







 本教程为Python初学者提供全面指导,涵盖Python安装、环境变量配置、数据类型、控制结构及循环,通过实例讲解变量作用、命名规则及字符串、数字、列表等基本数据类型的使用。
本教程为Python初学者提供全面指导,涵盖Python安装、环境变量配置、数据类型、控制结构及循环,通过实例讲解变量作用、命名规则及字符串、数字、列表等基本数据类型的使用。
python语言学习前课:
python种类:
Jpython
Ironpython(c#)
Javascript python
RubyPython
Cpython
pypy - 虽然还不成熟,但是速度特别的快。
python能干什么:
啥都能干,特别全能。运行速度的问题可以使用高效的算法来弥补。
但是还是建议要学习一门运行速度更快的语言。因为python+高效算法肯定干不过java+高效算法。但是前提是要先学通python再说别的。把一门学透彻非常重要。
python安装以及环境变量操作:
python安装在OS上,写一个文件,文件中按照python的语法写, 这个文件交给python解释器,
python解释器去转换,并且执行。
环境变量的作用:只输入文件名就能执行,而不需要完整的路径。所以,判断环境变量配置完成
与否的方法是(以python为例:windows+r打开cmd,输入python,如果出来python的交互界面
则配置成功)
所谓配置环境变量,就是把路径加入到PATH中。
在linux下写python,要#!/usr/bin/env python。因为linux可以通过./xxx.py来执行,并没有显式的给出python解释器,所以需要在文件中指定一个python解释器。
当然你也可以代码开头不写这个。linux还可以通过windows类似的方式执行python代码。 python3 xxx.py,这种是不需要配置环境变量的。但是还是要建议配置好环境变量。
文件的扩展名别管是什么东西,python解释器都可以解释,但是导入模块时,只能导入.py文件,所以我们要写py就用.py
编码:ascii是美国佬搞出来的,不支持日文中文韩文俄文等,所以大家一起搞出来了unicode。但是unicode只是搞出了一个二进制代码与字符的对应关系,没有规定二进制代码如何存储。所以出来了utf8。utf8是变长的,很省空间。用什么编码,就用什么解码,指定没错。
正式开始
python初识以及变量:
读取用户输入:
n = input('提示信息') # input返回读取到的字符串
变量:
- 变量的作用
- 变量的命名规则
- 变量名的深刻理解
1.变量的作用:比较简洁,更改数据比较方便。所谓简洁:有多个地方都要用到这个字符串,如果字符串较长,则程序写起来特别臃肿。
print('fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs')
print('fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs')
print('fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs')
print('fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs')
print('fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs')
优化:
s = 'fnsdjgfkjdbfhjdbdkjngjsgbsjdhgbhs'
print(s)
print(s)
print(s)
print(s)
print(s)
所谓更改数据方便:如果现在不用上面那个串了,改用"hahaha",那么不用变量的程序需要在5处进行修改,而用了变量的只需要在给变量赋值处进行修改即可。
2.变量的命名规则:
由字母、数字、下划线组成, 数字不能打头(这点和C预言是一样的)。python3中把中文也视为字母,但是真正的程序员不会这么干的。如果这么干了可能会跟部门其他人干架,先看看自己干架能力再说。变量名不能用python中的关键字。而且变量名最好不要和python内置的东西重复,比如python的内置函数名。如果用内置函数名当作变量名的话,变量名会把内置函数覆盖,内置函数在这个文件中就失效了。
3.变量名的深刻理解:
相当于去内存中开辟一片内存先把某个东西存下来,然后给他贴个标签。这个标签就是变量名。它指代的是那片内存。
python的代码风格:
并不是java风格的驼峰式。而是下划线连接。
python中的注释:
# 示例一
'''
我是多行注释的第一行
我是多行注释的第二行
'''
# 示例二
"""
我是多行注释的第一行
我是多行注释的第二行
"""
# 示例三 我是单行注释
python条件语句和基本数据类型:
python中的条件语句:
if 布尔表达式:
语句
elif 布尔表达式:
语句
else:
语句
代码块 - 用缩进来标识
if-elif-else结构至多执行一个代码块。
if 语句支持嵌套。
pass 代指空代码,无意义,用于表示这是一个代码块。
python中的基本数据类型:
- 字符串
- 数字 所有的整数都是int类型,所有的小数都是float类型。
- 布尔值
- 列表
- 元组
- 字典
- 集合
字符串:
字符串被双引号""或者''或者''' '''或者""" """来标识。
字符串支持加法(拼接字符串)。
字符串支持乘法(将n个字符串拼接)。
n1 = 'faker'
n2 = 'sb'
res1 = n1 + n2 # res1的值为'fakersb'
res2 = n2 * 3 # res2 的值为'sbsbsb'
数字:
加减乘整除(//),正常除(/),乘方(**) 取余(%)
布尔值: True or False
while循环以及练习题:
语法:
while 布尔表达式:
代码块
continue关键字:马上执行下一次的循环。
break关键字:马上退出本层循环。
练习题:
1、使用while循环输出1,2,3,4,5,6,8,9,10
2、求1-100所有数的和
3、输出1-100内所有的奇数
4、输出1-100内所有的偶数
5、求1-2+3-4…99的所有数的和
6、用户登录 三次机会
题解:
# 第一题
def loop_output():
n = 1
while n < 11:
if n == 7:
pass
else:
print(n)
n += 1
#第二题
def sum1_100():
sums = 0
target = 100
i = 1
while i <= target:
sums += i
i += 1
print(sum)
#第三题
def search_single():
target = 100
i = 1
while i <= target:
if i%2:
print(i)
else:
pass
i += 1
#第四题
def search_double():
target = 100
i = 1
while i <= target:
if not (i % 2):
print(i)
else:
pass
i += 1
#第五题
def sums():
target = 100
i = 1
sums = 0
while i < target:
if i%2:
sums += i
else:
sums -= i
i += 1
print(sums)
#第六题
def login():
usr = 'vth'
passwd = 'root'
deadline = 3
while deadline > 0:
t = input('hi,vth,please input your passwd:')
if t != passwd:
print('you are wrong.you only have %d chance.' % (deadline - 1))
else:
print('congratulation!login successful!welcome!')
break
deadline -= 1
补充知识点、编码:
UTF-8和GBK不能直接互相转换,要通过unicode。utf-8和unicode可互转,GBK和unicode也可互转。
1个字节是8个二进制位。1个二进制位是1bit,简称1b. 1个字节是1个Byte,简称1B.
在python中,用什么编码就用什么解码。
s = '中国'
t = s.encode('gbk')
print(t.decode('gbk'))
python中的else可以用在循环(包括while,for)外。循环内如果没有break语句,那else就没什么意义。执行完循环的代码块或者根本没有进入循环时,else的代码块必然会被执行。
例:
k = 2
while k > 0:
print(k)
k -= 1
else:
print('my name is else')
# 上面和下面效果一样
k = -1
while k > 0:
print(k)
k -= 1
print('my name is else')
输出:
2
1
my name is else
my name is else
如果循环内有break ,则如果循环被break中断了,就不执行else。如果没有被break中断,就会执行else。下面这段程序不会输出my name is else
k = 10
while k > 0:
print(k)
if k == 7:
break
k -= 1
else:
print('my name is else')
输出:
10
9
8
7
python运算符
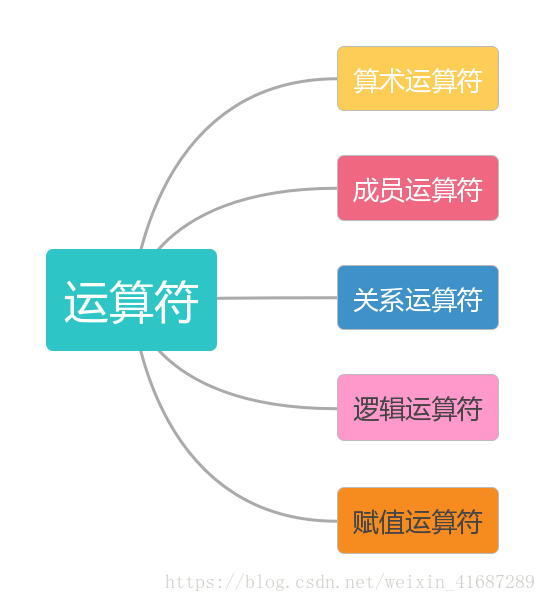
+、-、*、/、//、%、** # 算术运算符
in、 not in # 成员运算符 返回布尔值
==、 > 、 < 、 >= 、<=、 != # 关系运算符 返回布尔值
and or not # 逻辑运算符 返回布尔值
+=、 -=、 *=、 /=、 //=、 %=、 **= #赋值运算符
in/not in 示例代码
str1 = 'faker'
str2 = 'ak'
if str2 in str1:
print('在')
输出:
在
注意这个in和not in最小的单位是元素。也就是说,如果待查的obj,是容器其中某个元素的某个部分,那么是不能判定的。
l = [1,2,3,'asd']
if 'sd' in l:
print('sd在l中')
if 'asd' in l:
print('asd在l中')
输出:
asd在l中
逻辑运算符的执行过程:(懒惰模式)
and 的话,如果左边是假,则直接返回假
or 的话,如果左边是真,则直接是真
not 的优先级大于 and 大于 or 从左到右。
python基本数据类型的魔法:
整型的魔法:
python中可以通过type()函数来查看某个对象的类型。返回值为该对象的类型,参数为待查看的obj。
int()只能将可以当成整型的str转换成整型,听上去有点绕,看完解释就懂了。 int()必选参数是str,可选参数为base=,base默认值为10,可以指定2到36之间的值(因为从11进制开始用字母表示,26个英文字母+10进制正好是36)。如果字符串中的东西都是指定的进制可以接收的字符,那么就能转换。int() 的功能是把str当作base进制,返回10进制的值。
int()魔法示例代码:
# int魔法格式
# int('必选参数str',base=数字(可选))
s = 'z'
r = int(s,base=36)
print(r)
输出:
35
bit_lenth()示例代码
# bit_lenth()不接受参数,它是int对象的方法。
#返回将int值转换成二进制的位数(这里是没有前导0的)
age = 0x8
print(age.bit_length())
输出:
4
以下可以不看的。傻逼老男孩讲那么多自己记得住吗?直接跳过看最后的必须记住的字符串魔法即可。
字符串的魔法:
str.capitalize() 不接收参数,功能:返回将对象首字母大写后的串(并不原地改动,只改动第一个字母)
s = 'faker is a sb'
print(s.capitalize())
输出:Faker is a sb
str.casefold()和lower() 不接收参数,功能:返回将对象小写后的串(并不原地改动)casefold()功能更强大,能把所有有小写的东西都变成小写,lower()只能处理英文字母。
s = 'iHandy'
print(s.casefold())
print(s.lower())
输出:
ihandy
ihandy
str.center(width,fillchar=None) width是必选参数,是一个整型值。 fillchar是个可选参数,默认为空,可以指定一个长度为1的字符串。 功能:返回一个被fillchar填充过的并且将原串居中的总长度为width的字符串。如果左右填充数目不同,则肯定左边填充的多。
str.ljust(width,fillchar=None) str.rjust(width,fillchar=None) 分别是左对齐和右对齐。意思是将原串贴左边还是贴右边。返回值也是一个被填充过的字符串。
s = 'iHandy'
print(s.center(8,'*'))
print(s.ljust(8,'*'))
print(s.rjust(8,'*'))
输出:
*iHandy*
iHandy**
**iHandy
str.count(sub,start=None,end=None) sub是必选参数,是一个长度不限的字符串。start和end是可选参数,是整型值。 功能:返回一个从原串的[start,end)区间的sub出现的次数。
s = 'iHandyiHandy'
print(s.count('dy',4))
输出:2
str.endswith(suffix,start=None,end=None) suffix是必选参数,是一个长度不限的字符串。start和end是可选参数,接收整型值。功能:返回一个布尔值来标识原串是否以suffix串结尾。
s = 'iHandyiHandy'
print(s.endswith('dy'))
输出:True
str.startswith(suffix,start=None,end=None) 功能是返回一个布尔值来标志原串是否以suffix串开头。别的东西和endswith都一样。
str.find(sub,start=None,end=None) sub是必选参数,是一个长度不限的字符串。start和end是可选参数,接收整型值。功能:返回sub串在原串中第一次出现时的下标。如果sub串不在原串中,则返回-1. 同样功能的还有str.index(sub, start=None, end=None) index如果找不到会直接报错。所以我们只用find不用index。
s = 'iHandyiHandy'
print(s.find('dydasdasdasadsadasdasd'))
输出:-1
str.format(*args, **kwargs) *args接收多个无名参数,**kwargs接收多个关键字参数。
何为无名参数?format('faker','sb') 'faker' 和 'sb' 都是无名参数。何为关键字参数?format(name='faker',tag='sb') 这就是关键字参数。 *args用来收集无名参数,**kwargs用来收集关键字参数。功能:用来格式化字符串。功能类似的还有str.format_map(mapping),它接收一个字典。功能同样是格式化字符串。
s = '{name} {age} {tag}'
v = s.format(name='faker',age=18,tag='sb')
print(v)
s1 = '{:.2f}'.format(111.11111)
print(s1)
s2 = '{1} {0} {2}'.format('is','faker','sb')
print(s2)
s = '{name} {age} {tag}'
v = s.format_map({'name':'faker','age':18,'tag':'sb'})
print(v)
输出:
faker 18 sb
111.11
faker is sb
faker 18 sb
str.isalnum() 不接收参数。功能:返回一个布尔值来标识原串是否只包含数字或字母,或者又有数字又有字母。另外,这儿说的字母并不只是英文字母,经过测试,中文字也可以的。
s = 'faker1啊'
print(s.isalnum())
输出:True
str.expandtabs(tabsize=8) 接收一个可选参数,是传入一个int值。默认为8. 函数功能:将原串按tabsize分段,遇到str中的'\t'时,'\t'负责扩充至tabsize的长度。例:如果s = 'fake\tr'.expandtabs(3) 由于'\t'之前有4个字符,3个一组还余1个字符,这1个字符要被'\t'扩充至tabsize,所以'\t'占2个字符位。说的通俗点就是,总工作量就是tabsize , 如果有人跟\t组队,那么\t就少占点;如果没人跟它组队,它就自己占tabsize.用作制表特别好用。
s ='01\t012\t0123\t01234'.expandtabs(4)
print(s.expandtabs())
输出:
01 012 0123 01234
str.isalpha() 不接受参数,返回一个布尔值来标识原串是否只含有字母(不特指英文字母)
st = 'faker is a sb'
print(st.isalpha())
输出:False
str.isdigit() str.isdecimal() str.isnumeric() 不接受参数,返回一个布尔值标识原串是否是纯数字。isdigit可以识别符号的'II' 但是isdecimal就不行了。而且isnumeric能识别中文'二',另外两个不行。
st = '123'
st1 = '②'
st2 = '二'
print(st.isdecimal())
print(st1.isdigit())
print(st1.isnumeric())
输出:
True
True
True
str.isidentifier() 不接受参数,返回一个布尔值标识原串是否符合python标识符的命名规则。
st = 'def'
print(st.isidentifier())
输出: True
str.islower() 不接收参数,返回一个布尔值标识原串是否是小写。
str.lower() 不接收参数,返回把原串转换成小写的字符串。
类似的,还有isupper和upper。
st = 'a'
sss = 'A'
print(st.islower())
print(sss.lower())
输出:
True
a
str.isprintable() 不接受参数,返回一个布尔值标识原串是否有排版控制的字符('\n','\t')等。如果没有,则返回True. 注意,空格会返回True,因为它虽然肉眼不可见,但是它不是排版控制。
st = '\n\t'
s1 = ' '
print(st.isprintable(),s1.isprintable())
输出:False True
str.isspace() 不接受参数,返回一个布尔值标识原串是否全部是肉眼不可见的字符。包括空格,制表符,换行符等。
st = '\n\t'
s1 = ' '
print(st.isspace())
输出:True
str.istitle() 不接受参数,返回一个布尔值标识,原串如果所有单词的首字母都大写且其余字母都小写,则返回True。str.title()不接收参数,返回将一个串变成标准的title串(首字母大写,其余全小写)
st = 'faker is a sb of korAAn'
print(st,st.istitle())
s = st.title()
print(s,s.istitle())
s1 = s + 'AAAAA'
print(s1,s1.istitle())
输出:
faker is a sb of korAAn False
Faker Is A Sb Of Koraan True
Faker Is A Sb Of KoraanAAAAA False
str.join(iterable) 接收一个可迭代对象,并且这个可迭代对象的每一个元素需要是一个字符串。功能:按元素打散iterable,将str插入元素之间的空隙,返回拼接好的字符串。
st = 'fakerisasb'
l = ['a','b']
k = ('1','2','3')
f = {'2','4','6'}
d = {'1':11,'2':22,'3':33}
st1 = '**'
print(st1.join(l))
print(st1.join(st))
print(st1.join(k))
print(st1.join(f))
print(st1.join(d.keys()))
输出:
a**b
f**a**k**e**r**i**s**a**s**b
1**2**3
2**6**4
1**2**3
str.strip(chars) str.lstrip(chars) str.rstrip(chars) 接收一个不限长度的字符串。返回去除两端连续的符合chars里任一元素的字符后的字符串。怎么界定两端?只要有1个字符不再chars里,就可以算不是两端了。
s = ' *#*#***2121***#*# '
print(s.strip('* #1')) # 只要两头的字符在参数的字符串中,就可以去除
s.strip()
输出:212
str.maketrans(str1,str2) str.translate(table) 这两个函数配合使用可以做一个替换功能。
maketrans接收两个参数,第一个是待替换字符串,另一个是替换字符串。返回一个对应表table. translate接受一个对应表参数table,返回用table的规则替换后的字符串。
一定要注意str1的长度应该和str2的长度相同。
s = 'faker say that...'
print(s)
# 创建字符串的替换关系 两个参数分别是 待替换串和替换串
table = str.maketrans('faker','dasbb') # 两个字符串长度要相等
# 接收对应关系参数,返回替换后的字符串
res = s.translate(table)
print(res)
str.partition(str1) str.rpartition(str1) str.split() str.rsplit() 分割字符串。partition 和 rpartition必须接收str类型的参数。返回值是1个包含3个字符串的元组。如果原串中包含str1串,则str1串必定是元组的第二个元素,如果不包含str1串,则元组的第一个元素是原串,第二三个是空串。分割操作只进行一次。partition是从左向右找,rpartition是从右往左找。对于rpartition来说,如果不包含str1串,则元组的第三个元素是原串,第一第二个是空串。
示例代码:
test = 'f123f1'
r = test.partition('f21')
r2 = test.rpartition('f21')
print(r,r2)
test.split()
输出:
('f123f1', '', '') ('', '', 'f123f1')
str.split(str1,int)有两个可选参数。第一个可选参数接收一个字符串,默认值为isspace()的东西。第二个参数接收一个int值,代表分割次数。默认是分割完为止。
split()分割时会把分割标志给去除。返回一个包含被分割后的各字符串的列表。
rsplit()与split()完全一样,只不过是从右往左分割。
示例代码:
test = '\n1234543\n21234543\n21'
print(test.rsplit())
输出:['1234543', '21234543', '21']
str.splitlines(tag=False) tag 是一个可选参数,默认为False. 功能:按照换行符'\n'进行分割。如果tag是True,则在分割时,把'\n'分给前面的字符串。
s = '11\t11\n11'
print(s.splitlines(True))
输出:['11\t11\n', '11']
str.swapcase() 不接受参数,返回将字符串大写字母换小写,小写字母换大写之后的字符串。
s = 'aBc'
print(s.swapcase())
输出:
AbC
必须要记住的字符串魔法:

补充:str.replace(old,new,int=None) 将str中的old子序列替换成new子序列。int默认为None,就是全部替换。也可以指定替换次数。
st = 'guiminYuan say wahaha'
print(st.replace('guiminYuan','vth'))
输出:
vth say wahaha
字符串的灰魔法:
字符串的灰魔法:
- 索引
- 切片
- len
- for循环
- range()
代码示例:
# 索引示例
#python支持两套index。
# 一个是从前往后数,0到n
# 另一个是从后往前数,-1,-2等
s = 'faker'
print(s[0],s[2],s[-1])
# 切片示例
# 切片时有3个参数,starts,ends,step
# step以及它前面的冒号可以不写。
# 但是第一个冒号一定要有
s = 'faker'
s = s[1:3:-1]
s = s[1:3] # 代表切片坐标1(闭区间)到坐标3(开区间)
s = s[1:] # 代表从1到最后
s = s[:3] # 代表从最开始到3 一定要注意,python的区间都是左闭右开的
s = s[::-1] #反转字符串
print(s)
# len()示例
# len()接收一个可迭代对象,返回可迭代对象中元素的个数
print(len('faker'))
# for循环示例
iterable = 'abc'
for i in iterable: # 这里的i指代的就是iterable中的元素
print(i) # 这样取不到下标。
# 想取到下标可以这样
for index,ori in enumerate(iterable):
print('index is :',index,'value is :',ori)
#range()举例
for i in range(5):
print(i,end=' ')
print()
for i in range(1,4):
print(i,end=' ')
print()
for i in range(17,10,-2): #第三个参数是step
print(i,end=' ')
print()
输出:
0 1 2 3 4
1 2 3
17 15 13 11
内存一旦创建不能修改。所以想要修改字符串,只能将字符串调用方法返回给另外一个新的字符串。

















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









