







今日内容
爬虫课程:
一 爬虫基本原理
二 request请求库
一 爬虫基本原理
1、什么是爬虫?
爬虫就是爬取数据
2、什么是互联网?
由一堆网络设备,把一台台计算机互联到一起称之为互联网。
3、互联网建立的目的
数据的传递与数据的共享
4、什么是数据?
例如:
电商平台的商品信息()
链家、自如租房平台的房源信息
股票证券投资信息()
...
12306、票务信息(抢票)
5、什么是上网?
普通用户:
打开互联网
--->输入网址
--->往目标主机发送请求
--->返回响应数据
--->把数据渲染到浏览器中
爬虫程序:
模拟浏览器
--->往目标主机发送请求
--->返回响应数据
--->解析并提取有价值的数据
--->保存数据(文件写入本地、持久化到数据库中)
6、爬虫全过程:
1.发送数据(请求库:Request/Selenium)
2.获取响应数据
3.解析数据(解析库:BeautifulSoup4)
4.保存数据(存储库:文件保存/MongoDB)
总结:我们可以把互联网中的数据比喻成一座宝藏,爬虫其实就是在挖去宝藏。
二 requests请求库
1、安装与使用
pip3 install requests
2、分析请求流程(模拟浏览器)
- 百度:
1.请求url
www.baidu.com
2.请求方式
GET
POST
例: 爬校花网小视频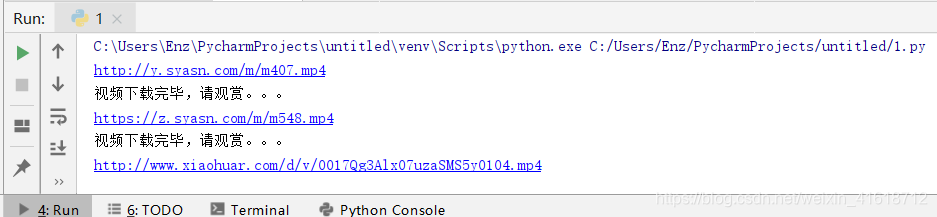
import time
import requests
# 爬虫三部曲
# 1.发送请求
def get_page(url):
response = requests.get(url)
return response
# 2.解析数据
import re
def parse_index(html):
#findall匹配所有
#re.findall('正则匹配规则','匹配文本','匹配模式')
#re.S:对全部文本进行搜索匹配
detail_urls = re.findall('<div class="items"><a class="imglink" href="(.*?)"',html,re.S)
return detail_urls
# 解析详情页
def parse_detail(html):
movie_url = re.findall('<source src="(.*?)">',html,re.S)
#print(movie_url)
if movie_url:
return movie_url[0]
# 3.保存数据
import uuid
# uuid.uuid4() 根据时间戳生成一段世界上唯一的字符串
def save_video(content):
with open(f'{uuid.uuid4()}.mp4','wb') as f:
f.write(content)
print('视频下载完毕,请观赏。。。')
# 测试用例:
if __name__ == '__main__':
for line in range(6):
url = f'http://www.xiaohuar.com/list-3-{line}.html'
# 发送请求
response = get_page(url)
# 解析主页页面
detail_urls = parse_index(response.text)
# 循环遍历详情页url
for detail_url in detail_urls:
# 往每一个详情页发送请求
detail_res = get_page(detail_url)
# 解析详情页获取视频url
movie_url = parse_detail(detail_res.text)
# 判断视频url存在则打印
if movie_url:
print(movie_url)
# 往视频url发送请求获取视频二进制流
movie_res = get_page(movie_url)
# 把视频的二进制流传给save_video函数去保存到本地
save_video(movie_res.content)
例:github自动登录
'''
POST请求自动登录github:
请求URL:
https://github.com/session
请求方式:
POST
请求头:
Cookie
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
请求体:
commit: Sign in
utf8: ✓
authenticity_token: eK6P0wQdoWlC7sLJYRe8a4O6XOjyIgicPxSAA1cmv2EIh2e2oGH3lVmzUpi+X4Emvg+MOUnAUEVNnQq6AwfYuQ==
login: 123
password: 123
webauthn-support: supported
'''
# 1、获取token随机字符串
'''
1.访问登录页面获取token随机字符串
请求URL:
https://github.com/login
请求方式:
GET
请求头:
COOKIES
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
2.解析并提取token字符串
# 正则
input type="hidden" name="authenticity_token" value="(.*?)" />
'''
import requests
import re
login_url = 'https://github.com/login'
# login页面的请求头信息
login_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
login_res = requests.get(url=login_url,headers=login_header)
# print(login_res.text)
# 解析提取token字符串
authenticity_token = re.findall('<input type="hidden" name="authenticity_token" value="(.*?)" />',login_res.text,re.S)[0]
print(authenticity_token)
# 获取login页面的cookies信息
# print(type(login_res.cookies))
#print(type(login_res.coolies.get_dict()))
login_cookies = login_res.cookies.get_dict()
# 2、开始登录github
'''
POST请求自动登录github:
请求URL:
https://github.com/session
请求方式:
POST
请求头:
Cookie
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
请求体:
commit: Sign in
utf8: ✓
authenticity_token: eK6P0wQdoWlC7sLJYRe8a4O6XOjyIgicPxSAA1cmv2EIh2e2oGH3lVmzUpi+X4Emvg+MOUnAUEVNnQq6AwfYuQ==
login: Cuteni
password: 1027kekaini
webauthn-support: supported
'''
# session登录url
session_url = 'https://github.com/session'
#请求头信息
session_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
#请求体信息
form_data = {
"commit": "Sign in",
"utf8": "✓",
"authenticity_token":authenticity_token,
"login": "Cuteni",
"password": "1027kekaini",
"webauthn-support": "supported"
}
session_res = requests.post(url=session_url,headers=session_headers,cookies=login_cookies,data=form_data)
with open('github1.html','w',encoding='utf-8') as f:
f.write(session_res.text)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









