







 LRU(Least Recently Used)是缓存系统常用的页面替换算法,用于提高访问速度。文章通过实例解释了LRU的工作原理,展示了如何在内存有限的情况下决定何时替换缓存中的数据。缓存设计的目标是解决内存和磁盘速度差异问题,当内存不足时,LRU会选择最久未使用的数据进行替换。文中提到了两种LRU实现方式:挪动位置法和双向链表+哈希表,后者在时间复杂度上有优势,能达到O(1)。最后,作者提供了LeetCode的LRU Cache题目链接供读者实践。
LRU(Least Recently Used)是缓存系统常用的页面替换算法,用于提高访问速度。文章通过实例解释了LRU的工作原理,展示了如何在内存有限的情况下决定何时替换缓存中的数据。缓存设计的目标是解决内存和磁盘速度差异问题,当内存不足时,LRU会选择最久未使用的数据进行替换。文中提到了两种LRU实现方式:挪动位置法和双向链表+哈希表,后者在时间复杂度上有优势,能达到O(1)。最后,作者提供了LeetCode的LRU Cache题目链接供读者实践。
LRU是Least Recently Used的缩写,即最近最少使用,也叫最近最久未使用,最初应用于操作系统的页面置换算法。当发生缺页中断后,选择将最久未使用的那一个页面替换出去。实践表明,LRU可以最大化页面页面利用率。LRU除了应用在操作系统层面,常被应用到缓存系统的设计中,很多著名的缓存系统,比如iOS中的YYCache、远程字典服务Redis中都使用了LRU。
那么为什么要设计缓存系统呢?因为磁盘的访问速度要比内存的访问速度慢很多,如果所有数据都存储在磁盘上访问的时延会很大,而所有数据都存放到内存里内存又有可能不够,而且内存中的数据断电后就会被清除。当然,有访问时间存在差异的地方都可以做缓存,不一定是磁盘与内存。缓存系统设计的最主要的目的,就是加快访问速度降低时延。
为了清楚的说明LRU所做的事情,我们先举个例子。
我们假设内存一共就可以存放3个节点,其余的节点存放在磁盘上或者在服务器上(其余的节点存放在那里读者其实不用关心)。现在我们给节点编号,并依次访问以下编号的节点。
依次访问1、2、3、2、1、4、5、2;
我们把最左边的节点当作最近访问的节点,最右边的节点当作最久未使用的节点。
第一次访问的是1,此时内存中还是空的,直接将1加入即可,加入后内存中是:
[1];
第二次访问的是2,此时内存中有1个节点,还没有达到内存的最大容量3,因此也可以直接加入,加入后内存中是:
[2,1];
第三次访问的是3,此时内存中有2个节点,还没有达到内存的最大容量3,因此还可以直接加入,加入后内存中是:
[3,2,1];
第四次访问的是2,我们通过查找内存中的节点发现,2已经在内存中了,我们只需要挪动一下位置,把2放到最近使用的位置(最左边的位置),其余节点的相对位置保持不变:
[2,3,1];
第五次访问的是1,我们通过查找内存中的节点发现,1也已经在内存中了,我们只需要挪动一下位置,把1放到最近使用的位置(最左边的位置),其余节点的相对位置保持不变:
[1,2,3];
第六次访问的是4,我们通过查找内存中的节点发现,4还不在内存中(如果在操作系统的角度看,此时就是发生了缺页中断),我们需要将4加入内存中,但是此时内存中的节点数已经达到内存的最大容量3了,因此必须替换出去一个。根据LRU算法,应该把最久未使用的3替换出去,然后将4加入放到最近使用的位置,其余节点的相对位置保持不变:
[4,1,2];
第7次访问的是5,我们通过查找内存中的节点发现,5还不在内存中(如果在操作系统的角度看,此时就是发生了缺页中断),我们需要将5加入内存中,但是此时内存中的节点数已经达到内存的最大容量3了,因此必须替换出去一个。根据LRU算法,应该把最久未使用的2替换出去,然后将5加入放到最近使用的位置,其余节点的相对位置保持不变:
[5,4,1];
第8次访问的是2,虽然2曾经存在于内存中,但是其已经被替换出去了,此时仍然发生了缺页中断,因此需要把1替换出去,把2放到最近访问的位置,其余节点的相对位置保持不变:
[2,5,4]。
知道了LRU是什么后,剩下的就是设计LRU了。根据上面的例子,我们可以很容易地设计出这个缓存系统。缓存没满就直接往里加,缓存没满就挪动节点,保证最近访问的节点在最近访问的位置即可。
第一种方法:挪动位置法
这种方法本质上比较暴力,但是相对于其他暴力方法,这种暴力方法通过了LeetCode的测试。
数据上我们采用C++的map(底层是用红黑树实现的)kv存放键值对,整型cache数组存放缓存中所有的key,最近访问的位置为cache数组的最后一个位置,最久未访问的位置为cache数组的第一个元素,capacity为缓存的容量,size为缓存中已存在节点的数量。
map<int, int> kv;
vector<int> cache;
int capacity;
int size;初始状态下size的值是0,kv中没有键值对,cache中也没有元素。
如果想要拿到某个key的值,就调用get函数——get(key)。
传入key后,我们可以在kv中根据key查找,如果kv中没有以key为键的键值对,就可以直接返回-1了,表示在LRU缓存中找不到以key为键的键值对。
if (kv.find(key) == kv.end()) {
return -1;
}由于map的底层是红黑树实现的,因此查找效率比较高,查找的时间复杂度为log(n)。
如果查找到了以key为键的键值对,那么就可以直接通过kv[key]得到其值然后返回。但是,在返回之前我们还需要调整位置,因为当前最近访问的节点变成了以key为键的键值对,因此需要调整cache数组,把key放到cache数组的最后一个位置上。
int pos = -1;
//寻找当前key在cache数组中的位置pos
for (int i = 0; i < size; i++) {
if (cache[i] == key) {
pos = i;
break;
}
}
//pos后面的元素都前移一格
for (int i = pos; i < size - 1; i++) {
cache[i] = cache[i + 1];
}
cache[size - 1] = key;
return kv[key];
整个get方法就可以如此设计:
int get(int key) {
if (kv.find(key) == kv.end()) {
return -1;
}
else {
int pos = -1;
for (int i = 0; i < size; i++) {
if (cache[i] == key) {
pos = i;
break;
}
}
for (int i = pos; i < size - 1; i++) {
cache[i] = cache[i + 1];
}
cache[size - 1] = key;
return kv[key];
}
}如果想要加入新的键值对,就调用put函数——put(key, value)。
需要注意的是,加入新的键值对还有可能是更新某个键的值的情况,比如kv中原本有一个键值对{1,2}了,用户突然调用了{1,3},此时需要将键1对应的值修改为3。修改某个键值对的值也算是访问某个key了,因此仍然需要做LRU相关的位置调整,这个我们无需再考虑,因为我们已经实现了为访问量身定制的get方法。只需要kv[key] = value,然后get(key)。
if (kv.find(key) != kv.end()) {
kv[key] = value;
get(key);
}那么如果put进来的是一个全新的键值对又应该做何处理呢?
这取决于缓存中已有节点的个数和缓存最大容量的关系。如果已有节点的个数size小于缓存最大容量capacity,说明此时缓存还没满,可以直接将键值对加入到最近访问的位置,即将key直接push到cache数组的末尾,然后在红黑树kv中加入这个键值对,最后不要忘记增加size。
kv[key] = value;
cache.push_back(key);
size++;如果已有节点的个数size大于等于缓存最大容量capacity,说明此时缓存已满,需要将最久未使用的键值对替换出去。最久未使用的key在cache数组的第一个位置(下标为0的位置),我们需要先在红黑树中删除这个键值对,然后挪动cache数组(将cache数组剩余的全部元素左移一格),最后不要忘记将新的键值对加入红黑树以及将新的key放到cache数组的最后一个位置。
//在红黑树中删除被换出的键值对
kv.erase(cache[0]);
//将cache数组剩余的全部元素左移一格
for (int i = 0; i < size - 1; i++) {
cache[i] = cache[i + 1];
}
//将新的key放到cache数组的最后一个位置
cache[size - 1] = key;
kv[key] = value;整个put方法就可以如此设计:
void put(int key, int value) {
if (kv.find(key) != kv.end()) {
kv[key] = value;
get(key);
}
else {
kv[key] = value;
if (size < capacity) {
cache.push_back(key);
size++;
}
else {
kv.erase(cache[0]);
for (int i = 0; i < size - 1; i++) {
cache[i] = cache[i + 1];
}
cache[size - 1] = key;
}
}
}
以上方法LRU实现方案无论是get方法还是put方法,由于涉及挪动数组元素,因此时间复杂度都是O(n)。
第二种方法:双向链表+哈希表
这种方法在时间复杂度上相比前面的挪动位置法有着质的提升。

get方法和put方法的时间复杂度都能达到常量级别。下面就来告诉大家是怎么做到的。
双向链表是一种特殊的链表,与单链表相比,每个节点含有两个指针,除了有一个指向后序节点的指针外,还有一个指向前向节点的指针。在一个单链表中,得到一个节点就可以得到它后面的节点。而在双向链表中,得到一个节点不仅可以得到它后面的节点,还可以得到它前面的节点。
既然是双向链表实现,我们需要先定义链表节点:
struct ListNode {
int key;
int val;
ListNode *left;
ListNode *right;
ListNode(int k, int v):key(k), val(v), left(NULL), right(NULL) {}
};既然想要达到常量时间复杂度的查询,我们可以想一想所有加快查询速度的方法都有哪些。第一种方法中提到的红黑树是一种提升查询速度的方法,红黑树类似于二叉搜索树或者说平衡二叉树(AVL树),其查询也有点类似二分搜索,其时间复杂度是O(log(n)),本质上是二分,达不到常量级别。那么剩下的,就是哈希表了,哈希表的查询速度几乎可以达到常量级别。
哈希表在C++中叫unordered_map,用法几乎与map一样,可以根据key得到value,但需要注意的是,我们在这里用到的unordered_map可不是用来存储LRU的key和value的,而是用来根据key找到双向链表节点的。因为根据key找到了某个节点,我们就可以很容易地拿到它左边的节点和右边的节点,然后就可以轻松地把某个节点“摘”下来,放到最近访问的位置。
哈希表定义:
unordered_map<int, ListNode *> mp;缓存中已有节点的个数和缓存最大容量的定义:
int size;
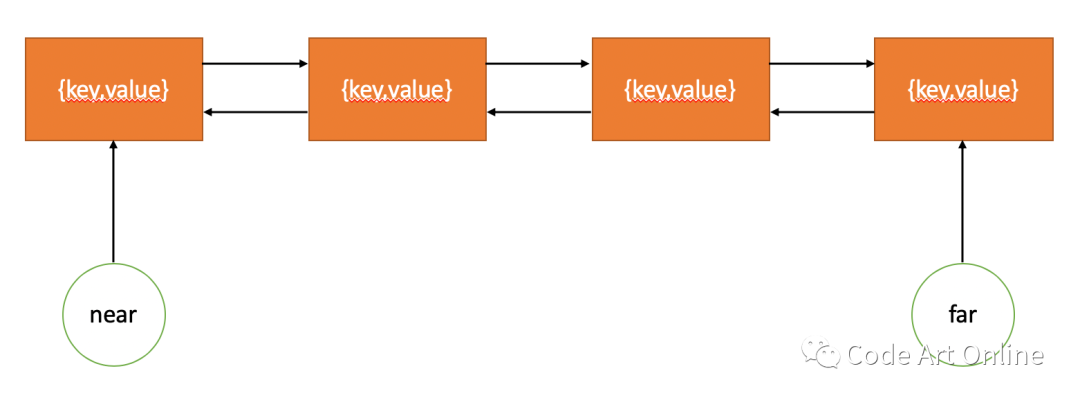
int capacity;near代表最近使用的节点(双向链表最左边的节点,也可以理解为头节点,每次插入都插入到头节点),far代表最久未使用的节点(双向链表最右边的节点)。
ListNode *near;
ListNode *far;初始状态:
size = 0;
near = NULL;
far = NULL;整个LRU缓存可以描述为下图所示:
先来实现比较简单的get函数——get(key)。
我们可以通过哈希表mp直接找到key对应的双向链表节点,顺理成章就能得到其value。如果mp[key]是空的,那么就是哈希表中没有key对应的节点,可以直接返回-1。
if (mp[key] == NULL) {
return -1;
}如果mp[key]不是空的,那么mp[key]的值就是key对应的节点。通过mp[key]->left可以得到key对应的节点在双向链表中的左侧节点,通过mp[key]->right可以得到key对应的节点在双向链表中的右侧节点。在理想状态下,通过mp[key]->left->right = mp[key]->right和mp[key]->right->left = mp[key]->left就可以顺利地将mp[key]给“摘下来”,mp[key]左边的节点的右侧节点指针指向mp[key]右边的节点,mp[key]右边的节点的左侧节点指针指向mp[key]左边的节点,实现了mp[key]左右侧节点的无缝拼接。
但是我们还要考虑极端情况,比如mp[key]就是最近访问的节点,那么mp[key]->left就是空的,此时其实可以直接返回不做任何操作了,因为mp[key]已经在最近访问的位置上了。
另一种极端情况就是mp[key]是最久未使用的节点,那么mp[key]->right就是空的,此时如果再访问mp[key]->right->left就会导致程序崩溃了。因此我们需要特判一下mp[key]->right是否为空。更为重要的是,mp[key]如果是最久未使用的节点,访问mp[key]后其会变成最近使用的节点,因此far指针需要指向mp[key]左侧的节点。
ListNode *node = mp[key];
if (node->left != NULL) {
node->left->right = node->right;
}
else {
//node就是near
return node->val;
}
if (node->right != NULL) {
node->right->left = node->left;
}
else {
//node就是far
far = far->left;
}不要忘记将即将变成最近使用节点的节点的左侧节点指针置为空。
node->left = NULL;更新最近访问的节点。需要注意的是,我们是在操作双向链表,要同时保证每个节点的left和right都是有效的,一般更新都会涉及两个方向上的更新。
node->right = near;
near->left = node;
near = node;整个get方法就可以如此设计:
int get(int key) {
if (mp[key] == NULL) {
return -1;
}
ListNode *node = mp[key];
if (node->left != NULL) {
node->left->right = node->right;
}
else {
//node就是near
return node->val;
}
if (node->right != NULL) {
node->right->left = node->left;
}
else {
//node就是far
far = far->left;
}
node->left = NULL;
node->right = near;
near->left = node;
near = node;
return node->val;
}
我们再来实现put方法。情况也是主要分为三种考虑,第一种是只键值对已经存在于缓存中了,只是更新key对应的value;第二种情况是缓存还未满;第三种情况是缓存已满。
对于第一种情况,更新key对应的value后再调用一下get(key)即可。调用get(key)只有一个目的,就是在不影响其他节点相对位置的情况下将mp[key]放到缓存最近访问的位置。
if (mp[key] != NULL) {
mp[key]->val = value;
get(key);
}缓存未满就是缓存中已有节点的个数小于缓存的最大容量,对于这种情况只需要在头节点处插入键值对。需要注意的是,如果是插入的第一个键值对节点,整个缓存的near指针和far指针还都是空的,因此需要特殊处理插入第一个键值对节点的情况,让near和far都指向这个新插入的键值对节点。对于其他情况直接在头节点处将新键值对节点插入即可,不要忘记更新near节点和让size增加。
ListNode *node = new ListNode(key, value);
mp[key] = node;
if (size == 0) {
//让near和far都指向新插入的键值对节点
near = far = node;
}
else {
near->left = node;
node->right = near;
near = node;
}
size++;对于缓存已满的情况,先将新的键值对节点插入到头节点,并更新near指针让其指向新插入的键值对节点。
ListNode *node = new ListNode(key, value);
mp[key] = node;
node->right = near;
near->left = node;
near = node;还需要释放掉最久未使用的节点。最久未使用的节点就是far指向的节点,我们可以用一个临时ListNode型的指针变量指向far指向的节点。然后开始调整near指针,让其指向其左侧的节点
ListNode *temp = far;
far->left->right = NULL;
far = far->left;不要忘记置空key对应的节点地址,因为其指向的节点即将被释放,如果不置空会造成程序运行崩溃的风险。
mp[temp->key] = NULL;释放被换出的节点。
delete temp;
temp = NULL;整个put方法就可以如此设计:
void put(int key, int value) {
if (mp[key] != NULL) {
mp[key]->val = value;
get(key);
}
else {
if (size >= capacity) {
ListNode *node = new ListNode(key, value);
mp[key] = node;
node->right = near;
near->left = node;
near = node;
//此时缓存已经满了
ListNode *temp = far;
far->left->right = NULL;
far = far->left;
mp[temp->key] = NULL;
delete temp;
temp = NULL;
}
else {
//缓存还没满
ListNode *node = new ListNode(key, value);
mp[key] = node;
if (size == 0) {
near = far = node;
}
else {
near->left = node;
node->right = near;
near = node;
}
size++;
}
}
}之所以双向链表+哈希表的get操作和put操作都可以在O(1)的时间内完成,是因为哈希表哈希查找key对应的键值对节点操作的时间复杂度几乎可以认为是O(1);而找到某个键值对节点直接就能找到该键值对节点的左右节点,因此衔接左右键值对节点的操作也可以在O(1)的时间复杂度内完成;插入键值对节点是往头节点插入,因此该操作操作也可以在O(1)的时间复杂度内完成。综上所述,总的时间复杂度还是O(1)。
大家如果想测试自己写的代码,请访问以下地址:
https://leetcode-cn.com/problems/lru-cache/
大厂的应届生秋招已经开始了,笔者在某大厂的应届生面试中被问到了LRU,因此写了这么一篇文章与同在求职的你分享。祝愿大家在秋招都能收割想要的offer,成为offer收割机。
欢迎大家关注/订阅我的微信公众号Code Art Online,我会在我的公众号分享个人见闻,发现生活趣味;这里不仅有0和1,还有是诗和远方↓↓↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









