







文章目录
一、背景
前端领域中关于异步的知识对架构师而言非常重要,未来的趋势前端很多工作是设计 pipeline 串各个服务和数据的推进器,我们需要和各个服务打交道就必然会有各种异步处理,今天让我们一起看看前端中的异步
二、JS 单线程设计原因
JavaScript 最初设计为在浏览器中运行,处理的主要任务是操作 DOM、处理用户事件和发送 Ajax 请求等,这些任务都不需要大量的计算和并发,因此单线程模型是足够的,也可以避免复杂的并发问题。虽然js是单线程,到那时浏览器调用js是通过两个线程来执行的。
如果 JavaScript 是多线程的,那么就可能出现两个线程同时操作 DOM 的情况,这将导致非常复杂的同步问题。为了避免这些问题,JavaScript 选择了单线程模型,所有操作都在一个事件循环中串行执行。
在某些情况下,JavaScript 仍然可以利用多线程。例如,Web Workers API 允许你创建并行的工作线程,这些线程可以在后台运行,不会影响用户界面。但是,工作线程不能访问主线程的上下文,例如 DOM,因此避免了并发操作 DOM 的问题。此外,Node.js 提供了 worker_threads 模块,也可以创建多线程
三、浏览器事件循环机制
我多年面试别人经历中,提起异步,基本会先追问一下事件循环机制。有的同学会提到V8,有的会说到浏览器里 event loop。在这里做个概念上的解释。
首先 js 本是一个解释性的语言,的确他的各种机制表现是需要相对于js运行环境而言的。最常见的就是 浏览器和node,当然现在一些native,甚至智能家居都会在上层选用js来解释一些行为,那这个就不在今天的讨论范围了。
至于有的同学提到的 V8,它是一个 JavaScript 引擎,它主要负责解析和执行 JavaScript 代码。V8 本身并没有事件循环机制,它只是执行 JavaScript 代码的一个环境,这些概念需要分清楚。
而事件循环(Event Loop)是 JavaScript 运行环境(如浏览器或 Node.js)的一部分,负责协调 JavaScript 代码的执行和异步事件(如定时器、网络请求等)的处理。因此,说到事件循环,实际上是 JavaScript 运行环境的事件循环,不是 V8 的事件循环。
当然在浏览器和 nodeJS 事件中循环机制的作用是有些不同的,接下来我们分类讨论
1. 浏览器环境
浏览器的事件轮询(Event Loop)是它执行代码、处理事件以及执行渲染的机制。它主要是基于 JavaScript 的单线程运行机制,以及它的非阻塞I/O和异步能力。
浏览器双线程渲染
首先先说一下浏览器使用到js解释浏览器行为的地方。浏览器为了处理 GUI 渲染任务、用户交互事件、网络请求等异步事件,以及 JavaScript 代码的执行通过两个线程来实现。主线程和 event loop 线程是一种数据结构,用来等待和发送消息。另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为"Event Loop线程"(可以译为"消息线程")。
引用掘金社区的两张图,个人觉得说的也比较形象
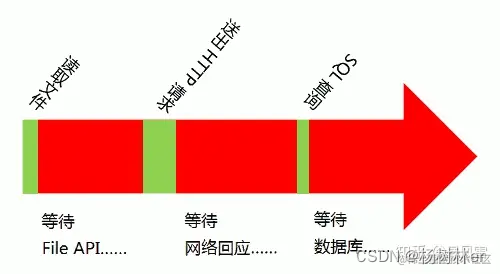
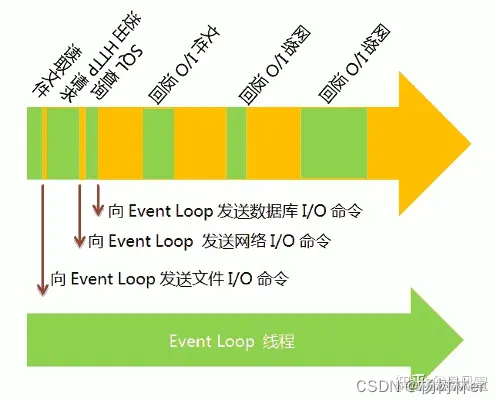
宏任务和微任务
JavaScript 中的宏任务(MacroTask)和微任务(MicroTask)是事件循环机制的重要组成部分。它们的概念源自于 HTML5 标准中的任务(task)和微任务(microtask)。
宏任务(MacroTask)
宏任务,有时也称为任务,是最大的异步执行单位。常见的宏任务是
- 整体代码 script(可以理解为同步代码)
- setTimeout
- setInterval
- setImmediate (Node.js 环境)
- requestAnimationFrame
- I/O
- UI rendering
每个宏任务在执行时,都会生成一个执行环境。
微任务(MicroTask)
微任务是在当前 task 执行结束后立即执行的任务,微任务的响应速度相比宏任务更快,因为无需等待下一轮事件循环。在浏览器环境中,常见的微任务有:
- Promise 的 then 和 catch
- process.nextTick (Node.js 环境)
- MutationObserver
事件轮循过程
总结了一下分为6个步骤:
- 首先,浏览器会将同步的代码任务例如,简单的 JavaScript 代码,如函数或者变量声明)放入主线程中去执行。
- 对于那些异步任务(例如,setTimeout,Promises,fetch等),他们会被推送到任务队列(Task Queue)或微任务队列(Microtask Queue)。
- 当主线程中的所有同步任务都完成时,浏览器会查看微任务队列,如果有任何微任务(例如,Promise的then回调),它们将被一一取出并执行。
- 完成微任务队列的执行后,浏览器会执行渲染步骤,更新UI。
- 然后,浏览器会查看任务队列,如果有任何宏任务(例如,setTimeout的回调),浏览器会取出一个宏任务执行。
- 重复以上过程,即回到第3步,再次检查微任务队列,更新UI,然后再执行一个宏任务,如此循环。
这种设计的理念是为了尽可能地优化用户体验,尽可能快地执行异步任务,因此,微任务会在当前宏任务执行结束后立即执行,而不需要等待下一个宏任务。
于是乎,很多面试题中 Promise,settimeout 的优先级问题就引刃而解了。
2. nodeJS 环境
Node.js 的事件循环有几个不同的阶段,每个阶段都有一个或多个任务队列。当一个阶段完成时,事件循环会移动到下一个阶段。以下是主要阶段:
- timers: 这个阶段执行已经到期的 setTimeout 和 setInterval 的回调函数。
- I/O callbacks: 这个阶段执行大部分回调函数,如网络、流、TCP 的错误回调,但是不包括由 timers 阶段和setImmediate 阶段处理的回调。
- idle, prepare: 这两个阶段内部使用,对开发者透明。
- poll: 这个阶段主要用于等待新的 I/O 事件,执行与 I/O 相关的回调。在某些条件下,也可能执行 setImmediate 的回调。
- check: 在这个阶段,setImmediate 的回调会被调用。
- close callbacks: 在这个阶段,会处理一些关闭的回调,如 socket.on(‘close’, …)。
总结来看,Node.js 的事件循环机制相对于浏览器的事件循环机制更为复杂。在浏览器中,只有一个宏任务队列和一个微任务队列。而在 Node.js 中,有多个阶段,每个阶段都有自己的队列。当一个阶段的队列被清空后,事件循环会移动到下一个阶段。
对于每个阶段,Node.js 都会创建一个新的调用栈,并从该阶段的队列中取出回调函数来执行。当调用栈被清空(也就是说所有的回调函数都已执行完毕)或者达到了回调函数的最大数量时,事件循环会移动到下一个阶段。在这个过程中,一些微任务(如 Promise 的回调)也可能会被执行。
四、异步的实现 (callback、promise、async-await)
1. 三个方法对比
在 JavaScript 中,常见的异步操作包括定时任务(如 setTimeout 和 setInterval)、AJAX 请求、读写文件等。在传统的异步编程模型中,我们通常会通过回调函数(callback)来处理这些异步操作,但是这样会导致代码结构复杂,难以维护,特别是当异步操作存在依赖关系时。接下来我们做个对比(以文件读写例子来看)
假设我们有三个文件,需要按顺序依次读取,每个文件的读取都依赖于上一个文件的读取结果,callback 写法如下:
const fs = require('fs');
fs.readFile('file1.txt', 'utf8', function(err, data1) {
if (err) throw err;
fs.readFile('file2.txt', 'utf8', function(err, data2) {
if (err) throw err;
fs.readFile('file3.txt', 'utf8', function(err, data3) {
if (err) throw err;
console.log(data1, data2, data3);
});
});
});
可以看到,随着异步操作的增加,回调函数嵌套的层数会增加,这就是所谓的回调地狱,代码难以阅读和维护。
注意书写上,错误通常作为回调函数的第一个参数传入。这种模式被称为 “错误优先” 的回调(error-first callback)。
而使用 Promise,我们可以这样写:
const fs = require('fs').promises;
fs.readFile('file1.txt', 'utf8')
.then(data1 => {
console.log(data1);
return fs.readFile('file2.txt', 'utf8');
})
.then(data2 => {
console.log(data2);
return fs.readFile('file3.txt', 'utf8');
})
.then(data3 => {
console.log(data3);
})
.catch(err => {
console.error(err);
});
使用 Promise,我们避免了回调地狱,代码更加清晰和优雅。每一个异步操作都返回一个 Promise 对象,通过链式调用 .then() 或 .catch() 方法,我们可以更加直观地管理异步操作的执行顺序和错误处理。
当然如果我们使用ES7 的 async/await 语法时,可以使异步代码看起来更像同步代码,从而更容易理解和管理。相比于 Promise,它提供了一种更加直观,更加简洁的方式来处理异步操作。我们可以这样做改造
const fs = require('fs').promises;
async function readFiles() {
try {
const data1 = await fs.readFile('file1.txt', 'utf8');
console.log(data1);
const data2 = await fs.readFile('file2.txt', 'utf8');
console.log(data2);
const data3 = await fs.readFile('file3.txt', 'utf8');
console.log(data3);
} catch (err) {
console.error(err);
}
}
readFiles();
async/await 语法使我们的代码看起来更像是同步的,我们无需通过链式调用来处理异步操作,也无需处理 Promise 的返回值。这使得我们的代码更易阅读和维护。
async/await 实际上是建立在 Promise 基础之上的,await 后面的表达式通常会返回一个 Promise 对象,然后 await 会暂停当前的 async 函数执行,等待 Promise 的解析。这使得 async/await 可以以同步的方式写异步代码,同时仍然使用 Promise 的优势,例如错误处理和组合能力。
2. Promise 原理
Promise 是 JavaScript 中用来处理异步操作的一种对象。它让异步操作更加方便和安全,避免了回调地狱(Callback Hell)的问题。Promise 的设计理念是,所有异步任务都返回一个 Promise 对象,该对象有一个 then 方法,用来指定下一步的回调函数。
三种状态
- pending:初始状态,既不是成功,也不是失败状态。
- fulfilled:表示操作成功完成。
- rejected:表示操作失败。
当 Promise 对象处于 fulfilled 或 rejected 状态时,称为 settled 状态。一旦 Promise 被 settled,它的状态就不能再改变,而且会拥有一个不变的结果值。
通过使用 Promise,我们可以更好地控制异步操作,并且可以通过链式调用的方式,组合多个异步操作,使得代码更加清晰易读。
简易手写 Promise
根据上述原理,我们来实现一个promise:
class SimplePromise {
constructor(executor) {
this.status = 'pending'; // 当前状态
this.value = undefined; // 成功状态的值
this.reason = undefined; // 失败状态的原因
this.onResolvedCallbacks = []; // 成功状态的回调函数队列
this.onRejectedCallbacks = []; // 失败状态的回调函数队列
let resolve = (value) => {
if (this.status === 'pending') {
this.status = 'resolved';
this.value = value;
this.onResolvedCallbacks.forEach(fn => fn());
}
};
let reject = (reason) => {
if (this.status === 'pending') {
this.status = 'rejected';
this.reason = reason;
this.onRejectedCallbacks.forEach(fn => fn());
}
};
try {
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.status === 'resolved') {
onFulfilled(this.value);
}
if (this.status === 'rejected') {
onRejected(this.reason);
}
if (this.status === 'pending') {
this.onResolvedCallbacks.push(() => {
onFulfilled(this.value);
});
this.onRejectedCallbacks.push(() => {
onRejected(this.reason);
});
}
}
}
这个实现只包含了 Promise 的最基本功能做个例子:创建 Promise、执行 Promise (resolve 或 reject)以及添加 then 方法。一个完整的 Promise 应该还包括错误处理、链式调用以及状态只能改变一次等特性。在实际使用中,我们还需要处理各种边界情况,例如 then 方法的参数可能不是函数,resolve 的参数可能是另一个 Promise 等等。
Async Await or Promise
经常在CR代码时我们纠结这两的选用,往往使代码规范看上去不一致。笔者从几个方面做个分析
使用 Promise 的情况可能包括:
- 当你需要将多个异步操作链接在一起时,Promise 的链式调用是非常方便的。
- Promise 的 then 和 catch 方法允许你对异步操作的结果和可能的错误进行更细粒度的控制。
- 当你需要在多个异步操作之间进行协调时,Promise 提供了一些有用的静态方法,如 Promise.all、Promise.race 等。
使用 async/await 的情况可能包括:
- 当你的代码包含大量的异步操作,并且这些操作之间存在复杂的控制流程(如条件语句、循环等)时,async/await 可以让你的代码看起来更清晰,更像同步代码。
- 如果你更喜欢使用 try/catch 结构进行错误处理,而不是使用 Promise 的 catch 方法,那么 async/await 是一个很好的选择。
- 在某些情况下,async/await 可以让你更方便地使用一些现代的 JavaScript 特性,如解构赋值等。
总的来说,如果代码中的异步操作比较简单,或者你需要更细粒度的控制,那么 Promise 可能是一个更好的选择。如果你的代码中的异步操作比较复杂,或者你希望你的代码看起来更像同步代码,那么 async/await 可能是一个更好的选择。往往大型项目在工程上的选型都会是 async/await,并且在架构上完成异步的统一捕捉,让代码看上去更 clean
3. Generator(生成器)
Generator(生成器)是 ES6 提供的一种特殊的函数,它不同于普通函数,能够控制函数的执行过程,手动暂停和恢复代码执行。Generator 函数的特点体现在:
- 语法上:在函数关键字 function 后面有一个星号 “*”,并且函数体内部使用 yield 表达式定义不同的内部状态。
- 执行过程上:Generator 函数返回一个指向内部状态的指针对象,也就是迭代器对象。我们可以使用这个迭代器对象的 next() 方法,让 Generator 函数恢复执行,每次调用 next 方法,Generator 函数都会执行到下一个 yield 表达式的位置。
function* helloWorldGenerator() {
yield 'hello';
yield 'world';
return 'ending';
}
var hw = helloWorldGenerator();
在这个例子中,helloWorldGenerator 是一个 Generator 函数。当我们调用这个函数时,它并不会立即执行,而是返回一个迭代器对象。我们可以通过调用这个迭代器对象的 next() 方法,来控制这个函数的执行过程。
hw.next() // { value: 'hello', done: false }
hw.next() // { value: 'world', done: false }
hw.next() // { value: 'ending', done: true }
hw.next() // { value: undefined, done: true }
当我们每次调用 next() 方法时,函数就会执行到下一个 yield 表达式的位置,并返回一个包含 value 和 done 两个属性的对象。value 属性表示当前 yield 表达式的值,done 属性表示函数是否已经执行完毕。
async 是一种特殊的 generator
你可以把 async 函数看作是一个特殊的 generator 函数,它会自动执行所有的 yield,并且等待它们的 promise 完成。这个自动执行的过程,实际上是通过一个名为 co 的库来完成的,这个库内部实现了一个自动执行 generator 的逻辑。
五、异步请求控制实现
在聊完基础异步实现这个知识点后,我们一定想了解多个异步代码执行后,从代码上我们如何去做请求的控制。例如我们可能需要处理并发请求的数量,或者我们可能需要等待某个异步请求完成之后再执行另一个异步请求。
1. 并发控制请求数量
并发控制以避免过多的请求对服务器或者客户端产生压力. 例如我们写个 limitConcurrency 函数控制同时并发最多三个请求。对于并发请求控制,Promise.all 不能直接实现。因为 Promise.all 会立即执行所有的 Promise,没有办法对其进行并发控制。
/**
*
在 limitConcurrency 函数中,active, finished, started, results 和 index 是用来跟踪任务执行进度的状态变量,它们的含义如下:
active:正在执行的任务数量。每当开始一个新的任务时,这个变量就会增加;每当一个任务完成时,这个变量就会减少。
finished:已经完成的任务数量。每当一个任务完成时,这个变量就会增加。
started:已经开始的任务数量。每当开始一个新的任务时,这个变量就会增加。
results:一个数组,用来存储所有任务的结果。每个任务完成时,它的结果会被添加到这个数组中。
index:正在执行的任务在 tasks 数组中的索引。这个变量是为了保证 results 数组中的结果顺序和 tasks 数组中的任务顺序一致。
startNext 函数的作用是开始下一个任务。它首先检查是否所有的任务都已经完成,如果是的话,就调用 resolve 函数,将 results 数组作为参数,表示所有的任务都已经完成。如果还有未完成的任务,它就开始下一个任务,并更新相关的状态变量。
在初始化阶段,startNext 函数会被调用 limit 次,开始 limit 个任务。然后,每当有一个任务完成时,startNext 函数就会被再次调用,开始下一个任务。这样就可以保证任何时刻都只有最多 limit 个任务同时进行。
*
**/
function limitConcurrency(tasks, limit) {
return new Promise((resolve, reject) => {
let active = 0;
let finished = 0;
let started = 0;
let results = [];
// This function will start a task
function startNext() {
if (finished >= tasks.length) {
// All tasks finished
resolve(results);
return;
}
if (started < tasks.length) {
// Start a new task
let task = tasks[started++];
let index = started - 1;
active++;
task().then(result => {
active--;
finished++;
results[index] = result;
startNext();
}).catch(reject);
}
}
// Start initial batch of tasks
for (let i = 0; i < limit && i < tasks.length; i++) {
startNext();
}
});
}
// Example usage
let tasks = [
() => fetch('https://api.example.com/data1'),
() => fetch('https://api.example.com/data2'),
() => fetch('https://api.example.com/data3'),
// ... more tasks ...
];
limitConcurrency(tasks, 3)
.then(results => console.log(results))
.catch(error => console.error(error));
这个函数的工作方式是,当有一个任务完成时,它会尝试开始下一个任务。因此,任何时刻都只有最多 limit 个任务同时进行。当所有任务都完成时,这个函数返回的 Promise 会解决,并返回所有任务的结果。
等待某个异步请求完成后执行另一个
2. 顺序
如果我们需要依次执行多个异步操作,可以使用 Promise 的链式调用。
let promise = Promise.resolve();
for (let i = 0; i < 10; i++) {
promise = promise.then(() => fetch('/api/data'));
}
3. 并发
- 如果你想要并发执行多个异步操作,并且当所有异步操作都完成后再进行下一步操作,你可以使用 Promise.all()。
Promise.all([
fetch('/api/data1'),
fetch('/api/data2'),
fetch('/api/data3')
]).then(results => {
// results 是一个数组,包含了三个 fetch 请求的结果
console.log(results);
});
- 如果你想要并发执行多个异步操作,但只需要获取第一个完成的异步操作的结果,你可以使用 Promise.race()。
Promise.race([
fetch('/api/data1'),
fetch('/api/data2'),
fetch('/api/data3')
]).then(result => {
// result 是第一个完成的 fetch 请求的结果
console.log(result);
});
六、前端副作用管理
1. 副作用
从前端架构师的视角看异步,除了单个异步实现,异步请求实现外,函数对外部影响的那些副作用的处理往往和微任务在框架哪个地方写,怎么组织代码有关,我们试图分析下现在框架一般做的一些事情。
我尝试列举描述副作用,包含但不限于:
- 更改全局变量或应用状态: 如果函数改变了外部的某个变量,那么它就产生了副作用。在 React 和 Redux 中,改变组件状态或者改变全局的 Redux store 都是副作用。
- 网络请求: 发送 HTTP 请求是典型的副作用。它们通常会影响应用的状态,例如,我们可能在发送请求后更新 Redux store。
- 定时器: 使用 setTimeout 或 setInterval 创建的定时器也是一种副作用。因为它们会在未来的某个时间点改变应用状态。
- 读写本地存储: 如果函数读取或写入 localStorage、sessionStorage 或 indexedDB,那么它产生了副作用。
- 日志记录: 将信息记录到 console 或者将错误信息发送到日志服务器都是副作用。
在处理这些副作用时,我们需要一种方式来控制它们的执行顺序,处理可能出现的错误,以及在需要的时候取消它们。这就是 redux-saga 和其他副作用管理库的用武之地。
例如,你可能需要在用户提交表单后发送一个 HTTP 请求。在请求完成之前,你需要显示一个加载指示器,如果请求失败,你需要显示错误消息,如果用户在请求完成之前导航到了其他页面,你可能需要取消这个请求(调用取消请求的API)。通过使用 redux-saga,你可以使用简单、声明式的 API 来管理这个过程。
看上去很多时候我们也没这么做是因为在实现业务前端实际过程中为了效率做了些权衡并没有这样去精细化管理副作用。
2. 副作用为啥要工程约束
在 jQuery 时代,处理副作用的方式往往是通过回调函数和事件监听来进行。这种方法相比于现在的前端框架,显得更加直观和手动。
例如,如果你想在 AJAX 请求完成后更新一些 DOM 元素,你可以在 AJAX 的成功回调函数中直接操作 DOM。如果你想在用户点击一个按钮后执行某些操作,你可以给这个按钮添加一个点击事件监听器。
然而,这种方法也有其局限性。首先,它将异步操作、副作用和状态管理混在一起,使得代码难以维护和理解。其次,当应用变得更复杂,你可能会遇到“回调地狱”,即回调函数嵌套回调函数,导致代码难以阅读和理解。此外,错误处理也变得更加困难,因为每个回调函数可能都需要处理错误,而且错误可能需要在多个地方进行处理,于是 最狭义的前端代码架构 就出现了,需要把这些问题代码的组织工程的维护通过统一的实践管理起来。
副作用本身是一种无法避免的现象,因为在实际的应用中,我们经常需要进行 I/O 操作(例如网络请求、读写文件等)、改变全局状态、操作 DOM 等,这些都会产生副作用。副作用如果不妥善处理,可能会导致程序的行为变得难以预测和控制,比如出现状态不一致、内存泄漏、程序错误等问题。
3. 各前端框架处理副作用思路
作为前端技术架构师需要通各框架的设计原理思路如何解决一个问题的,这里讲解下副作用在各框架的处理思路
七、前端渲染框架:React、Vue 和 Angular
1. React
React 没有内置的副作用处理机制,但是它提供了一些用于处理副作用的生命周期方法和 Hooks。
类组件中(在生命周期方法中处理副作用)
- componentDidMount:当组件首次渲染后,此方法将被调用,你可以在这里发起网络请求、设置定时器或执行其他需要在 DOM 准备好后进行的操作。
- componentDidUpdate:当组件的 props 或 state 更新后,此方法将被调用,你可以在这里根据新的 props 或 state 发起网络请求或执行其他副作用。
- componentWillUnmount:当组件被卸载和销毁之前,此方法将被调用,你可以在这里取消网络请求、清除定时器或执行其他清理操作。
函数组件中(React 提供了 useEffect Hook 来处理副作用)
useEffect(() => {
// 在组件渲染后和更新后执行这个函数
fetchData();
// 在组件卸载前执行这个函数
return () => {
cancelFetch();
};
}, [dependencies]);
/**
useEffect 的第一个参数是一个函数,这个函数将在组件渲染后和每次更新后被调用。如果这个函数返回另一个函数,那么返回的函数将在组件卸载前和每次更新前被调用。
useEffect 的第二个参数是一个数组,它表示这个副作用的依赖。当依赖改变时,副作用将被重新执行。如果没有提供这个数组,那么副作用将在每次更新后被重新执行。如果提供了一个空数组,那么副作用只在组件首次渲染后执行一次。
*/
虽然 useEffect 可以用于处理副作用,但它并不提供像 redux-saga 那样的副作用管理能力。如果你需要更复杂的副作用管理,比如需要处理并发的副作用,或者需要在副作用之间共享状态,那么你可能需要使用 redux-saga 或其他副作用管理库
2. Vue.js
Vue.js 使用生命周期钩子函数来处理副作用。
例如,你可以在 created 或 mounted 钩子中发起网络请求,然后在 beforeDestroy 钩子中取消网络请求或进行其他清理操作。
在 Vue.js 3 中,Vue.js 引入了 Composition API,其中的 watch 和 watchEffect 函数也可以用于处理副作用
3. Angular
Angular 使用 RxJS(一个响应式编程库)来处理副作用。你可以在服务中创建一个 Observable 来表示副作用,然后在组件中订阅这个 Observable。当组件被销毁时,Angular 会自动取消订阅,这样就可以避免产生未处理的副作用。另外,Angular 还提供了 HttpClient 服务,它能够方便地发起 HTTP 请求,并自动处理一些常见的副作用,如错误处理和取消请求。
八、前端数据流框架:Redux、MobX、Vuex
1. Redux
Redux 是一个 JavaScript 应用的状态管理框架,它本身并不直接处理副作用。然而,有一些中间件(比如 redux-thunk、redux-saga、redux-observable)提供了处理副作用的能力。
例如,
- redux-thunk 允许 action 创建函数返回一个函数,这个函数可以包含异步操作;
- redux-saga 使用 ES6 的 Generator 功能,将异步操作和应用的状态管理解耦;由于引入了 generator做更精细化副作用分类
- redux-observable 则基于 RxJS,可以方便地处理更复杂的异步流
大家又机会重点学习下 redux-saga,他虽然使用generator变得很复杂,但是其函数式精细化处理前端effect 的生命周期值得学习。
在 redux-saga 中,异步任务被放入了一个单独的线程——称之为 Saga,它使用 Generator 函数来编写。每一个 saga 都可以被视为一个单独的线程,它们独立于主应用程序,并且可以并行执行。
2. Mobx
MobX 是一个响应式的状态管理库,它提供了一种自动跟踪状态变化并触发副作用的机制。在 MobX 中,你可以使用 autorun、reaction 或 when 函数来定义副作用。当相关的状态变化时,这些副作用将自动执行。
3. Vuex
Vuex 是 Vue 的官方状态管理框架,它将副作用放在 action 中处理。在 Vuex 的 action 中,你可以执行任何异步操作,然后通过提交 mutation 来改变状态。如果需要处理更复杂的副作用,你可以使用像 vue-observable 或 vuex-saga 这样的库。
总结,基本前端框架都采用生命周期,特殊api 流程来进行对副作用所处阶段的收集。并在合适的时机调度执行。
九、前端框架异步调度器
在理解这些框架给我们提供哪些API来处理这些异步和副作用后,我们可以更深一步去追这些框架内部实现又是什么机制来调度的。在这篇文章的视角不分析源码的函数设计模式,更多从大体概念简要说明流程,以让我们知道同步异步在前度框架里的位置
1. React 的调度
React 通过 “Fiber” 的数据结构来追踪组件树的状态。每当有更新(如 setState 调用或新的 props)时,React 会创建一个或多个新的 Fiber 节点以反映这些更改。这些更新的 Fiber 节点会被添加到一个 “工作单元” 链表中,以便调度器进行处理。调度器的工作就是通过遍历这个工作单元链表,并在每个 Fiber 上调用适当的生命周期方法(如果是类组件)或函数组件本身(如果是函数组件)。如果是 Concurrent Mode,调度器还会做更多工作,如根据优先级将工作分解为可中断的 “chunks”,并可能在执行更高优先级的工作时中断或延迟低优先级的工作。
2. 调度阶段(Schedule Phase)
调度阶段是由于用户交互、网络响应或者其他更新触发的。当组件需要更新时,React 将创建更新并将其加入到队列中,这个队列称为更新队列。这是 React 实现异步渲染的关键部分。然后,根据 React 的调度机制(Scheduler),选择优先级最高的任务进行处理。
- 在类组件中,如果使用 setState 或者 forceUpdate,就会在组件的更新队列中创建更新。
- 在函数式组件中,如果使用 useState 或 useReducer hook,同样会在组件的更新队列中创建更新。
3. 构建阶段(Build Phase):
在调度阶段结束后,React 开始构建新的 Fiber 树。在这个阶段,React 会对每一个需要更新的组件进行重新渲染,并创建出新的 Fiber 节点来表示这些组件。然后,React 会比较新旧 Fiber 节点来决定如何进行高效的更新。
- 对于每个需要更新的组件,React 会调用其 render 方法(或者函数组件本身)来获取新的 JSX 结构,然后将其转换为新的 Fiber 节点。
- 对于每个新的 Fiber 节点,React 会和旧的 Fiber 节点进行对比,确定是否需要进行更新。
4. 提交阶段(Commit Phase):
构建阶段完成后,React 拥有了一棵新的 Fiber 树,并且知道了哪些部分需要更新。然后,React 进入提交阶段,在这个阶段,React 会将新的 Fiber 树映射到 DOM 上。
- 首先,React 遍历新的 Fiber 树,找出所有需要更新的 DOM 节点。
- 对于需要更新的 DOM 节点,React 会进行相应的操作。这可能是创建新的 DOM 节点,更新已有的 DOM 节点,或者删除不再需要的 DOM 节点。
- 在这个阶段,React 还会调用生命周期方法,比如 componentDidMount,componentDidUpdate 和 componentWillUnmount。
5. 副作用(Effects):
如果你在组件中使用了 React Hooks(例如 useEffect),那么在提交阶段之后,React 会处理所有注册的副作用。这包括运行你提供的副作用函数,以及在组件更新或卸载时进行必要的清理工作。
6. setState 同异步问题
- 在非 Concurrent 模式下:setState 可同步可异步取决于何处调用
在大多数情况下,当你调用 setState,React 将请求的状态更改放入队列中,然后在稍后的时间进行更新。它会批量地执行这些更改以优化性能。这就是为什么你不能立即在调用 setState 之后读取状态更新的原因。这种行为可以在事件处理器或者生命周期方法中观察到。
this.setState({count: 1});
console.log(this.state.count); // 这里可能会打印出旧的 state,因为 setState 是异步的
在某些情况下,setState 可能会同步更新状态。如果你在 React 的事件处理器之外调用 setState,例如在一个 setTimeout 或者原生 DOM 事件处理器中,那么 setState 将会立即更新状态,而不是将其放入队列中。
setTimeout(() => {
this.setState({count: 1});
console.log(this.state.count); // 这里将会打印出新的 state,因为在 setTimeout 中 setState 是同步的
}, 0);
- 在 Concurrent 模式下
在 Concurrent 模式下,React 通过异步渲染和中断渲染的能力,使得 UI 的更新可以更好地适应用户的输入,从而提供更流畅的用户体验。在这种模式下,setState 的行为就是异步,因为更新会被推迟或者被中断,以使得更高优先级的更新能够先进行。
这里对setstate同异步的书写,无论在哪种情况下,你都不应该依赖 setState 后的状态立即更新。如果你需要在状态更新后执行某些操作,你应该使用 setState 的第二个参数,也就是一个回调函数
this.setState({count: 1}, () => {
console.log(this.state.count); // 这里将会打印出新的 state,因为它在 setState 的回调函数中
});
7. 调度器自己实现的目的
在我们的浏览器处理空闲时间中,有两个API 如 requestAnimationFrame 和requestIdleCallback 都可以让我们在浏览器空闲时执行任务。我试图总结以下几点自研原因
- 更细粒度的任务控制:React希望能够控制任务的优先级和执行时间。通过自定义调度器,React能够将任务切分为多个小的工作单元,并按照优先级和浏览器的空闲时间执行这些工作单元。
- 可预测性:浏览器提供的 API 它们的调度行为并不总是可预测的。例如,requestIdleCallback在某些情况下可能会有很大的延迟。React的调度器尝试解决这种不确定性,让任务执行更具可预测性。
- 兼容性:不是所有浏览器都提供了如requestIdleCallback这样的API,而React的目标是在所有现代浏览器中提供一致的性能和行为。因此,React需要自己实现这样的调度机制。
- 并发模式:React引入Fiber架构,是为了支持React的并发模式(Concurrent Mode)。这种模式允许React同时处理多个渲染任务,而不是一次只处理一个。这在处理用户交互、动画等需要高响应性的场景时特别有用。这种级别的并发性无法仅通过使用浏览器API实现,因此需要自己的调度机制。
8. Vue 的调度
基本工作流程
Vue.js 的响应式系统是基于数据驱动,而React是采用组件驱动的方式。所以它并没有采用和 React 一样的 Fiber 架构和 Scheduler调度。它通过数据的变化去驱动视图的更新,而不是通过调度任务。
- 实例化Vue对象:首先会进行Vue实例的初始化,初始化生命周期、事件等。
- beforeCreate:这个生命周期在实例初始化之后被调用,这个时候实例的数据观测还没有完成,所以在这个生命周期中不能访问到数据。
- created:这个生命周期在实例创建完成后被调用,这个时候实例的数据观测已经设置完毕,数据变化时,视图会重新渲染。
- 编译模板:接下来对模板进行编译,将模板中的指令解析成一段段的watcher,然后进行依赖收集。
- 挂载实例:将实例挂载到DOM上,一般是执行$mount方法,挂载过程中,会调用beforeMount和mounted两个生命周期方法。
- beforeMount:在挂载开始之前被调用,此时模板已经编译完成,但是还没挂载到DOM上。
- mounted:这个生命周期在模板被完全替换成渲染后的DOM后调用。此时,可以通过this.$el来访问到实例的根DOM节点。
- 更新数据:当数据变化时,会触发更新,进入下一个流程。
- 虚拟DOM重新渲染和patch:首先通过比对新旧虚拟DOM,进行DOM的更新,然后调用beforeUpdate和updated两个生命周期方法。
- beforeUpdate:在数据发生变化,触发更新之前调用。这个时候可以在更新之前获取到现在的DOM状态。
- updated:在虚拟DOM重新渲染和打补丁之后调用。此时,DOM已经更新完成,你可以执行依赖于DOM的操作。
- 卸载:Vue实例被销毁
- beforeDestroy:实例销毁之前调用。在这一步,实例仍然完全可用,可以在这里解除定时器和事件监听器等。
- destroyed:Vue实例销毁后调用。此时,Vue实例的所有指令绑定已经解绑,所有的事件监听器已被移除,所有的子实例也已经被销毁。
上述生命周期函数中,我们可以插入适当的副作用逻辑。在created, mounted, updated, beforeUpdate, beforeDestroy等阶段,比如常常执行如发送请求、启动定时器、绑定/解绑事件监听等副作用。
Vue3 异步渲染机制
虽然Vue2并没有引入Fiber架构和调度机制,但在 Vue3,引入了类似的异步渲染特性。Vue 3采用了新的虚拟DOM实现和组件级的异步更新队列,这在某种程度上实现了类似的调度能力,可以优化长列表等性能瓶颈,和React的调度能力有类似之处。
在Vue 3中,一个新的异步更新队列被引入。当你改变数据,视图并不会立即更新,而是等待同一事件循环中所有的数据变化完毕再统一更新视图。这样做的好处是当你连续改变数据时,程序只需要执行一次更新而不是多次。
异步更新队列的实现逻辑:
- 当观测到数据变化,Vue会开启一个异步任务,用来在稍后更新组件。这个异步任务可能是使用Promise.then、MutationObserver或setImmediate等方法创建的。
- 在这个异步任务中,Vue会首先对更新队列进行排序,这样可以保证组件按照从父到子的顺序更新。这种机制允许父组件在子组件更新前改变它们的状态。
- 接下来,Vue会遍历这个更新队列,执行实际的更新操作。在这个过程中,如果某个组件的依赖在这个过程中改变了,那么这个组件将会被跳过,避免不必要的更新。
- 当更新队列被清空后,Vue会执行一些后置的队列,比如执行updated钩子函数,或者触发DOM更新等。
这个异步渲染机制,类似于React的Fiber架构,都是尝试将渲染工作分片,然后利用浏览器的空闲时间逐步完成,以达到更平滑的用户体验。尽管Vue 3并没有实现像React Fiber那样的时间切片能力,但是它的异步更新队列还是带来了很大的性能提升。

















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









