







使用sklearn构建完整的机器学习项目流程
完整的机器学习项目流程:
- 明确项目任务:回归/分类
- 收集数据集并选择合适的特征。
- 选择度量模型性能的指标。
- 选择具体的模型并进行训练以优化模型。
- 评估模型的性能并调参。
使用sklearn构建完整的回归项目
- 案例一:波士顿房价
- 收集数据集并选择合适的特征:
from sklearn import datasets
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
boston_data.head()
-
选择度量模型性能的指标
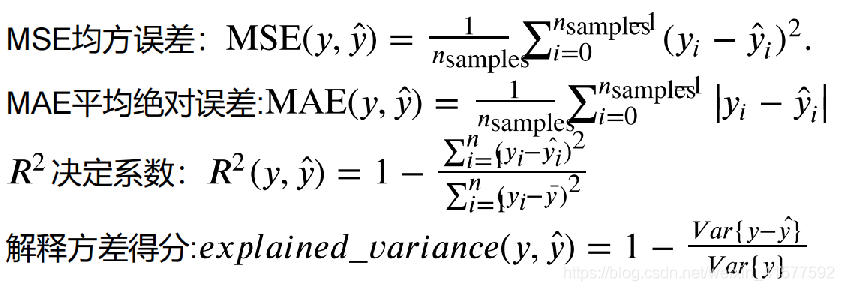
-
选择具体的模型并进行训练
线性回归模型(最小二乘估计、几何解释、概率视角)、线性回归的推广(多项式回归、广义可加模型GAM)、回归树、支持向量机回归SVR
# 线性回归模型
from sklearn import linear_model # 引入线性回归方法
lin_reg = linear_model.LinearRegression() # 创建线性回归的类
lin_reg.fit(X,y) # 输入特征X和因变量y进行训练
print("模型系数:",lin_reg.coef_) # 输出模型的系数
print("模型得分:",lin_reg.score(X,y)) # 输出模型的决定系数R^2
# 多项式回归
from sklearn.preprocessing import PolynomialFeatures
X_arr = np.arange(6).reshape(3, 2)
print("原始X为:\n",X_arr)
poly = PolynomialFeatures(2)
print("2次转化X:\n",poly.fit_transform(X_arr))
poly = PolynomialFeatures(interaction_only=True)
print("2次转化X:\n",poly.fit_transform(X_arr))
# GAM
from pygam import LinearGAM
gam = LinearGAM().fit(boston_data[boston.feature_names], y)
gam.summary()
# 回归树
from sklearn.tree import DecisionTreeRegressor
reg_tree = DecisionTreeRegressor(criterion = "mse",min_samples_leaf = 5)
reg_tree.fit(X,y)
reg_tree.score(X,y)
# SVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler # 标准化数据
from sklearn.pipeline import make_pipeline # 使用管道,把预处理和模型形成一个流程
reg_svr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))
reg_svr.fit(X, y)
reg_svr.score(X,y)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









