







一、工作流程
1、调度器:从处理器接收的任务队列,在数据库中查找,判断该任务是否为新任务或者需要重新爬取的任务,再根据优先级对任务进行重新排序,再交给抓取器进行处理。
2、抓取器:负责获取网页内容,并将结果发给处理器处理。
3、处理器:主要是负责对数据提取,以及脚本解析(主要用的是PyQuery提取信息)
4、结果工作者result worker(可选):主要是重写数据的储存,默认是存在resultdb中。
5、phantomjs:作用类似scrapy中的中间件,主要用于处理js脚本,返回新的响应内容给fetcher
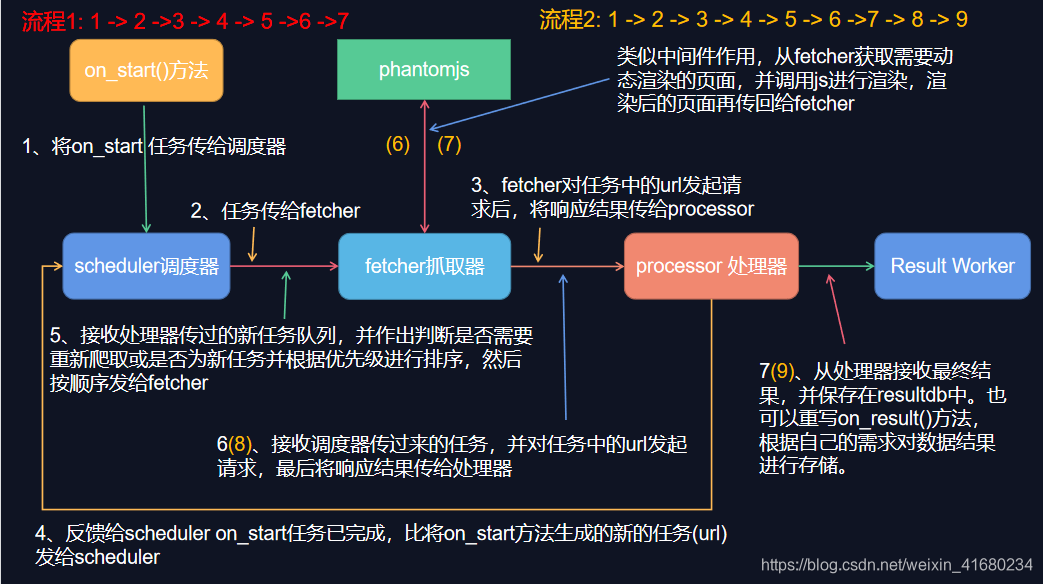 pyspider 中的数据流如上图所示:
pyspider 中的数据流如上图所示:
1、当您按下 WebUI 上的运行按钮时,会执行脚本中的on_start方法,并将on_start 方法作为项目的入口提交给调度器。
2、调度程序将这个带有Data URI 的 on_start 方法作为普通任务分派给 Fetcher。
3、Fetcher 发出请求和响应(对于 Data URI,它是一个虚假的请求和响应,但与其他正常任务没有区别),然后馈送到 Processor,也就是把响应结果发给处理器。
4、处理器调用 on_start 方法并生成一些新的 URL 以进行抓取。 Processor 向Scheduler 发送一条反馈消息,告诉调度器这个任务已经完成,把新的任务通过消息队列发送给Scheduler(这里大多数情况下on_start 没有结果。如果有结果,Processor 将它们发送到result_queue)。
5、调度器接收到新任务,在数据库中查找,判断该任务是新任务还是需要重新爬取,如果是,则放入任务队列。按顺序分派任务给处理器processor。
6、该过程重复(从第 3 步开始)并且不会停止,直到 WWW 死了 😉。调度程序将检查周期性任务以抓取最新数据。
7、当任务队列为空时,也就是没有新的任务时,或者重试失败的时候,会触发on_finshed方法。
# 注意:
1、任务的id默认是md5(url),每个任务有四个状态:活跃、失败、成功、未使用,只有活跃状态的任务才会传给调度器。
2、schedule会对接收的任务的设置的爬取时间以及itag参数进行判断,若爬取时间未到,或者itag没有变化,则会抛弃该任务。
二、常见的问题
1、解决 web界面太小问题
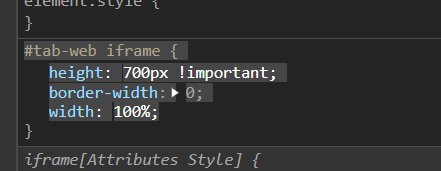
(1)解决方法1:在浏览器按F12修改css值,给iframe标签添加 heights :700px ! important,高度可以自己随意设置
注意:这个方法是一次性的,下次重新打开需要重新设置
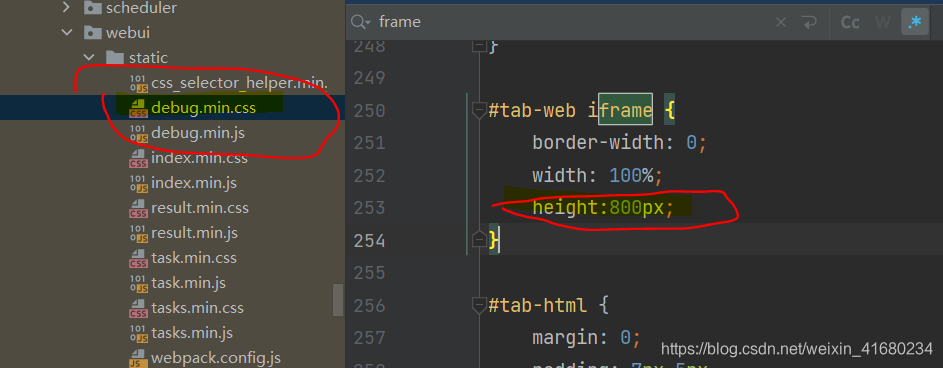
(2)解决方法2:直接修改pyspider源码中的css文件
2、559证书问题
暂时只知道在全局配置或者在crawl中添加 validate_cert属性:validate_cert=False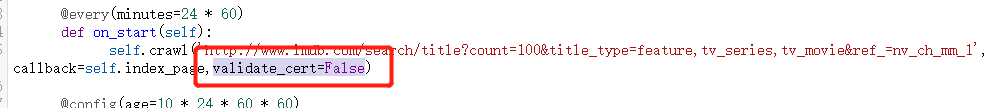
3、爬取速度慢问题
可以通过设置rate/burst比值,rate是每秒爬取的数量 burst是并发数量,设置要爬取网站是否有频率限制。
4、参数传递问题
pyspider函数之间传递参数是用save参数,而不是scrapy中的meta参数
5、web界面run一次后,后面就爬不到内容了
原因:on_start上的装饰器限制了,装饰器规定多久爬一次,另外,pyspider中有一个参数,itag用来做任务标记,当itag重新改变时,执行脚本,它会重新抓取,没有改变时,则不会重新抓取,默认值是:无
6、web界面中results 看不到爬取结果?
原因:重写了on_result方法,导致数据存在我们指定的位置,没有保存再resultdb中,所以,才导致看不到。
三、其他知识点
任务
1、任务的id默认是md5(url),每个任务有四个状态:活跃、失败、成功、未使用,只有活跃状态的任务才会传给调度器。
2、schedule会对接收的任务的设置的爬取时间以及itag参数进行判断,若爬取时间未到,或者itag没有变化,则会抛弃该任务。
3、当抓取器或脚本报错时,默认会重试三次,每次重试时间不一样,默认第一次重试是在30s后,第二次是在1h后,第三次是在6h后,第四次是在12h后
可以在脚本中添加retry_delay参数,用来自定义重试时间
retry_delay = {
0: 30,
1: 1*60*60,
2: 6*60*60,
3: 12*60*60,
'': 24*60*60
}
API
1、scrawl方法:
# ----------------常用参数----------------
priority:优先级,值越高越好,默认是0
exetime:执行时间,就是任务什么时候执行
itag: 标签,发生改变时会重新爬取数据,默认值为无
# 例子
self.crawl(url,callback=self.test, priority=1,exetime=time.time()+30*60,itag=time.find('.update-time').text())
# 优先级为1,将在当前时间30分钟后执行,以样式为update-time元素的文本为标签值
age:定时时间,也可在index_page函数上的装饰器@config中配置
'''
auto_recrawl:定时时间到,自动启动脚本重新爬取 ,默认:False
method:请求方法,默认是 GET
params:url参数字典,一般用在get请求
data: post请求的数据参数
files:文件参数,{filed:{filename:'content'}}以字典形式分段上传,一般用于post请求
'''
#-例子: http://httpbin.org/get?a=123&b=c
self.crawl(url,callbask=self.callback,params={'a':123,'b':'c'})
'''
user_agent、headers、cookies:浏览器标识,请求头,cookies值
connect_timeout: 连接超时时间,默认是20s
timeout: 超时时间,也就是获取页面最长时间,默认是120s
allow_redirects:遵循30x(300家族状态码)重定向,默认是True
validate_cert: https请求证书,默认是True,也就是需要验证证书
'''
proxy: 代理参数,目前仅支持http代理
# 例子:
self.crawl(url,callback=self.callback,proxy="192.168.10.131:8080")
'''
etag:http的缓存机制,默认是True,当请求的页面内容没变时,使用上次请求留下来的本地缓存。
last_modified:http的缓存机制,与etag类似,默认是True
'''
fetch_type: 抓取方式,默认值为None,设置为js,则启用javascript fetcher 抓取
js_script:脚本内容
# 例子
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
fetch_type='js', js_script='''
function() {
window.scrollTo(0,document.body.scrollHeight);
return 123;
}
''')
'''
js_run_at:js脚本执行时间,有document-start 和 document-end两个选项,默认是document-end,文档结束后
js_viewport_width/js_viewport_height:设置js窗口大小
load_imgaes: 用js渲染加载的时候是否加载图像,默认是:False
'''
save: 用于传递参数,类似scrapy中meta参数
# taskid: 任务id,默认是url的md5值,可以重写get_taskid方法,获取taskid值
import json
from pyspider.libs.utils import md5string
def get_taskid(self, task):
return md5string(task['url']+json.dumps(task['fetch'].get('data', '')))
force_update:强制升级参数,true/false
cancel: 取消任务,搭配force_update和auto_recrawl两个参数一起用(false)
# 将装饰器里面的配置作为self.crawl参数
@config(age=15*60)
def index_page(self, response):
# age是15*60, 也就是回调函数index_page装饰器的age
self.crawl('http://www.example.org/list-1.html', callback=self.index_page)
# age是10*24*60*60,也就是回调函数detail_page装饰器的age
self.crawl('http://www.example.org/product-233', callback=self.detail_page)
@config(age=10*24*60*60)
def detail_page(self, response):
return {...}
#整个项目配置的crawl_config,crawl以上配置都可以放在crawl_config中。
crawl_config={
'itag':'v233', # 标签配置
'proxy':'192.168.10.131:8080' # 代理
}
2、response响应参数:
# 获取响应内容的三个方式
response.text # 响应内容为文本形式,Unicode格式
response.content # 响应内容为字节形式
response.doc # 响应内容为PyQuery对象
response.etrr # 响应内容为 lxml对象
response.json # 响应内容为json格式
# 其他参数
response.status_code # 响应状态码
response.orig_url # 响应源链接,也就是请求url
response.headers # 响应头,以字典的形式保存
response.cookies # cookies值
response.error # 获取错误时的信息,正确则为None
response.time # 响应时间
response.ok # 判断响应是否成功,是布尔值
response.encoding # response.content的编码
response.save # 传递参数
response.js_script_result # js脚本返回的内容
response.raise_for_status() # 当出现错误,或状态码不是200的时候,捕获错误
装饰器:
@catch_status_code_error ,主要是解决非200响应的请求。
pyspider遇到非200响应请求是不会走回调函数的,在回调函数上添加装饰器@catch_status_code_error,那么,即使请求失败,它也会执行回调函数
@every装饰器受age影响,如果未到定时时间,即使触发抓取请求,请求也会被舍弃。
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.example.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self):
...
扩展
pip inistall --allow-all-external pyspider[all]
# window下会报错,直接用pip iinstall pyspider[all] 则不会,pyspider[all]是对数据库的支
`

















 1973
1973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









