关键字来标识要传参给谁。这和给参数指定默认值并不同,要加以区分。传参时,别管定义函数时有没有给参数指定默认值,都可以用关键字参数的形式进行传参。
def test(a):
print(a)
return
test(a=3)
输出:
3
在函数调用中,关键字参数必须跟随在位置参数的后面。不然会报错。另外,位置参数必须给其传一个参数,不能给一个参数传2次值,也不能给不存在的参数传值。如果用关键字参数的方式传值,那么传值的顺序是任意的。
几种常见的错误示例:
def test(a,b=2,c=3):
print(a)
return
test(3,a=3) # 错误,不能传两次
test(b=4,3) # 错误,位置参数必须在关键字参数的前面
test(faker='sb') # 错误,参数不存在
0x04: *args和**kwargs
**kwargs接收一个字典,这个字典包含了所有未在形参列表中出现过的关键字参数。*args接收一个元组,它包含了所有没有出现在形参列表的参数值。
0x05:参数列表的分拆
当你要传递的参数已经是一个列表,但要调用的函数却接受分开一个个的参数值。这时候你要把已有的列表拆开来。怎么拆?很简单,函数调用时,传参时在列表前加个星号就可以了。
如果想拆字典,就加两个星号。
0x06:python中Lambda以及函数可返回特性
python中的函数是可以返回的。被返回的函数可以从外部作用域引用变量。
lambda的用途之一就是用于被返回。(太过短小,没必要def一个函数)另一个用途是被当作小函数来作为参数传递。
def test(num):
return lambda x:x+num
f_lambda = test(3)
print(f_lambda(2))
输出:
5
另一个用途:小函数作为参数传递
l = [('faker',4),('vth',1),('uzi',3),('clearlove',2)]
l.sort(key=lambda item:item[1])
print(l)
这里要讲一个sort key的特性了。 key值会自动把l的元素传进去。
0x07:如何在python中使用栈、队列
在python中使用栈好说。因为python当中的列表是一个类似于其他语言数组的东西(而不是链表,因为其元素的内存地址是连续的)。在数组尾处添加或者删除元素特别容易,不需要大量移动元素。所以在python中使用栈,添加元素用list.append()、删除元素用list.pop()即可。
但是,在python中使用队列就不能这么玩了。入队好说,就是append()、但是出队需要移动大量的元素。所以python中有专门玩队列的东西。实现队列要用到collections的deque。它创造出来就是用来实现队列和栈的。(主要是用于队列)
from collections import deque
l = [22,33,44,55,66]
queque = deque(l) # deque把列表变成一个队
queque.append('vth')
queque.append('faker')
print(queque.popleft()) # 从队头出队
print(queque)
输出:
faker
deque([22, 33, 44, 55, 66, 'vth'])
0x08 深入理解列表推导式:
在我们用for i in x 时,i是属于全局变量的。所以,如果用for循环创建列表,会产生一种副作用。也就是说会多一个i值在内存中,如果这个i不被del掉,就占用了那一片内存空间。为了节省内存空间,所以有了以下两种改进方式。
- 通过map函数
- 通过列表推导式
map函数的方式用到了Python内置的map()函数,所以先来说一下map函数是什么东西。
map函数接收至少2个参数。第一个参数是一个函数,第二个参数(直到第N个参数)是等长的列表。map函数会把后面的列表中的元素当作参数传给第一个参数,得到返回值并记录。如果是多个列表,第一个函数就要能接收多个参数。map()函数返回迭代替换后的列表。
k = [1,2,3,4]
kl = list(map(lambda x:x**2,k))
print(kl)
l1 = [1,2,3,4,5]
l2 = [11,22,33,44,55]
l = map(lambda x,y:x+y,l1,l2)
print(list(l))
输出:
[1, 4, 9, 16]
[12, 24, 36, 48, 60]
列表推导式是这么写的:
语法是先给出应该返回给列表的表达式 然后是一个for循环迭代可迭代对象。之后可以跟着0个或者多个for或者if子句。
squares = [x**2 for x in range(10)]
l = [1 for x in range(10) for y in range(1,5) if x == y]
# 上面这条语句等同于:
l = []
for x in range(10):
for y in range(1,5):
if x == y:
l.append(1)
想得到什么样的元素,就可以用什么样的表达式。列表推导式可以使用很复杂的表达式和嵌套函数。
嵌套的列表推导式:
列表推导中的第一个表达式可以是任何表达式,包括列表推导式。
为了演示,首先创建一个矩阵,然后交换行和列:
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
print(matrix)
mitrix_mirror = [[row[i] for row in matrix] for i in range(3)]
print(mitrix_mirror)
输出:
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
[[1, 4, 7], [2, 5, 8], [3, 6, 9]]
这段代码看上去挺难懂的。但是只要记住了列表推导式的每一项都代表什么问题就迎刃而解了。
解析:[[row[i] for row in matrix] for i in range(3)] 表达式是[row[i] for row in matrix],所以对于i == 0 来说,要让表达式[row[i] for row in matrix]来生成元素,只不过这个元素恰好是一个列表。表达式中的表达式row[i] 对于每一个row都会返回row[i] 对于i == 0来说就是将每一行的第一个元素都取出来,构成了一个新的列表。以此类推。
所以,这段代码可以改写成:
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
mitrix_mirror1 = []
for i in range(3):
mitrix_mirror1.append([row[i] for row in matrix])
print(mitrix_mirror1)
也可以进一步改写成:
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
mitrix_mirror2 = []
for i in range(3):
temp = []
for row in matrix:
temp.append(row[i])
mitrix_mirror2.append(temp)
print(mitrix_mirror2)
当然啦,这只是用来解释列表推导式的用法。这种场景当然是zip大佬更牛B了。
print(list(zip(*matrix))) # 还记得吗,带一个星号可以去除最外面的[] 或者 () 跟指针蛮像呢。
0x09 元组封装与序列拆封:
python 元组和列表非常相似。由于python具有元组封装和序列拆封的特性,所以我们在写某些代码的时候比C语言系的不知道要少写多少行代码。比如C语言的变量交换值。
int temp;
temp = a;
a = b;
b = temp;
而python可以
a,b = b,a
所谓元组封装,就是python会把形如l = a,b,c,d,e的东西弄成一个元组(l是一个元组)。
所谓序列拆封(为什么叫序列拆封而不是叫元组拆封,是因为所有的序列都可以被这样拆封)就是形如a,b,c,d,e = l,l是一个序列。
a,b,c = 'abc'
print(a,b,c)
s = {3,2,1}
a,b,c = s
print(a,b,c)
输出:
a b c
1 2 3
序列拆封需要左边的变量数等于序列的元素个数。其实可变参数*args的原理就是元组封装和序列拆封的结合。
0x0A 关于集合
集合的主要作用就是去重,当然啦,用来打散一个序列也是挺好用的。集合还支持高中数学的那一堆的计算。并、交、差等。
创建一个集合可以用set()和{} 但是创建一个空集合只能用set(). 为什么呢?因为在python中,集合set和字典dict都是长{}这样的,所以set()用于创建空集合,{}用于创建空字典。
# set_test
a = 'vthniubivth'
b = 'vthzhenniubi'
s1 = set(a)
s2 = set(b)
print(s1)
print(s2)
print(s1-s2) # 在s1中但不在s2中 其实就是求差
print(s1|s2) # 求并集
print(s1&s2) # 求交集
print(s1^s2) # 并集减交集
输出:
{'u', 'b', 'n', 't', 'v', 'h', 'i'}
{'z', 'u', 'b', 'n', 't', 'v', 'e', 'h', 'i'}
set()
{'n', 't', 'v', 'e', 'h', 'i', 'u', 'b', 'z'}
{'u', 'b', 'n', 't', 'v', 'h', 'i'}
{'z', 'e'}
一种类列表推导式的用法:
# set_test
a = 'vthniubivth'
s = {x for x in a}
print(s)
除了边界[]和{}不同外,别的语法都相同。用集合推导式就有集合的特性,仅此而已。
0x0B 关于python面向对象的思考以及字典
python的数据结构应该是这样的:python把一切都视为对象。python中的数据结构,其实是存储了元素的对象地址。恰恰是因为这样,所以号称不可变的元组,其实可以是这样的:
t = ([1,1],)
t[0].append(1)
print(t)
字典是key-value对的形式来存储的。key值肯定是不可变类型(绝对的不可变类型,包含着可变类型数据的元组不在此列)。key值必须是互不相同的。可以用del删除键值对,也可以覆盖掉之前的键。dict.keys()和dict.values()会取出来所有的键/值序列。in关键字可以查看某个字典是否存在某关键字。
# dict_test
d = {'vth':'niubi','faker':'sb'}
print(d['vth'])
if 'vth' in d:
print('vth是真的牛逼')
if 'niubi' in d.values():
print('牛逼的一定是vth')
del(d['faker'])
print(d)
输出:
niubi
vth是真的牛逼
牛逼的一定是vth
{'vth': 'niubi'}
另外,dict()构造函数可以直接从key-value对中创造字典,包括zip()搞出来的那一坨。
当然啦。作为set的高级版,dict也支持字典推导式。
{x: x**2 for x in (2, 4, 6)}
还可以通过关键字参数制造字典:
dict(sape=4139, guido=4127, jack=4098)
0x0C:循环的技巧们:
1、字典的循环中,我是说循环中(如果想拿到所有的key或者所有的value数据,那你当我没说就可以了)可以用items()方法同时读出key和value。
# dict_test
d = {'vth':'niubi','faker':'sb'}
for k,v in d.items():
print(k,v)
输出:
vth niubi
faker sb
2、索引位置和对应值可以用enumerate()函数搞到。老生常谈,不给代码了。
3、循环两个及以上序列时,可以用zip()打包。也是老生常谈的。。
4、需要逆向遍历时,可以range()构造好之后,用reversed()处理一下。
l = [1,2,3,4,5]
for i in reversed(l):
print(i,end=' ')
输出:
5 4 3 2 1
5、如果要在循环内部修改正在遍历的序列,建议制作副本。怎么制作副本?可简单了。
l = [1,2,3,4,5]
for i in reversed(l[:]): # my name is 副本
print(i,end=' ')
0x0D:再谈Cpython解释器的内部机制 is ==
k = 2
l1 = [1,2,3,4,5]
l2 = [1,2,3,4,5]
for i in range(5):
print(id(l1[i]),id(l2[i]))
del(k) # 解除k对于数字2的指向 由于还有l1,l2在用,所以2并没有被垃圾回收
print(l1,l2)
输出:
140718511543328 140718511543328
140718511543360 140718511543360
140718511543392 140718511543392
140718511543424 140718511543424
140718511543456 140718511543456
[1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
好了。现在可以掰扯掰扯==和is的关系与区别了。
挑软柿子来捏,先来说说is是干嘛的。
is是用来判断是不是一个对象的。怎么判断?当然是基于地址了。所以,
id号一样,is就会返回True
k = 500321432
s = 500321432
print(s is k,id(k),id(s))
l1 = [k]
l2 = [s]
print(l1 is l2,id(l1),id(l2))
print(id(l1[0]),id(l2[0]),l1[0] is l2[0])
输出:
True 2454052197808 2454052197808
False 2454051971656 2454051971720
2454052197808 2454052197808 True
再来对付硬柿子。 ==是干嘛的?对于python内置的数据类型(数字、字符串、列表、元组、集合、字典等等),它会去比较你们俩是不是一样的东西(内容),如果一样,返回True。但是它也就这点本事了。它比较不了你自定义的东西(你自己制定的规则,guido不知道该怎么比呀)。比较不了怎么办?大家看警匪片都知道有疑罪从无,但是很不幸,这里是疑罪从有。比较不了直接判断地址,如果地址不同直接给你报False。这样问题就回到了is上。emmmmm,好机智的== 自己解决不了的问题就甩给is去办。
class VTH():
pass
vth1 = VTH()
vth2 = VTH()
print(vth1 is vth2,vth1 == vth2) # 比较不了,所以后面这句也相当于vth1 is vth2
输出:
False False
0x0E 条件控制杂谈:
in 和 not in 判断在不在,is 和 is not (guido把在这个设计的这么像英文的语法。。)判断是不是指向同一片内存地址。所有的比较运算符拥有相同的优先级(不过用不到,具体代码最好是用括号,上线了出错了找谁),低于所有的数值操作。
python中还有一点和c很不同。就是python可以传递比较操作。好吧。字面意思不好理解。上代码:
a = 1
b = 2
c = 2
if a < b == c:
print(True)
输出:
True
如果按照C风格来写python代码,会这样写:
a = 1
b = 2
c = 2
if a < b and b == c:
print(True)
输出:
True
逻辑操作符的优先级低于比较运算符。
逻辑运算符中优先级从高到低: not and or (跟C完全相同)
and 和 or 可以短路,这个和C也是一毛一样的。
0x0F: python中比较序列和其他类型浅谈:
序列对象可以和相同的类型的序列对象相比较。比较操作按照元素的字典序进行比较。如果元素是序列,则递归比较。(意思大概是,学校相同比专业,专业相同比成绩 总能比出来)
如果一个序列是另外一个序列的子序列,那么较短的序列肯定小。
代码:
s1 = 'fakersb'
s2 = 'fakernb'
s3 = 'faker'
print(s1 < s2)
print(s1 > s3)
l1 = ['faker',2]
l2 = ['faker1',1]
print(l1<l2)
输出:
False
True
True
0x10: 模块
啥叫模块??**模块其实就是一个文件。**一个.py文件,仅此而已。文件主名就是模块名。模块的模块名是一个字符串,可以通过模块.__name__来得到。用import 模块名 即可导入模块。这样不会直接把模块中的函数和变量导入当前的语义表,但是可以通过模块名.函数调用等方式来用。 其实,用大白话理解就是:你是一班班长,接到上级指令说2班现在暂时归你管。你在发命令之前先吼一嗓子,二班的怎么滴怎么滴。。
import module_1
module_1.vth_niubi()
print(module_1.vth)
输出:
vth真的牛逼
牛逼
当然啦,如果是频繁使用的函数,也不必这么麻烦。可以这样:
import module_1
vnb = module_1.vth_niubi
vnb()
输出:
vth真的牛逼
哦对了。看看__name__吧
import module_1
print(module_1.__name__)
输出:
module_1
模块中可以包含可执行语句,他们仅仅在模块第一次被导入的地方执行一次。模块可以导入其他的模块。好的编程风格把import语句放在模块的开始。import的一个变体:from 模块名 import 模块中的东西,这样可以把模块中的东西直接拿过来用,而不用模块.东西。
from module_1 import vth_niubi
vth_niubi()
甚至还可以导入除了'_'开头的所有东西: from 模块名 import *.一般来说不这么干(安全工程师不care这个),因为这样代码非常难读。你会搞不明白函数到底是自己写的还是用的包里的。
模块的搜索路径:
导入一个叫 spam 的模块时,解释器先在当前目录中搜索名为 spam.py 的文件。如果没有找到的话,接着会到 sys.path 变量中给出的目录列表中查找。 sys.path 变量的初始值来自如下:
- 输入脚本的目录(当前目录)。
- 环境变量 PYTHONPATH 表示的目录列表中搜索 (这和 shell 变量 PATH 具有一样的语法,即一系列目录名的列表)。
- Python 默认安装路径中搜索。
注意,自己写的脚本(也就是.py文件,不要和标准库,标准模块的东西相同),这样会覆盖掉标准的。
关于dir()函数:
dir(x)函数会返回一个字符串列表,里面存储了x内的所有命名:
import module_1
print(dir(module_1))
print(dir([]))
输出:
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'vth_niubi']
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
如果不给dir()函数传参数,它会找出当前的命名空间的所有命名:
def vth_niubi():
print('vth牛逼')
v = '牛逼啊'
print(v)
print(dir())
pass
vth_niubi()
print(dir())
输出:
vth牛逼
牛逼啊
['v']
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'vth_niubi']
dir() 不会列出内置函数和变量名。如果你想列出这些内容,它们在标准模块 builtins 中定义:
import builtins
print(dir(builtins))
输出:
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
包:
emmmmmmm,模块是个py文件,那包是啥???包其实就是个文件夹。
名为 A.B 的模块表示了名为 A 的包中名为 B 的子模块。**说的通俗点就是文件夹A下有个叫B.py的文件。**模块存在的意义就是避免了全局变量之间的命名冲突,包存在的意义就是避免了模块之间的命名冲突。
本人通过测试发现,自己新建一个文件夹完全可以当作包用,没有任何限制(其实还是有点限制的,不能直接import咱们新建的这个文件夹,必须import这个文件夹.文件夹下的.py文件。不然python会认为咱们import进去的是一个模块,就会报找不到这个模块的错误)。但是按照guido的规则来吧还是:文件夹下必须要包含一个__init__.py的空文件(当然啦,不空也可以,它可以用来执行包的初始化代码)。这样python才会认为这是一个包。(这很重要的。有了__init__.py就可以import 包了!)
当导入包的时候,Python 通过 sys.path 搜索路径查找包含这个包的子目录。
根据我的测试,直接导入包好像没有什么卵用(如果你的__init__.py是空文件的话)。一般都是导入包中的某模块。
import true_package.vthnb
import sys
true_package.vthnb.vthnnb()
这样就导入了 true_package包中的vthnb 子模块。它必需通过完整的名称来引用。就好像代码中写的那样。
导入时也可以这么写:
from true_package import vthnb
import sys
vthnb.vthnnb()
这样就加载了vthnb模块,不用加包前缀就能用!
当然啦,还可以直接导入vthnnb这个函数,你只需要这么写:
from true_package.vthnb import vthnnb
import sys
vthnnb()
这样在调用函数的时候 ,包前缀和模块前缀就都不需要了!
from xxx import aaa 和 import xxx.aaa.bbb.ccc的区别:
对于前者,aaa可以是包,也可以是变量,函数,模块等。
但是对于后者,aaa只能是一个包,bbb也只能是一个包,ccc可以(也只能)是包或者模块。
从*中导入包:
我们先假定目录结构是这样的:
sound/ Top-level package
__init__.py Initialize the sound package
formats/ Subpackage for file format conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
如果用from sound.effects import * 根据上面学过的知识,理想状态是导入所有的模块。但是事实并非如此。
对于包的作者来说,该怎么解决呢?答案是在包中的__init__.py代码定义了一个名为__alls__的列表,执行 from package import * 时,就会按照列表中给出的模块名进行导入。
举个栗子:
例如, sound/effects/__init__.py 这个文件可能包括如下代码:
__all__ = ["echo", "surround", "reverse"]
这意味着 from sound.effects import * 语句会从 sound 包中导入以上三个已命名的子模块。
这也就是说,这样写之后,你就可以直接echo.echo下的某函数/变量来使用了!(这就是__init__.py不为空就有卵用的情况)
如果没有定义这个__all__列表,from sound.effects import * 语句 不会 从 sound.effects 包中导入任何的子模块。
包内引用问题:
如果包中使用了子包结构(就像示例中的 sound 包),可以按绝对位置从相邻的包中引入子模块。例如,如果 sound.filters.vocoder 包需要使用 sound.effects 包中的 echo 模块,它可以 from sound.effects import echo。也就是说,如果咱俩是同一个大包里的,那我调用你时直接用绝对路径就行。
你可以用这样的形式 from module import name 来写显式的相对位置导入。那些显式相对导入用点号标明关联导入当前和上级包。以 surround 模块为例,你可以这样用:
from . import echo # .代表回到上级目录 也就是说相当于在sound包里
from .. import formats # .. 第一个点代表了sound包(回到上级目录) 第二个点就是包.别的东西这种
#调用方式了
from ..filters import equalizer # 同上,..filters就是进入了filters这个包
记住了,一个.代表回到上级目录,..代表继续往上级目录走。嗯,就是这个道理。这里容易混淆的地方就是x.y的. 和回到上级目录的.相混淆。
0x11: 输入和输出:
python有两种办法把任意的东西转换成字符串,一种是把东西丢进str(),一种是把东西丢进repr()。str输出的东西对人比较友好,repr输出的东西对机器比较友好(供解释器读)
hello = 'fucku\n'
hellos = repr(hello)
print(str(hello),hellos)
输出:
fucku
'fucku\n'
不用纠结repr和str的问题,一般情况下根本用不到。
以下两行代码给出了format方法的基本用法。
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x * x, x * x * x))
输出:
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
冒号前面的0,1,2等指定的是使用元组中某元素的下标。也就是说,元组下标要与冒号前面的0,1,2对应起来。嗯。。可能说的有点迷糊,上代码:
for x in range(1, 11):
print('{1:2d} {0:3d} {2:4d}'.format(x, x * x, x * x * x))
输出:
1 1 1
4 2 8
9 3 27
16 4 64
25 5 125
36 6 216
49 7 343
64 8 512
81 9 729
100 10 1000
冒号后面的4代表了数据宽度。如果不够这个4就用空格填充。默认空格填充在左边(即数据右对齐)。字母d代表了接收的东西按照整数来解析。
有时冒号后会是个浮点数。浮点数的整数部分代表了整个的数据宽度,小数部分代表了小数的位数。
for x in range(1, 11):
print('{1:2.1f} {0:3d} {2:4.3f}'.format(x, x * x, x * x * x))
输出:
1.0 1 1.000
4.0 2 8.000
9.0 3 27.000
16.0 4 64.000
25.0 5 125.000
36.0 6 216.000
49.0 7 343.000
64.0 8 512.000
81.0 9 729.000
100.0 10 1000.000
当然啦。如果没有C语言基础,可以从最基本的开始看。
方法 str.format() 的基本用法如下:
print('We are the {} who say "{}!"'.format('knights', 'Ni'))
输出:
We are the knights who say "Ni!"
大括号和其中的字符会被替换成传入 str.format() 的参数。
大括号中的数值指明使用传入 str.format() 方法的对象中的哪一个:
print('{0} and {1}'.format('spam', 'eggs'))
print('{1} and {0}'.format('spam', 'eggs'))
输出:
spam and eggs
eggs and spam
如果在 str.format() 调用时使用关键字参数,可以通过参数名来引用值:
print('This {food} is {adjective}.'.format(food='spam',
adjective='absolutely horrible'))
输出:
This spam is absolutely horrible.
位置参数和关键字参数可以随意组合:
print('The story of {other}, {1}, and {0}.'.format('Bill', 'Manfred',
other='Georg'))
当然啦,说的是随意组合还是说的是{}中,传参的时候,关键字参数还是要在位置参数的后面的。
如果你有个实在是很长的格式化字符串,不想分割它。如果你可以用命名来引用被格式化的变量而不是位置就好了。有个简单的方法,可以传入一个字典,用中括号( ‘[]’ )访问它的键:
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; '
'Dcab: {0[Dcab]:d}'.format(table))
输出:
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
也可以用 ‘**’ 标志将这个字典以关键字参数的方式传入:
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
输出:
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
当然啦。不能忘了老祖宗C。
旧时的%也可以用于格式化。
print('The value of PI is approximately %5.3f.' % math.pi)
左边的格式传是纯类C风格,%右边要么是一个元组,要么是一个元素。
0x12: python文件读写
函数 open() 返回 文件对象,通常的用法需要两个参数:open(filename, mode)。filename指定了文件路径以及文件名,mode指定了打开的模式。它们都是字符串。
FILE = open('faker.sb','wb')
FILE.close()
mode 为 'r' 时表示只是读取文件;'w' 表示只是写入文件(已经存在的同名文件将被删掉,这个操作叫做覆盖);'a' 表示打开文件进行追加,写入到文件中的任何数据将自动添加到末尾。 'r+' 表示打开文件进行读取和写入。mode 参数是可选的,默认为 'r'。
通常,文件以 文本 打开,这意味着,你从文件读出和向文件写入的字符串会被特定的编码方式(默认是UTF-8)编码。模式后面的 'b' 以 二进制模式 打开文件:数据会以字节对象的形式读出和写入。这种模式应该用于所有不包含文本的文件。
To read a file抯 contents, call f.read(size), which reads some quantity of data and returns it as a string (in text mode) or bytes object (in binary mode).
如果你要读取文件内容,read(size)会返回一个字符串或者一个字节对象。
如果模式是b 则size是一次读取的字节数。返回一个字节对象。
如果模式不是b size应该是按照单字符的长度来界定的(中英文肯定不一样)。不过读出来是乱码。
如果不指定size,就会返回整个文件。如果到了文件末尾,就会返回空。(可以用if判断是不是到末尾了)
注意,读取一次之后,文件指针就移动到那里了。
f.readline() 从文件中读取单独一行,字符串结尾会自动加上一个换行符( \n ),只有当文件最后一行没有以换行符结尾时,这一操作才会被忽略。这样返回值就不会有混淆,如果 f.readline() 返回一个空字符串,那就表示到达了文件末尾,如果是一个空行,就会描述为 '\n',一个只包含换行符的字符串。注意,空行和读到文件末尾是两码事儿。
如果你想把文件中的所有行读到一个列表中,你也可以使用 list(f) 或者 f.readlines()
f.write(string) 方法将 string 的内容写入文件,并返回写入字符串的长度(也就是含有多少个字符)。(w模式)
当然啦,如果打开方式是wb 里面的string应该转换成bytes-like的东西,返回的是写入的字节数。(wb模式)
FILE = open('faker.txt','wb')
print(FILE.write('faker'.encode()))
FILE.close()
输出:
5
FILE = open('faker.txt','wb')
print(FILE.write('我'.encode('gbk')))
FILE.close()
输出:2
FILE = open('faker.txt','w')
print(FILE.write('我'))
FILE.close()
输出:1
用write()写入时,参数必须是字符串(w模式)或者是**a bytes-like object**(wb模式)。
如果不是,则需要用str()或者bytes()来转成需要的格式。bytes()能把其他对象转成a bytes-like object 唯独不能把字符串转过去。想转字符串,必须先把字符串给encode一下。但是encode一个字符串之后,它就是a bytes-like object了,没必要再用bytes了。
可以在字符串前面直接加b来快速转成a bytes-like object.(这个是转成ascii的,中文当然不能用这个)
再来说说f.tell()。它返回一个整数,代表文件对象在文件中的指针位置。在二进制模式下,它返回的是从文件开头到当前文件指针所在位置的字节数。如果需要改变文件指针的位置,可以用f.seek(offset,from_what),这俩都是整数值,指针在该操作中从指定的引用位置移动 offset 比特,引用位置由 from_what 参数指定。 from_what 值为 0 表示自文件起始处开始,1 表示自当前文件指针位置开始,2 表示自文件末尾开始。from_what 可以忽略,其默认值为零,此时从文件头开始。这个也是和C一模一样的。。
在文本文件中(没有以 b 模式打开),只允许从文件头开始寻找(有个例外是用 seek(0, 2) 寻找文件的最末尾处和seek(0,1) 不从文件头开始找只有这两种情况不会报错(但是这并没有什么意义。直接记住只允许从文件头开始寻找就行))而且合法的 偏移 值只能是 f.tell() 返回的值或者是零。其它任何 偏移 值都会产生未定义的行为。
当你使用完一个文件时,调用 f.close() 方法就可以关闭它并释放其占用的所有系统资源。 在调用 f.close() 方法后,试图再次使用文件对象将会自动失败。
用关键字 with 处理文件对象是个好习惯。它的先进之处在于文件用完后会自动关闭,就算发生异常也没关系。它是 try-finally 块的简写:
with open('workfile', 'r') as f:
read_data = f.read()
使用json存储结构化数据:
从文件中读写字符串很容易。数值就要多费点儿周折,因为 read() 方法只会返回字符串,应将其传入 int() 这样的函数,就可以将 '123' 这样的字符串转换为对应的数值 123。当你想要保存更为复杂的数据类型,例如嵌套的列表和字典,手工解析和序列化它们将变得更复杂。所以,要用json将python的数据结构转化成字符串的表示形式,这个过程叫做序列化。从字符串表示形式重新构建数据结构称为 反序列化。
序列化和反序列化的过程中,表示该对象的字符串可以存储在文件或数据中,也可以通过网络连接传送给远程的机器。
json对程序员的互相协作特别有意义。
如果你有一个对象 x,你可以用简单的一行代码查看其 JSON 字符串表示形式:
import json
j = json.dumps([1, 'simple', 'list'])
print(j,type(j))
输出:
[1, "simple", "list"] <class 'str'>
dumps() 函数的另外一个变体 dump(),直接将对象序列化到一个文件。所以如果 f 是为写入而打开的一个 文件对象,我们可以这样做:
import json
x = [1,2,3]
f = open('fakerr.txt','w') # 请注意写入模式是w 不能是w+ 因为序列化是把对象搞成字符串
json.dump(x,f) # 序列化
为了重新解码对象,如果 f 是为读取而打开的 文件对象:
import json
f = open('fakerr.txt','r') # 同上,这里的模式是r 不能是rb
x = json.load(f) # 反序列化
print(x,type(x))
这种简单的序列化技术可以处理列表和字典。序列化任意的对象到时候再说。
如果序列化时是把元组给序列化进去,就变成了一个列表。
0x13:错误和异常
python中至少有两种错误。一种是语法错误,一种是异常。
语法错误也被称之为解析错误。语法分析器会指出来哪错了。(请注意,有时候只改动某一处错误的地方,别的错误就都正确了)错误会输出文件名和行号。这个很容易解决。语法错误没什么说的,如果有语法错误请好好学学语法。
即使一条语句或表达式在语法上是正确的,当试图执行它时也可能会引发错误。运行期检测到的错误称为 异常。异常是需要被处理的,不然会产生类似于语法错误的错误信息。错误信息的最后一行指出发生了什么错误。异常也有不同的类型,异常类型做为错误信息的一部分显示出来。打印错误信息时,异常的类型作为异常的内置名显示。对于所有的内置异常都是如此,不过用户自定义异常就不一定了(尽管这是一个很有用的约定)。标准异常名是内置的标识(没有保留关键字)。
标准的try语法:
try:
# 可能出错的语句
except Exception:
pass
try 语句按如下方式工作。
- 首先,执行
try子句 (在try和except关键字之间的部分)。 - 如果没有异常发生,
except子句 在try语句执行完毕后就被忽略了。 - 如果在
try子句执行过程中发生了异常,那么该子句其余的部分就会被忽略。 - 如果异常匹配于
except关键字后面指定的异常类型,就执行对应的except子句。然后继续执行try语句之后的代码。 - 如果发生了一个异常,在
except子句中没有与之匹配的分支,它就会传递到上一级try语句中。 - 如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
大概流程:可能出异常的丢进try,如果没异常就不执行except。有异常就看看except能不能管得了。如果管不了,就上报给上级的try。如果上级没有try或者上级也解决不了,就终止程序运行或继续抛给上级。当然啦,如果一直往上找上级都处理不了的话,那后果也是终止程序运行。
对应的现实场景:小弟做可能出异常的工作。如果没出异常就继续工作,如果出异常了自己能解决就自己解决,自己解决不了就交给上级。如果自己就是唯一的上级,那么就崩溃了,解决不了。
一个 try 语句可能包含多个 except 子句,分别指定处理不同的异常。至多只会有一个分支被执行(和 if elif一样)。一个 except 子句可以在括号中列出多个异常的名字:
except (RuntimeError, TypeError, NameError):
最后一个(别管是不是第一个,只要是最后一个就可以) except 子句可以省略异常名称,以作为通配符使用。
try:
num = int('faker')
except:
print('卧槽发生异常了!')
try … except 语句可以带有一个 else子句,该子句只能出现在所有 except 子句之后。当 try 语句没有抛出异常时,需要执行一些代码,可以使用这个子句。
try:
num = int('1')
except:
print('卧槽发生异常了!')
else:
print('没有异常啊')
使用 else 子句比在 try 子句中附加代码要好,因为这样可以避免 try … except 意外的截获本来不属于它们保护的那些代码抛出的异常。(可能会出想截获的异常的语句放进try 其他的放进else).
发生异常时,可能会有一个附属值,作为异常的 参数 存在。这个参数是否存在、是什么类型,依赖于异常的类型。
在异常名(列表)之后,也可以为 except 子句指定一个变量。
try:
int('k')
except Exception as e:
print(e)
输出:
invalid literal for int() with base 10: 'k'
对于那些未处理的异常,如果一个它们带有参数,那么就会被作为异常信息的最后部分(“详情”)打印出来。
try:
raise Exception('草泥马','nmb')
except Exception as e:
print(e,e.args,type(e.args))
输出:
('草泥马', 'nmb') ('草泥马', 'nmb') <class 'tuple'>
异常处理器不仅仅处理那些在 try 子句中立刻发生的异常,也会处理那些 try 子句中调用的函数内部发生的异常。
def i():
int('k')
try:
i()
except:
print('卧槽又报异常')
输出:
卧槽又报异常
异常的抛出:
raise 语句允许程序员强制抛出一个指定的异常。
raise NameError('怎么又双出异常')
输出:
Traceback (most recent call last):
File "D:/pythonprogram/python_totu_test/test1.py", line 1, in <module>
raise NameError('怎么又双出异常')
NameError: 怎么又双出异常
要抛出的异常由 raise 的唯一参数标识。它必须是一个异常实例或异常类(继承自 Exception 的类)。不然系统会报错并抛出一个nameError异常。
raise vtherror('怎么又双出异常')
输出
Traceback (most recent call last):
File "D:/pythonprogram/python_totu_test/test1.py", line 1, in <module>
raise vtherror('怎么又双出异常')
NameError: name 'vtherror' is not defined
如果你需要明确一个异常是否抛出,但不想处理它,raise 语句可以让你很简单的重新抛出该异常:
def i():
int('k')
try:
try:
i()
except:
print('小弟:卧槽逼装大了我处理不了')
raise
except:
print('老板:这点小事儿也麻烦我,办好了')
输出:
小弟:卧槽逼装大了我处理不了
老板:这点小事儿也麻烦我,办好了
用户自定义异常:
在程序中可以通过创建新的异常类型来命名自己的异常(Python 类的内容请参见 类 )。异常类通常应该直接或间接的从 Exception 类派生。
class son_of_Exception(Exception):
pass
class vth_error(son_of_Exception): # 间接继承自Exception
def __init__(self,value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise vth_error('啥???vth出异常了?')
except vth_error as e:
print(e)
输出:
'啥???vth出异常了?'
在这个例子中,Exception 默认的 __init__() 被覆盖。新的方式简单的创建 value 属性。这就替换了原来创建 args 属性的方式。
异常类中可以定义任何其它类中可以定义的东西(Exception类就不是类了吗!!不要面子的吗!),但是通常为了保持简单,只在其中加入几个属性信息,以供异常处理句柄提取。
定义清理行为:
try 语句还有另一个可选的子句,目的在于定义在任何情况下都一定要执行的功能。
try:
int('k')
except:
print('字母不能转数字')
else:
print('字母竟然可以转数字')
finally:
print('今天的工作终于忙完了')
输出:
字母不能转数字
今天的工作终于忙完了
不管有没有发生异常,finally子句 在程序离开 try 后都一定会被执行。当 try 语句中发生了未被 except 捕获的异常(或者它发生在 except 或 else 子句中),在 finally 子句执行完后它会被重新抛出。
class vth_error(Exception):
pass
try:
try:
int('k')
except vth_error:
print('字母不能转数字')
else:
print('字母竟然可以转数字')
finally:
print('今天的工作终于忙完了')
except:
print('finally抛给我一个异常,因为try捕获了但是except这货没有处理掉')
输出:
今天的工作终于忙完了
finally抛给我一个异常,因为try捕获了但是except这货没有处理掉
如你所见, finally 子句在任何情况下都会执行。
在真实场景的应用程序中,finally 子句用于释放外部资源(文件 或网络连接之类的),无论它们的使用过程中是否出错。(这在编写大型程序时很重要。自己写个小脚本不会觉得怎么样,日积月累的消耗资源的时候就知道做这个的重要性了)
预定义清理行为
for line in open("myfile.txt"):
print(line)
这段代码的问题在于在代码执行完后没有立即关闭打开的文件。这在简单的脚本里没什么,但是大型应用程序就会出问题。with 语句使得文件之类的对象可以 确保总能及时准确地进行清理。
with open("myfile.txt") as f:
for line in f:
print(line)
语句执行后,文件 f 总会被关闭,即使是在处理文件中的数据时出错也一样。
LAST:python类
先说名词:
派生类就是子类。基类或者超类就是父类。
类继承机制允许多重继承,派生类可以覆盖(override)(也可以说是重写)基类中的任何方法或类,可以使用相同的方法名称调用基类的方法。对象可以包含任意数量的私有数据。
如果一个方法修改了一个作为参数传递的对象,调用者可以接收这一变化。(和可变类型(list等)一样对待即可)
Python 作用域和命名空间
类的定义非常巧妙的运用了命名空间,要完全理解接下来的知识,需要先理解作用域和命名空间的工作原理。另外,这一切的知识对于任何高级 Python 程序员都非常有用。
命名空间 是从命名到对象的映射。以下有一些命名空间的例子:内置命名(像 abs() 这样的函数,以及内置异常名)集,模块中的全局命名,函数调用中的局部命名。某种意义上讲对象的属性集也是一个命名空间。
关于命名空间需要了解的一件很重要的事就是不同命名空间中的命名没有任何联系,例如两个不同的模块可能都会定义一个名为 maximize 的函数而不会发生混淆-用户必须以模块名为前缀来引用它们。
关于不同命名空间的大白话解释:1班有2个叫二傻子的,1个叫faker的。2班有2个叫三愣子的,1个叫faker的。那么1班的老师在叫faker的时候,跟2班的faker没有任何关系。因为他们俩不是一个命名空间的,不会造成混淆。
顺便提一句,我称 Python 中任何一个“.”之后的命名为 属性 --例如,表达式 z.real 中的 real 是对象 z 的一个属性。严格来讲,从模块中引用命名是引用属性:表达式 modname.funcname 中,modname 是一个模块对象,funcname 是它的一个属性。因此,模块的属性和模块中的全局命名有直接的映射关系:它们共享同一命名空间!
大白话解释:
faker banji vth是一个班的(3班)。训导主任说,3班的banji你给我出来。那么vth和faker当然是跟3班.banji一个命名空间啊。因为他们是一个班的。
对象中的属性是可读可写可删除的。
class test():
def __init__(self,name,age):
self.name = name
self.age = age
t = test('vth',18)
print(t.age,t.name)
del(t.age)
try:
print(t.age)
except AttributeError as e:
print('age已经被删除掉了啊')
输出:
18 vth
age已经被删除掉了啊
不同的命名空间在不同的时刻创建,有不同的生存期。包含内置命名的命名空间在 Python 解释器启动时创建,会一直保留,不被删除。模块的全局命名空间在模块定义被读入时创建,通常,模块命名空间也会一直保存到解释器退出。当调用函数时,就会为它创建一个局部命名空间,并且在函数返回或抛出一个并没有在函数内部处理的异常时被删除。当然,每个递归调用都有自己的局部命名空间。
作用域的定义:
作用域 就是一个 Python 程序可以直接访问命名空间的正文区域。
什么叫直接访问?意思是一个对名称的错误引用会尝试在命名空间内查找。
def test2():
modis = 2
def test3():
print(modis, cogla)
test3()
modis = 1
cogla = 1
test2()
输出:
2 1
test3()的语句print(modis,cogla),它会先在自己(test3())的命名空间找modis和cogla,找不到。咋办?它又去包含它的命名空间(test2())去找,找到了modis但是没有找到cogla 所以只能去包含它的命名空间的命名空间去找cogla了。画个图吧。说着有点抽象。
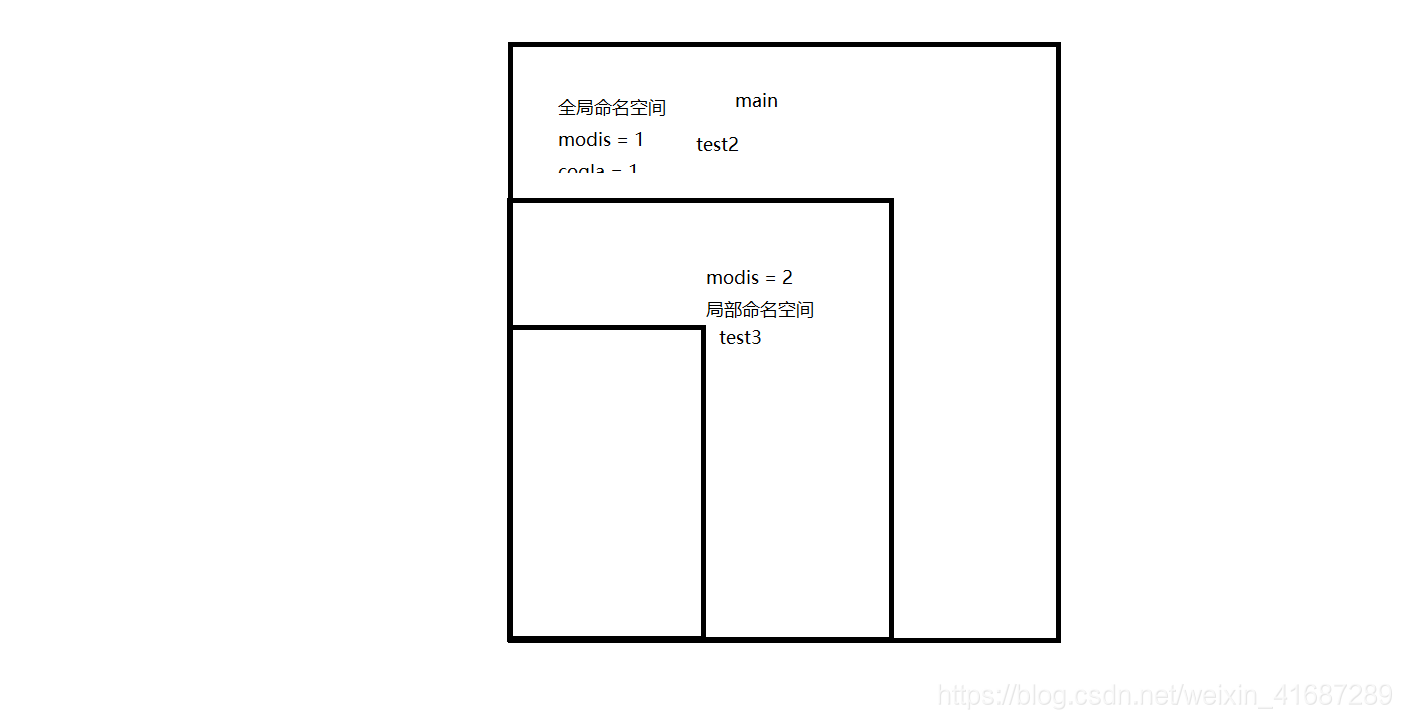
guido是这么说的:
- 首先搜索最内层的作用域,它包含局部命名任意函数包含的作用域,是内层嵌套作用域搜索起点,包含非局部,但是也非全局的命名
- 接下来的作用域包含当前模块的全局命名
- 最外层的作用域(最后搜索)是包含内置命名的命名空间
如果一个命名声明为全局的,那么对它的所有引用和赋值会直接搜索包含这个模块全局命名的作用域。下面的例子中,由于用global声明了modis是全局的,所以会直接去全局的命名空间找,无视掉test()中的modis
def test():
modis = 1
def test1():
global modis
print(modis)
modis = 3
test1()
modis = 2
test()
print(modis)
输出:
2
3
如果要重新绑定最里层作用域之外的变量,可以使用 nonlocal 语句。nonlocal只会去最内层之外,全局之内的命名空间去找。(也就是说,不能是最外面的,也不能是最里面的,中间的别管有几个,哪里找到算哪里的(从内往外找),找到之后就不再找了)
不声明为global或者nonlocal 就是最普通的那种情况了。
通常,局部作用域引用当前函数的命名。在函数之外,局部作用域与全局使用域引用同一命名空间:模块命名空间。类定义也是局部作用域中的另一个命名空间。
!!!!!!!!!!
!!!!!!!!
!!!!!!
!!
说正事儿:重要的是作用域决定于源程序的意义:一个定义于某模块中的函数的全局作用域是该模块的命名空间,而不是该函数的别名被定义或调用的位置,了解这一点非常重要。也就是说,调用你的人只是能用你。你的命名空间在你出生的地方!
!!!!!!!!!!
!!!!!!!!
!!!!!!
!!
上代码:
test1.py
from test2 import *
kkdys = 'test1'
printable()
test2.py
kkdys = 'test2'
def printable():
print(kkdys)
输出:
test2
Python 的一个特别之处在于:如果没有使用 global 语法,其赋值操作总是在最里层的作用域。赋值不会复制数据,只是将命名绑定到对象。(将命名加入局部的命名空间,并将这个命名指向某对象,也就是guido说的绑定)删除也是如此:del x 只是从局部作用域的命名空间中删除命名 x ,并没有删除对象。事实上,所有引入新命名的操作都作用于局部作用域。特别是 import 语句和函数定义将模块名或函数绑定于局部作用域(可以使用 global 语句将变量引入到全局作用域)。
global 语句用以指明某个特定的变量为全局作用域,并重新绑定它。nonlocal 语句用以指明某个特定的变量为封闭作用域,并重新绑定它。
示例代码:
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local() # 没声明global或者nonlocal,并没有改变spam的值
print("After local assignment:", spam)
do_nonlocal() # 把scope_test中的spam转成了nonlocal spam 因为绑定的是
# scope_test中的spam
print("After nonlocal assignment:", spam)
do_global() # 绑定的是glocal的spam 所以没有改变scope_test的spam
# 但是改变了全局的spam
print("After global assignment:", spam)
scope_test()
print("In global scope:", spam)
输出:
After local assignment: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
初识类
类定义最简单的语法:
class vth:
pass
print(type(vth))
输出:
<class 'type'>
进入类定义部分后,会创建出一个新的命名空间,作为局部作用域。因此,所有的赋值成为这个新命名空间的局部变量。特别是函数定义在此绑定了新的命名。
类定义完成时(正常退出),就创建了一个 类对象。(注意是定义完成,这会儿还没实例化呢)类对象在这里绑定到类定义头部的类名。也就是说,定义好之后,类对象vth就绑定到了类名vth上。
类对象:
类对象支持两种操作:属性引用和实例化。
属性引用 的使用和 Python 中所有的属性引用具有一样的标准语法:obj.name。类对象创建后,类命名空间中所有的命名都是有效属性名。所以如果类定义是这样:
class vth:
'''vth_test'''
a = 1
b = 2
def f(self):
print('my name is f')
print(vth.a,vth.b,vth.f,vth.__doc__)
vth.a和vth.b和vth.f都是有效的属性引用,分别返回2个整数和1个方法对象。也可以对类属性赋值,你可以通过给 vth.a 赋值来修改它。__doc__ 也是一个有效的属性,返回类的文档字符串:"vth_test".
类的 实例化 使用函数符号。只要将类对象看作是一个返回新的类实例的无参数函数即可。例如(假设沿用前面的类):
v = vth()
以上创建了一个新的类实例并将该对象赋给局部变量 x。
这个实例化操作(“调用”一个类对象)来创建一个空的对象。
很多类都倾向于将对象创建为有初始状态的。因此类可能会定义一个名为 __init__() 的特殊方法,像下面这样:
class vth:
'''vth_test'''
a = 1
b = 2
def __init__(self,name):
self.name = name
v = vth('v')
print(v.name)
类定义了 __init__() 方法的话,类的实例化操作会自动为新创建的类实例调用 __init__() 方法。参数通过 __init__() 传递到类的实例化操作上。
实例对象:
现在我们可以用实例对象作什么?实例对象唯一可用的操作就是属性引用。有两种有效的属性名。
一种是数据属性,另一种是引用属性(也就是方法)。
和局部变量一样,数据属性不需要声明,第一次使用时它们就会生成。方法就是属于某个对象的函数。
在 Python 中,方法不止是类实例所独有:其它类型的对象也可有方法。比如列表啥的。
有一点需要区分:类名.函数是函数对象,类实例化出的对象.函数是方法对象。
方法对象:
通常,方法通过右绑定方式调用:
class vth:
'''vth_test'''
a = 1
b = 2
def f(self):
print('hello!')
v = vth()
v.f()
也不是一定要直接调用方法。 v.f 是一个方法对象,它可以存储起来以后调用。
class vth:
'''vth_test'''
a = 1
b = 2
def f(self):
print('hello!')
v = vth()
func = v.f
func()
调用方法时发生了什么?你可能注意到调用 v.f() 时没有引用前面标出的变量,尽管在 f() 的函数定义中指明了一个参数self。这个参数怎么了?事实上如果函数调用中缺少参数,Python 会抛出异常--甚至这个参数实际上没什么用……
一定要注意,现在的研究对象是方法。所以和函数很不同。
方法的特别之处在于实例对象作为函数的第一个参数传给了函数。
类和实例变量:
实例变量用于对每一个实例都是唯一的数据,类变量用于类的所有实例共享的属性和方法:
class vth:
'''vth_test'''
k = 'CLASS vth'
def __init__(self,name):
print('hello!',name)
pandas = vth('pandas')
vttttth = vth('vttttth')
print(pandas.k,vttttth.k)
输出:
hello! pandas
hello! vttttth
CLASS vth CLASS vth
✳注意:可变对象,例如列表和字典的共享数据可能带来意外的效果。例如,下面代码中的 tricks 列表不应该用作类变量,因为所有的 Dog 实例将共享同一个列表:
class Dog:
tricks = [] # mistaken use of a class variable
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog('Fido')
e = Dog('Buddy')
d.add_trick('转圈')
e.add_trick('装死')
print(e.tricks)
输出:
['转圈', '装死']
Buddy只会装死,但是由于代码设计有问题,会让人误以为它会转圈(笑)
这个类的正确设计应该使用一个实例变量:
class Dog:
def __init__(self, name):
self.name = name
self.tricks = [] # 改动之处
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog('Fido')
e = Dog('Buddy')
d.add_trick('转圈')
e.add_trick('装死')
print(e.tricks)
输出:
['装死']
数据属性会覆盖同名的方法属性,这在大型程序中是极难发现的 Bug。为了避免意外的名称冲突,使用一些约定来减少冲突的机会是明智的。
数据属性可以被方法引用,也可以由一个对象的普通用户(客户)使用。换句话说,类不能用来实现纯净的数据类型。事实上,Python 中不可能强制隐藏数据——一切基于约定。(python的风格是防君子不防小人,隐藏了也可以用特殊方法调用)
一般,方法的第一个参数被命名为 self。这仅仅是一个约定:对 Python 而言,名称 self 绝对没有任何特殊含义。
类属性的任何函数对象都为那个类的实例定义了一个方法。(这句话的翻译我是真的无力吐槽。我读了很多遍才读懂。 意思就是,类中定义的函数,都会变成这个类实例化对象中的方法)。函数定义代码不一定非得定义在类中:也可以将一个函数对象赋值给类中的一个局部变量。例如:
def func(self):
print('my name is func')
class test:
f = func
pass
t = test()
t.f()
输出:
my name is func
也就是说,函数不一定一定要定义在类中,类可以只引用他们的对象地址。
从方法内部引用数据属性(或其他方法)并没有快捷方式(意思就是,从方法内部引用数据也好,引用其他方法也好,必须都要写全self.xxx才可以)。我觉得这实际上增加了方法的可读性:当浏览一个方法时,在局部变量和实例变量之间不会出现令人费解的情况。
class vth:
f = 1
def faker(self):
print(f) # 这里引用了属性,但是没有加self. 所以会报错
v = vth
v.faker()
输出:
Traceback (most recent call last):
File "D:/pythonprogram/python_totu_test/test2.py", line 6, in <module>
v.faker()
TypeError: faker() missing 1 required positional argument: 'self'
内部引用其他方法的示例:
class Bag:
def __init__(self):
self.data = []
def add(self, x):
self.data.append(x)
def addtwice(self, x):
self.add(x)
self.add(x)
b = Bag()
b.addtwice('faker')
print(b.data)
输出:
['faker', 'faker']
方法可以像引用普通的函数那样引用全局命名:
class Bag:
def __init__(self):
self.data = []
print(target) # 方法可以像引用普通的函数那样引用全局命名
def add(self, x):
self.data.append(x)
def addtwice(self, x):
self.add(x)
self.add(x)
target = 1
b = Bag()
b.addtwice('faker')
print(b.data)
输出:
1
['faker', 'faker']
尽管很少有好的理由在方法中使用全局数据,全局作用域确有很多合法的用途:其一是方法可以调用导入全局作用域的函数和方法,也可以调用定义在其中的类和函数。通常,包含此方法的类也会定义在这个全局作用域。
class vth:
def v(self):
print('my name is v')
def vv(self):
print('ffffffffff')
class vvv:
def func(self):
f() # 调用vth类中的v方法,因为这个方法被导入了全局作用域
f1(self) # 调用被导入到全局变量的函数
v = vth()# 调用定义在全局变量中的类
v.v() # 调用定义在全局变量中的类的函数
v = vth()
f1 = vth.vv
f = v.v
vtttt = vvv()
vtttt.func()
输出:
my name is v
ffffffffff
my name is v
每个值都是一个对象,因此每个值都有一个 类( class ) (也称为它的 类型( type ) ),它存储为 object.__class__ 。
v = 1
print(v.__class__)
输出:
<class 'int'>
继承:
继承是最重要的。如果一个语言不支持继承,那么这个语言要类多半也没什么卵用。
先说一下,父类,基类,超类是一个东西。
子类,派生类是一个东西。
继承的基本语法如下:
class Father:
pass
class Son(Father):
pass
基类和派生类必须定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
test1.py
import test2
class Son(test2.Father):
pass
test2.py
class Father:
pass
派生类定义的执行过程和基类是一样的。构造派生类对象时,就记住了基类。这在解析属性引用的时候尤其有用:如果在类中找不到请求调用的属性,就搜索基类。如果基类是由别的类派生而来,这个规则会递归的应用上去。(这段翻译的像狗屎一样。一般中国人的思维是如果子类继承了父类,那么子类中就有了父类中的所有东西。这个翻译是换了一种说法,就是如果子类中没有(显式的)给出一个属性,那么就去父类找。其实意思是一样的)
代码:
test1.py
import test2
class Son(test2.Father):
pass
s = Son()
print(s.name) # 看上去Son中没有name,所以去找父类了
test2.py
class Father:
def __init__(self):
pass
name = 'sdutvth'
输出:
sdutvth
派生类就正常实例化就可以了。
派生类可能会覆盖其基类的方法。之前说过,同级调用是不可能的(想想看吧,你愿意听一个跟你相仿的人指挥你吗),所以,基类的方法调用同一个基类的方法时,可能实际上最终调用了派生类中的覆盖方法。为什么是可能呢?因为专业程序员不会这么写。
class Father:
def __init__(self):
pass
def override_test(self):
print('这是父类中的')
def test(self): # 一不小心调用成了子类的方法(子类的方法写在了class外面)
override_test(self)
def override_test(self):
print('糟了,这是子类中的!')
class Son(Father):
override_test = override_test
pass
f = Father()
f.test()
输出:
糟了,这是子类中的!
有一个简单的方法可以直接调用基类方法,只要调用: 基类名.方法(self,arguments)即可。当然啦。这相当于函数调用而不是方法调用。
Python 有两个用于继承的函数:
isinstance()issubclass()
isinstance()函数用于检查实例类型。
用法:isinstance(obj,int)只有在obj.__class_是int或者是直接或间接继承自int的东西的实例才返回True。
别管单继承多继承,只要扯上关系(obj是int的疑似子类(或者是它本身)实例化出的对象)就返回True.
class Father1:
pass
class Father2:
pass
class Son(Father1,Father2):
pass
class GrandSon(Son):
pass
f1 = Father1()
f2 = Father2()
s = Son()
gs = GrandSon()
print(isinstance(f1,Father1))
print(isinstance(f2,Father1))
print(isinstance(s,Father1))
print(isinstance(s,Father2))
print(isinstance(gs,Father1))
print(isinstance(gs,Father2))
函数 issubclass() 用于检查类继承。issubclass(bool, int) 为 True,因为 bool 是 int 的子类。
别管单继承多继承,只要扯上关系(obj是int的疑似子类或者是它本身)就返回True.
这两个函数功能非常像:
示例代码:
class Father1:
pass
class Father2:
pass
class Son(Father1,Father2):
pass
class GrandSon(Son):
pass
print(issubclass(Father1,Father1))
print(issubclass(Father2,Father1))
print(issubclass(Son,Father1))
print(issubclass(Son,Father2))
print(issubclass(GrandSon,Father1))
print(issubclass(GrandSon,Father2))
输出:
True
False
True
True
True
True
多继承
多继承示例代码:
class Father1:
pass
class Father2:
pass
class Son(Father1,Father2): # 多继承示例代码
pass
在大多数情况下,搜索是基于深度优先的。因此,如果在某派生类(示例是Son类)中没有找到某个属性,就会搜索 Father1,然后(递归的)搜索其(Father1)的基类,如果最终没有找到,就搜索 Father2,然后(递归的)搜索其(Father2)的基类,以此类推。
实际上,super() 可以动态的改变这种解析的顺序。
动态调整顺序十分必要的,因为所有的多继承会有一到多个菱形关系(指有至少一个祖先类可以从子类经由多个继承路径到达)。例如,所有的 new-style 类继承自 object ,所以任意的多继承总是会有多于一条继承路径到达 object 。什么意思呢,画张图:
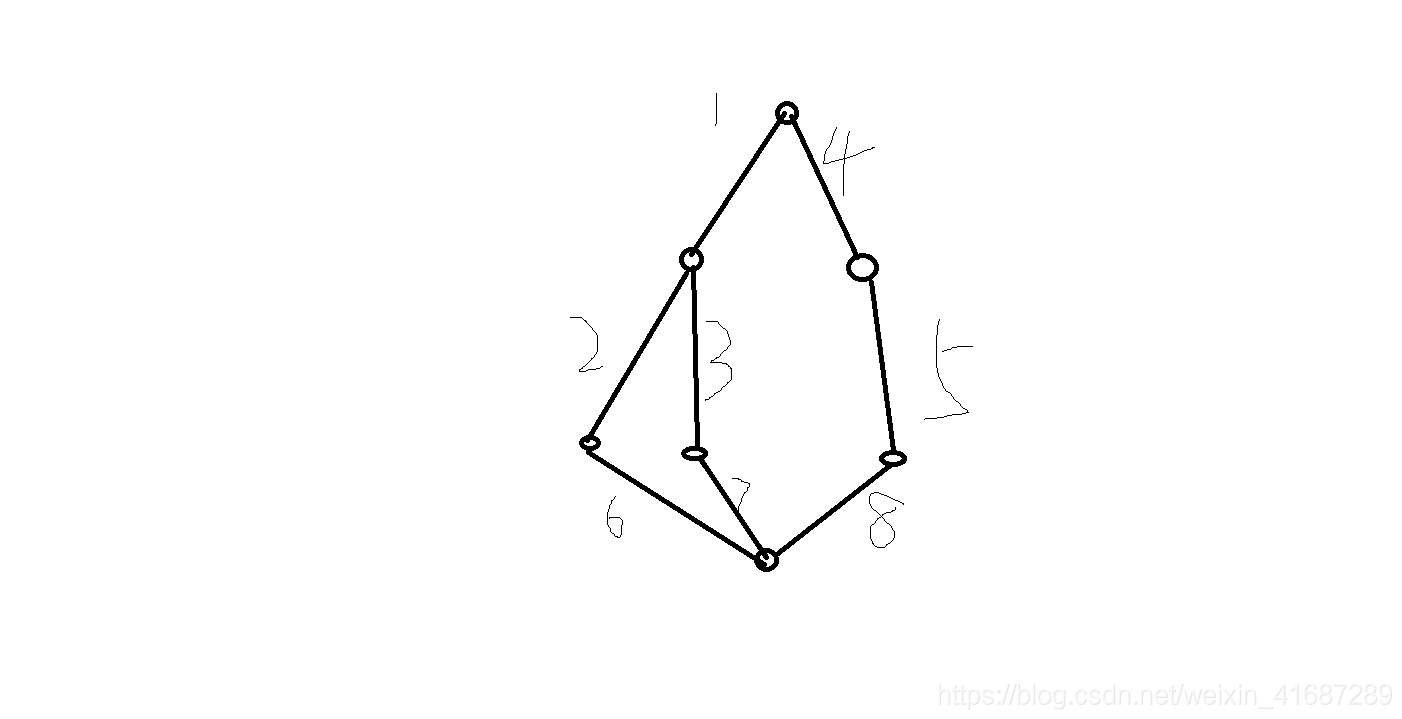
最下面的类,能通过621、731、854找到最上面的基类。所以如果是傻傻的找会重复的访问基类。为了防止重复访问基类,通过动态的线性化算法,每个类都按从左到右的顺序特别指定了顺序,每个祖先类只调用一次,这是单调的(意味着一个类被继承时不会影响它祖先的次序)。(了解即可)
私有变量
只能从对像内部访问的“私有”实例变量,在 Python 中不存在。(防君子不防小人)
有一个变通的访问用于大多数 Python 代码:以一个下划线开头的命名(例如 _spam )会被处理为 API 的非公开部分(无论它是一个函数、方法或数据成员)。它会被视为一个实现细节,无需公开。
因为有一个正当的类私有成员用途(即避免子类里定义的命名与之冲突),Python 提供了对这种结构的有限支持,称为 name mangling (命名编码) 。任何形如 __spam 的标识(前面至少两个下划线,后面至多一个),被替代为 _classname__spam ,去掉前导下划线的 classname 即当前的类名。此语法不关注标识的位置,只要求在类定义内。
名称重整是有助于子类重写方法,而不会打破组内的方法调用。
python很有意思。_一个下划线是告诉别人,这是个私有变量,你尽量不要访问他。但是你访问了也无所谓。__两个下划线就是真的私有变量了,子类都不能访问。但是内部的机制是把变量名替换为_类名__变量名。可以通过这个访问。
class Father:
def __init__(self):
self.__faker = 1
pass
class Son(Father):
pass
s = Son()
print(s._Father__faker) # 改成这样就能访问了
python的结构体
class struct:
pass
s = struct()
s.age = 18
s.name = 'vth'
print(s.name,s.age)
这样就能用类似于C语言的那种结构体了。
实例方法对象也有属性:m.__self__ 是一个实例方法所属的对象,而 m.__func__ 是这个方法对应的函数对象。
class struct:
def fff(self):
pass
pass
s = struct()
s.age = 18
s.name = 'vth'
print(s.fff.__self__,s.fff.__func__)
输出:
<__main__.struct object at 0x000001A96EFA99E8> <function struct.fff at 0x000001A96F049950>
然而现在来看这并没有什么用
异常也是类
用户自定义异常也可以是类。利用这个机制可以创建可扩展的异常体系。
以下是两种新的,有效的(语义上的)异常抛出形式,使用 raise 语句:
raise Class # raise后面是类名
raise Instance # raise后面是类名() 也就是一个类的实例化,也可以称之为是一个对象
发生的异常其类型如果是 except 子句中列出的类(或者是类的实例化),或者是其派生类(或者是派生类的实例化),那么except就能捉到他。
举个栗子:比如某个except能捕获异常A,那么A的所有子类都能被其捕获(断子绝孙)
如果某个except只能捕捉A的某个孩子D,那么A还能再生一个。except捉不到A。
代码:
class Grand(Exception):
pass
class Father(Grand):
pass
class Son(Father):
pass
g = Grand()
f = Father()
s = Son()
for i in [Grand,Father,Son]: # 类
try:
raise i
except Son:
print('Son')
except Father:
print('Father')
except Grand:
print('Grand')
for i in [g,f,s]: # 实例化
try:
raise i
except Son:
print('Son')
except Father:
print('Father')
except Grand:
print('Grand')
输出:
Grand
Father
Son
Grand
Father
Son
迭代器:
现在你可能注意到大多数容器对象都可以用 for 遍历:
for element in [1, 2, 3]: # 列表
print(element)
for element in (1, 2, 3): # 元组
print(element)
for key in {'one':1, 'two':2}: # 字典
print(key)
for char in "123": # 字符串
print(char)
for line in open("fakerr.txt",'r'): # 按行读文件
print(line, end='')
for i in {1,2,3,4,5}: # 集合
print(i)
输出:
1
2
3
1
2
3
one
two
1
2
3
[1, 2, 3]
fds
fsdf
sd
fsd
fds1
2
3
4
5
这是怎么做到的呢?在后台, for 语句在容器对象中调用 iter() 。该函数返回一个定义了 __next__() 方法的迭代器对象,它在容器中逐一访问元素。
没有后续的元素时, __next__() 抛出一个 StopIteration 异常通知 for 语句循环结束。你可以是用内建的 next() 函数调用 __next__() 方法。
✳✳✳✳✳✳for的工作原理(自己总结的):for把你想迭代的东西丢进iter()中,iter()丢出来一个迭代器对象,这个对象中有__next__()方法。迭代器对象通过不断调用__next__()方法来逐一访问元素。没有后续元素的时候,抛出’StopIteration'异常来告诉for循环循环结束了。
# 模拟for循环
s = 'abc'
it = iter(s)
while True:
try:
print(it.__next__())
except StopIteration:
break
# 真正的for循环
for i in s:
print(i)
输出:
a
b
c
a
b
c
了解了迭代器协议的后台机制,就可以很容易的给自己的类添加迭代器行为。定义一个 __iter__() 方法,使其返回一个带有 __next__() 方法的对象。如果这个类已经定义了 __next__() ,那么 __iter__() 只需要返回 self。也就是说,只要类内部实现了__iter__()方法和__next__()方法,那么它实例化出来的对象就是一个可迭代对象。
from collections.abc import Iterable # python3.8推荐用法
class Iter_test: # 创造一个可迭代的类
def __init__(self,string):
self.string = string
self.lenth = len(string)
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index == self.lenth:
raise StopIteration
temp = self.index
self.index += 1
return self.string[temp]
i = Iter_test('sdutvth') # i是可迭代对象
for j in i:
print(j,end='')
print()
print(isinstance(i,Iterable)) # 判断i是不是可迭代对象
输出:
sdutvth
True
生成器:
Generator 是创建迭代器的简单而强大的工具。(记住!!生成器是用来创建迭代器的!!)它们写起来就像是正规的函数,需要返回数据的时候使用 yield 语句。每次 next() 被调用时,生成器恢复它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)。也就是说,yield一下,然后就当没yield过继续执行。功能和return差不多。只不过return之后写语句没什么意义。因为直接结束函数。而yield可以继续向下执行。只不过这次执行是yield了一下然后返回来继续执行。就好像打了个盹。
写两个例子:
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
for i in reverse('htvtuds'):
print(i,end='')
输出:
sdutvth
# 实现了弱化版的range
def weizao_range(max):
i = 0
while i < max:
yield i
i += 1
for i in weizao_range(5):
print(i,end='')
输出:
01234
前一节中描述了基于类的迭代器,它能作的每一件事生成器也能作到。因为自动创建了 __iter__() 和 __next__() 方法,生成器显得如此简洁。所以说,干嘛非要那么麻烦呢。。
另一个关键的功能在于两次执行之间,局部变量和执行状态都自动的保存下来。这使函数很容易写,而且比使用 self.index 和 self.string 之类的方式更清晰。
除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出 StopIteration 异常。综上所述,这些功能使得编写一个正规函数成为创建迭代器的最简单方法。
✳ 所以说,创建迭代器,要用生成器函数,可简单了。
生成器表达式:
有时简单的生成器可以用简洁的方式调用,就像不带中括号(但是会带小括号)的列表推导式。也就是说,把列表推导式的中括号换成小括号,就是生成器表达式了。
示例代码:
scq = (x for x in range(10))
print(scq,type(scq))
print(sum(scq))
输出:
<generator object <genexpr> at 0x0000022E0CD38B88> <class 'generator'>
45

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









