




 本文详细介绍了Spark Master在主备切换(HA)、注册机制、状态改变处理以及资源调度(包括driver和application的调度算法)方面的核心功能。分析了主备切换的四种方式,注册流程,以及不同状态下的处理策略,特别是资源调度中的spreadOutApps和非spreadOutApps算法,确保集群高效运行。
本文详细介绍了Spark Master在主备切换(HA)、注册机制、状态改变处理以及资源调度(包括driver和application的调度算法)方面的核心功能。分析了主备切换的四种方式,注册流程,以及不同状态下的处理策略,特别是资源调度中的spreadOutApps和非spreadOutApps算法,确保集群高效运行。
作用
主备切换机制(HA)
Master HA 的四大方式:分別是 ZOOKEEPER,FILESYSTEM, CUSTOM, NONE;
需要说明的是:
- ZOOKEEPER 是自動管理 Master;
- FILESYSTEM 的方式在 Master 出现突障后需要手动启动机器,机器启动后会立即成为 Active 级别的 Master
来对外提供服务(接受应用程序提交的请求、接受新的 Job 运行的请求) - CUSTOM 的方式允许用户自定义 Master HA 的实现,这对于高级用户特别有用;
- NONE,这是默应情况,当我们下载安装了 Spark 集群中就是采用这种方式,该方式不会持久化集群的数据, Driver,
Application, Worker and Executor. Master 启动起立即管理集群;
关于zookeeper的主备切换
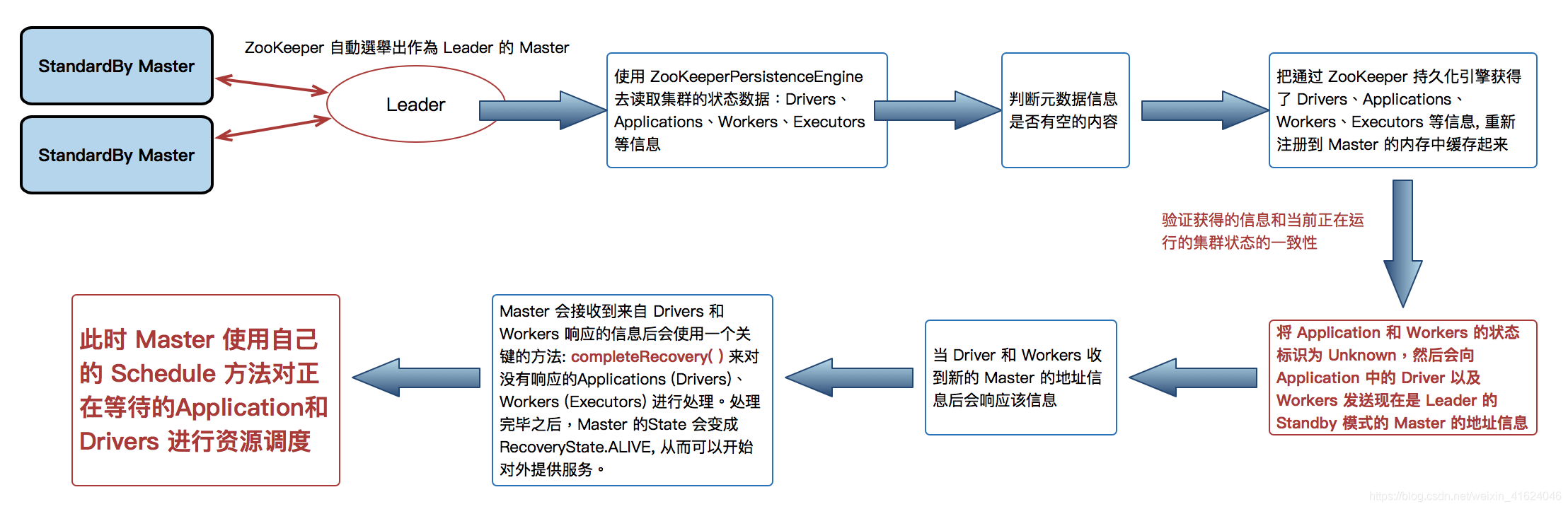
将Application和worker,过滤出来目前状态还是unknown的,然后遍历,分别调用removeWorker和finishApplication方法,对可能已经出故障,或者甚至已经死掉的application和Worker,进行清理,若drive中supervise属性若为true,会在挂掉的时候重新启动
总结一下清理机制
1,从内存缓存结构中移除。
2,从相关的组件的内存缓存中移除
3,从持久化存储中移除
注册机制
Master 接受注册的对象主要是 Driver, Application 和 Worker, 需要补充说明的是 Executor 不会注册给 Master,Executor 是注册给 Driver 中的 SchedulerBackend 的
具体注册步骤点击
master处理注册
如果master的状态是standby,不是active,那么什么也不会干
如果不是,则
- 用applicationDescription信息,创建applicationInfo
- 注册application
- 将Application加入缓存,将application加入等待调度序列-waitingApps
- 使用持久化引擎,将application进行持久化
状态改变处理机制源码分析
如果drive的状态是错误,完成,被杀掉,失败。那么就移除drive
- 用Scala的find()高阶函数,用寻找driveID对应的drive
- 如果找到了,some,样例类
- 将drive从内存缓存中清除
- 向completeDrivers中加入driver
- 使用持久化引擎去除drive的持久化信息
- 设置drive的state,exception
- 将drive所在的work,移除drive
- 调用scheduler方法
executor状态改变、
- 找到executor对应的app,然后在反过来通过app内部的executors缓存获取executor信息 如果有值
- 设置executor的当前状态
- 将drive同步发送executorUpdate消息
- 判断状态改变是否完成了,
- 从APP的缓存中移除executor
- 从运行的executor的work的缓存中移除executor
- 判断,如果executor的退出是非正常的
- 判断application当前的重试次数是否达到最大值
- 重新进行调度 如果未达到最大值,进行removeApplication操作(就是说反复调度失败,就认为application也失败)
资源调度机制源码分析(schedule(),两种资源调度算法)
首先判断master状态不是active的话,直接返回
也就是说不会standby master不会进行application等资源的调度
关于random.shuffle方法(在范围内取出一个随机数,然后交换)
取出workers中的所有之前注册上来的worker,进行过滤,必须是状态为alive的work
对状态为alive的work,使用random.shuffle方法进行打乱
调度drive, 只有用yarn-cluster模式提交的时候,才会注册drive,因为standalone模式和yarn-client模式,都会在本地直接启动drive,而不会来注册drive更不可能让master调度drive
drive的调度机制
- 遍历waitingDriversArrayBuffer,遍历条件是numWorkersVisited小于numWorkersactive
,即存在未遍历到的,继续遍历,而且,当前这个driver还没有被启动,也就是说是launched为false,如果当前这个worker的空闲内存量大于等于,drive需要的内存
并且worker的空闲CPU数量,大于等于drive需要的CPU数量 - 启动drive
- 并且将drive从waitingDrivers移除
- 将指针指向下一个worker
在某个work上启动drive
- 将driver加入worker的内部的缓存结构
- 将work内使用的内存和CPU数量,都加上driver需要的内存和CPU数量
- 同时把worker也加入到driver的内存的缓存结构中
- 然后调用worker的actor,给他发送launchDrive消息,让worker来启动drive
将driver的状态设置为running
application的资源调度机制
调度算法有两种,一种是spreadOutApps,另一种是非spreadOutApps,可以手动切换
spreadOutApps的算法
- 首先,遍历waitingApps中的ApplicationInfo,并且过滤出application还需要调度的core的application
- 从worker中,过滤出状态为active的,再次过滤可以被application使用的work,然后按照剩余CPU数量倒序排序
- 创建以个空数组,存储了要分配给每个worker的CPU数量
- 获取到底要分配多少cpu,去app剩余要分配的CPU的数量和worker总共可用的CPU数量的最小值
- while条件,只要分配CPU,还没分配完,就继续循环(这种算法实际是将要启动的executor平均分配到各个worker上)
- 每一个worker,如果空闲的cpu数量大于已经分配的出去的数量, 也就是说还有可分配cpu 将总共要分配的CPU数量-1,因为这里已经决定在这个worker上分配一个cpu
给这个worker分配的CPU数量加1 - 将指针移动到下一个worker
- 给每个worker分配完application要求的CPU core之后
- 遍历worker, 判断只要之前给这个worker分配到了core
首先在application内部缓存结构中,添加executor
并且创建executordesc对象,其中封装了,给这个executor多少CPU core
在脚本中可以指定CPU数量和executor数量,但是是基于总的CPU分配的,比如要求3个executor,每个要求3个CPU,有九个worker,每个有一个 CPU core,就会给每个worker分配一个core,然后每个work启动一个executor
那么就在worker上启动executor
将application设为running
非spreadOutApps的算法
- 将每一个application,尽可能少的分配到work上
- 首先,遍历worker,并且是状态为alive,还有空闲 CPU的worker
- 遍历application,并且是还有需要分配的core的application
- 判断,如果当时这个worker可以被application使用
- 取worker剩余的CPU数量,与APP要分配的CPU数量的最小值
- 如果剩余为零,那就不分配了
- 给app添加一个executor
- 在worker上启动executor
- 将application状态修改为running

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









