







case when 填充null值
case when t1.operstatus is null then 0 else operstatus end as operstatus_new
交易时间与注册时间差(时间戳)
select t1.orderid,
unix_timestamp(t1.transtime,"yyyy-MM-dd HH:mm:ss") - unix_timestamp(t2.opertime,"yyyy-MM-dd HH:mm:ss") time_internal
from t1
left join t2
on t1.paycustuserid = t2.userid
交易时间与注册时间差是否小于xx分钟
select t1.orderid,
case when t1.time_internal>0 and t1.time_internal <30*60 then 1
when t1.time_internal>30*60 and t1.time_internal <60*60 then 2
when t1.time_internal>60*60 and t1.time_internal <6*60*60 then 3
when t1.time_internal>6*60*60 and t1.time_internal <24*60*60 then 4
when t1.time_internal>24*60*60 and t1.time_internal <7*24*60*60 then 5
else 0 end as time_internal_bin
from t1
lag()与 lead()取前几行或后几行
这种操作可以用表的自连接实现,但是LAG和LEAD与left join、rightjoin等自连接相比,效率更高,SQL更简洁。
函数语法如下:
lag(exp_str,offset,defval) over(partion by ..order by …)
lead(exp_str,offset,defval) over(partion by ..order by …)
select t1.*,
row_number()over(partition by t1.paycustuserid order by t1.paycustuserid,t1.transtime) seq,
lag(t1.transtime,1,t1.transtime)over (partition by t1.paycustuserid order by t1.paycustuserid,t1.transtime)as last_time,-----------------lag时间
lag(t1.transamount,1,t1.transamount)over (partition by t1.paycustuserid order by t1.paycustuserid,t1.transtime)as last_amount-----------------lag金额
from t1
order by t1.paycustuserid,t1.transtime
计算时间差,相同金额
select t1.orderid,t1.transamount,floor(transamount) transamount_new,
,case when substring(transamount/1000,length(transamount/1000),1) ='9' then 1 else 0 end as trans_cnt
--末位
,case when substr(transamount/1000,length(floor(transamount/1000))-1,2)='99'
then 1 else 0 end as trans_99_cnt
--取整后的后两位
from t1
统计交易时间(小时/月份/日期)
select substring(transtime,12,2) time,count(*) hh
from t1
group by substring(transtime,12,2)
order by hh desc
统计每个月黑样本
select substring(transtime 1,7) time,
count(*) total_num,
sum (case when label = 1 then 1 else 0 end ) black_num,
sum (case when label = 1 then 1 else 0 end ) white_num,
from ebank_order1
group by substring(transtime 1,7)
order by substring(transtime 1,7)
统计分位点
percentile(cast(transamount as bigint),0.25) as 25per,
percentile(cast(transamount as bigint),0.5) as 50per
percentile_approx(transamount,double(0.8),999999) as ad ----近似分位点
截取
where substring(reverse4,1,length(reverse4)-1) = '石家庄'
left(reverse4,length(reverse4)-4)
trim/rtrim/ltrim
代码review
1、注意去重、填充空值,表名、字段名是否正确
2、status<>99删除取max后group by(注册状态去重)时间差
3、分类问题,特征要有区分黑白样本的能力
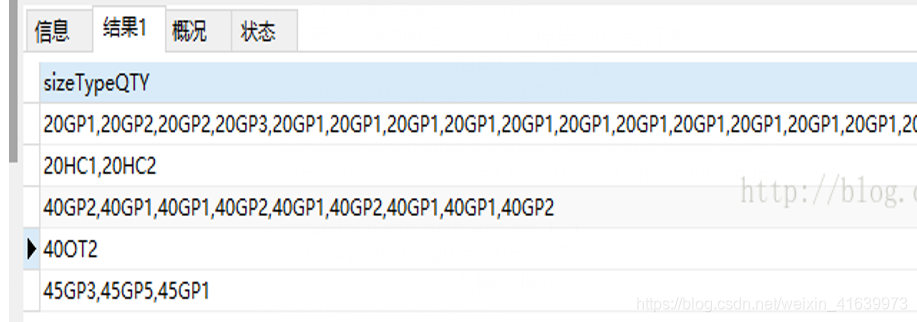
MYSQL GROUP_CONCAT()函数
GROUP_CONCAT函数返回一个字符串结果,该结果由分组中的值连接组合而成。常和groupby连用
效果如下:
方差、标准差
变异系数
排序去重
关于样本方差,总体方差
方差公式:
m为x1,x2…xn数列的期望值(平均数)
s^2 = [(x1-m)^2 + (x2-m)^2 + ... (xn-m)^2]/n
s即为标准差,s^2为方差。
1、当我们需要真实的标准差 方差的时候 最好是使用: stddev stddev_pop var_pop
2、而只是需要得到少量数据 标准差 方差 的近似值 可以选用: stddev_samp var_samp
stddev_samp :
s^2 = [(x1-m)^2 + (x2-m)^2 + ... (xn-m)^2]/n-1
样本方差之所以要除以(n-1)是因为这样的方差估计量才是关于总体方差的无偏估计量
这个公式是通过修正下面的方差计算公式而来的:
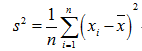
修正过程为:
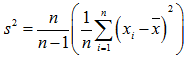
我们看到的其实是修正后的结果:
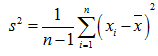
当然,还有一种比较直接的解释,由于是求样本中的方差,所以在求解样本均值时,已经用掉了一个自由度的值,
所以求方差时,其实有用的值会少一个。例如在只有一个样本时,这时求样本方差是不能估计总体方差的。
所以,总体方差和样本方差的区别是在于信息量,总体的信息是完全确定的,即这时求出来的统计参数都是能确定地表征总体的分布信息。
但是用样本的信息去估计总体,则不能确定表征总体的分布信息,之间相差了一个自由度。
SQL 行转列的两种做法—case when / pivot
SQL 行转列的两种做法
if object_id('tb')is not null drop table tb
Go
create table tb(姓名 varchar(10),课程 varchar(10),分数 int)
insert into tb values('张三','语文',74)
insert into tb values('张三','数学',83)
insert into tb values('张三','物理',93)
insert into tb values('李四','语文',74)
insert into tb values('李四','数学',84)
insert into tb values('李四','物理',94)
go
select * from tb
-- 使用case when (SQL2000以上)
select 姓名,
max(case 课程 when '语文' then 分数 else 0 end)语文,
max(case 课程 when '数学'then 分数 else 0 end)数学,
max(case 课程 when '物理'then 分数 else 0 end)物理
from tb
group by 姓名
-- 使用pivot
select * from tb pivot(max(分数) for 课程 in (语文,数学,物理))a
– 另外也可以通过写存储过程实现,但比较麻烦。

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









