




 机器学习模型的性能评估包括ROC曲线和AUC,它们反映了学习器的泛化能力。ROC曲线通过假正例率和真正例率展示模型性能,AUC作为其下的面积,表示分类效果。此外,代价敏感错误率引入代价矩阵,以适应不同任务的代价需求,最小化总体代价成为优化目标。
机器学习模型的性能评估包括ROC曲线和AUC,它们反映了学习器的泛化能力。ROC曲线通过假正例率和真正例率展示模型性能,AUC作为其下的面积,表示分类效果。此外,代价敏感错误率引入代价矩阵,以适应不同任务的代价需求,最小化总体代价成为优化目标。
对机器学习的泛化性能进行评估,不仅需要切实可行的实验估计方法,还要有衡量模型泛化能力的评价标准,即性能度量。它反映了任务需求,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果;因此,模型的选择与性能的好坏不仅取决于算法和数据,还取决于任务的需求。
一般,对于回归任务来说,性能度量有“均方误差”,那对于分类任务来说,性能度量有错误率和精度;查准率(准确率)、查全率(召回率)与F1;
1 关于ROC与AUC:
很多学习器是为测试样本产生一个实值或者概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,若大于阈值则为正类,反之,为反类。如,神经网络在一般情形下是对每个测试样本预测出一个[0.0,1.0]之间的实值,然后将这个值与0.5进行比较,大于0.5则判为正例,否则为反例,这个实值或概率预测结果的好坏,直接决定了学习器的泛化能力。
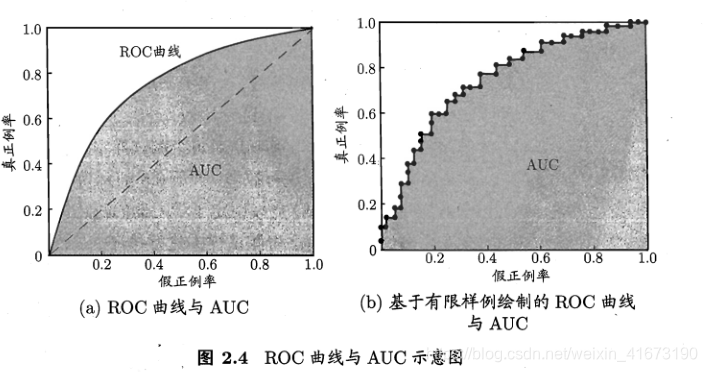
在不同的任务中,可根据任务需求来采用不同的截断点,如果重视准确率,则可以选择排序中靠前的位置进行截断;如果重视召回率,那么可以选择靠后位置进行截断。需要注意的时,排序本身质量的好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏。此时ROC曲线能体现学习器泛化性能的好坏。
ROC全称“受试者工作特征”曲线,它源于“二战”中用于敌机检测的雷达信号分析技术,二十世纪六七十年代开始被用于一些心理学、医学检测应用中,伺候应用于机器学习领域。以假正例率(FPR)为横坐标,真正率(TPR)为纵轴。ROC曲线下的面积,即为AUC。
2.代价敏感错误率与代价曲线
以二分类为例,设定一个代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









