







首先先复习一下条件概率、全概率、贝叶斯公式的推导过程。并举了三个贝叶斯的相关的例子。 贝叶斯网络又称信念网络,是有向无环图模型,是一种概率图形模型。
贝叶斯网络又称信念网络,是有向无环图模型,是一种概率图形模型。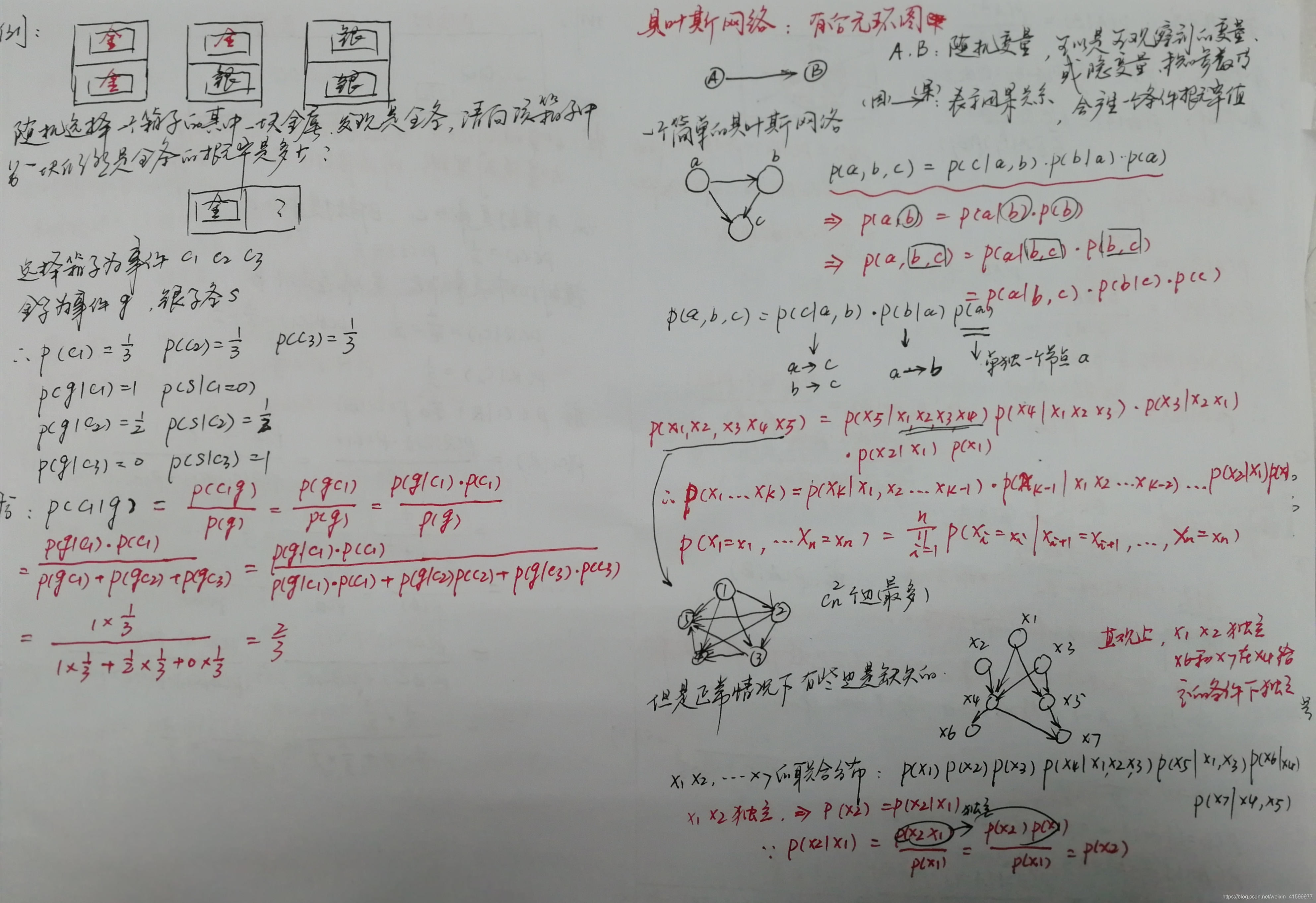

 后面会针对贝叶斯网络的实际应用进行说明…
后面会针对贝叶斯网络的实际应用进行说明…
 博客先复习了条件概率、全概率、贝叶斯公式的推导过程,并给出三个相关例子。介绍贝叶斯网络是有向无环图模型和概率图形模型,后续将说明其实际应用。
博客先复习了条件概率、全概率、贝叶斯公式的推导过程,并给出三个相关例子。介绍贝叶斯网络是有向无环图模型和概率图形模型,后续将说明其实际应用。
博客先复习了条件概率、全概率、贝叶斯公式的推导过程,并给出三个相关例子。介绍贝叶斯网络是有向无环图模型和概率图形模型,后续将说明其实际应用。
博客先复习了条件概率、全概率、贝叶斯公式的推导过程,并给出三个相关例子。介绍贝叶斯网络是有向无环图模型和概率图形模型,后续将说明其实际应用。
首先先复习一下条件概率、全概率、贝叶斯公式的推导过程。并举了三个贝叶斯的相关的例子。贝叶斯网络又称信念网络,是有向无环图模型,是一种概率图形模型。后面会针对贝叶斯网络的实际应用进行说明…
 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























