







计算机视觉任务一般有分类任务、检测任务、分割任务等。其中检测任务是其中的一个典型应用。
什么是目标检测,目标检测就是我们给定一张图片,通过模型能够用矩形框(也有其他形式的框,比较基础的是矩形框)标注出我们希望检测到的物体并且在将该物体框出来的同时能够给出这个物体属于哪一种类别。
那么我们该如何达到目标检测的目的呢?首先我们有这样一个思想:深度学习中所有的问题都可以归纳为分类问题和回归问题(这个思想我是和我的老师也是这一领域的一个大佬验证过,所以是比较可靠的一个思想)。然后根据这个思想我们可以将检测问题也看做多个分类问题,我们可以设定一个滑动窗口在原图片上进行滑动,每次对滑动窗口的图片内容进行分类(这也是为什么我们在训练检测模型之前首先要拿一个分类模型作为backbone,并且这个分类模型是经过预训练的原因。当然我觉得之所以要拿别人预训练好的分类模型backbone是因为之前的分类模型已经有了很强的特征提取能力,这点是比较重要的)。如果分类得到的结论是物体,那么表明这次滑动窗口检测我们设定要检测的物体了,这个滑动窗口我们可以记录下来,然后接着进行滑动直到让窗口滑动完整张图片。但是我们发现还有一种情况我们需要考虑到,那就是被检测的物体的大小我们是不确定的。我们可能希望检测的物体是有大有小的,这种问题应该如何解决呢?答案是我们用不同大小的窗口去滑动,我们人为选定几种窗口大小,然后将这几种窗口的都在原图片上滑动一遍(或者滑动窗口大小不变,对原图进行多尺度缩放,mtcnn的pnet就是这么干的,也同样达到了用不同尺寸窗口去预测的效果。这两种做法原理上都是相对于原图进行多尺度的,也有很多模型是直接在特征图上进行多尺度的考虑的比如另一个单步预测模型ssd,这个稍微提一下)。

以上就是一个简单的最原始检测做法。我们知道最原始的往往是最本质的,但是也是最有优化空间的做法。那么会有哪些问题呢?我以下归纳以下:
- 计算量太大,我们要先遍历不同尺寸的窗口,在用不同尺寸的窗口去在图片上进行滑动。相当于我们要经过很大量级的分类模型。这个计算量是相当恐怖的。不太切合实际。卷积运算是可以减缓这个问题的。遍历的问题是遍历的串形性,一个窗口在分类的时候需要上一个窗口运算完,所以时间消耗是很大的。卷积的计算实际上是矩阵的计算,并且放在gpu上能够达到并行的效果,计算效率得到大幅度提升。(yolo的做法是,直接输入一张图片直接对整张图片做回归算法。)

- 就算我们不考虑计算量问题,我们只是分类其实也是不够的。我们也要做回归,因为我们不能保证我每次滑动的窗口都恰好将物体框住。所以我们在确定框柱的是要检测的物体同时也要想办法将窗口的长、框、坐标回归到最合理的状态。所以我们在设计模型输出的时候除了是否是物体的置信度和分类也要把位置信息(x,y,w,h)信息给设计进去,训练的时候做损失。
- 不同窗口框住同一个物体的问题。比如我们在窗口滑动的时候步长设定相对来说偏小了。导致两个相邻的窗口框到了同一个检测物体。这种问题任何训练好的检测网络都会遇到。所以我们拿到一个训练好的检测模型的时候,图片经过了模型得到一系列框之后。我们在对这些框进行nms操作(或者softnms操作原理上是一样的)将重复的框去除掉,最后得到的框才是我们想要的框,然后将这些框显示标注出来(注意一下,这一步是不参与训练的。是训练好的模型得到一系列框之后的处理,是一个结果的优化)。
我们在回过头来看以下yolo的设计思路。我们先从简单的开始,首先如何训练样本呢。我们先训练backbone的原始分类模型。我们先生成一批正样本(goundtruth上有标注框的样本,所谓的前景)、负样本(背景样本,与标注框重合度小于一定阈值的或者直接为0的样本),正负样本的比例需要注意下,官方给到的是1:3。因为如果不设定比例的话背景样本肯定会远超前景样本,我们模型在训练的时候就会大多在学习负样本,到时候遇到正样本的时候很大可能是识别不出来的。训练好一个初始的backbone后,我们要对拟合层进行设计。
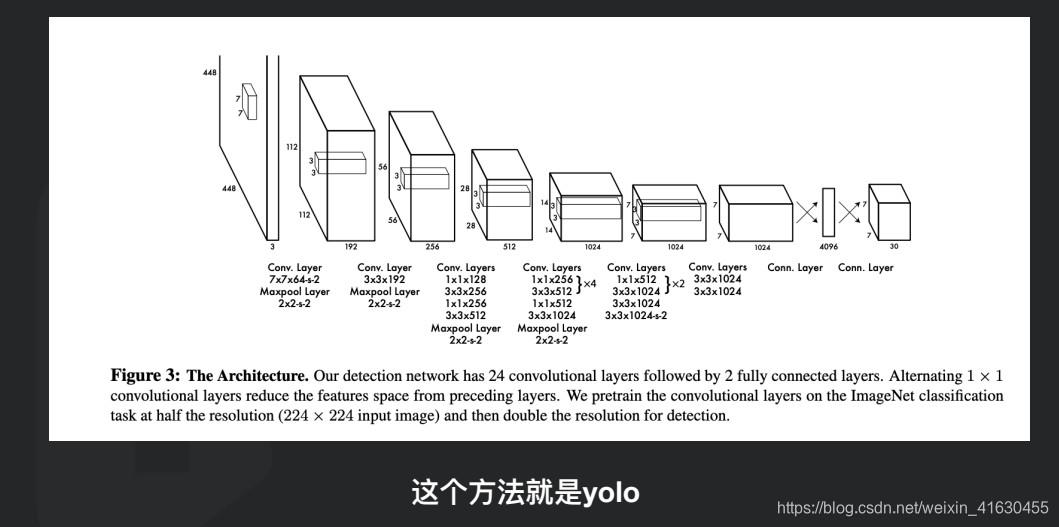
假定我们的图片上只有一个检测物品并且只有一个固定类别,我们就将分类层的onehot改成(x,y,w,h,confidence),如下图改了fc5层后面的那一部分。

假定我们图片上只有一个检测物品并且类别可能是多个类别中的一类。我们就将分类层的onehot改成(x,y,w,h,confidence,onehot),confidence确定是物体的概率,onehot用来找类别。

以上我们都是一直假设只有一个要检测的物体。那么如果我们有多个物体我们该如何处理呢?将原来的输出乘以一个N。N就是我们要检测的几个物体,那么N又应该如何确定呢

yolo的做法是将多组输出与位置进行了强相关。yolov1的时候将原图片划分了7*7个cell,也就是N=7*7=49个cell。一个cell只负责检测一个物体(这个也是yolo的缺点,如果两个物体的中心点都是落在同一个cell里面,yolo也只能检测出一个物体来)

同一个位置,有时候出现大目标有时候出现小目标。这个时候怎么办?如下图操作,实际预测的时候我们取confidence比较大的那个做预测。

根据以上,yolov1的设计我们已经得到了。
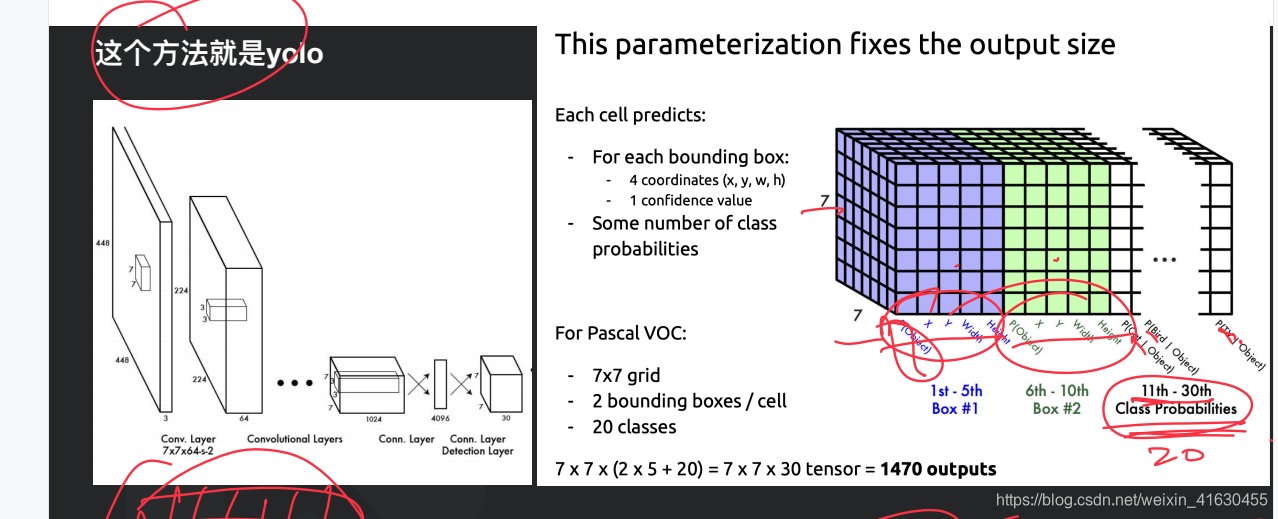
我们最终是得到7*7*(2*5+20)的一个tensor。里面的7*7指的是对原图划分的7*7个cell,谁的中心点落在哪个cell里面就由哪个cell预测该物体。2*5里面的2是为了预测大物体小物体,因为前面提到的物体的大小我们是未知的。5是指框的confidence,x,y,w,h五个信息。20是指onehot,确定有物体后的物体类别判断。
那么我们应该如何训练呢?
首先我们要把我们要预测的vetor的数值都规范在了0,1之间。yolov1中目标检测单个物体的框都是和这个图的整体相关的(比如w,h就是与原图的w,h相关的),所以yolov1的时候里面是有两层全连接的。

在计算损失函数的时候

这里负责的意思是指,训练的时候我一个cell其实是有B个框的,我们选择iou高的那个框作为负责这个对应groundtruth的预测。这里训练的时候其实就把这B个框分别能够预测目标的不同尺寸给分离开来了。比如B1个框负责预测大物体,B2个框负责预测小物体这种。在计算loss的时候如果不是这个框负责的物体则不会记入loss。


yolov1存在两个比较显著的问题。一个就是一个cell只能预测一个物体,并且对于物体的形状存在比较大的限制。还有一个问题就是大物体和小物体的损失误差,我们看到虽然公式中采用了开根号的做法缓解了同样的loss对小物体的影响更明显的问题但是这个问题依然存在。
文末附一个Nms的基本步骤。

这位大佬写的非常有意义,尤其是里面关于targetlabel的处理部分的代码能够帮助理解yolov1的具体细节。地址在这里:https://zhuanlan.zhihu.com/p/183261974


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









