







 本文记录了一位初学者使用Python的BeautifulSoup库进行网页爬虫的简单过程,包括爬取网站链接、数据清洗及存储到TXT文件。在实际操作中,遇到了链接保存至Excel时的数据丢失问题,以及针对不同网站开发独立爬虫的时间成本问题。
本文记录了一位初学者使用Python的BeautifulSoup库进行网页爬虫的简单过程,包括爬取网站链接、数据清洗及存储到TXT文件。在实际操作中,遇到了链接保存至Excel时的数据丢失问题,以及针对不同网站开发独立爬虫的时间成本问题。
领导知道我会点py。让我去几个网站爬文章下来。
然后我开始百度py怎么爬爬虫。
我的思路如下(初学者抛砖引玉)
1、首先爬取网站所有连接;
2、然后依次访问连接爬取数据;
3、随后把数据清洗后保存到txt里面;
4、打包发给运营。
# coding=utf-8
from bs4 import BeautifulSoup
import requests
def getHtml(url, label, attr):
response = requests.get(url)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, 'html.parser')
for target in soup.find_all(label):
try:
value = target.get(attr)
except:
value = ''
if value:
print(value)
url = 'http://www.miit.gov.cn/n1146290/n1146392/index.html'
label = 'a'
attr = 'href'
getHtml(url, label, attr)
筛查爬取到的连接,发现这些分页打开能看到具体的文章连接↓
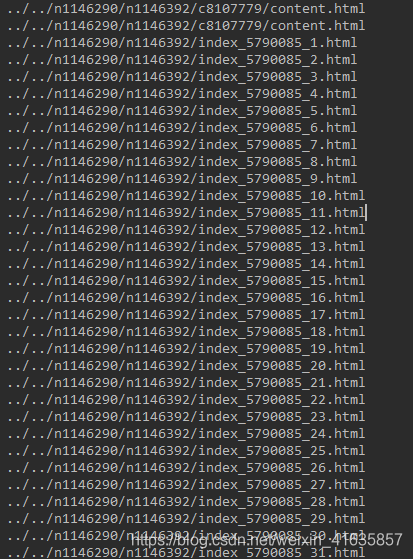

调整代码批量获取文章连接↓
from bs4 import BeautifulSoup
import requests
import time
def getHtml(url, label, attr):
response = requests.get(url)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, 'html.parser')
for target in soup.find_all(label):
try:
value = target.get(attr)
except:
value = ''
if value:
print(value)
for i in range(1,4): # 仅仅展示就爬了四条链接的文章
url = "http://www.miit.gov.cn/n1146290/n1146392/index_5790085_"+str(i)+".html"
label = 'a'
attr = 'href'
getHtml(url, label, attr)
time.sleep(0.5)获取到所有连接↓,扔到到excel里。本来我是直接保存到excel里的,但是自动写入后读取的时候有问题会漏字。而且每个网上都得单独写爬虫我也没时间开发一个通用性很好的脚本,我就手工处理了。(有重复是因为网站爬下来就是两个一样的链接。)
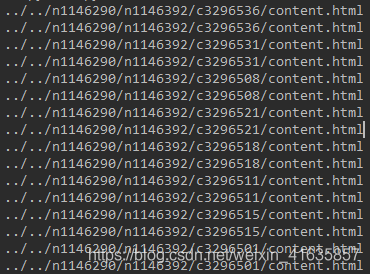
最后依次访问每个链接,爬取数据进行数据清洗并保存到txt里↓
import requests
from bs4 import BeautifulSoup
import re
import xlrd
table = xlrd.open_workbook('F:\\url.xlsx', "r")
sheet1 = table.sheet_by_index(0)
rows = sheet1.nrows
for i in range(1, rows): # 1,2,3,4,5
url = str("http://www.miit.gov.cn/"+sheet1.row_values(i)[0])
# print(url)
strhtml = requests.get(url)
strhtml.encoding = 'utf-8' # 将编码格式改为utf-8
soup = BeautifulSoup(strhtml.text, 'lxml')
data = soup.select('#con_title')
data = str(data).replace('<br/>', "\n") # 用换行符替换'<br/>'
re_h = re.compile('</?\w+[^>]*>') # html标签
data = re_h.sub('', str(data))
data = str(data).replace('[', "")
data = str(data).replace(']', "")
# print(url)
print(str(data))
data5 = soup.select('#con_con')
data5 = str(data5).replace('<br/>', "\n") # 用换行符替换'<br/>'
re_h = re.compile('</?\w+[^>]*>') # html标签
data5 = re_h.sub('', str(data5))
data5 = str(data5).replace('[', "")
data5 = str(data5).replace(']', "")
print(str(data5))
f = open("F:\\爬虫数据\\"+str(data)+".txt", 'a', encoding="utf-8")
f.write(str(data)) # 将字符串写入文件中
f.write("\r\n")
f.write(str(data5)) # 将字符串写入文件中
定位方式如下:
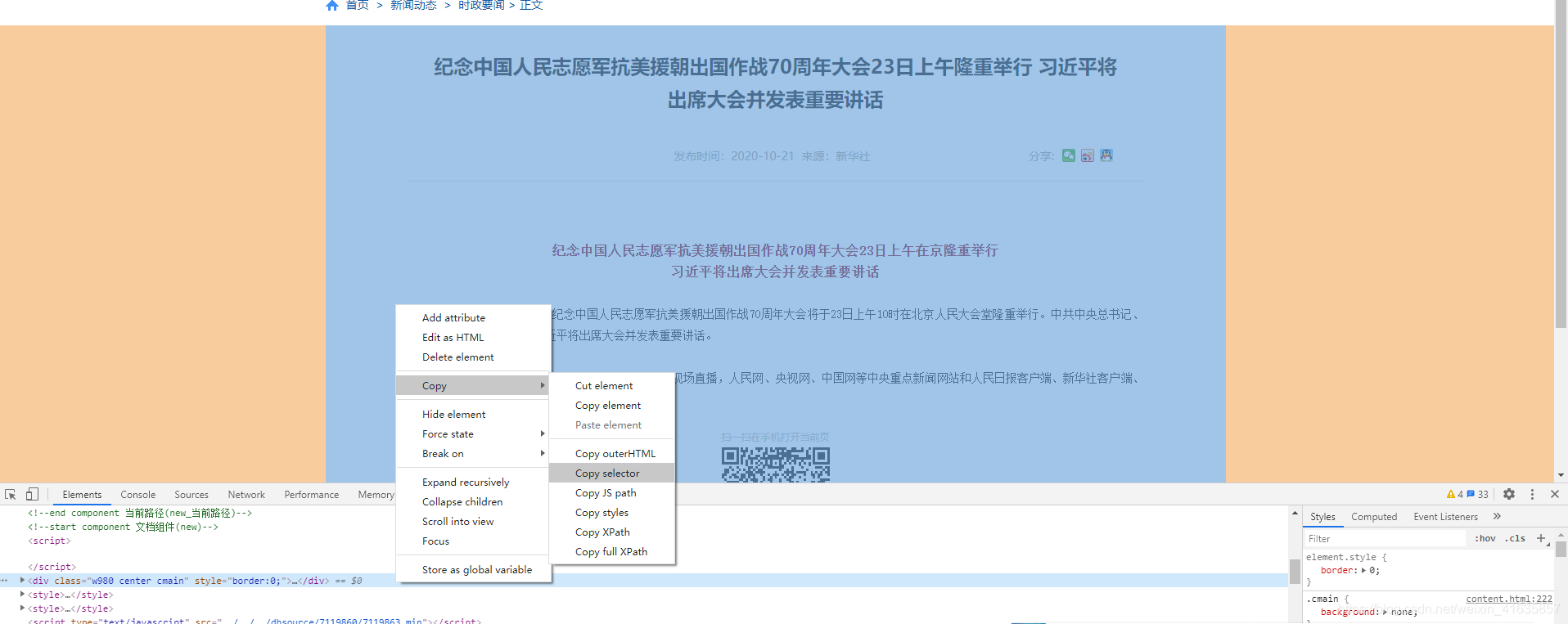

















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









