






 本文介绍了Python中使用正则表达式进行网页内容抓取的方法,包括re模块的findall、search、match、finditer和compile等关键函数。通过实例展示了如何匹配和提取字符串中的特定信息,以及如何利用分组功能进行更精确的数据筛选。此外,还提到了在线测试正则表达式的工具,帮助开发者提升正则表达式的运用效率。
本文介绍了Python中使用正则表达式进行网页内容抓取的方法,包括re模块的findall、search、match、finditer和compile等关键函数。通过实例展示了如何匹配和提取字符串中的特定信息,以及如何利用分组功能进行更精确的数据筛选。此外,还提到了在线测试正则表达式的工具,帮助开发者提升正则表达式的运用效率。
正则表达式:
Regular Expression,正则表达式,一种使用表达式的方式对字符串进行匹配的语法规则.
我们抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容.用正则再合适不过了
正则的优点:速度快,效率高,准确性高
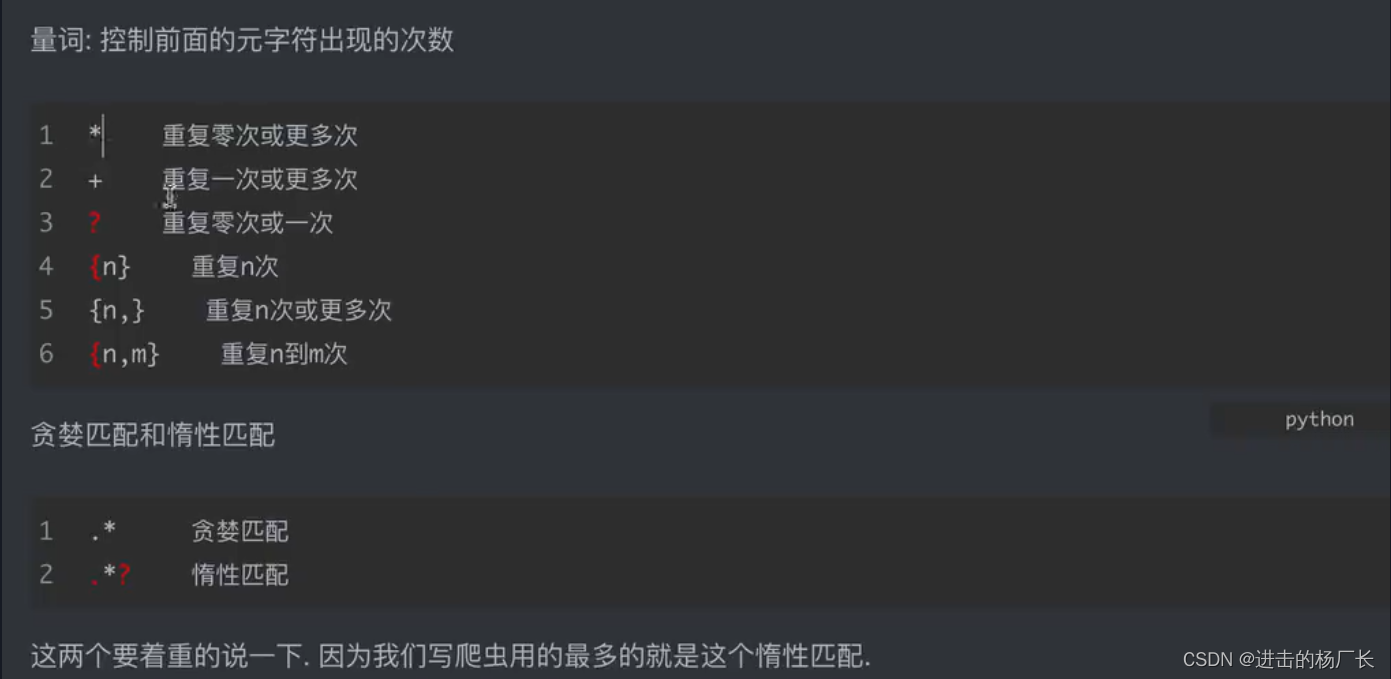
正则的语法:使用元字符进行排列组合用来匹配字符串
在线测试正则表达式:https:/tool.oschina.netlregex
元字符:具有固定含义的特殊符号
常用元字符: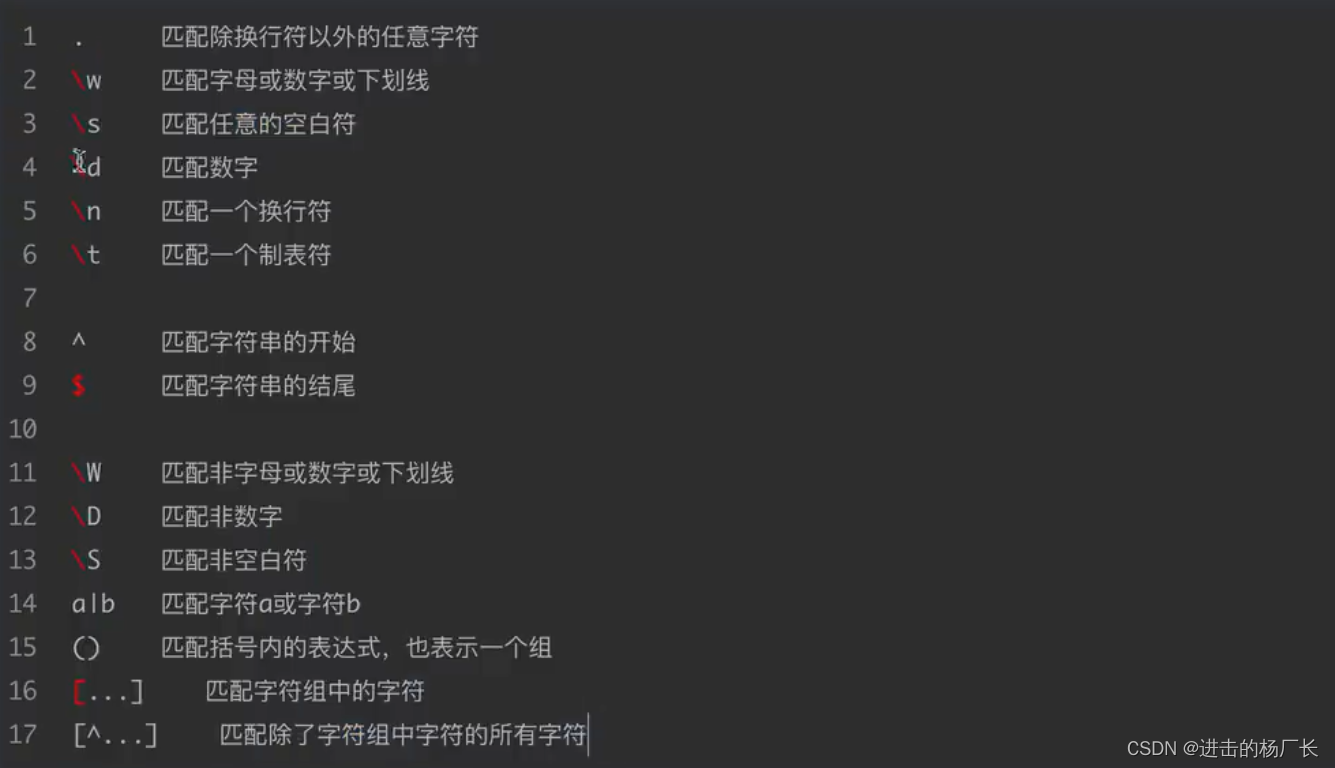
re模块
那么接下来的问题是,正则我会写了,怎么在python程序中使用正则呢?答案是用re模块
re模块中我们只需要记住这么几个功能就足够我们使用了.
1. findall 查找所有.返回list I
import re
lst = re.findall("m","mai le fo len,mai ni mei! ")
print(lst)
#['m', 'm', 'm']
lst = re.findall(r"\d+","5点之前.你要给我5000万")
print(lst)
#['5', '5000']
2. search 会进行匹配.但是如果匹配到了第一个结果.就会返回这个结果.如果匹配不上search返回的则是None
import re
ret = re.search(r'\d','5点之前,你要给我5000万').group()
print(ret)
#5
3. match只能从字符串的开头进行匹配
import re
ret = re.match('a', 'abc'). group()
print(ret)
#a
4. finditer,和findall差不多.只不过这时返回的是迭代器(重点)
import re
it = re.finditer("m","mai le fo len,mai ni mei!")
for el in it:
print(el.group())# 依然需要分组
#m
#m
#m5.compile(可以将一个长长的正则进行预加载.方便后面的使用
import re
obj = re.compile(r'\d{3}') # 将正则表达式编译成为一个正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc6234eeee')# 正则表达式对象调用search,参数为待匹配的字符串
print(ret.group())
#结果:123
6.正则中的内容如何单独提取?
单独获取到正则中的具体内容可以给分组起名字
import re
s= """
<div class='西游记'><span id='10010'>中国联通</span></div>
"""
obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>\w+)</span>",re.S)
result = obj.search(s)
print(result.group()) #结果:<span id='10010'>中国联通</span>
print(result.group("id")) #结果:10010 #获取id组的内容
print(result.group("name")) #结果:中国联通 #获取name组的内容
这里可以看到我们可以通过使用分组.来对正则匹配到的内容进一步的进行筛选.
7、#预加载正则表达式
import re
obj = re.compile(r"\d+")
ret = obj.finditer("我的电话号是:10086,我女朋友的电话是:10010")
for it in ret:
print(it.group())
#结果:
#10086
#10010

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









