







黑客攻防

一、网络安全概述
本单元旨在帮助学生建立起网络安全的基本概念,了解目前阶段来自网络威胁的主要挑战,网络安全学科所涉及到的技术门类和专业范围,网络安全领域对从业者的技术要求。

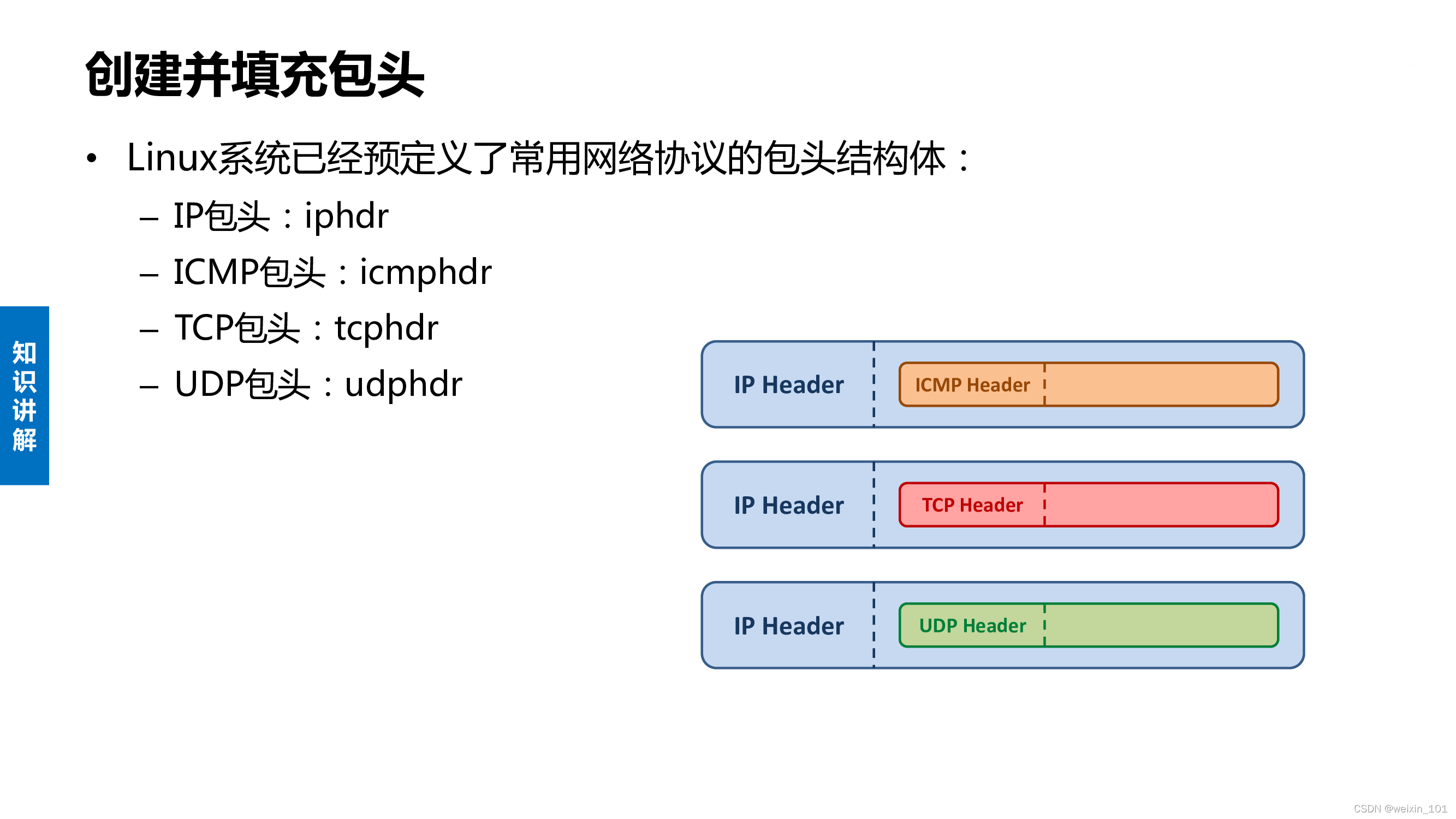
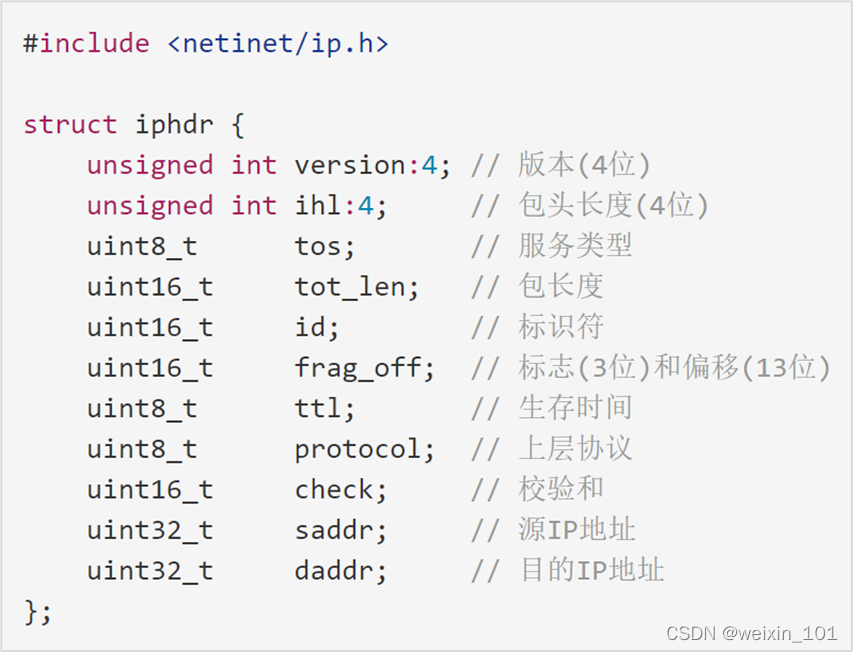
二、网络协议栈
Linux作为应用最广泛的开源操作系统之一,不仅能够提供终端主机所需要的各种网络协议软件,而且还能够实现网桥、路由器等网络设备的基本功能
为了帮助学生获得自主知识产权网络安全软件产品的研发能力,本课程所有案例均在Linux操作系统上完成
本单元将从两个方面对Linux网络协议栈展开讨论,一是结合Linux网络协议栈的设计特点,介绍网络协议栈源码的几个主要功能模块,二是讨论Linux网络协议栈源码

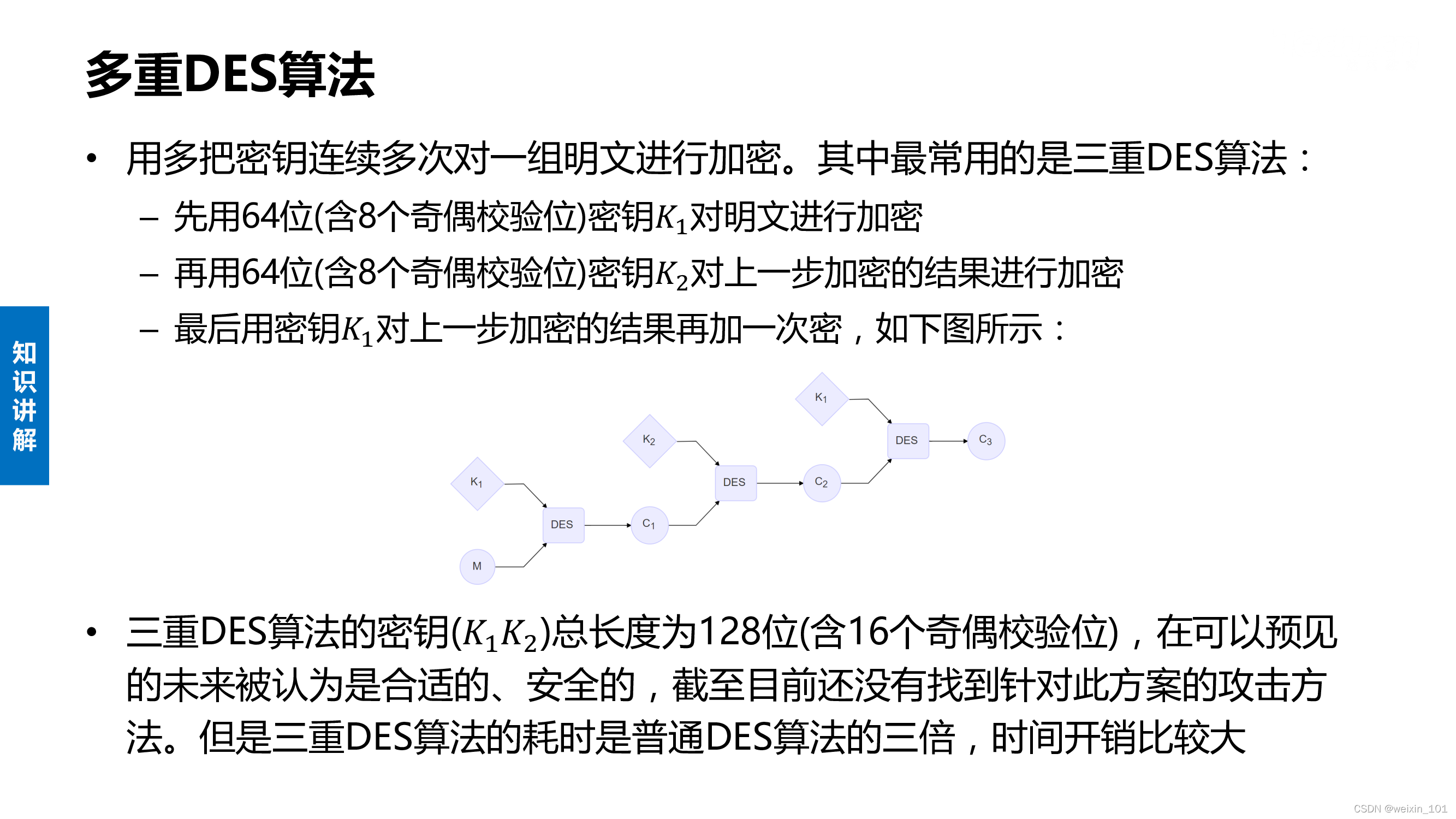
三、对称密钥
DES算法是一种典型的对称密钥加密算法,也是应用密码学中最基本的加密算法之一,目前广泛应用于网络通信加密、数据存储加密、口令与访问控制系统之中
掌握DES算法在网络通信中的应用对于理解对称加密算法大有裨益
本单元以加密TCP聊天程序为案例,研究基于DES算法的通信加密应用软件的设计和编程方法
本单元旨在帮助学生理解对称加密算法DES的基本工作原理,掌握将DES算法应用于网络通信的设计与软件编程的基本方法,掌握Linux操 作系统socket编程的基本方法
通过本单元的学习,学生应能利用socket编写一个TCP聊天程序,其聊天内容在传输过程中通过DES算法加密和解密
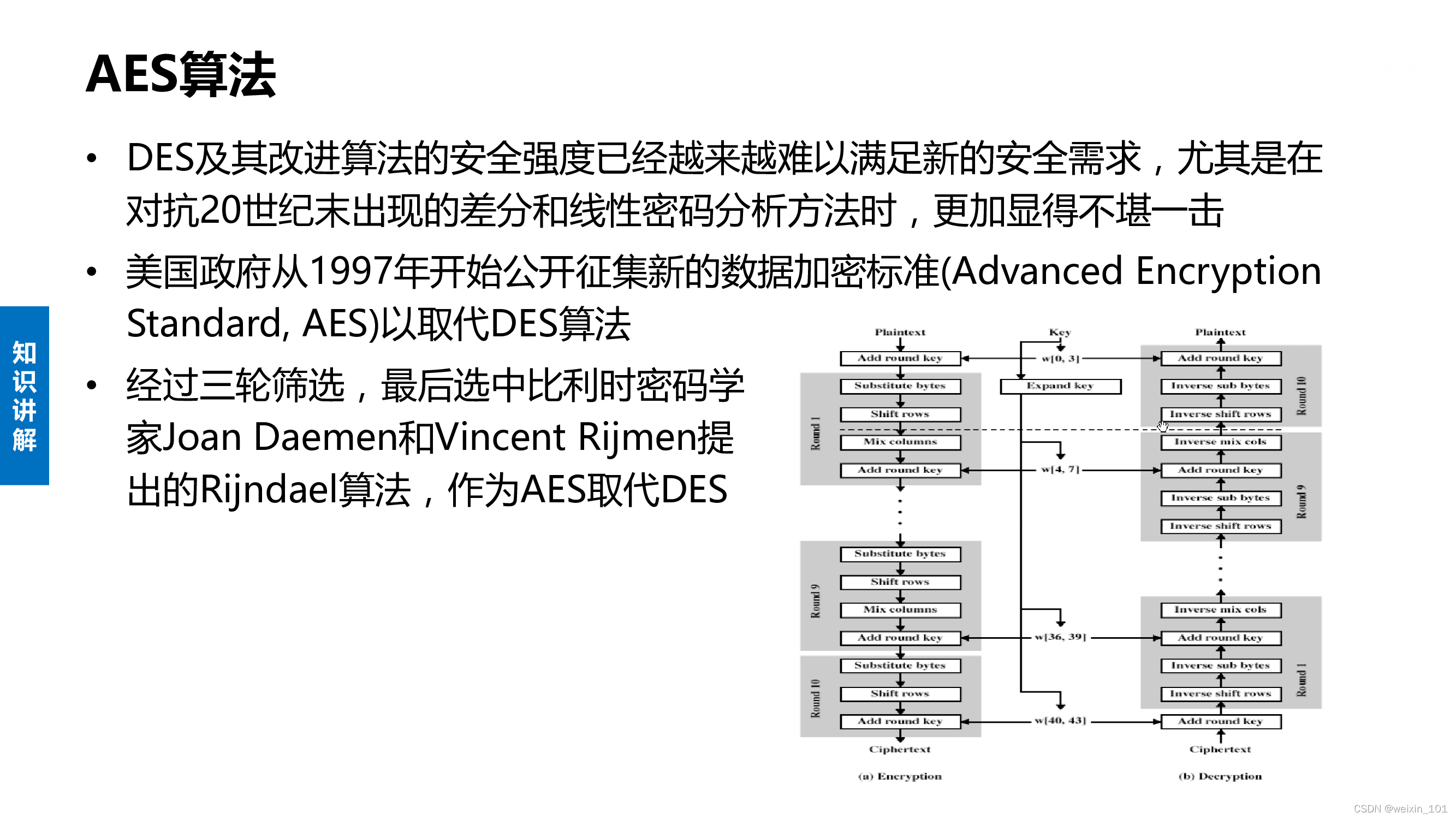
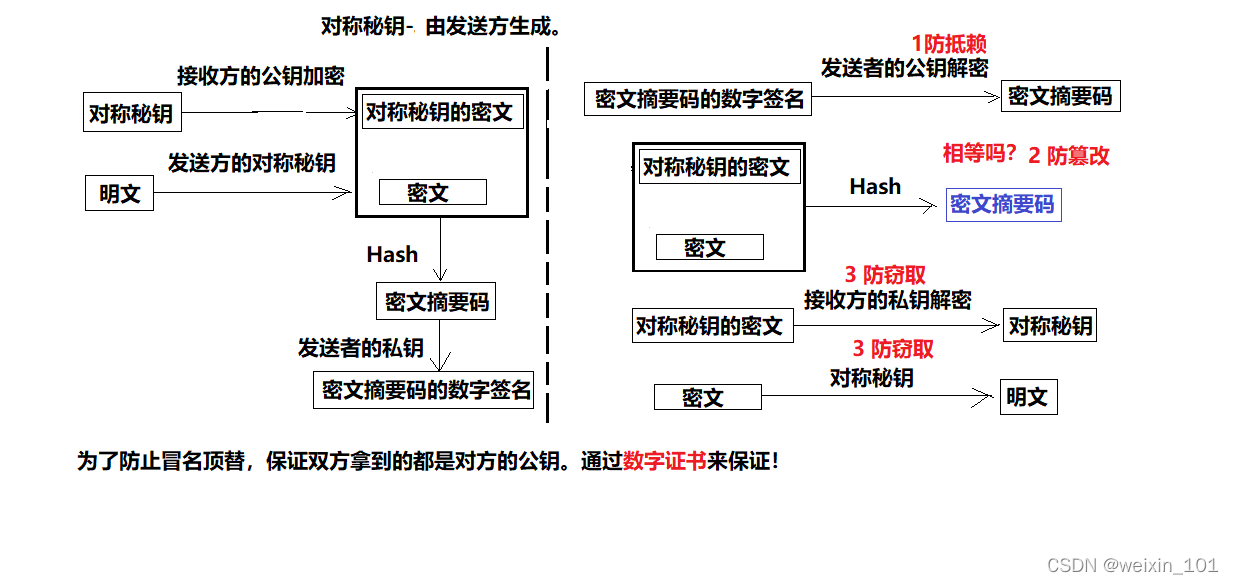
四、公钥密码
在讨论了对称加密算法DES的原理与实现的基础上,本单元以典型的非对称加密算法RSA为例,以进一步完善加密TCP聊天程序为目标, 系统地讨论公钥密码体系与RSA算法的基本工作原理和应用软件编程方法
本单元旨在帮助学生理解非对称加密算法RSA的基本工作原理,掌握将RSA算法应用于网络通信的设计与软件编程的基本方法,了解在 Linux操作系统上实现异步I/O的基本方法
通过本单元的学习,学生应能在上一单元加密聊天程序的基础上,增加基于RSA算法的密钥分发功能,用公私钥对DES密钥加解密


五、消息摘要
MD5是目前最流行的消息摘要算法,已被广泛应用于数字签名、文件完整性检测等领域
熟悉MD5算法对于开发安全的网络应用程序具有重要的意义
本单元旨在帮助学生理解MD5消息摘要算法的基本原理,掌握利用MD5算法生成消息摘要的计算方法,掌握将MD5算法应用于文件完整性校验软件的基本设计与编程方法,掌握在Linux操作系统中检查文件完整性的基本方法
通过本单元的学习,学生应能正确实现MD5摘要的计算过程,对任意长度的字符串和文件能够生成128位长的MD5摘要,并通过该摘要验证文件的完整性

六、嗅探器
网络监控软件能够监测网络流量,发现网络中异常的数据流,有效地发现和防御网络攻击,是保证网络安全的重要工具和手段之一,也是网络安全技术人员必须掌握的重要技能之一
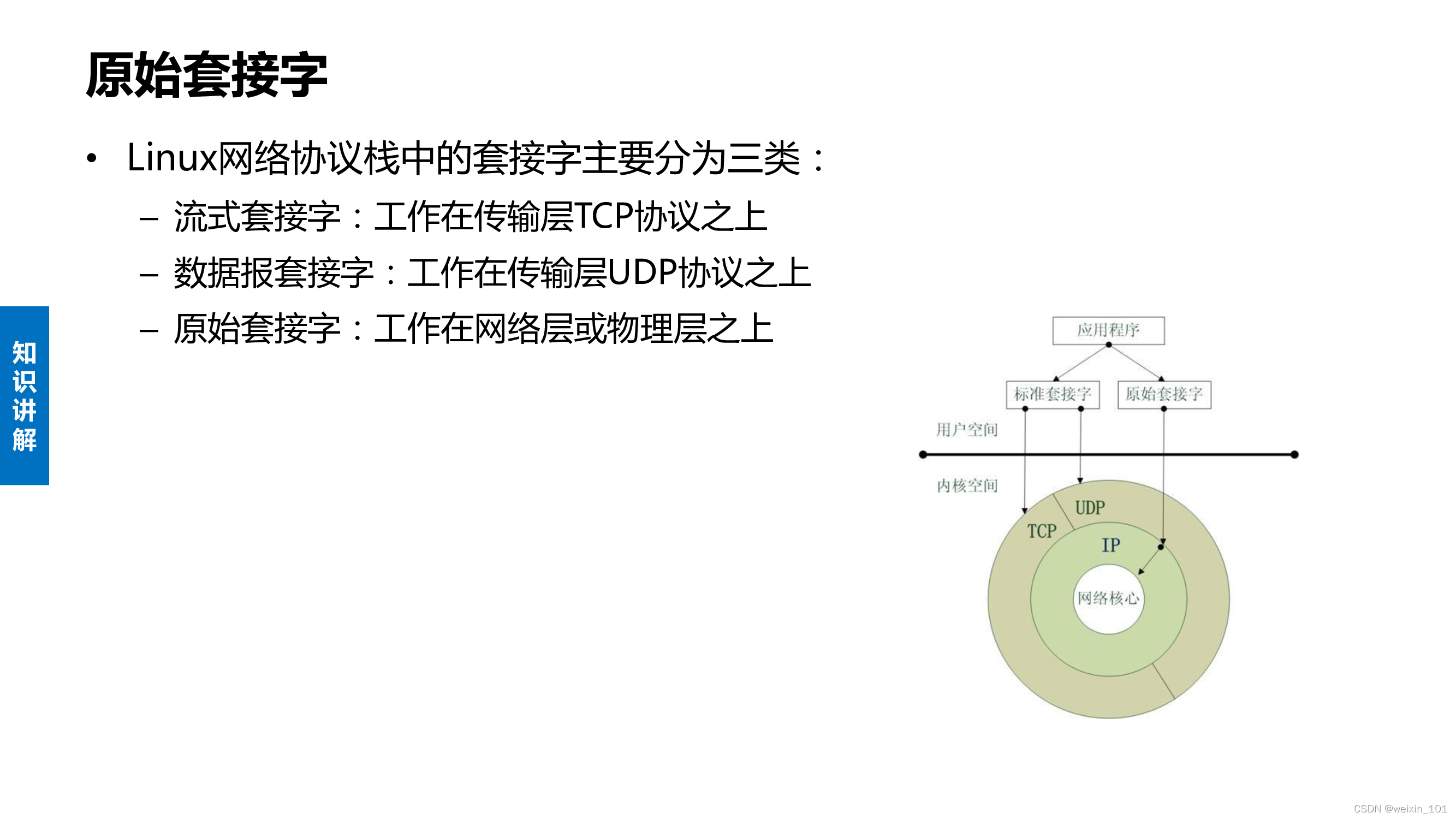
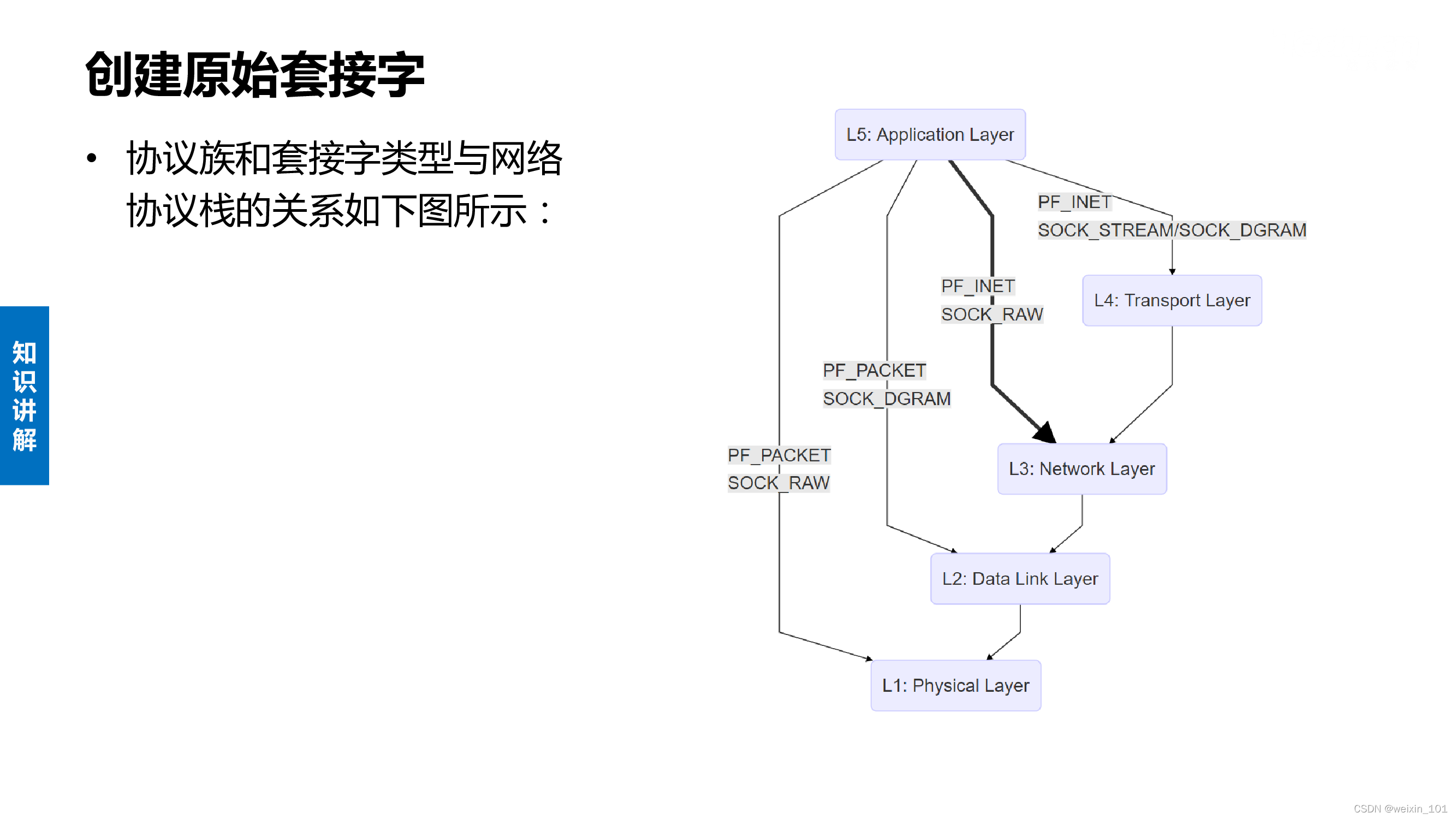
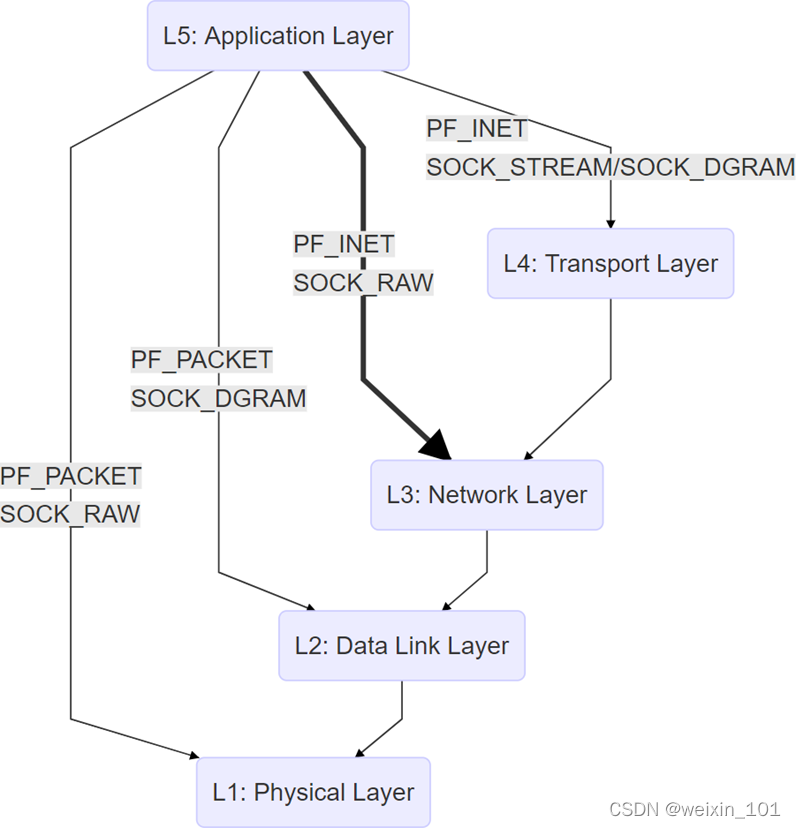
本单元研究基于原始套接字(Raw Socket)的网络嗅探器(Sniffer)系统的设计和软件编程方法
本单元旨在帮助学生理解Sniffer的基本工作原理和实现方法,掌握Raw Socket的基本工作原理,掌握TCP/IP、ICMP等协议及socket编程方法
通过本单元的学习,学生应能利用原始套接字编写一个网络嗅探器捕获网络数据包,分析基本的数据包信息并实现简单的过滤器功能
七、安全Web服务器
Web服务使用HTTP协议传输明文,重要数据有被第三方截获的风险。安全超文本传输协议(HTTP over SSL,HTTPS)通过安全套接字层 (Secure Socket Layer,SSL)加密HTTP数据,保护数据在Web系统中的传输安全
掌握基于OpenSSL的安全Web服务器软件的设计和编程方法,对于提高Web系统的安全性有着重要的意义
本单元旨在帮助学生理解HTTPS协议和SSL协议的基本工作原理,掌握使用OpenSSL库编程的方法,掌握安全Web服务器的基本设计与实现方法
通过本单元的学习,学生应能在Linux平台上基于OpenSSL库,编写一个安全Web服务器程序,该服务器能并发处理多个请求,至少支持 HTTPS协议下最基本的GET命令,进而扩展到支持HEAD、POST以及DELETE等命令,编写必要的客户端程序,以发送HTTPS请求,并显示服务器返回的响应结果
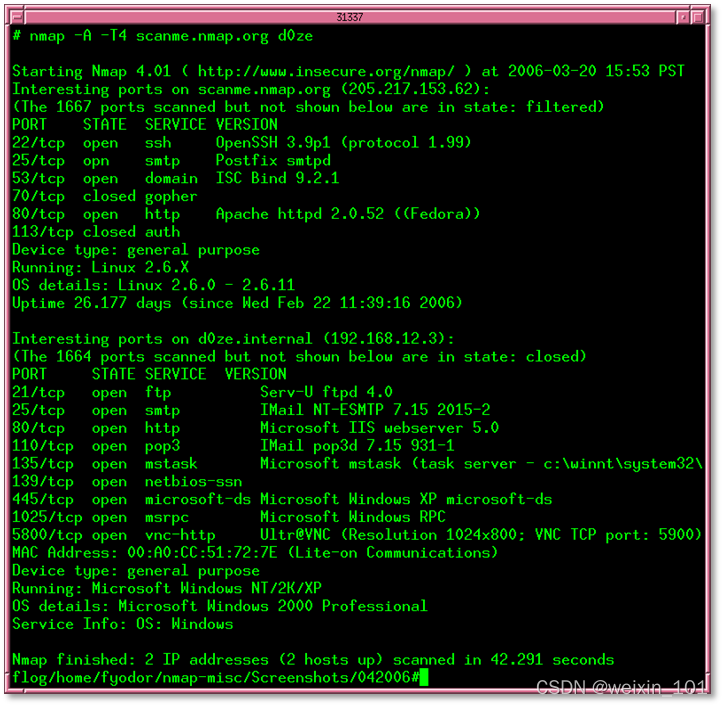
八、端口扫描
网络端口扫描器不仅可以发现目标主机的开放端口和操作系统类型,还可以获知系统的安全漏洞和口令缺陷,既是重要的网络检测设备,同时也是黑客的攻击工具
掌握端口扫描器的基本工作原理和软件设计方法是对网络安全技术人员的起码要求,对维护网络安全,了解黑客攻击手段有着重要的意义
本单元旨在帮助学生理解网络端口扫描器的基本结构、工作原理和设计方法,掌握TCP CONNECT扫描、TCP SYN扫描、TCP FIN扫描以 及UDP扫描的基本工作原理、设计与实现方法,掌握ping程序的设计与实现方法,掌握Linux操作系统多线程编程的基本方法
通过本单元的学习,学生应能编写端口扫描程序,实现TCP CONNECT扫描、TCP SYN扫描、TCP FIN扫描和UDP扫描等四种基本扫描方式,设计并实现ping程序,探测目标主机是否可达
九、网络诱骗
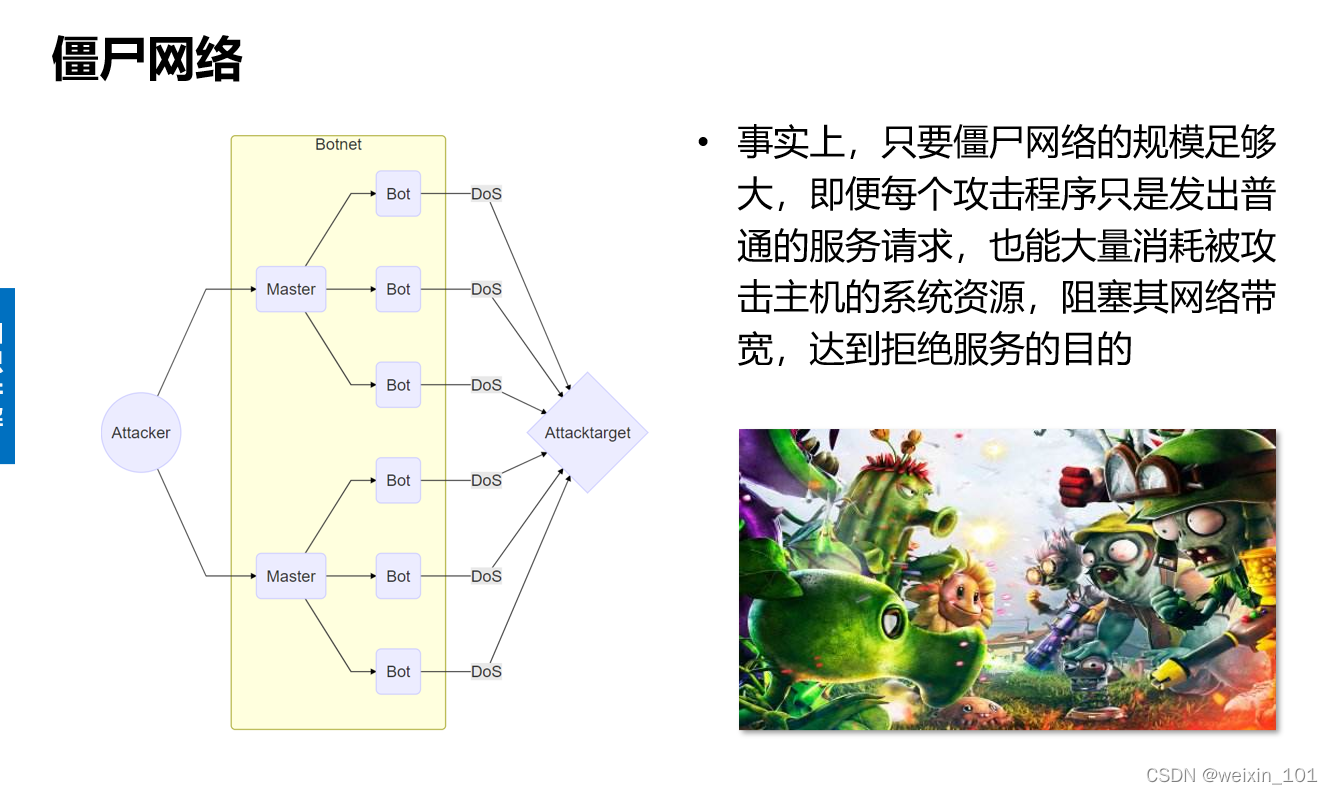
网络诱骗系统通常会通过一些诱饵来诱惑潜在的攻击者发起攻击,同时对其攻击行为进行监控和记录,评估其危害,搜集犯罪证据,以达到主动保护系统安全的目的
网络诱骗系统的主要技术包括伪装技术、监控技术和隐藏技术
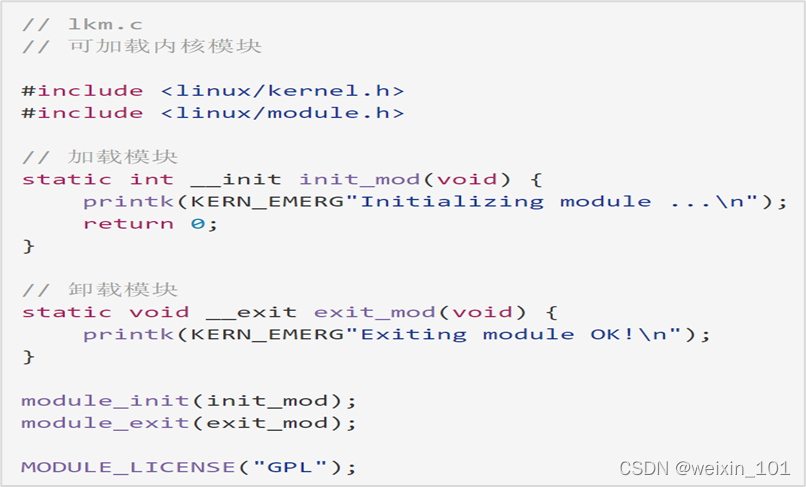
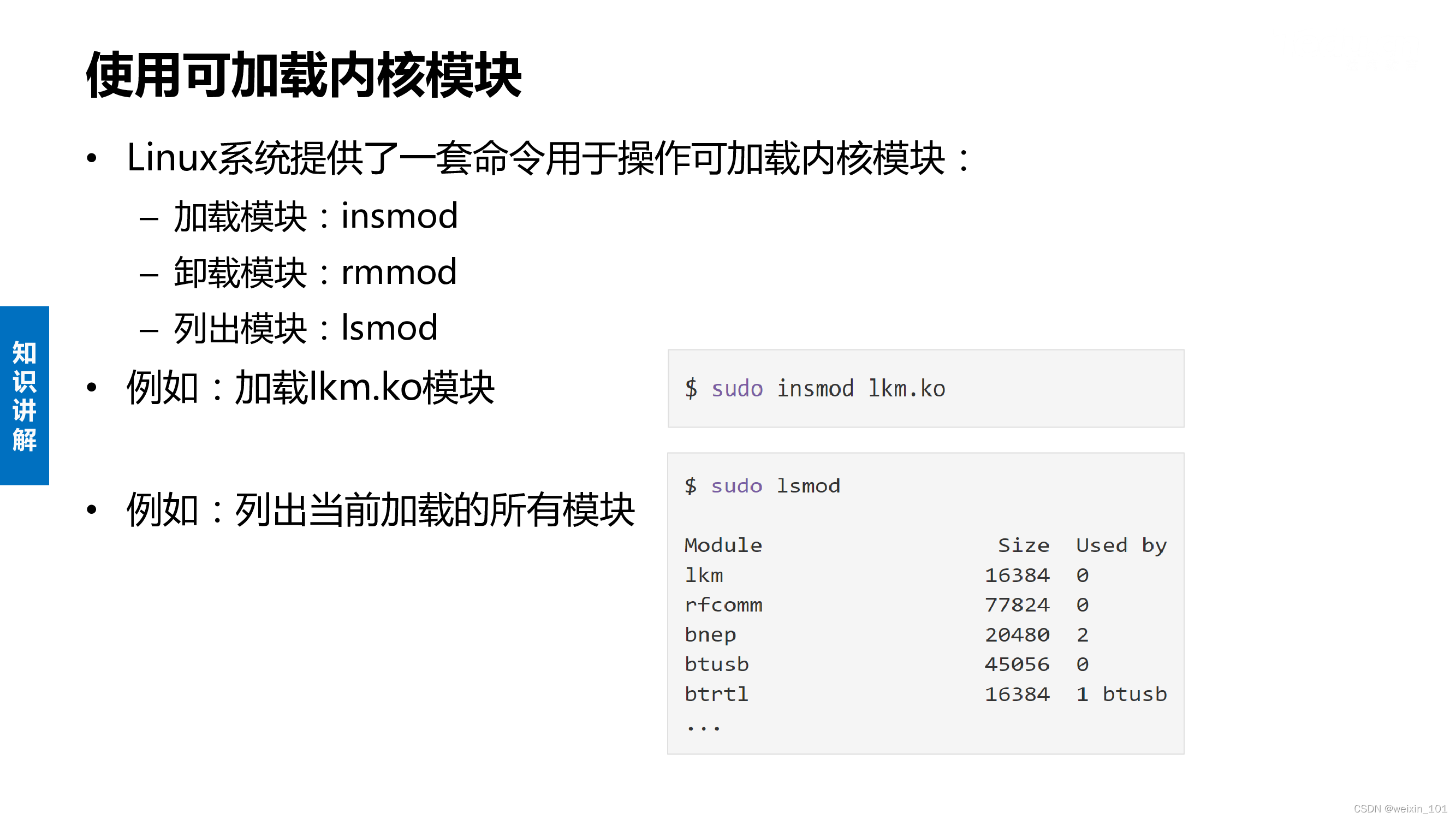
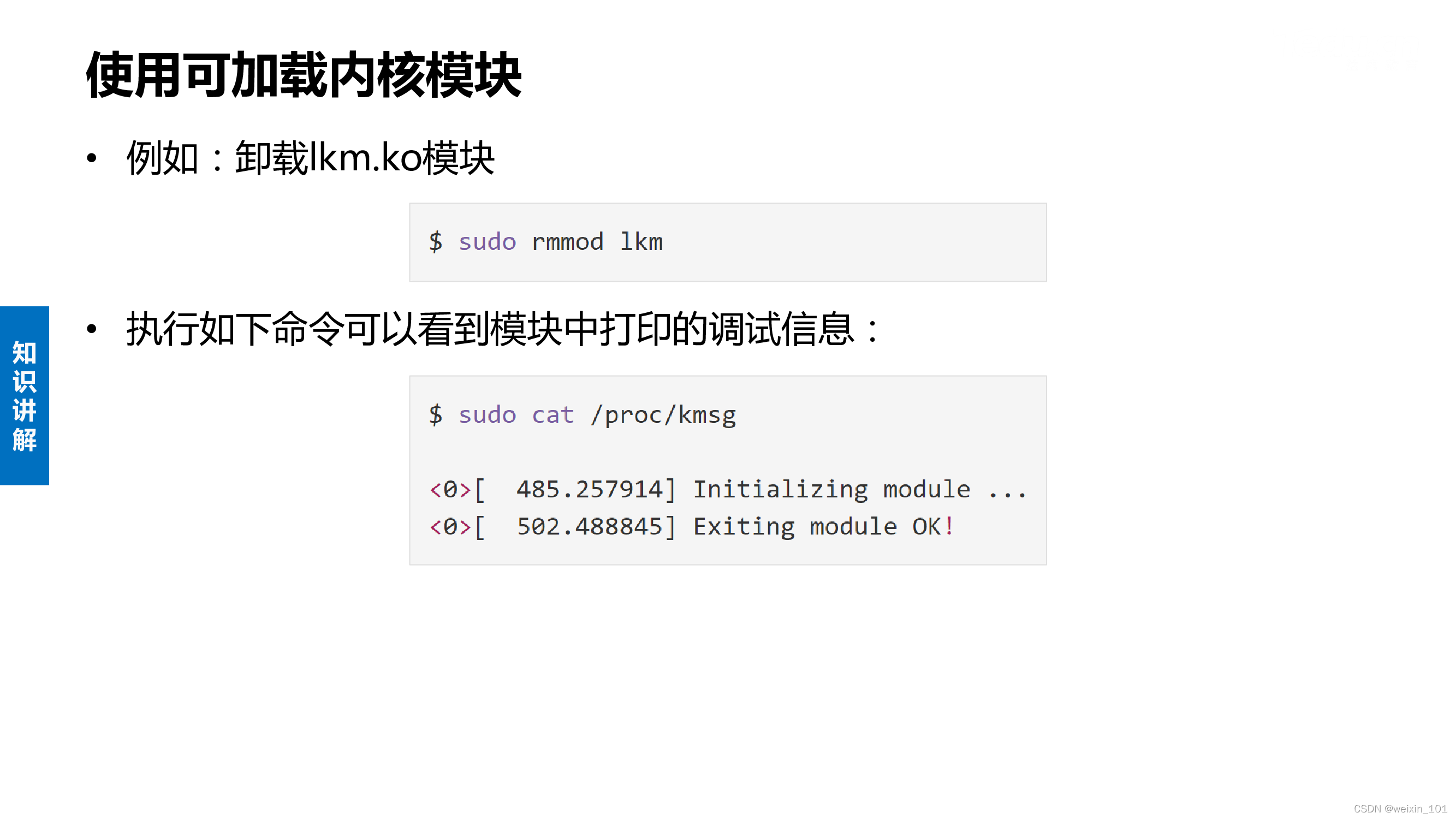
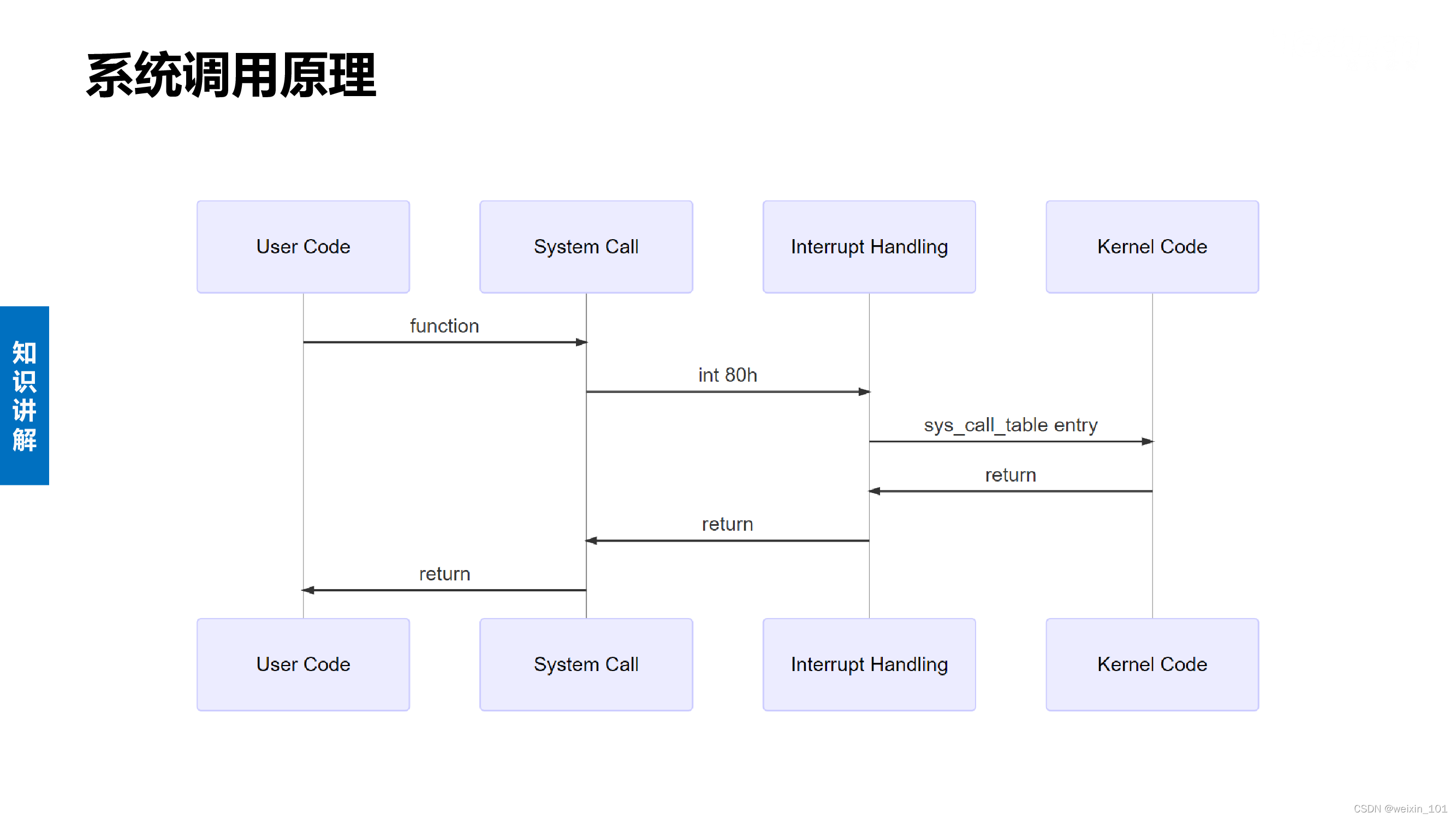
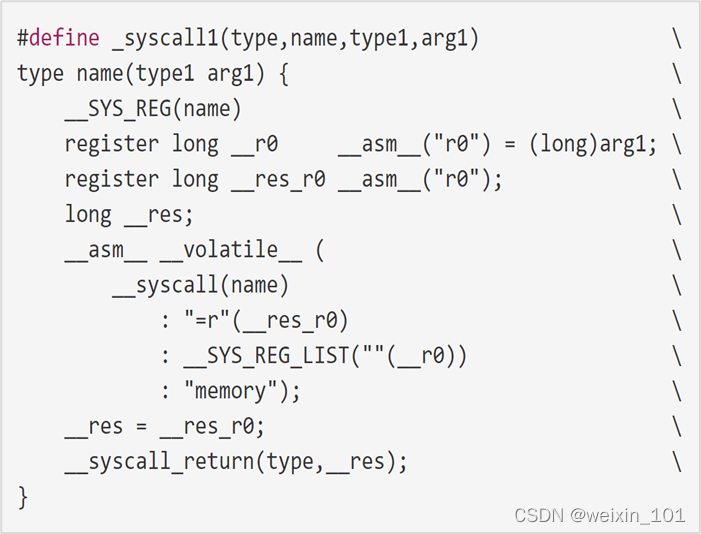
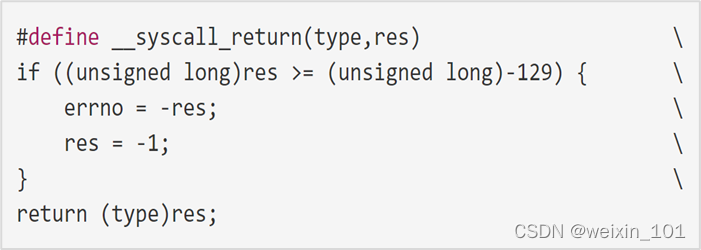
本单元旨在帮助学生理解网络诱骗系统的基本工作原理,理解Linux系统调用的原理和实现,以及利用钩子技术扩展操作系统自带编程接口 的方法,掌握可加载内核模块编程的相关知识和方法,了解Linux系统中程序隐藏的方法
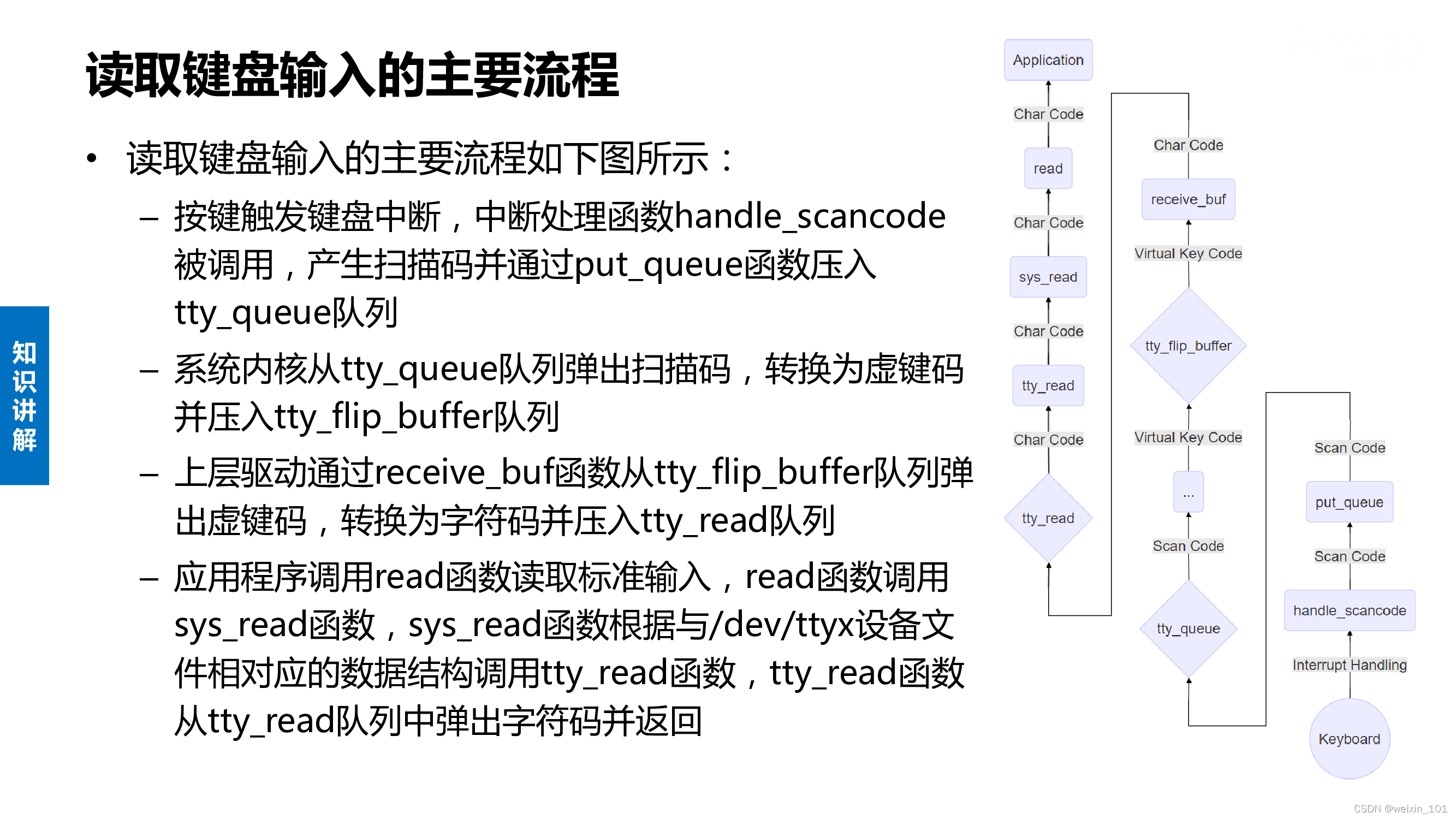
通过本单元的学习,学生应能设计并实现一个简单的网络诱骗系统,该系统运行在Linux操作系统的核心层(Ring 0),将用户终端登录后的键盘输入记录在日志文件中,甚至可以尝试为该系统添加隐藏(模块、文件、通信等)功能
十、入侵检测
入侵检测系统(IDS)是一种对网络传输进行实时监测,并在发现可疑情况时发出警报或采取主动防御措施的网络安全设备
本单元在系统分析入侵检测系统基本工作原理的基础上,以基于特征的入侵检测系统为案例,研究入侵检测系统的设计与软件编程方法
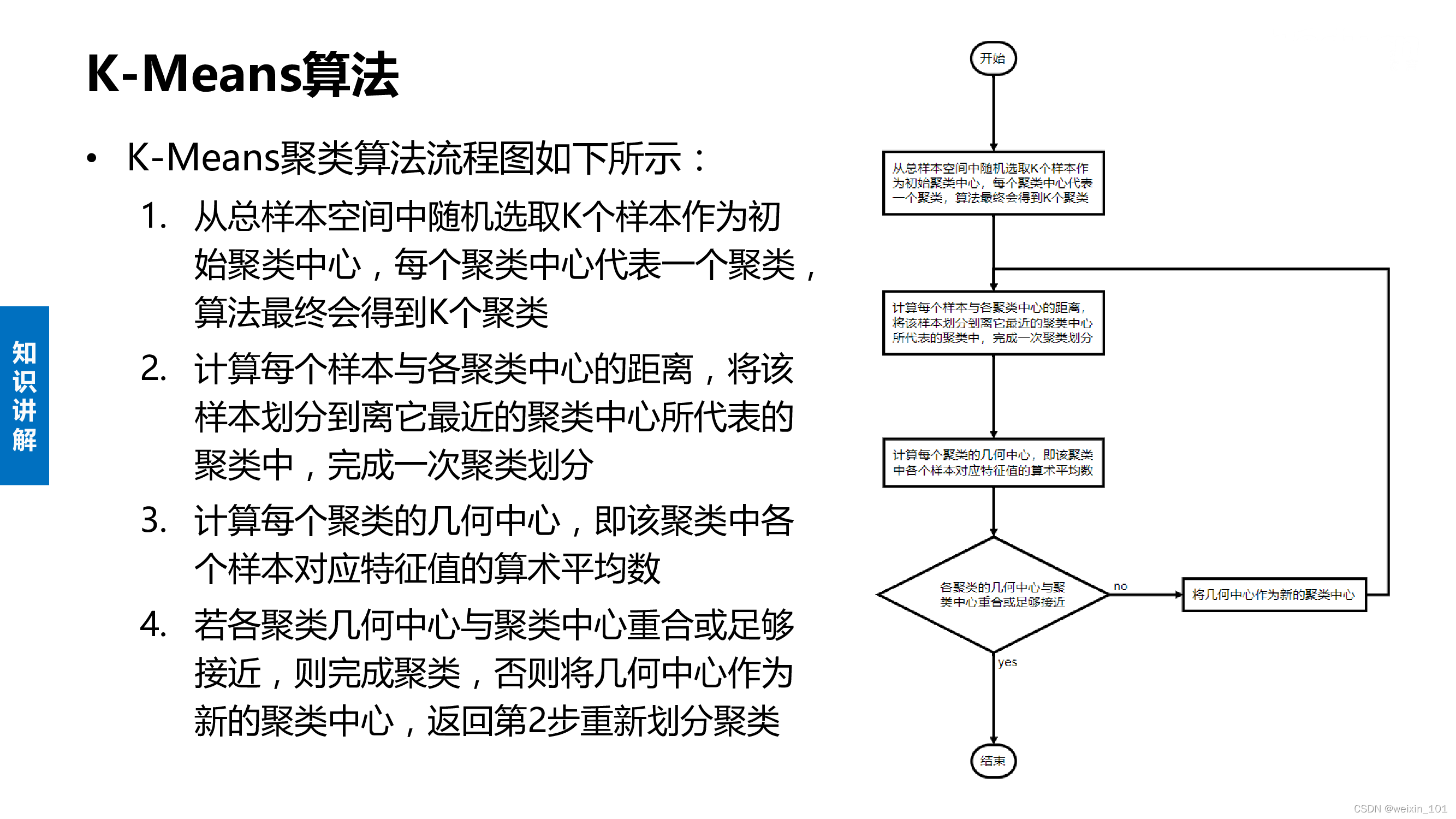
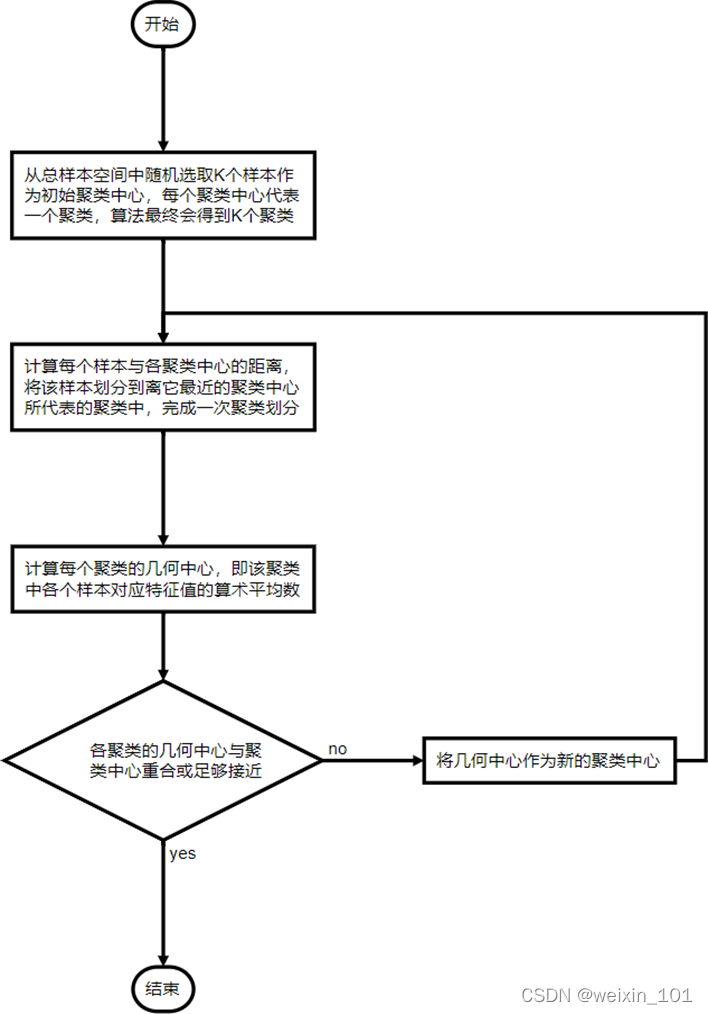
本单元旨在帮助学生掌握基于特征的入侵检测系统的基本工作原理、设计和实现方法,掌握K-Means聚类算法的计算过程,掌握在网络安全系统中应用数据挖掘技术的基本概念和方法
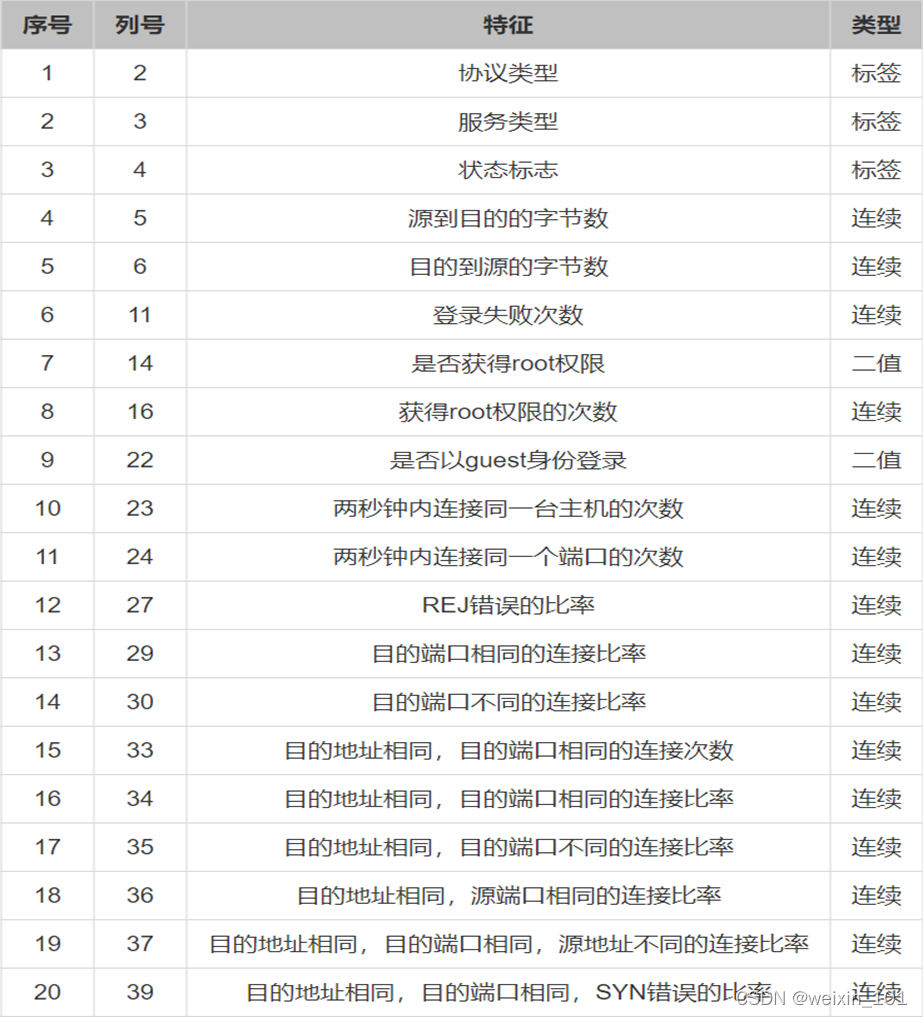
通过本单元的学习,学生应能使用KDD Cup 1999数据集进行聚类分析,训练一个用于入侵检测的聚类模型,并使用该模型对测试数据进行预测
十一、防火墙
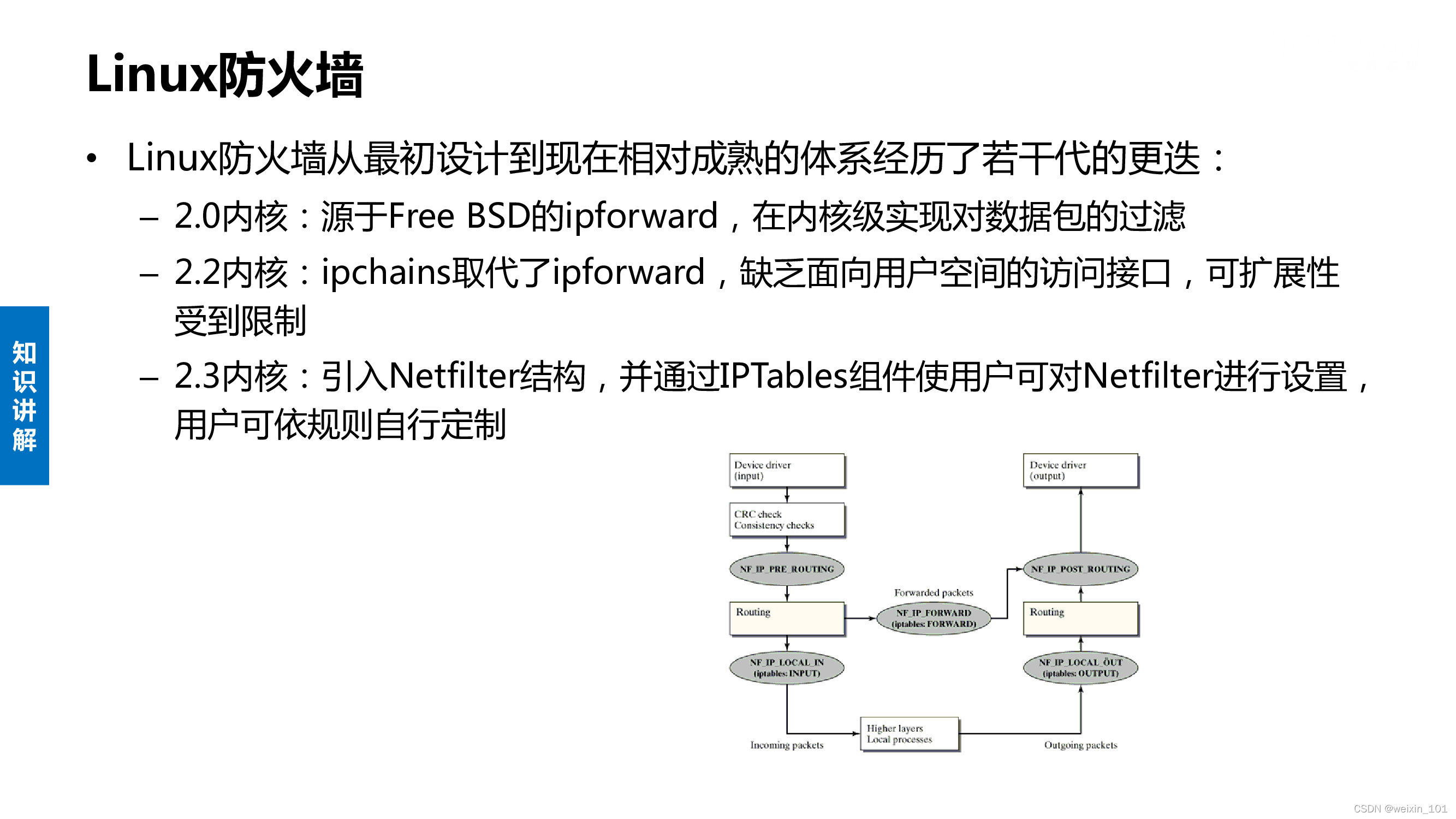
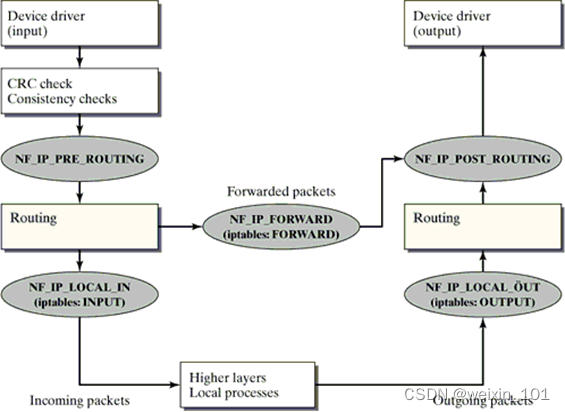
防火墙通过在网络与网络或网络与主机之间建立访问控制以及地址隐藏等技术手段,保护网络资源免受非法侵害,是目前常用的网络安全设备之一
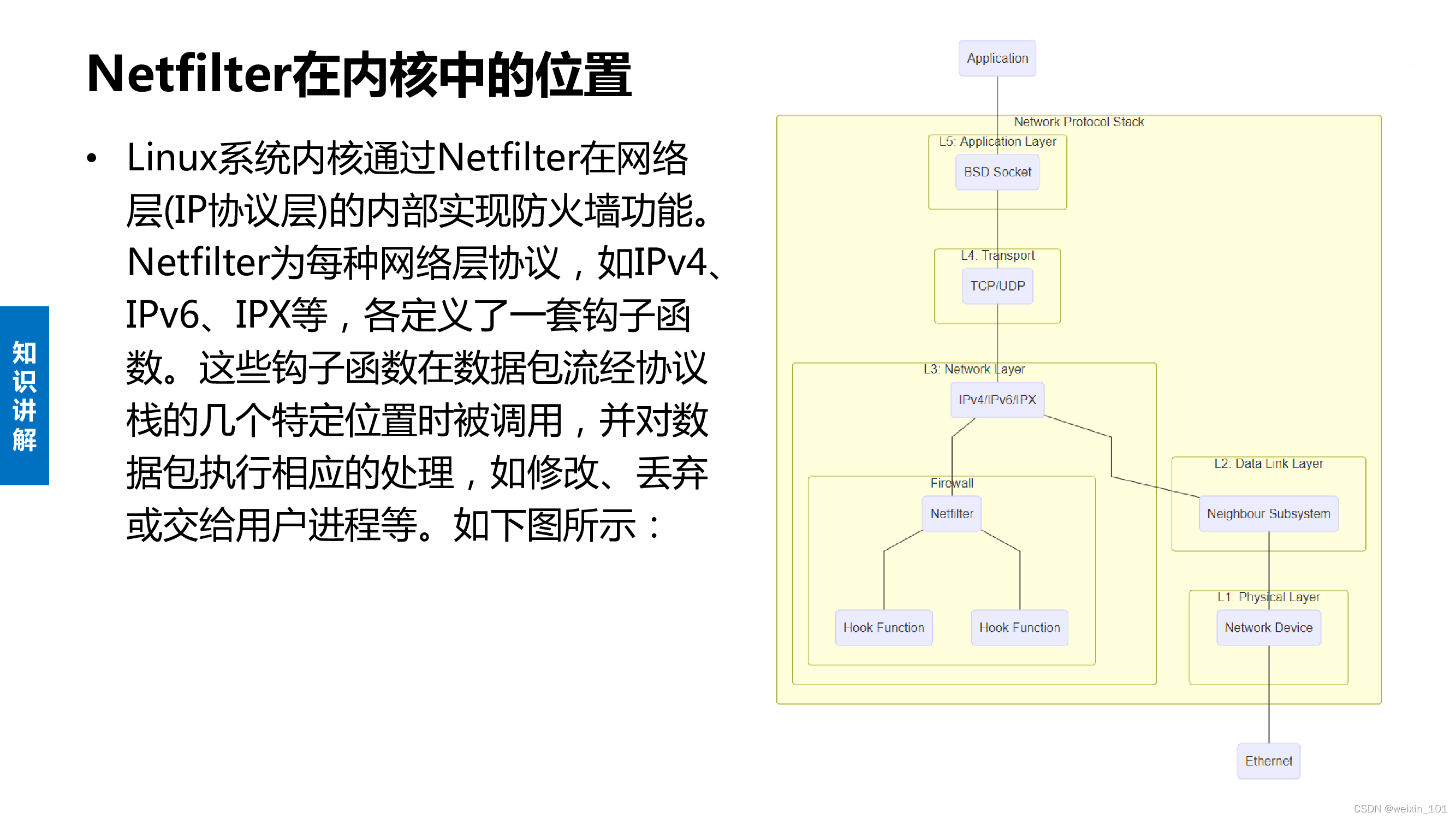
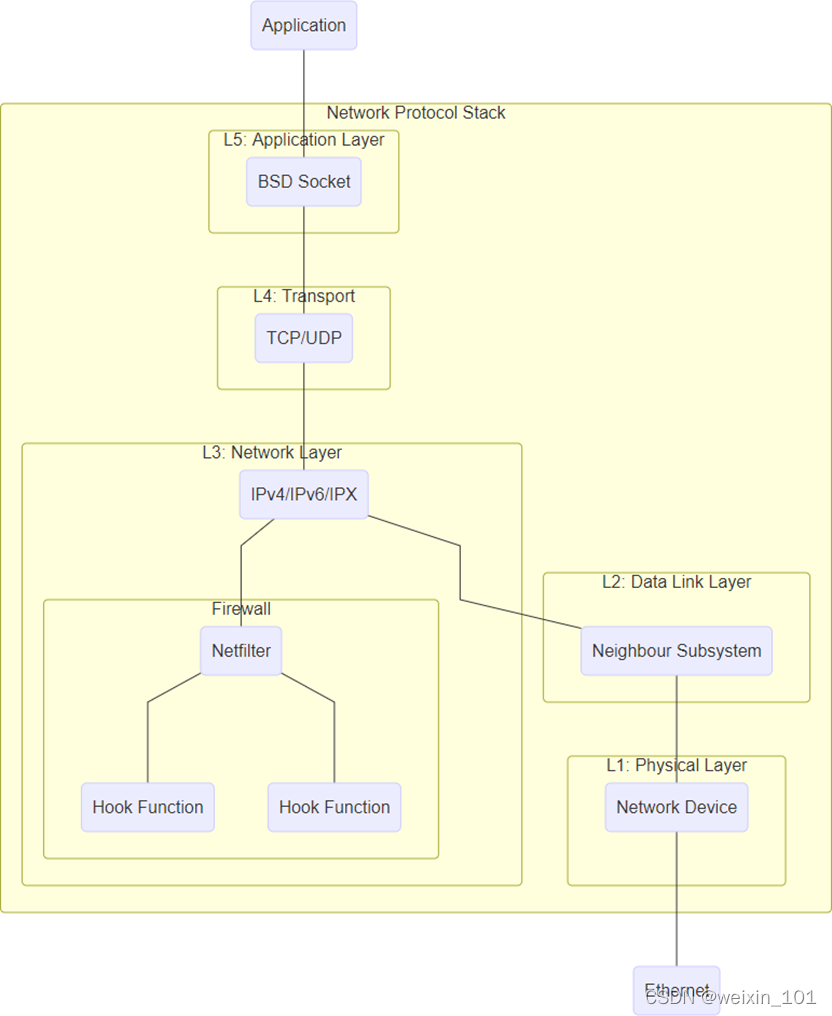
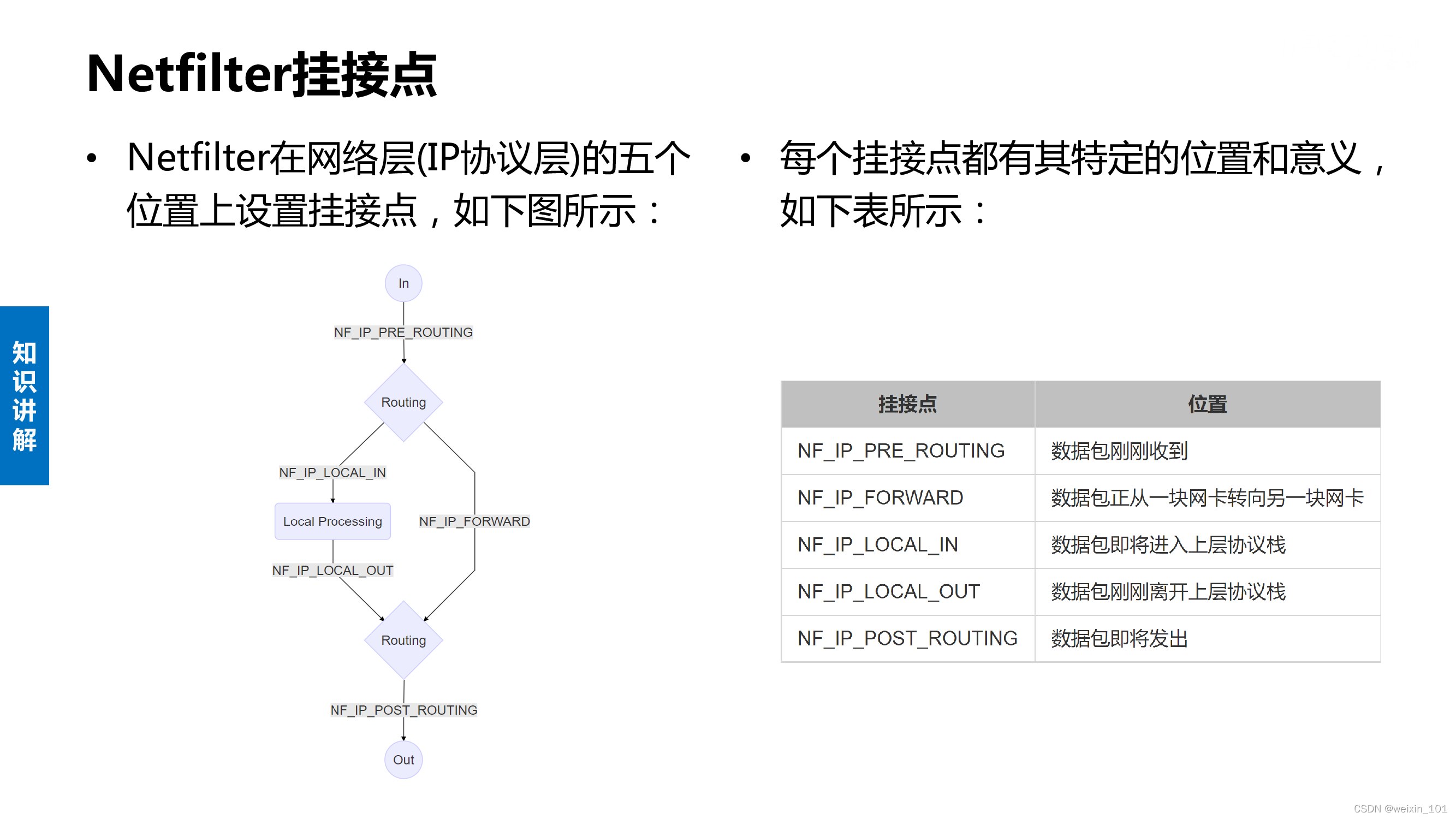
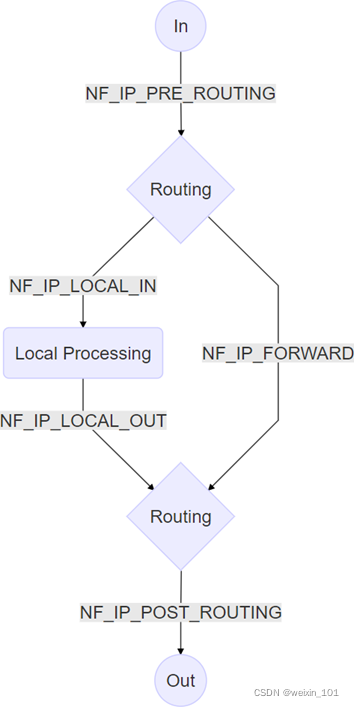
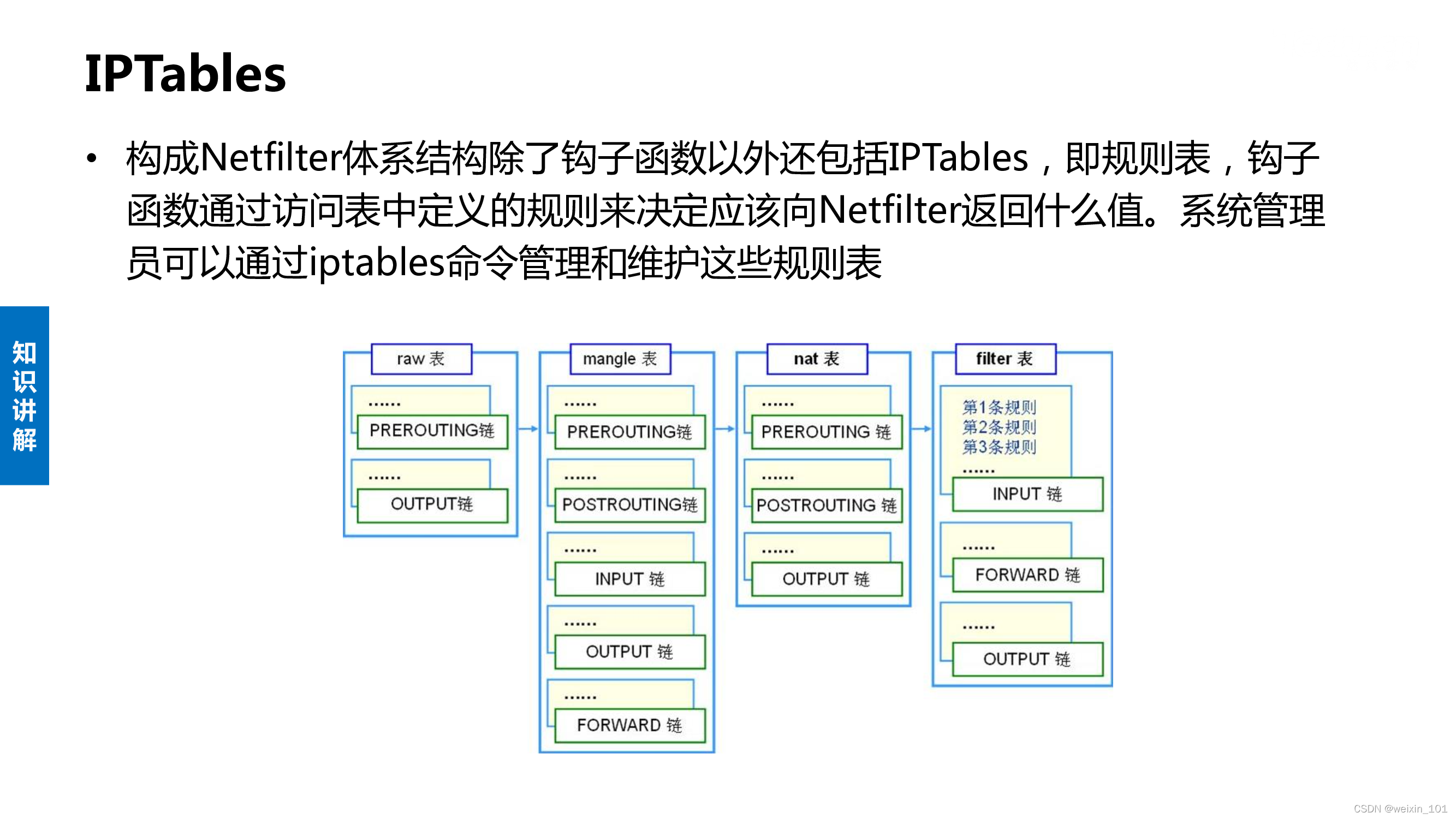
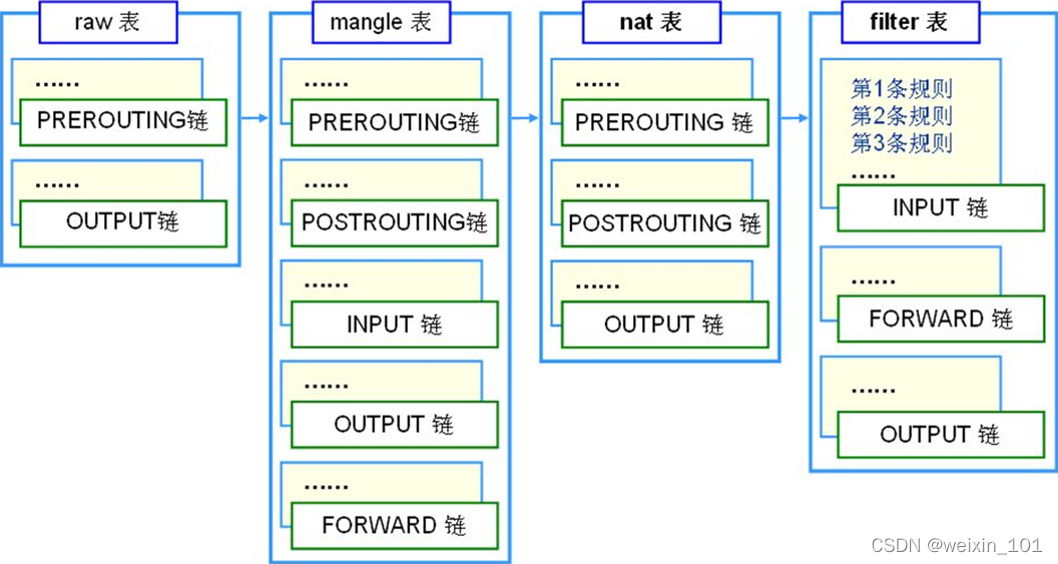
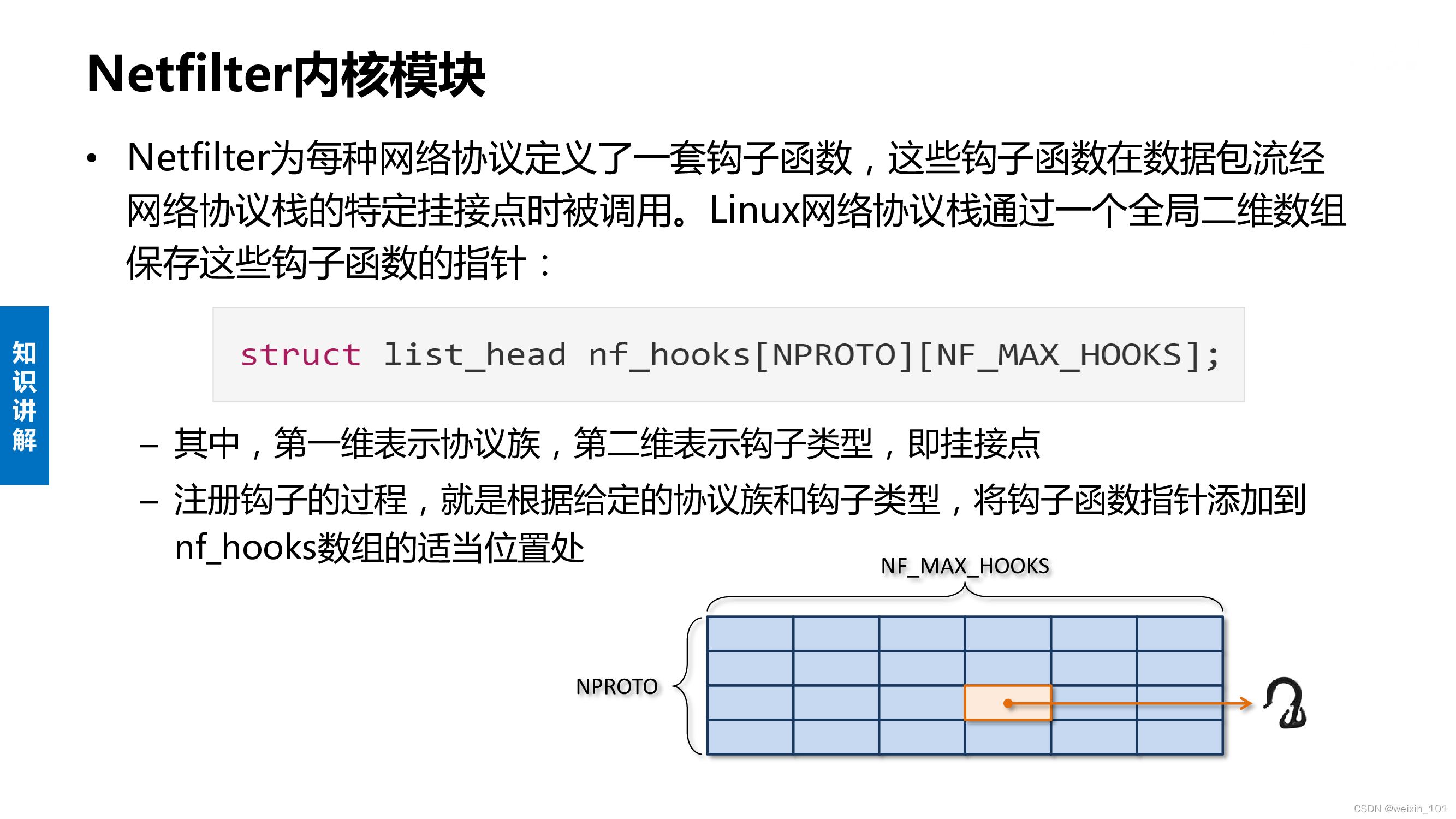
Linux系统通过Netfilter内核模块提供了包过滤功能,可以此作为构建防火墙的基础
本单元通过扩展Netfilter内核模块实现防火墙的功能,同时也讨论了通过IPTables快速搭建自定义防火墙的方法
本单元旨在帮助学生理解防火墙技术的基本工作原理,理解Linux环境中Netfilter/IPTables的工作机制,掌握对Netfilter内核模块进行扩展编 程的基本方法,掌握通过IPTables构建防火墙的基本方法
通过本单元的学习,学生应能通过扩展Netfilter内核模块的方法实现简单的防火墙,以基于协议、源IP地址或目的端口号的方式过滤数据包
十二、内核加固
Linux是一种开源操作系统,开发人员可以通过修改其源代码对系统进行加固
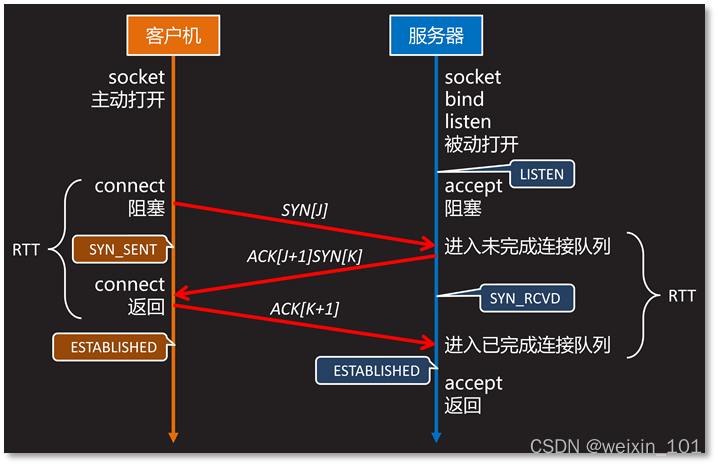
本单元通过加固Linux网络协议栈程序,改变Linux内核对孤立TCP SYN数据包的处理方式,提升系统对TCP SYN拒绝服务攻击的防御能力
本单元旨在帮助学生理解TCP连接的建立过程以及拒绝服务攻击的基本原理和方法,通过分析Linux内核源码,理解Linux网络协议栈的实现原理,掌握对TCP SYN洪泛的防御手段以及对Linux内核进行扩展开发的方法,了解Linux TCP Cookie防火墙的工作原理
通过本单元的学习,学生应能通过扩展Linux原有的内核功能,使其在遭受TCP SYN拒绝服务攻击时,主动丢弃TCP SYN数据包,在不影响已建立TCP连接的前提下,提高系统抵御拒绝服务攻击的能力
Unit01

网络安全









网络威胁





研究范围



安全体系





网络攻击








安全防护








防毒杀毒



电子取证




持续规划






密码科学










应用技术










人员需要



Unit02

Linux网络协议栈


设计特点







固定模式






主要模块




















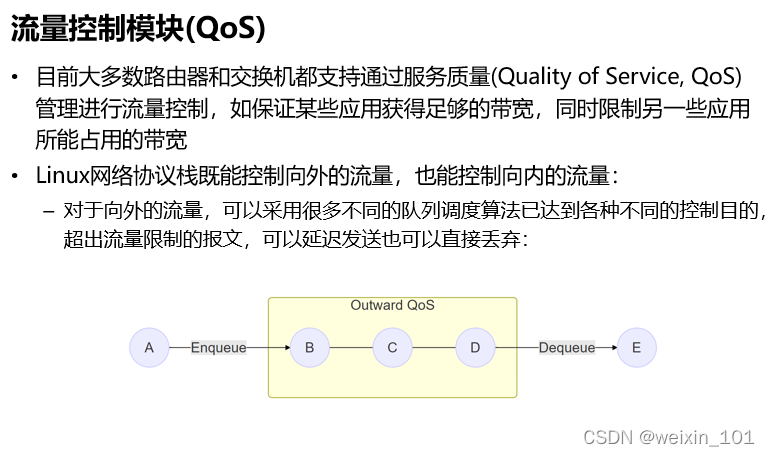
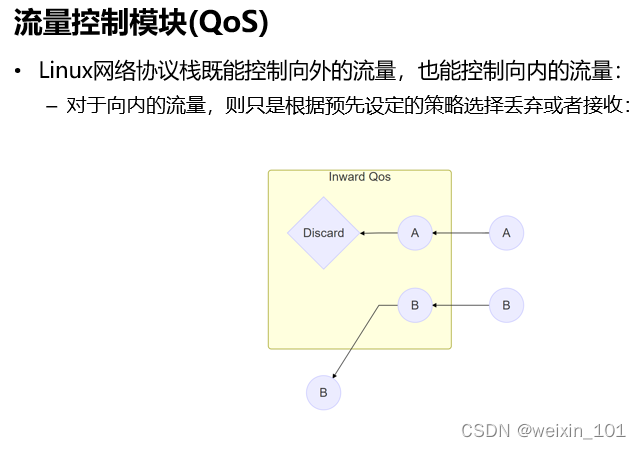
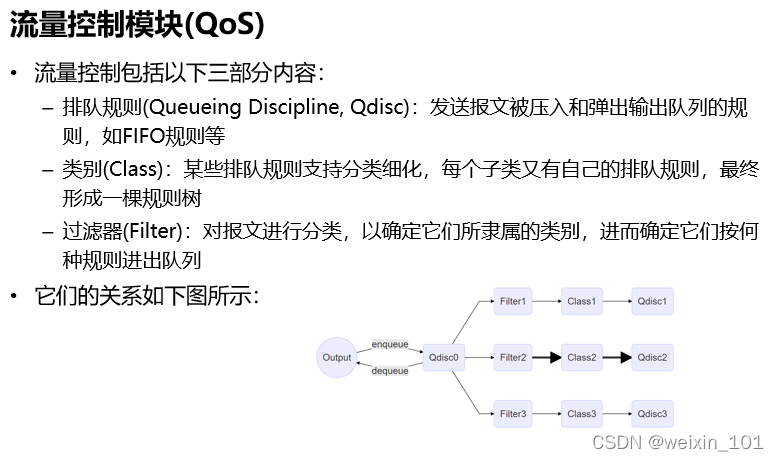
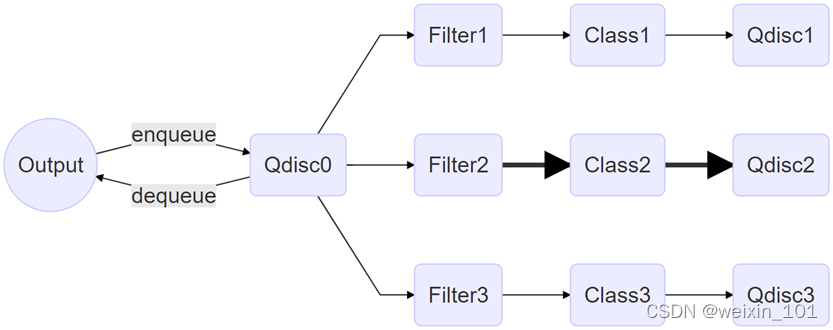

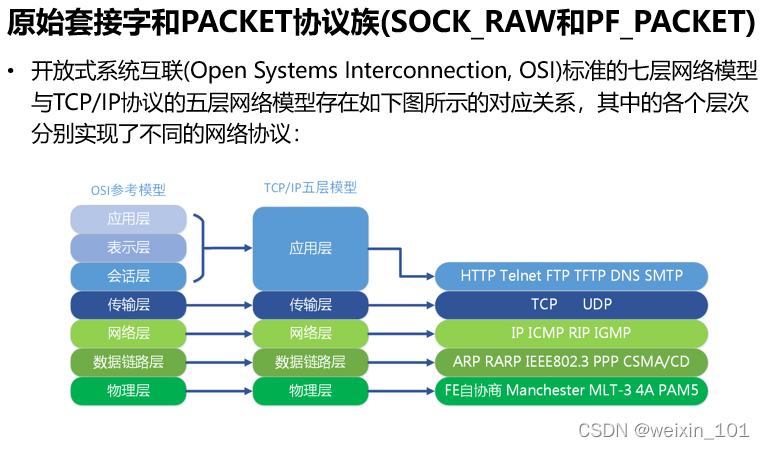
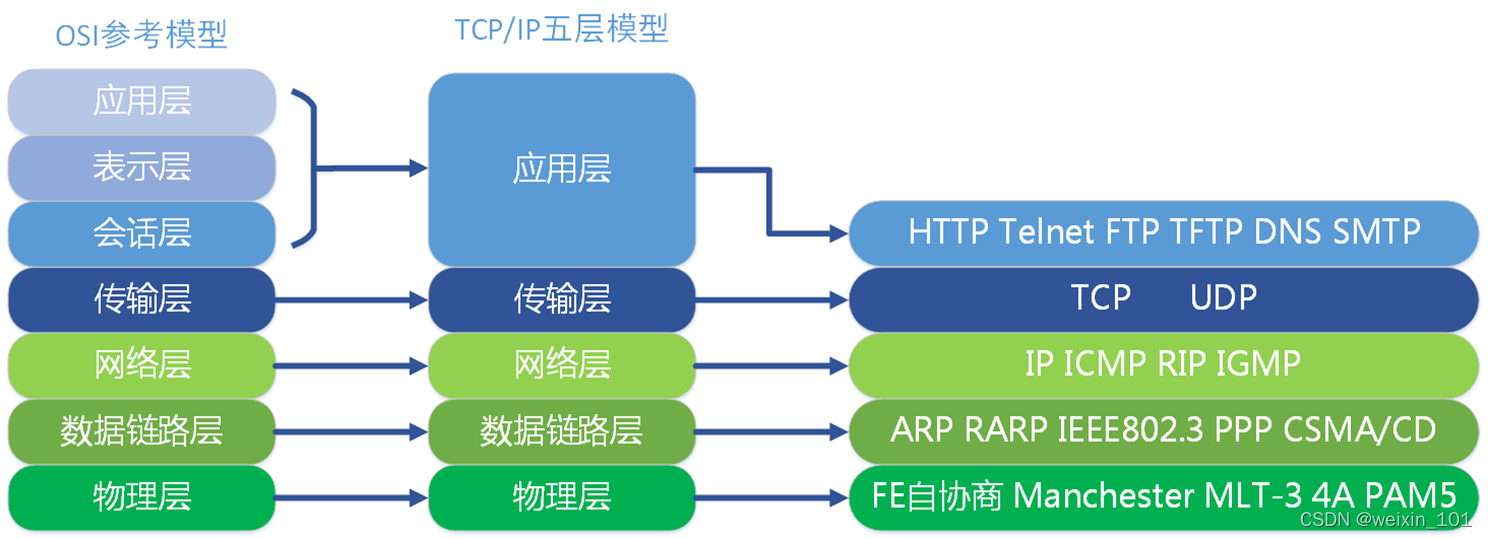
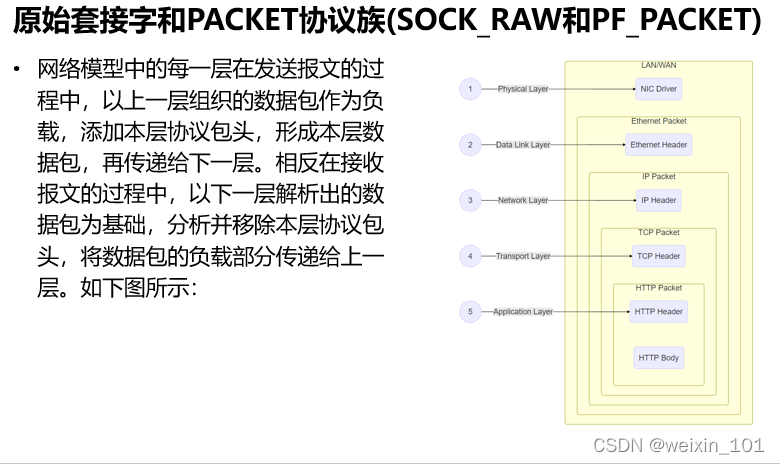
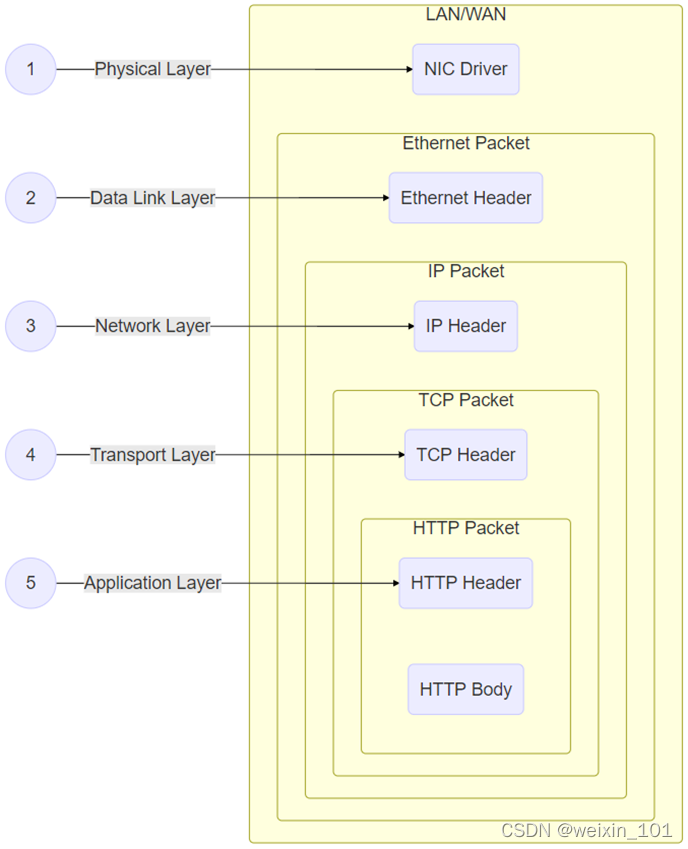

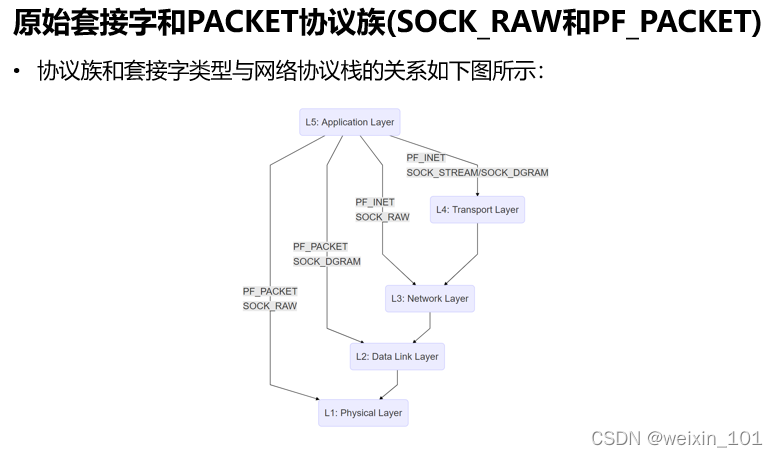
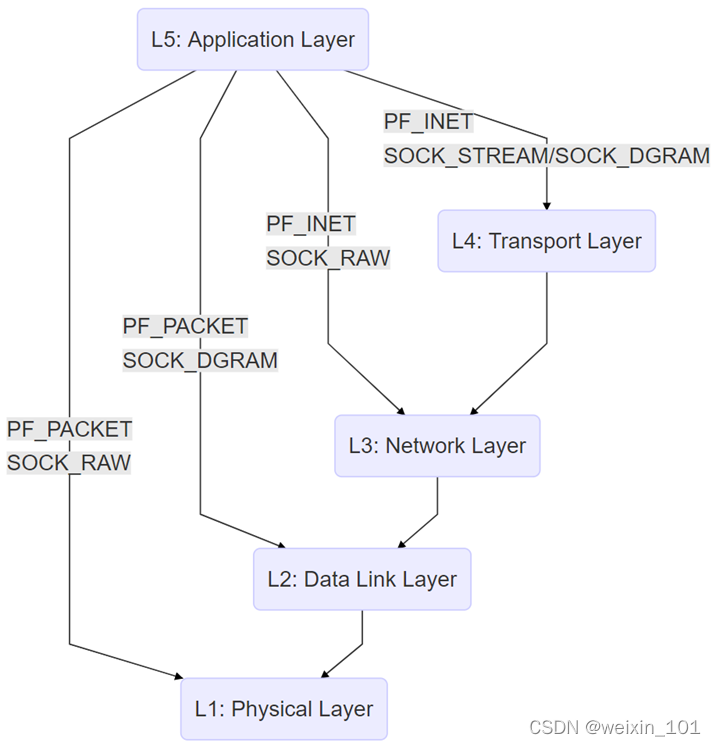

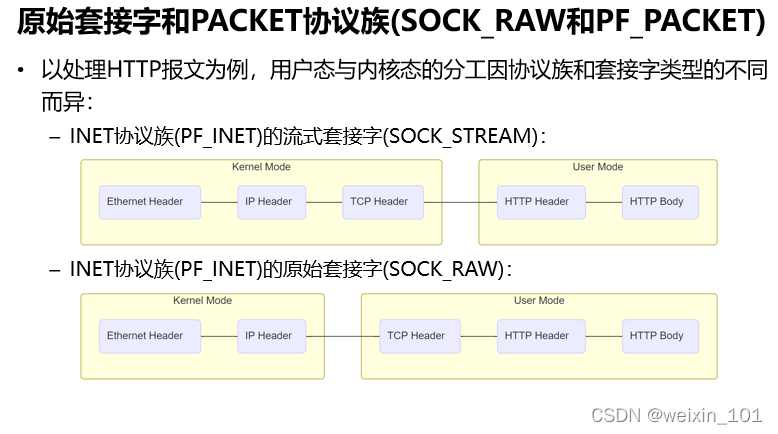
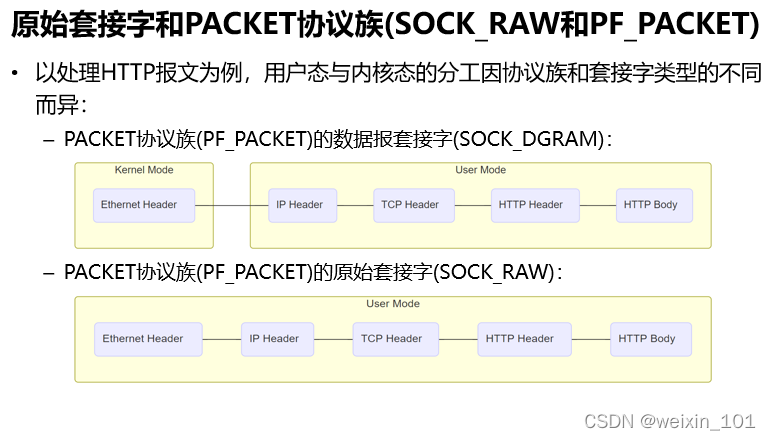
报文表示


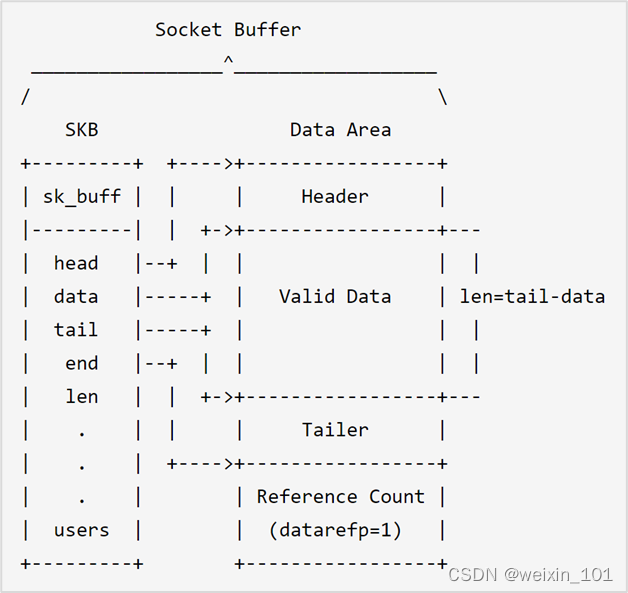

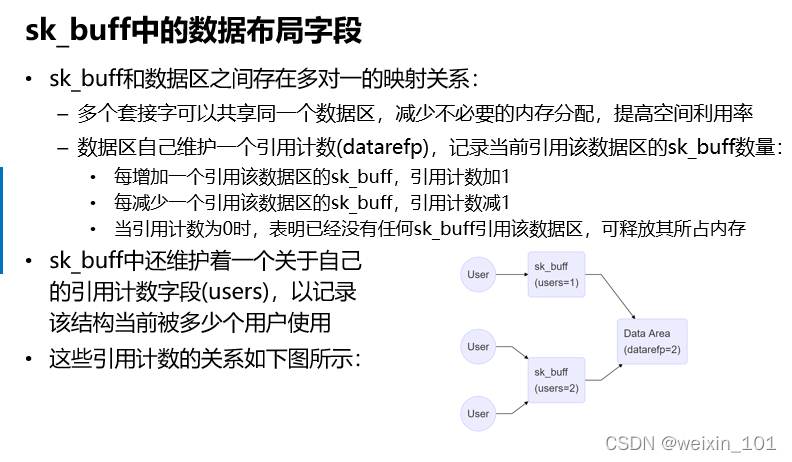
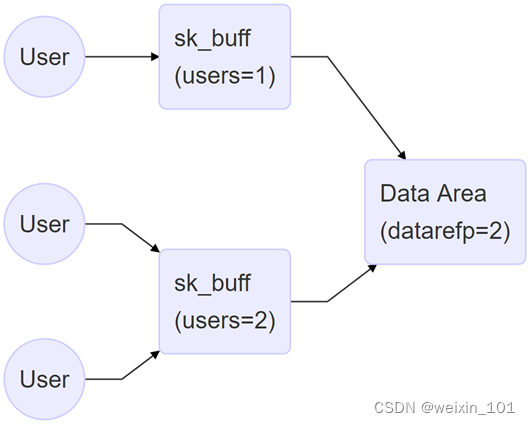












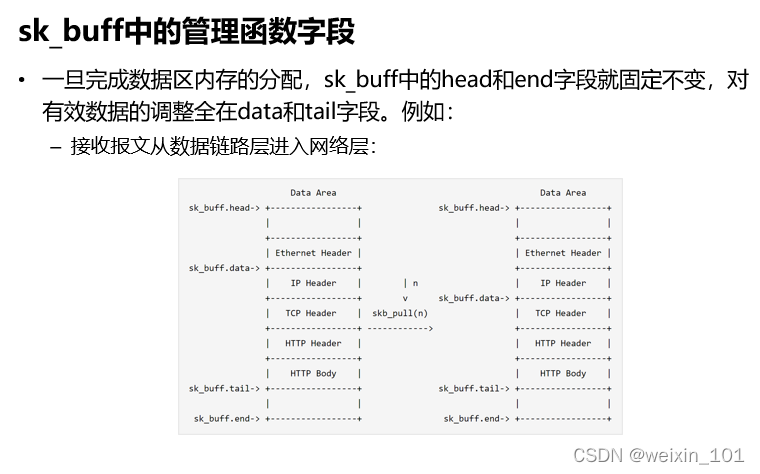
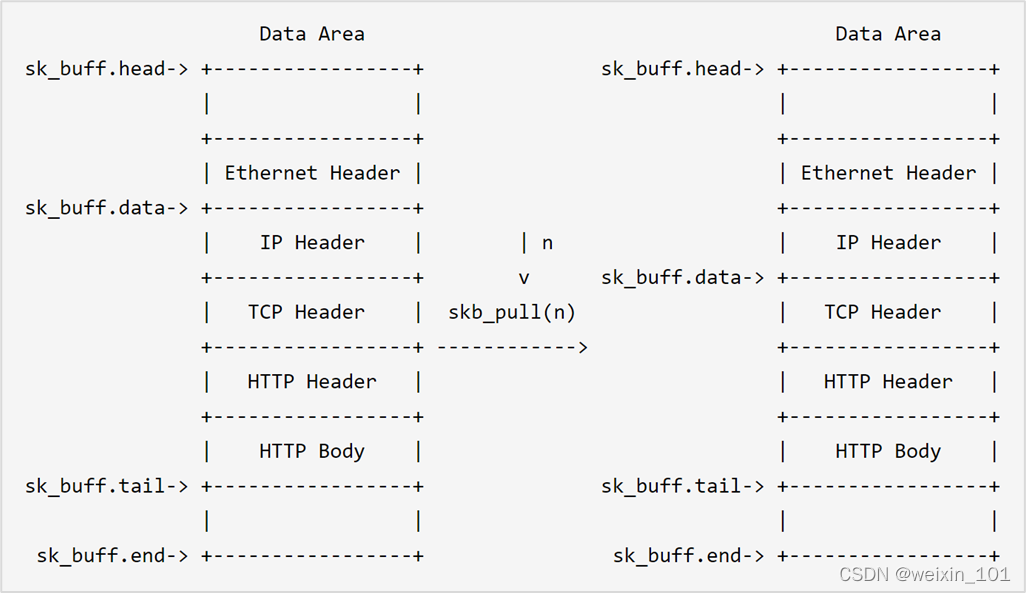
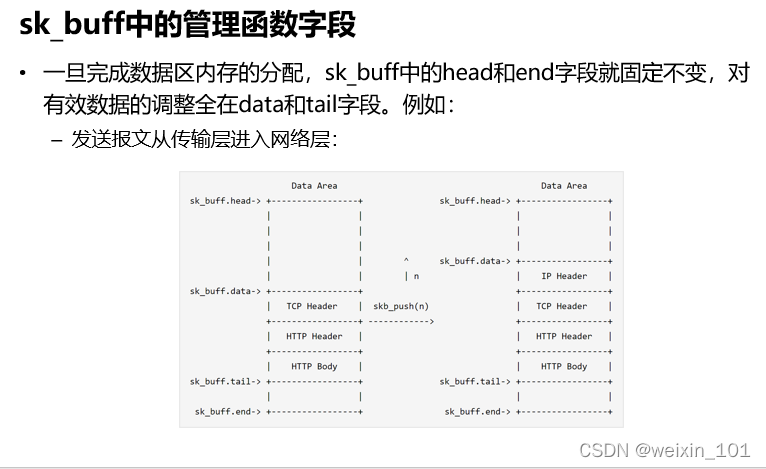
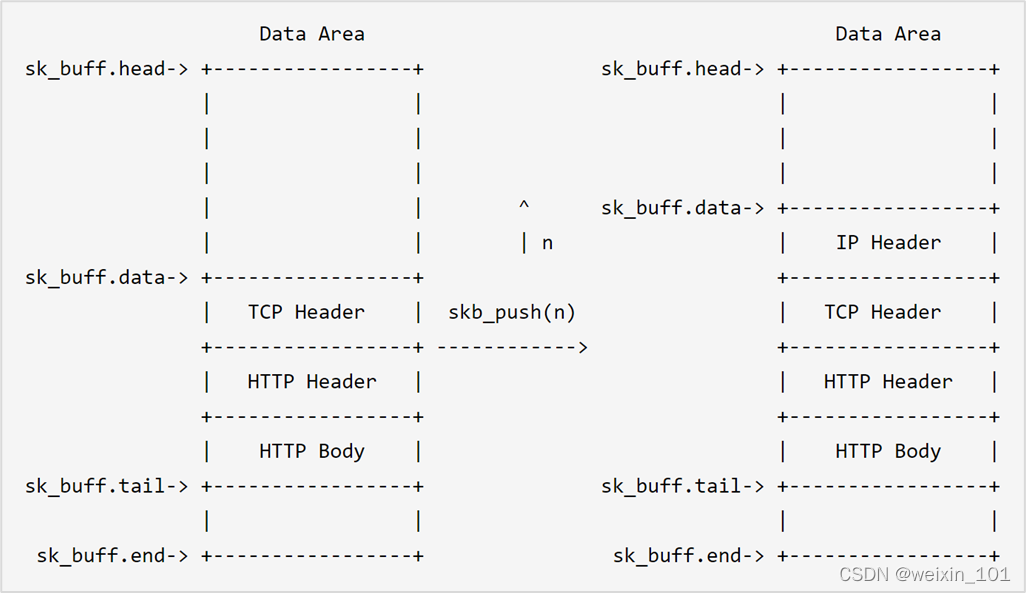
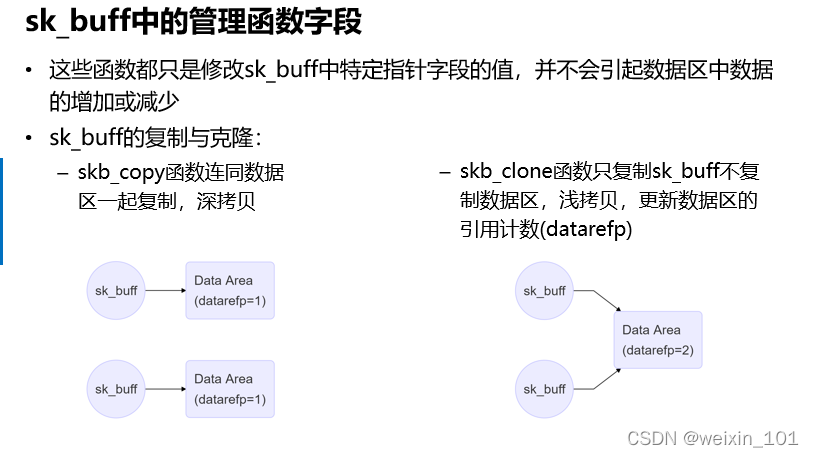
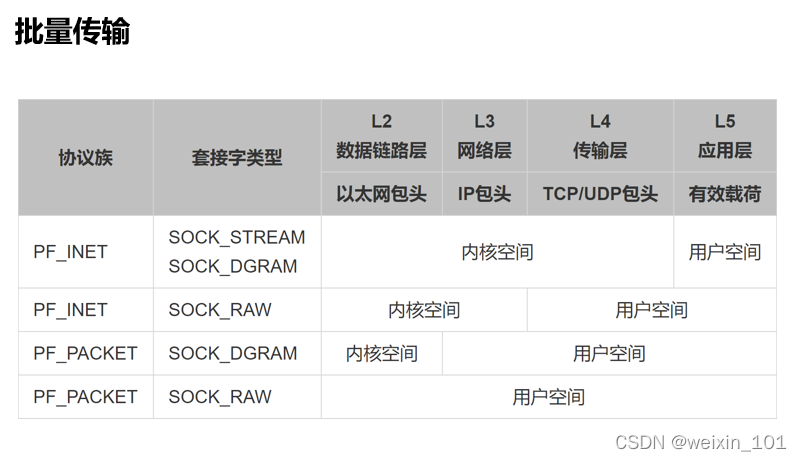
批量传输







Unit03
DES算法的历史


DES算法的特点


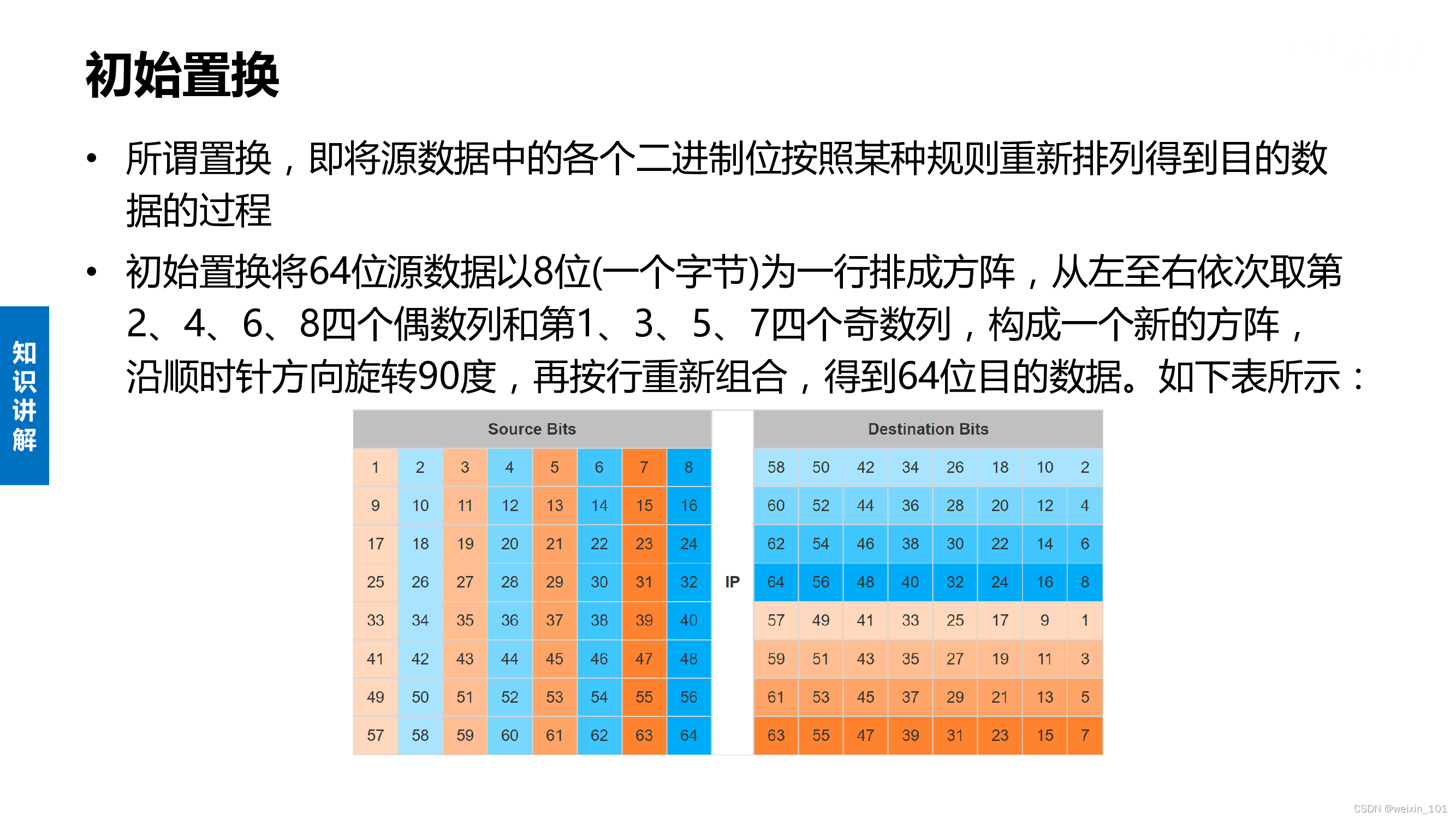
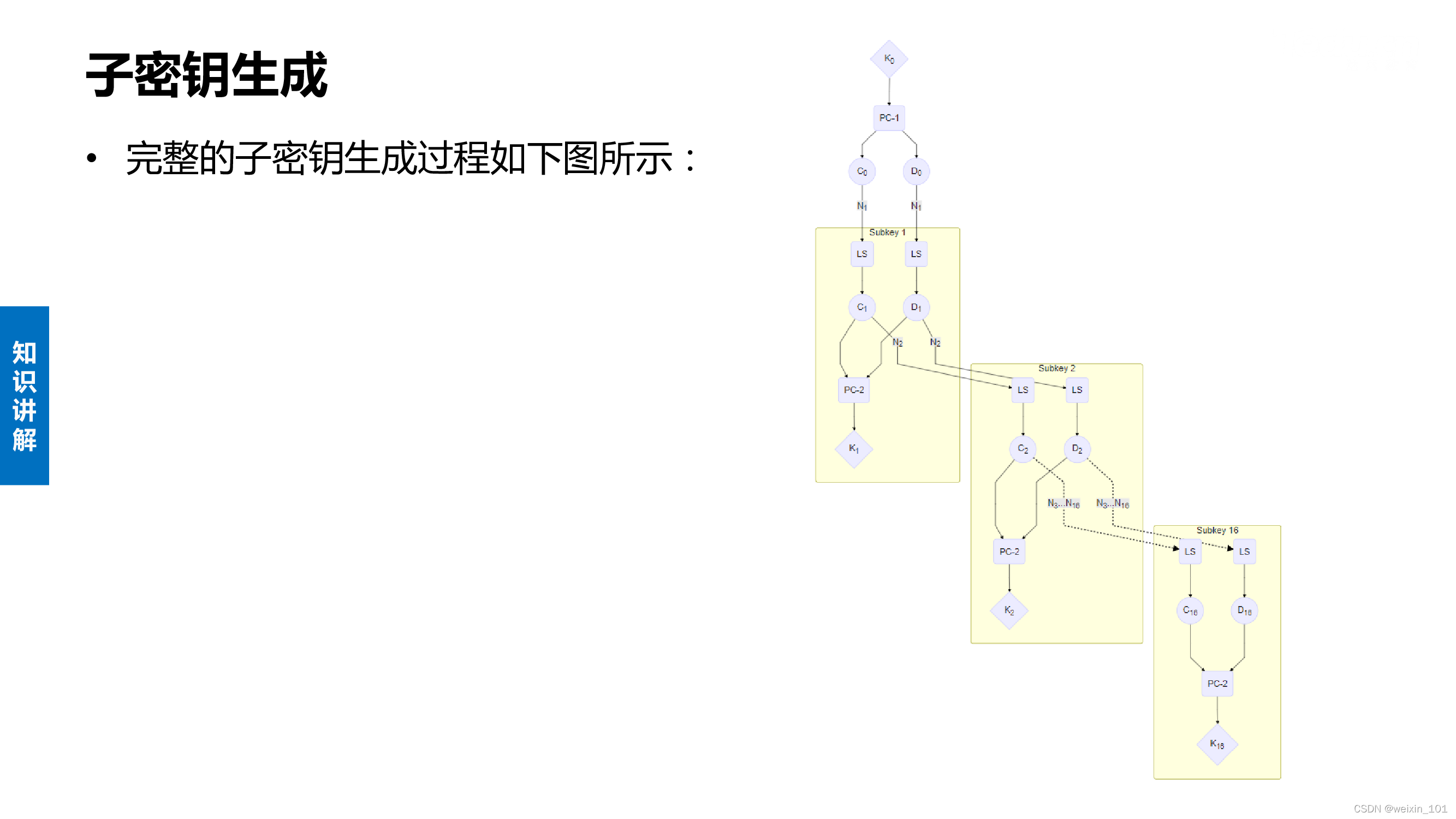
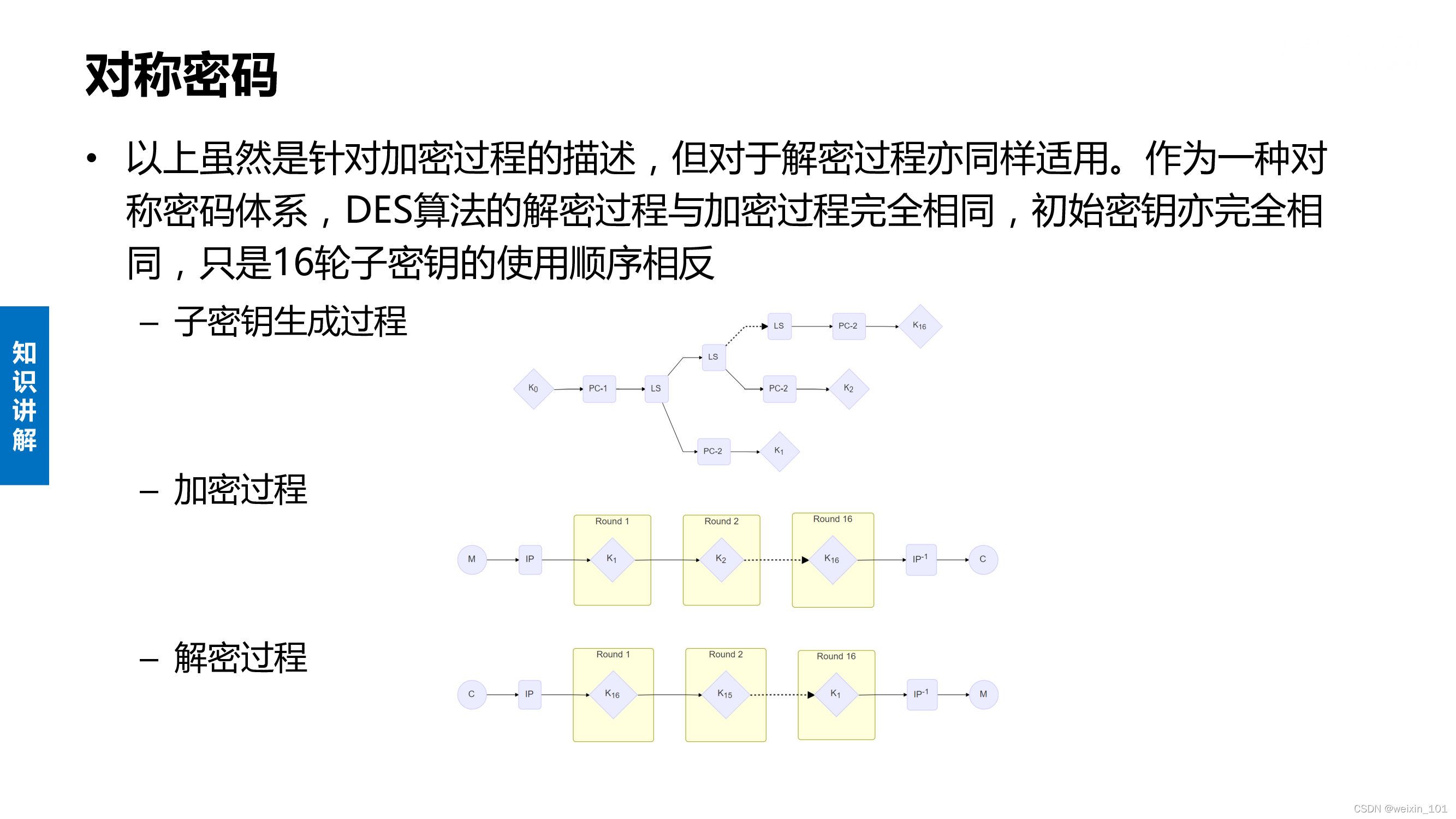
DES算法的内容


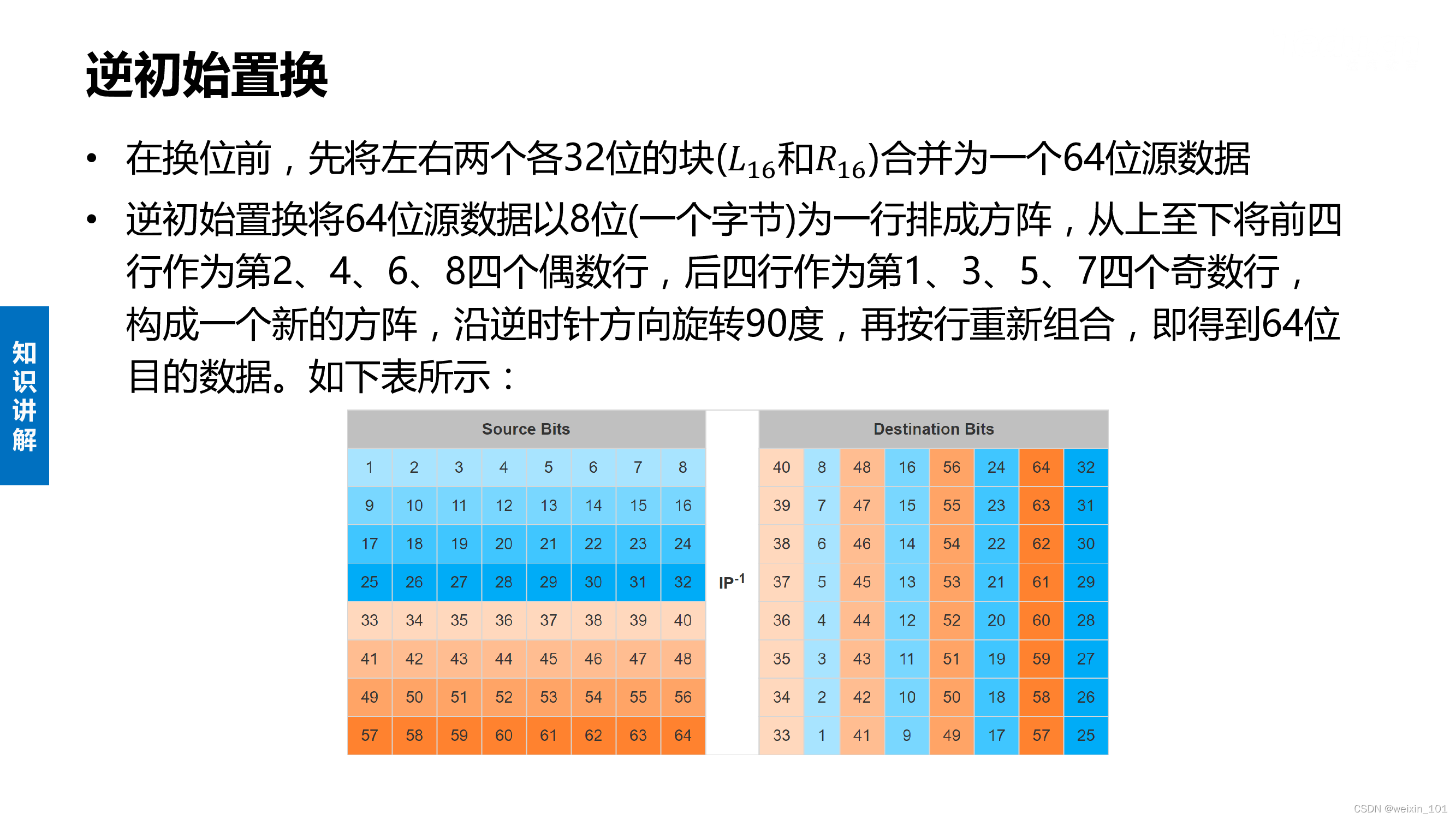



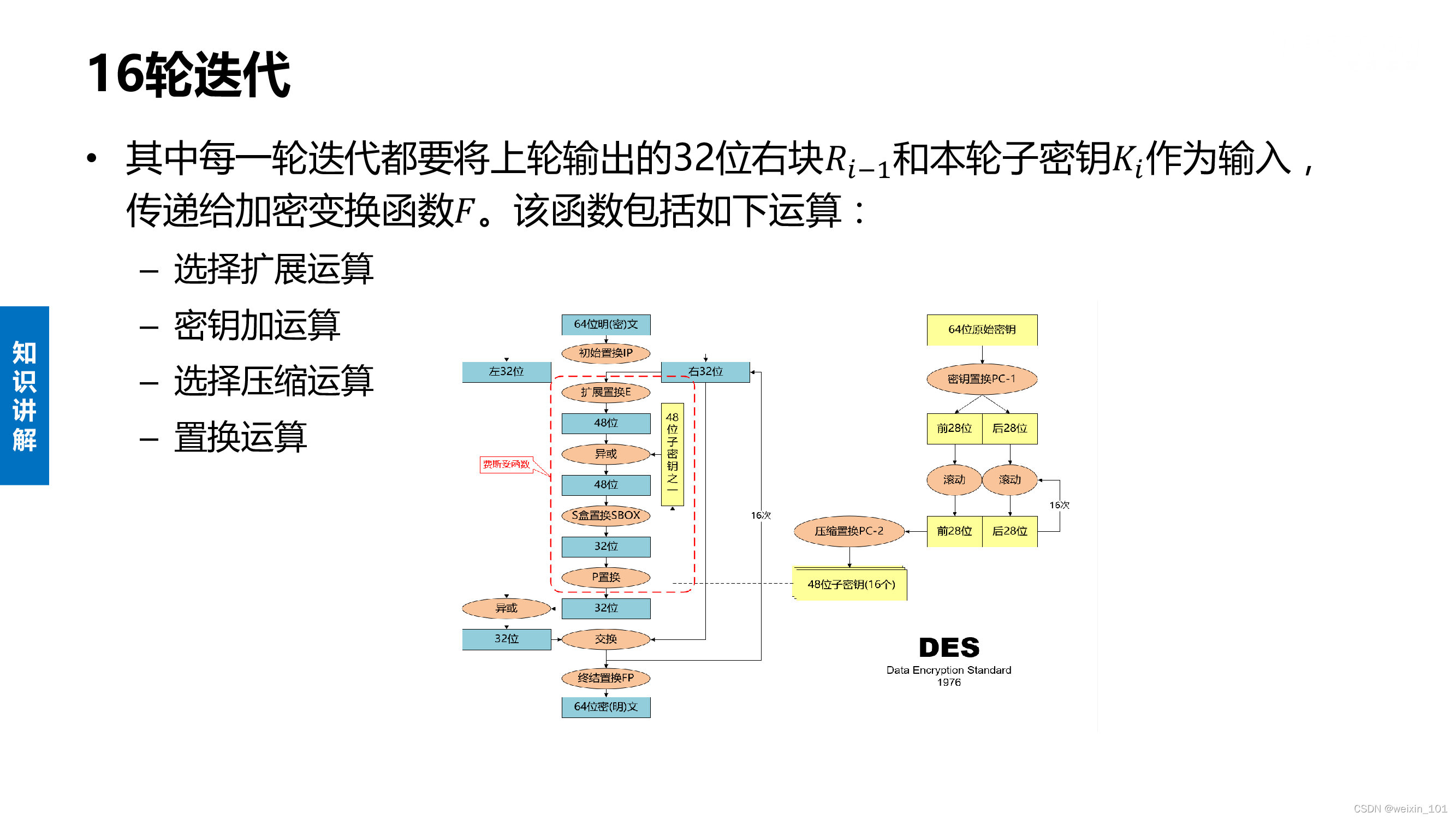

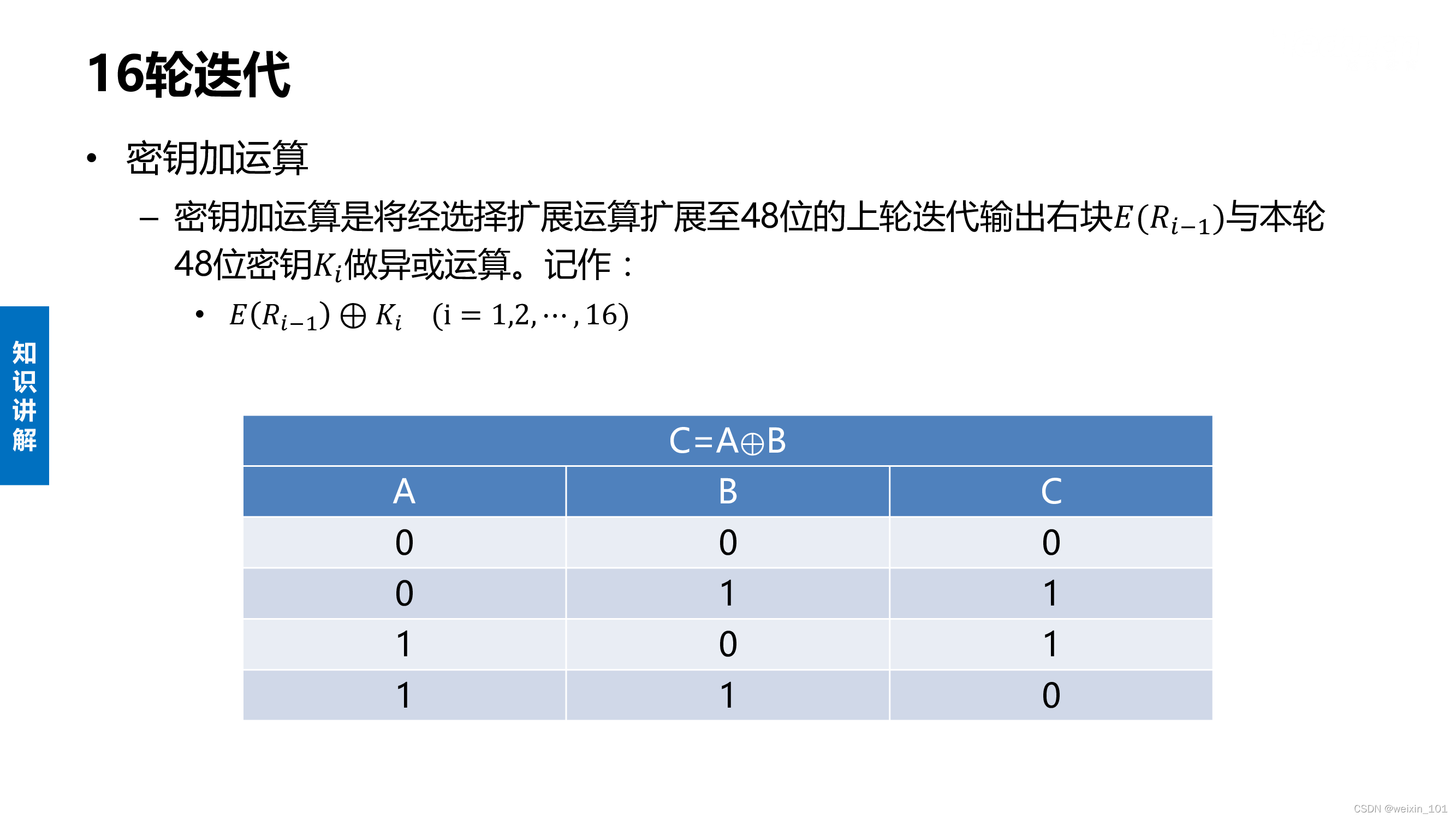



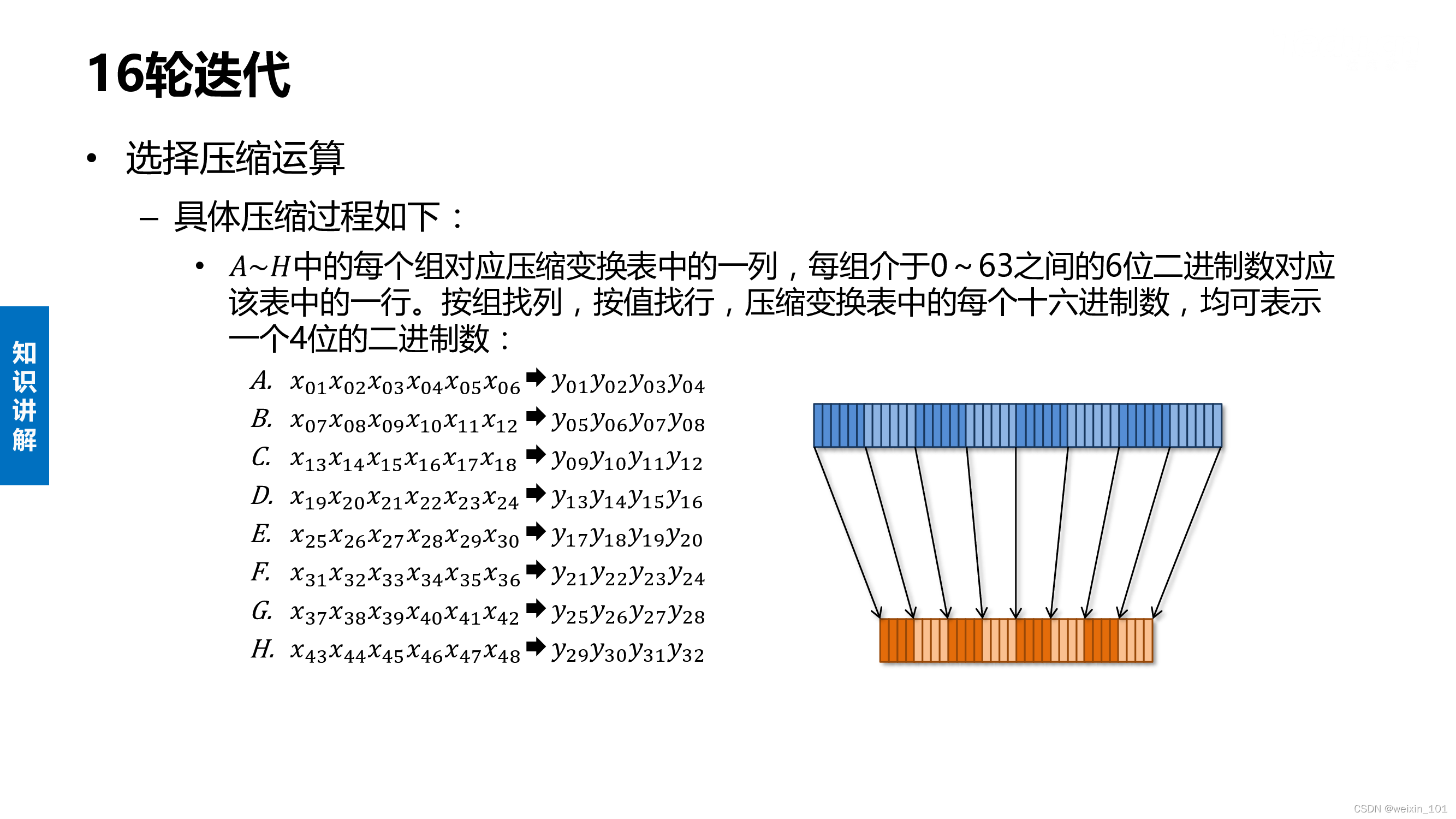
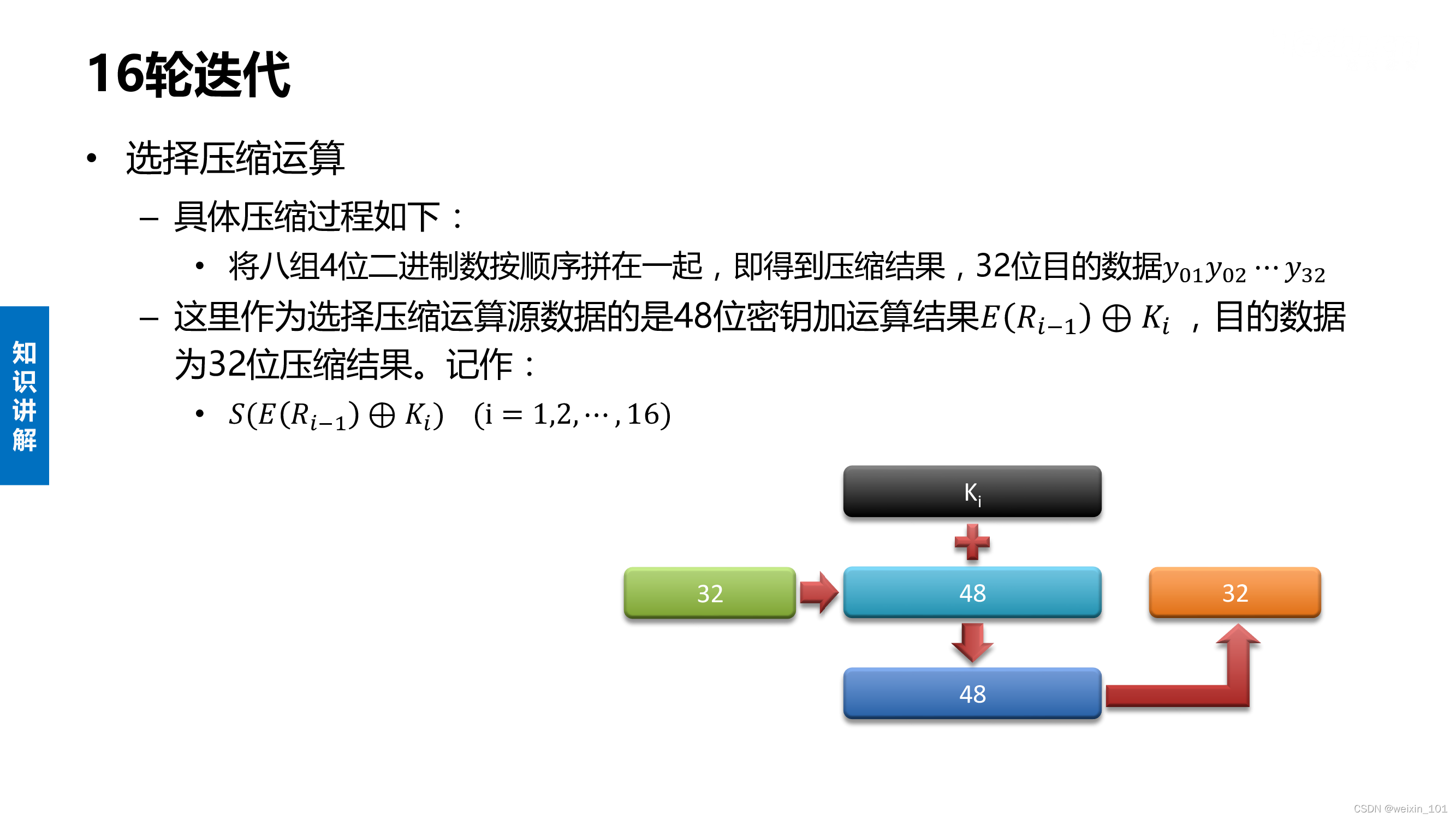
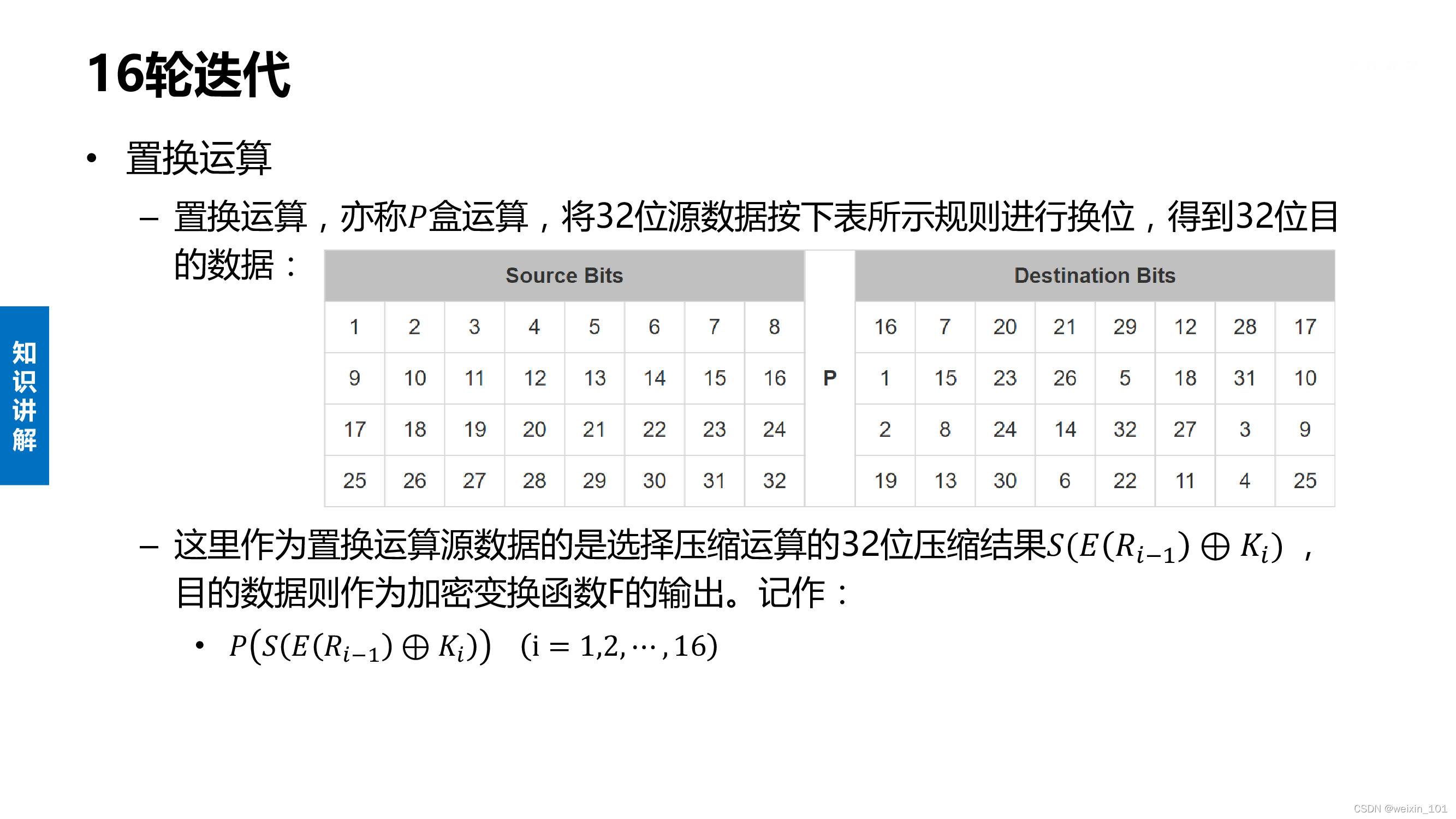

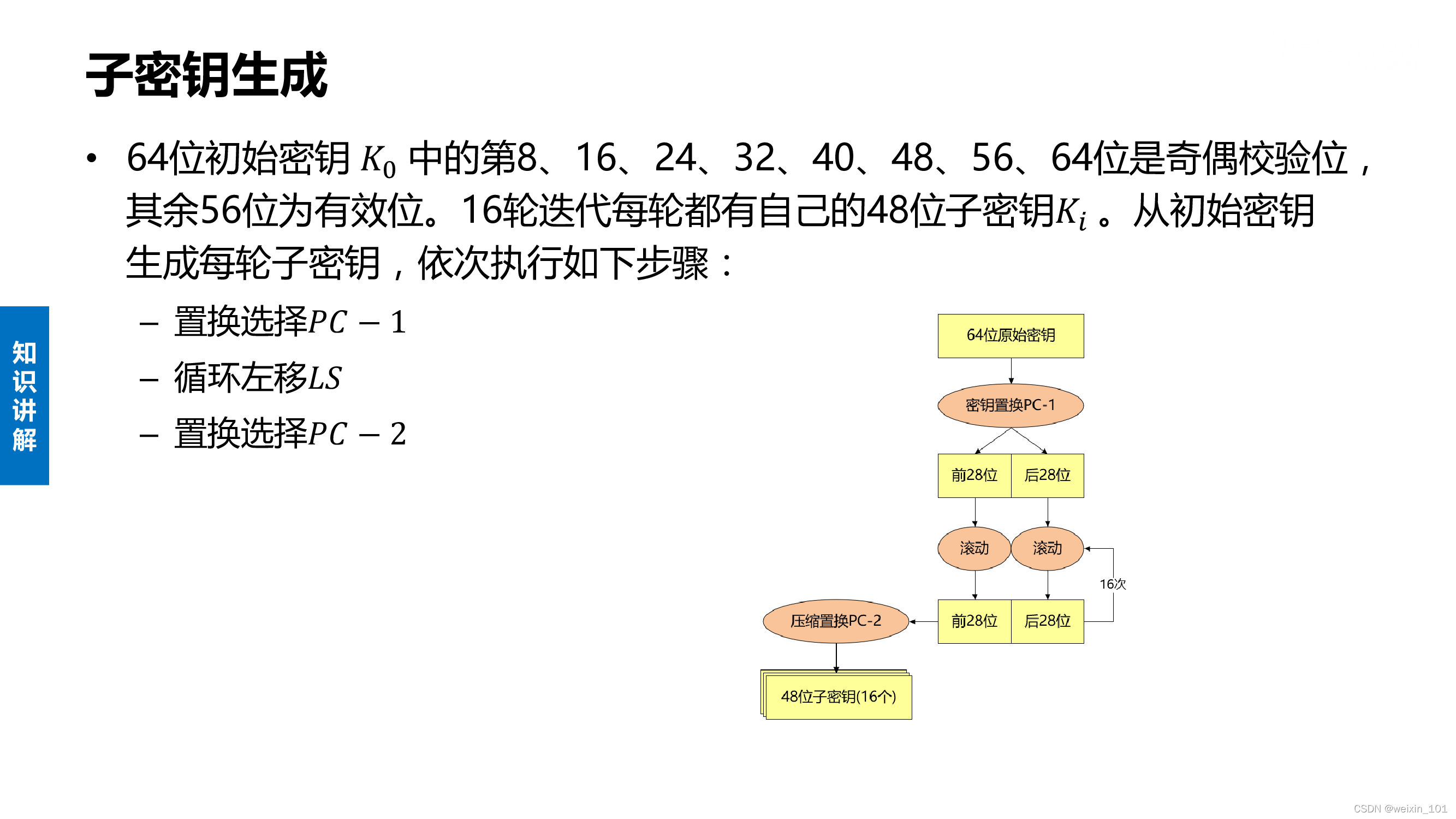

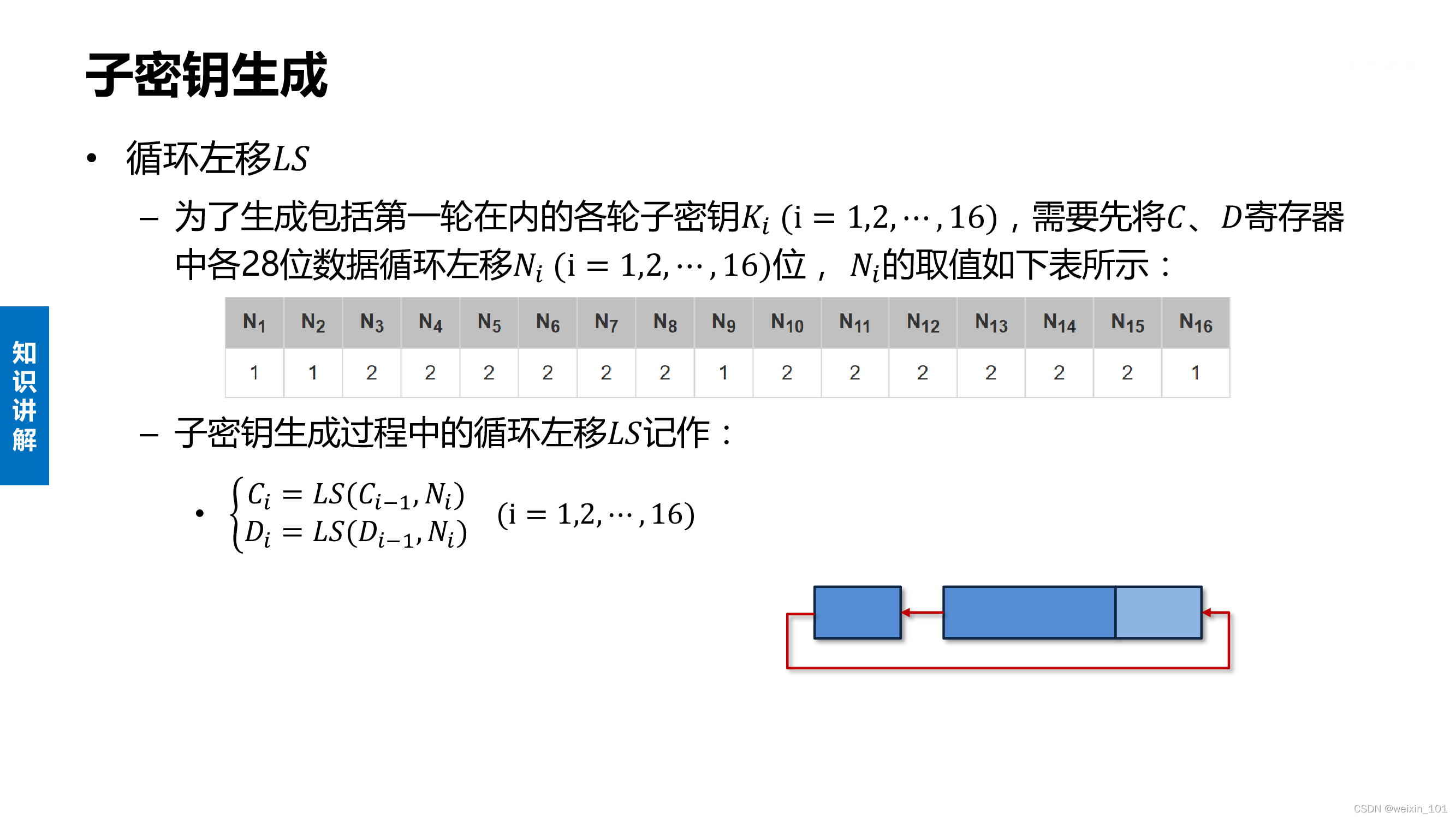




实训案例



扩展提高
DES算法的安全性



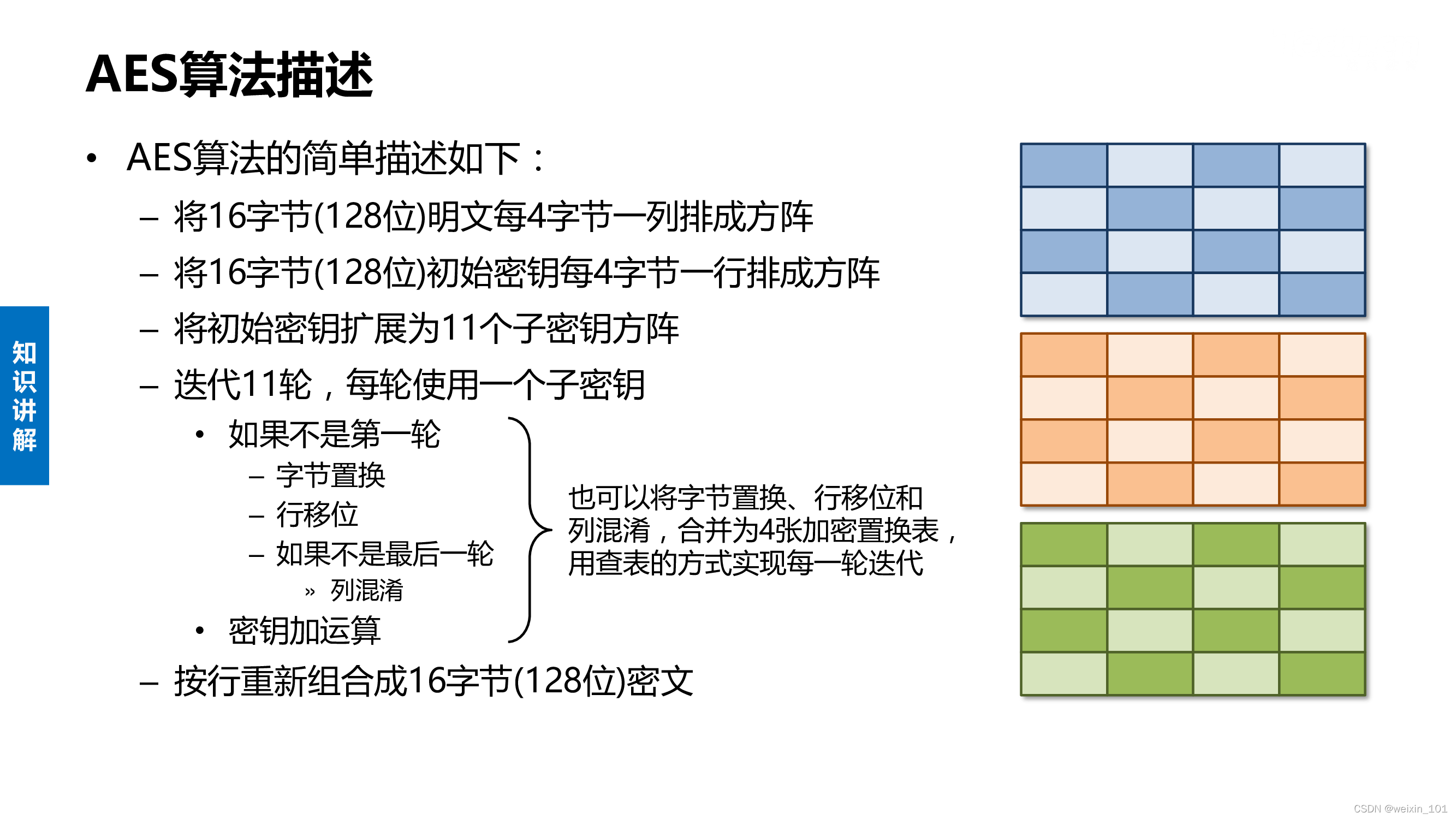
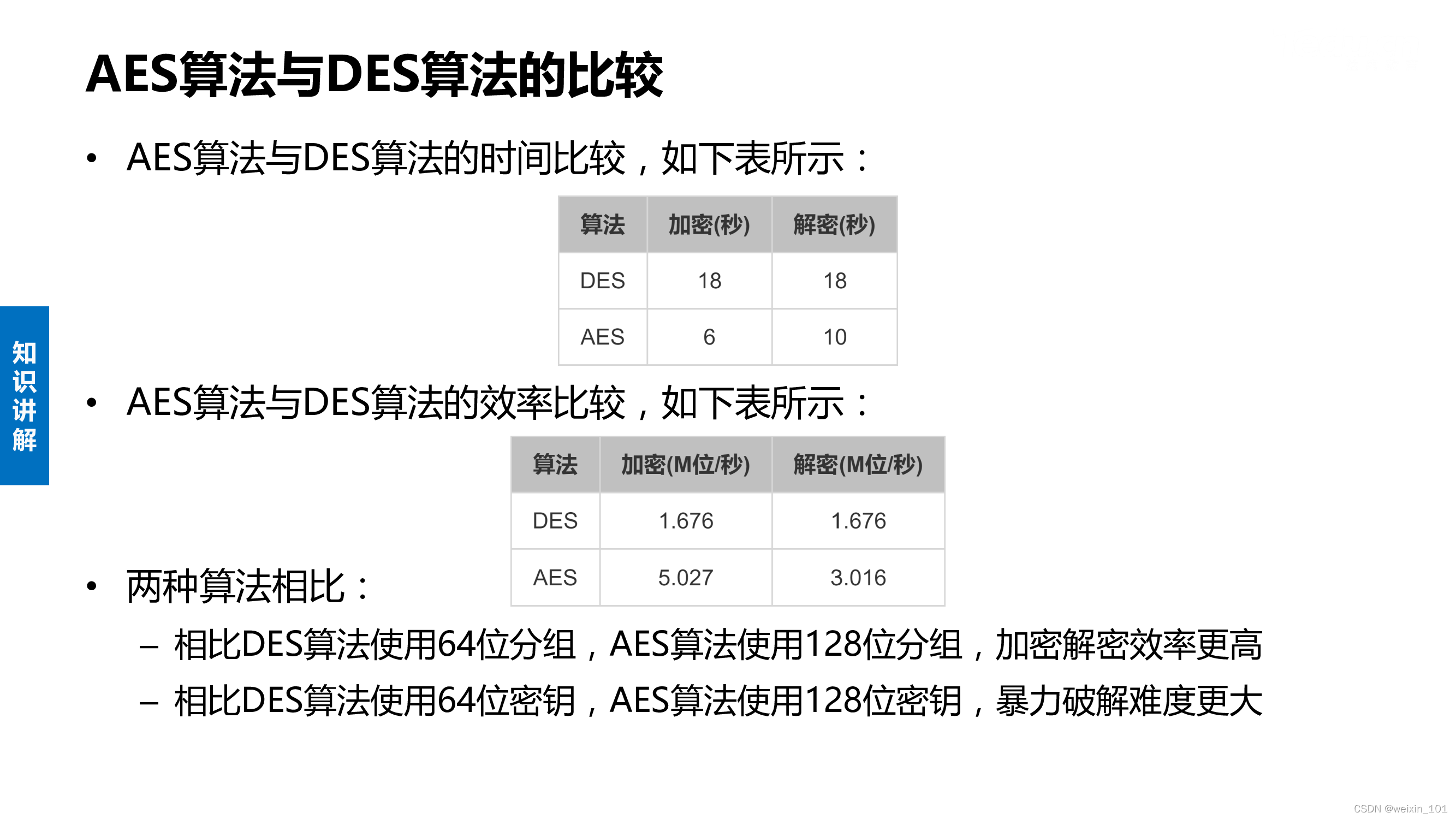
AES算法

高级通信函数




Unit04
公钥密码的概念


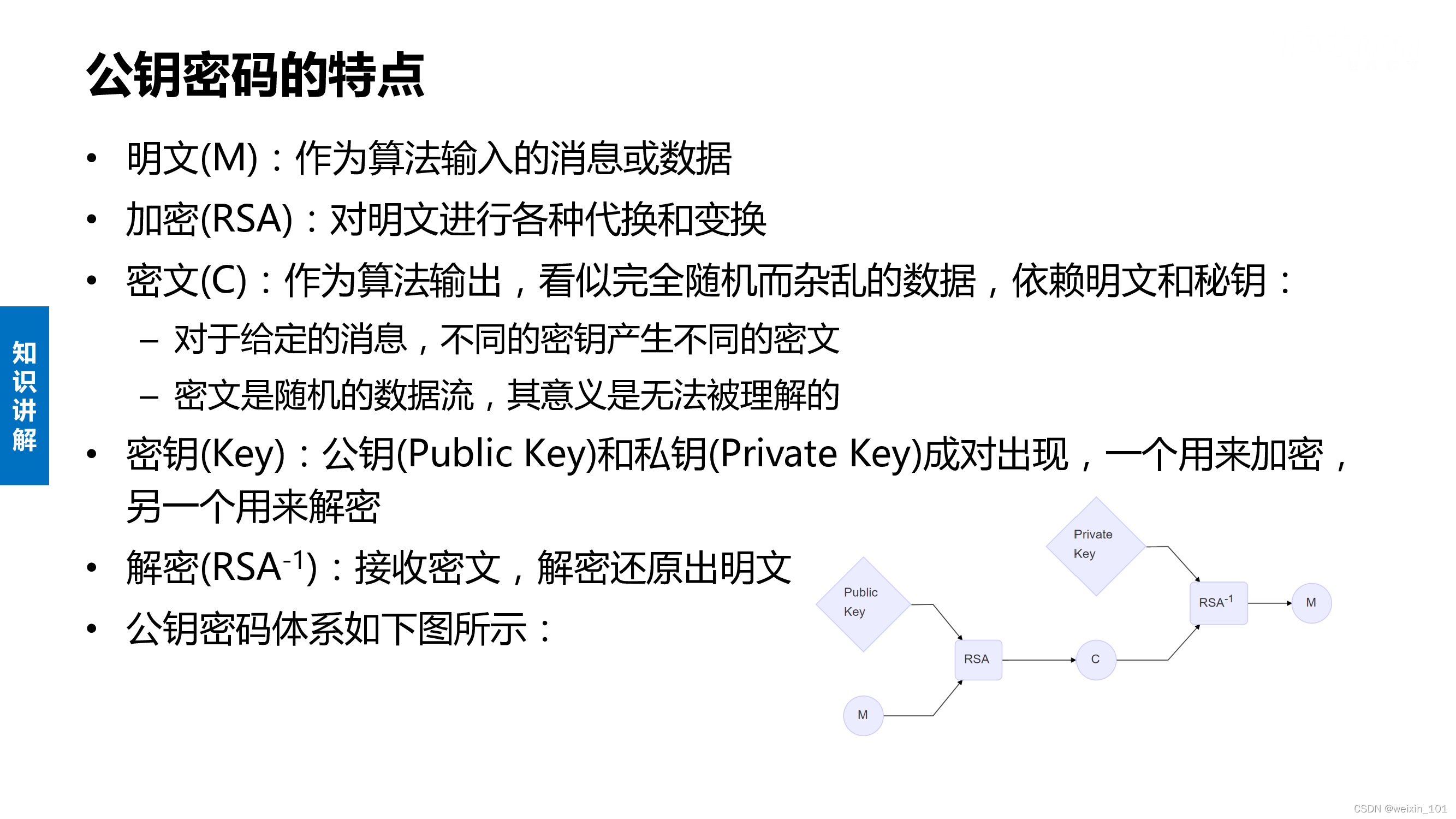
公钥密码的特点

RSA算法的原理





实训案例



RSA算法的安全性


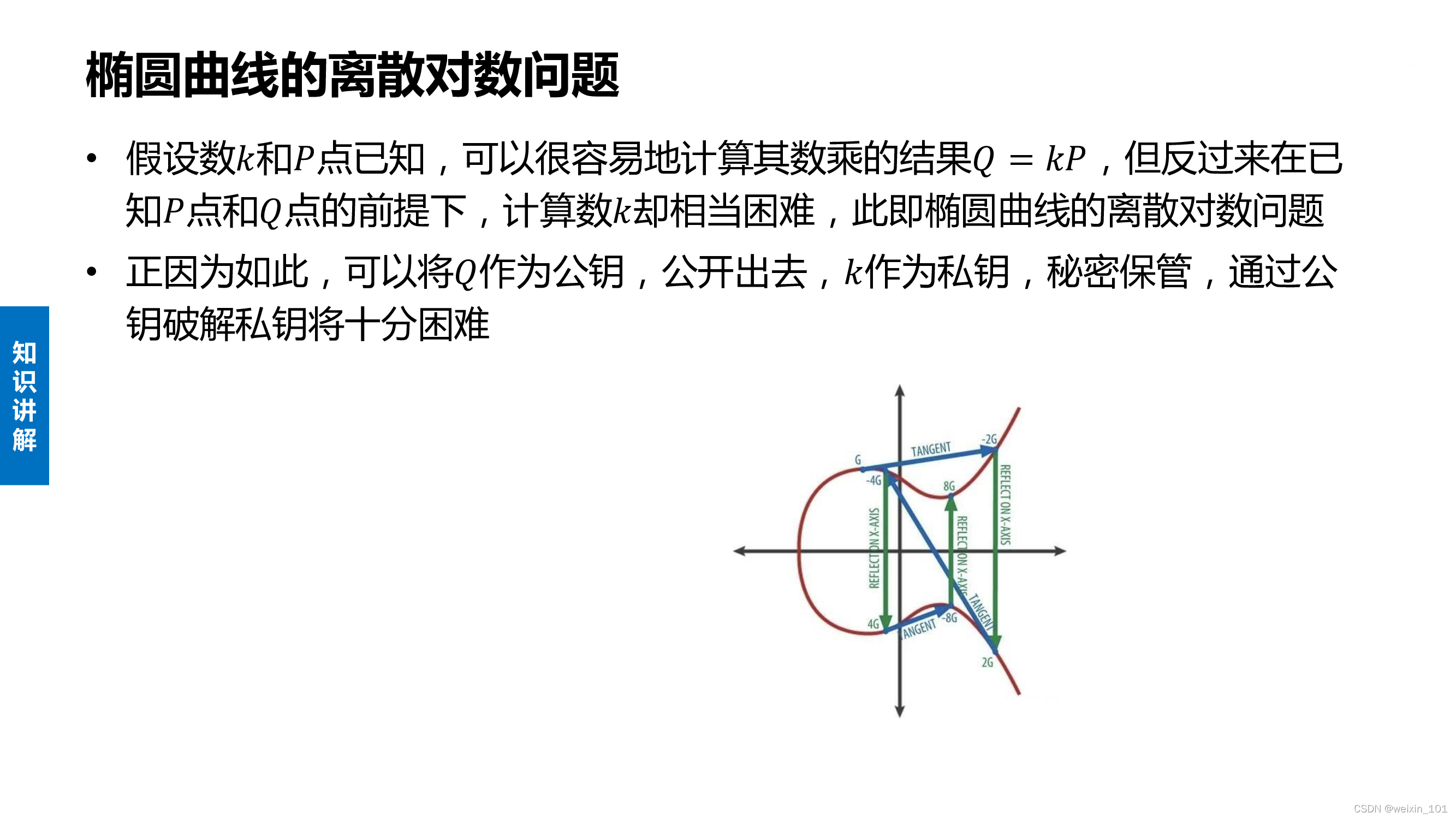
其他公钥密码








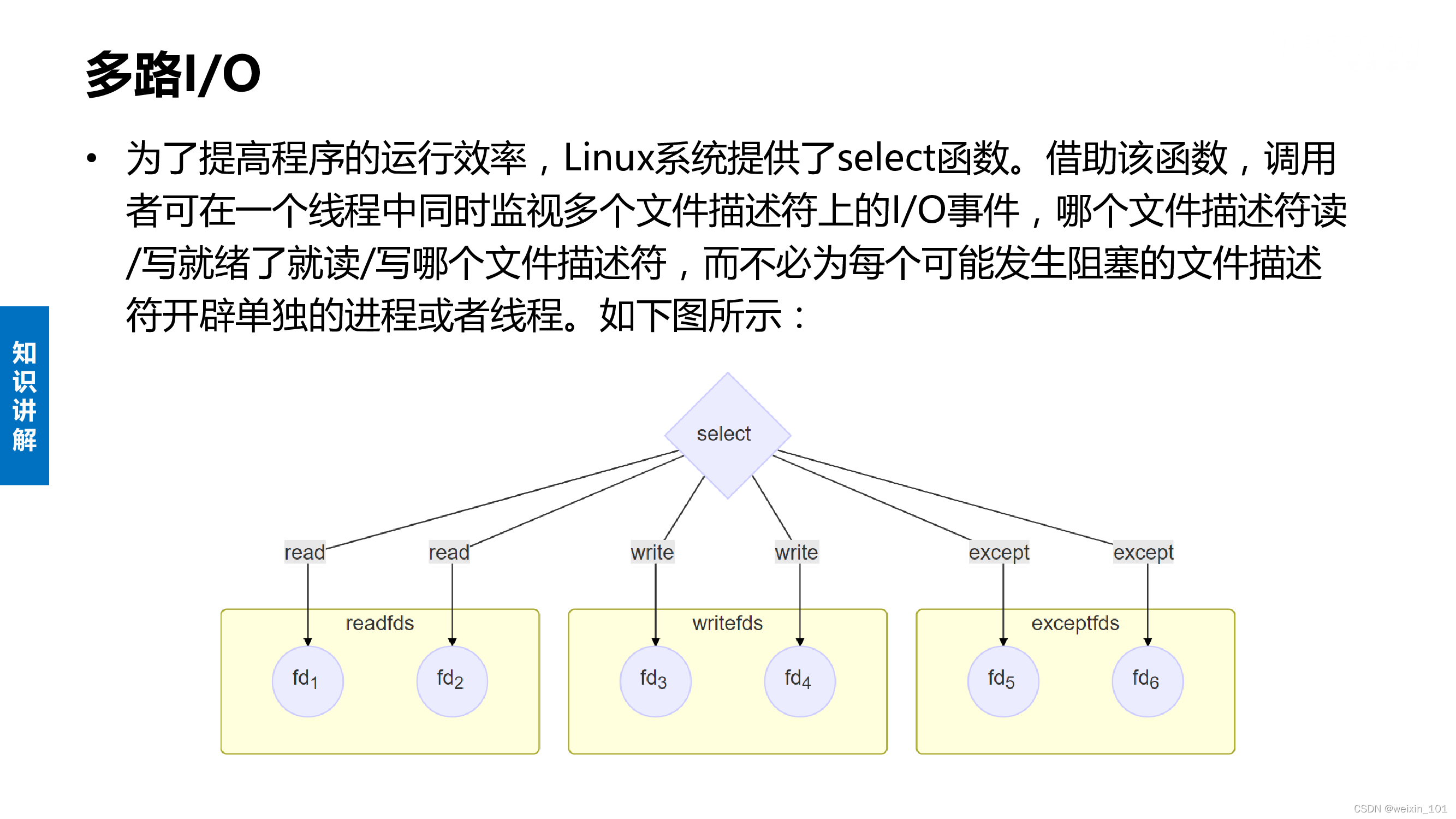
多路I/O



Unit05

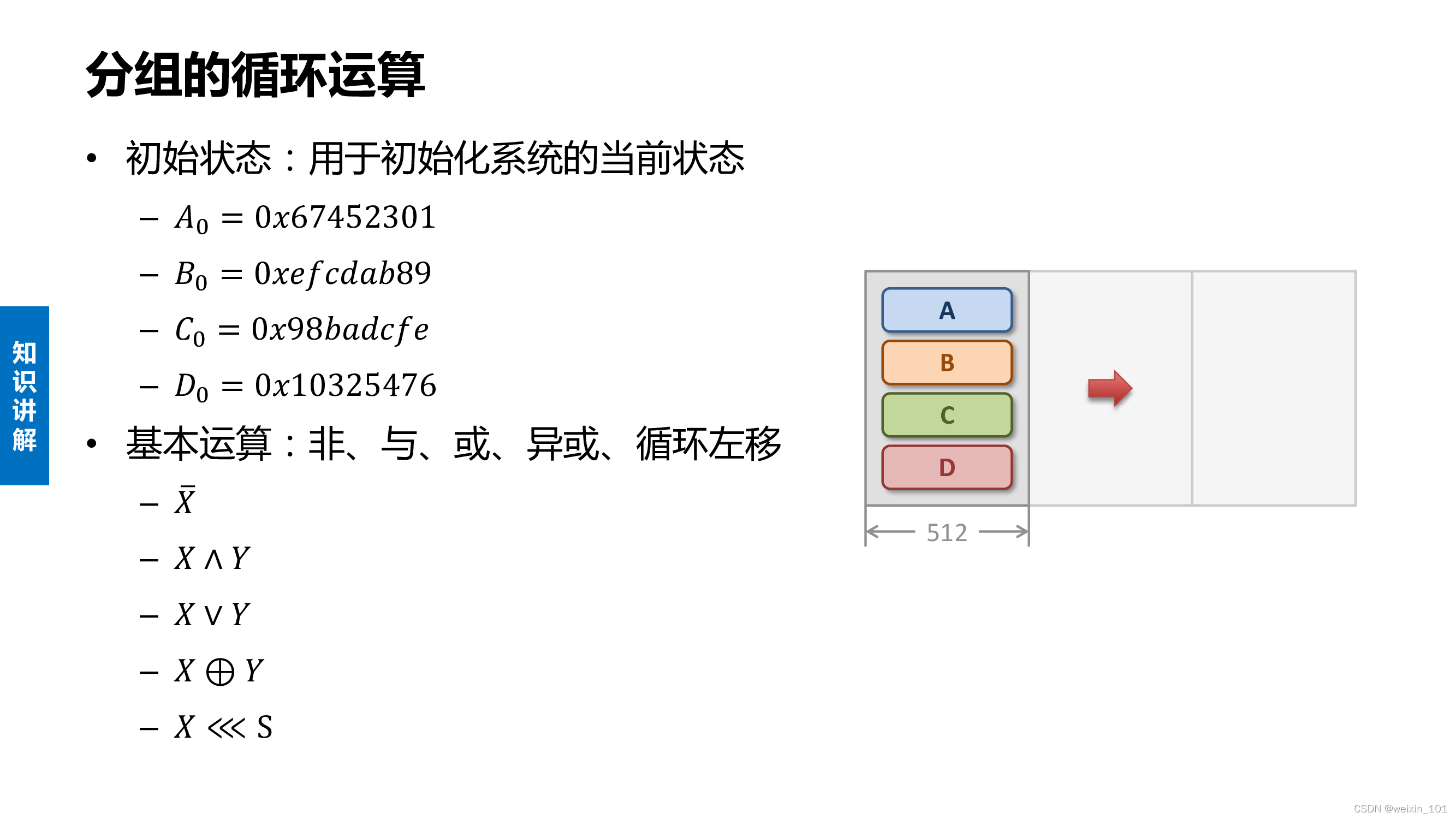
MD5算法的特点


MD5算法的内容








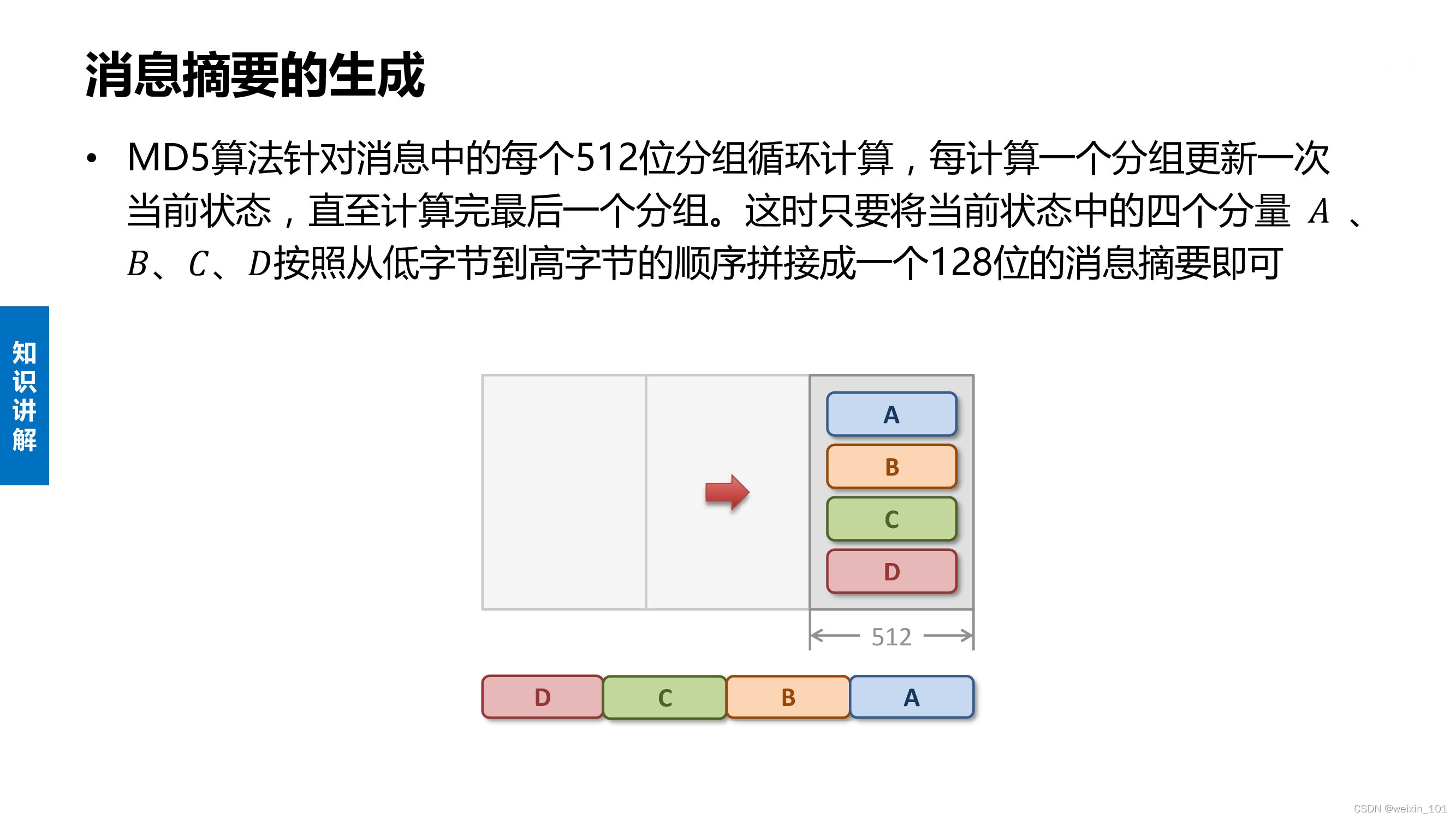
实训案例



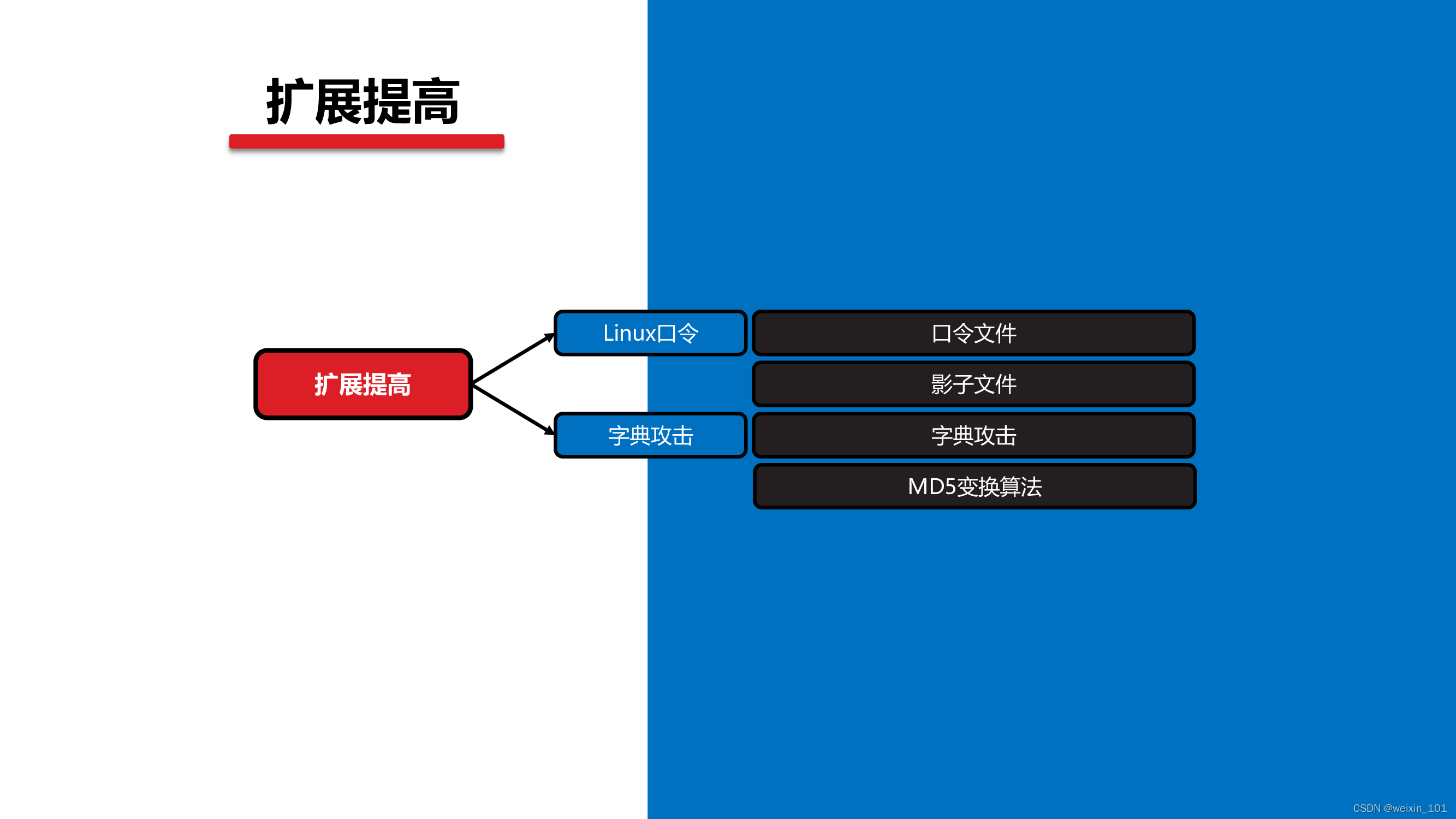
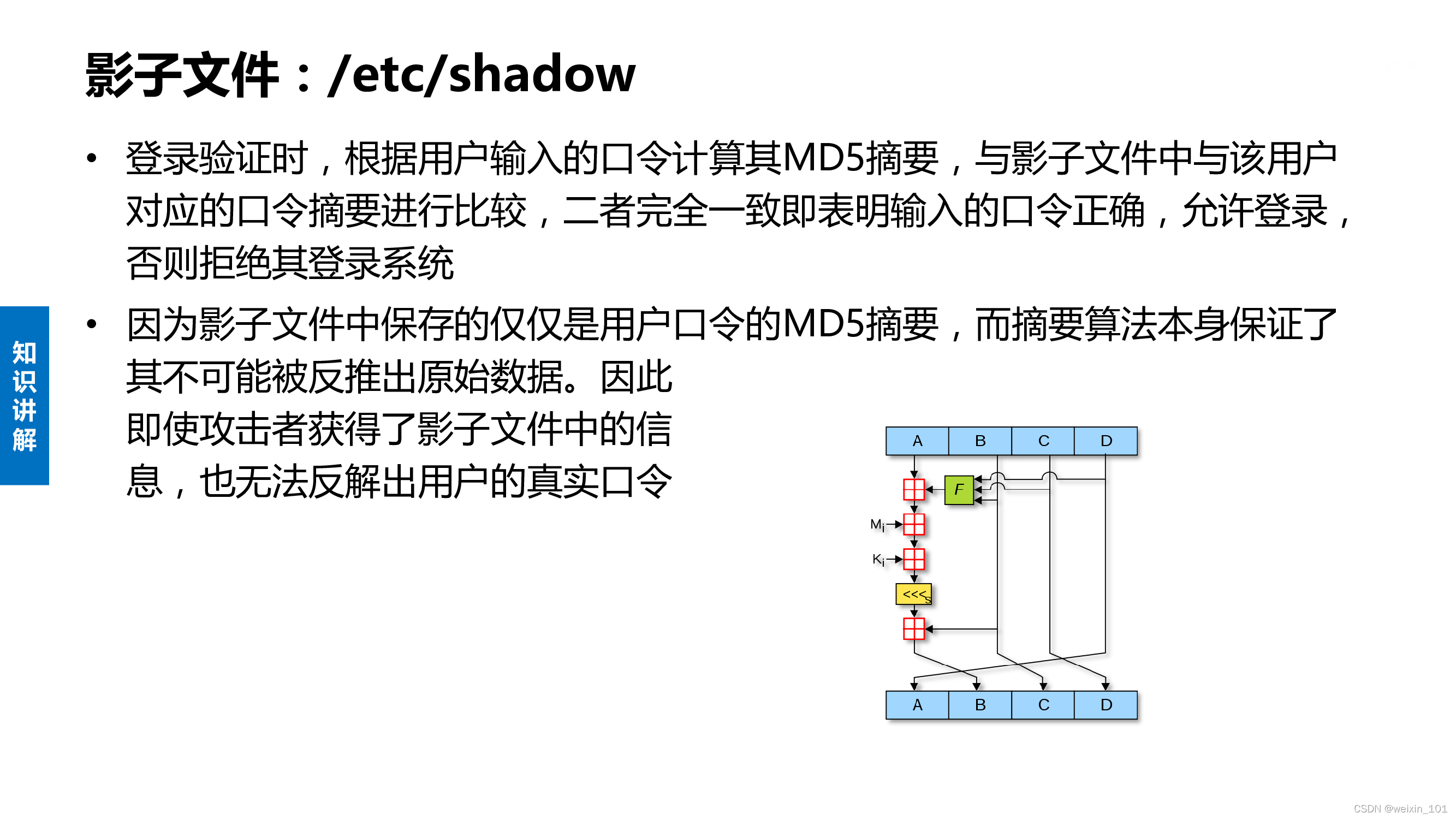
Linux口令与MD5算法



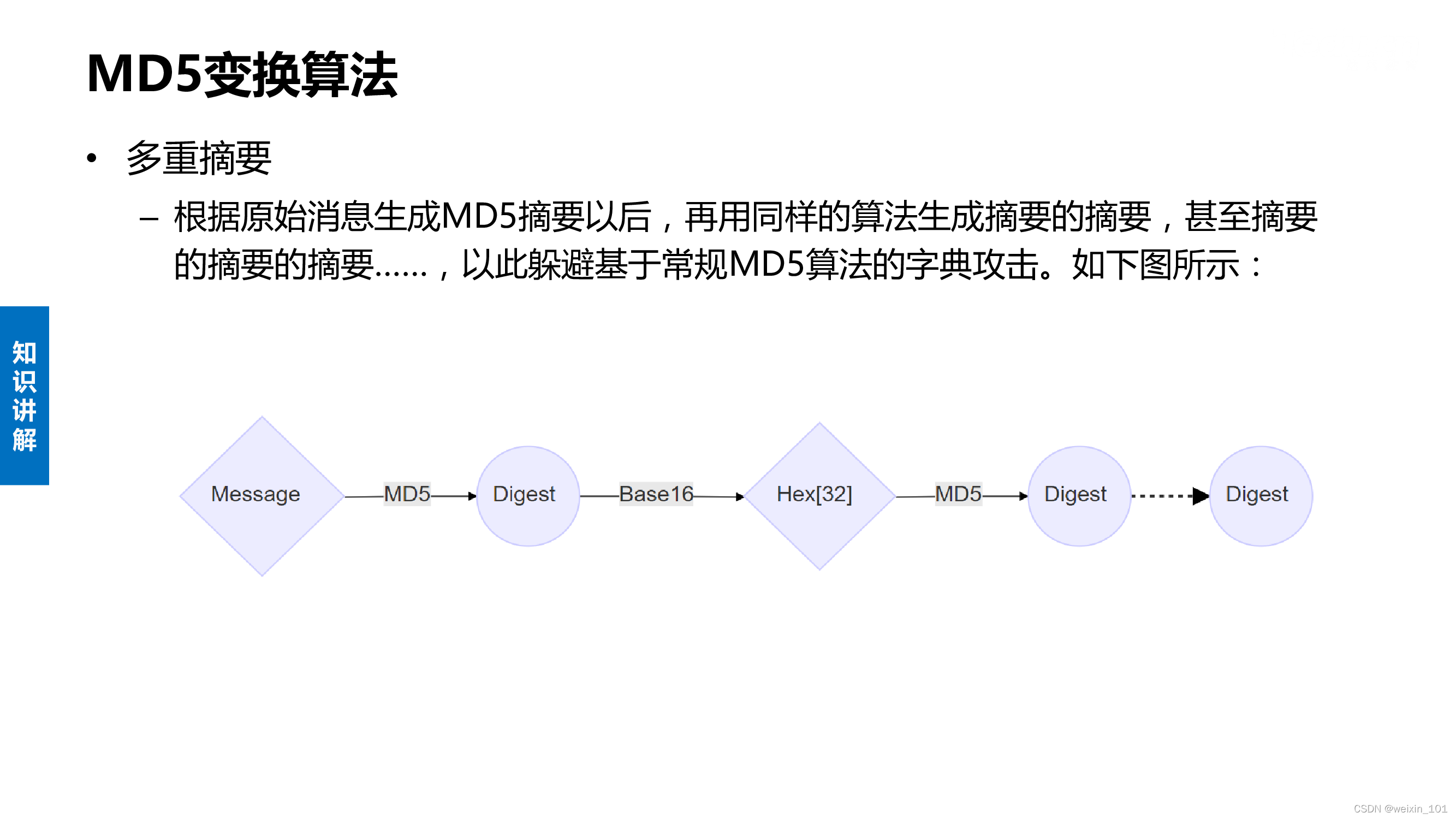
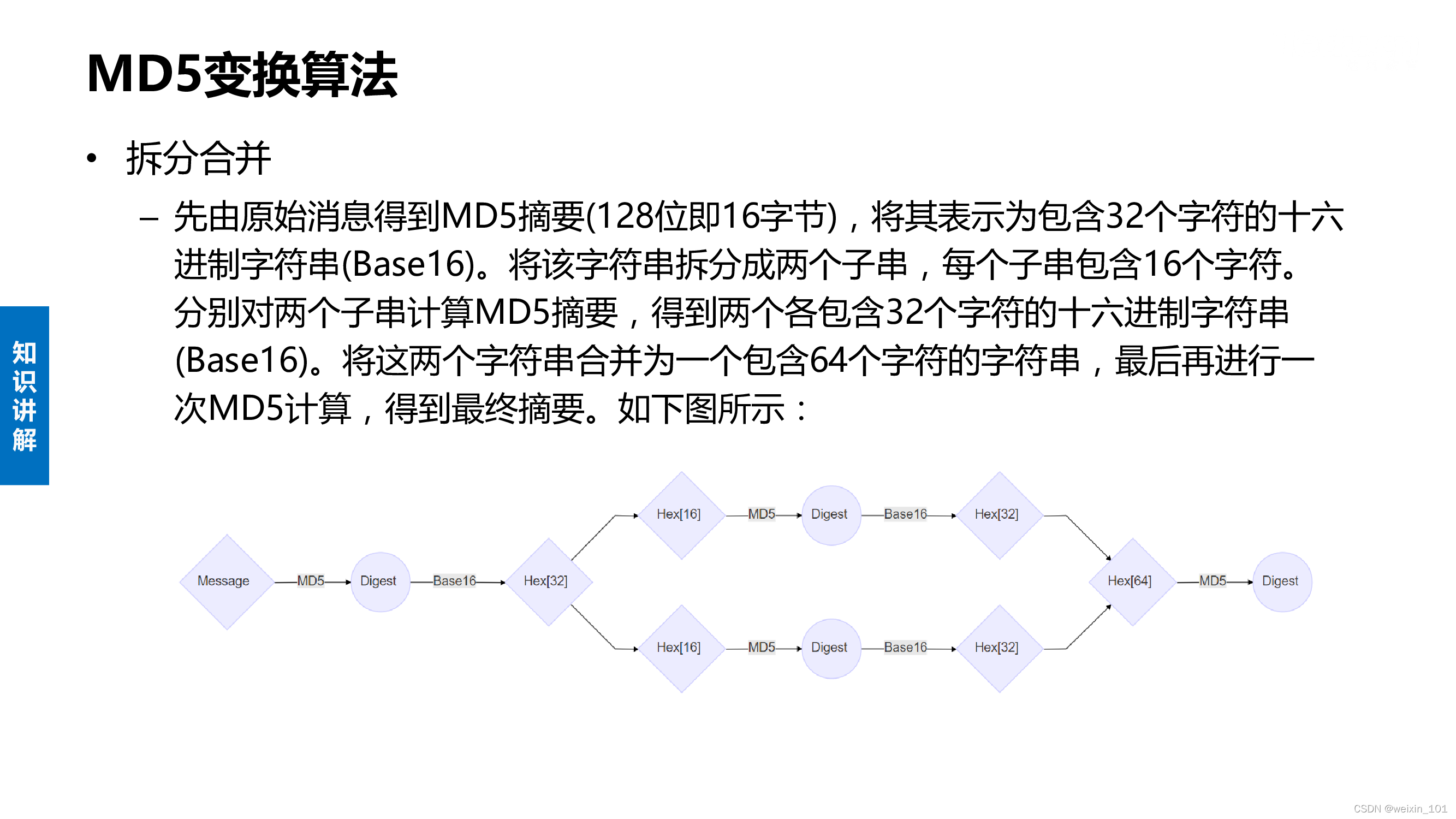
字典攻击与MD5变换算法




Unit06

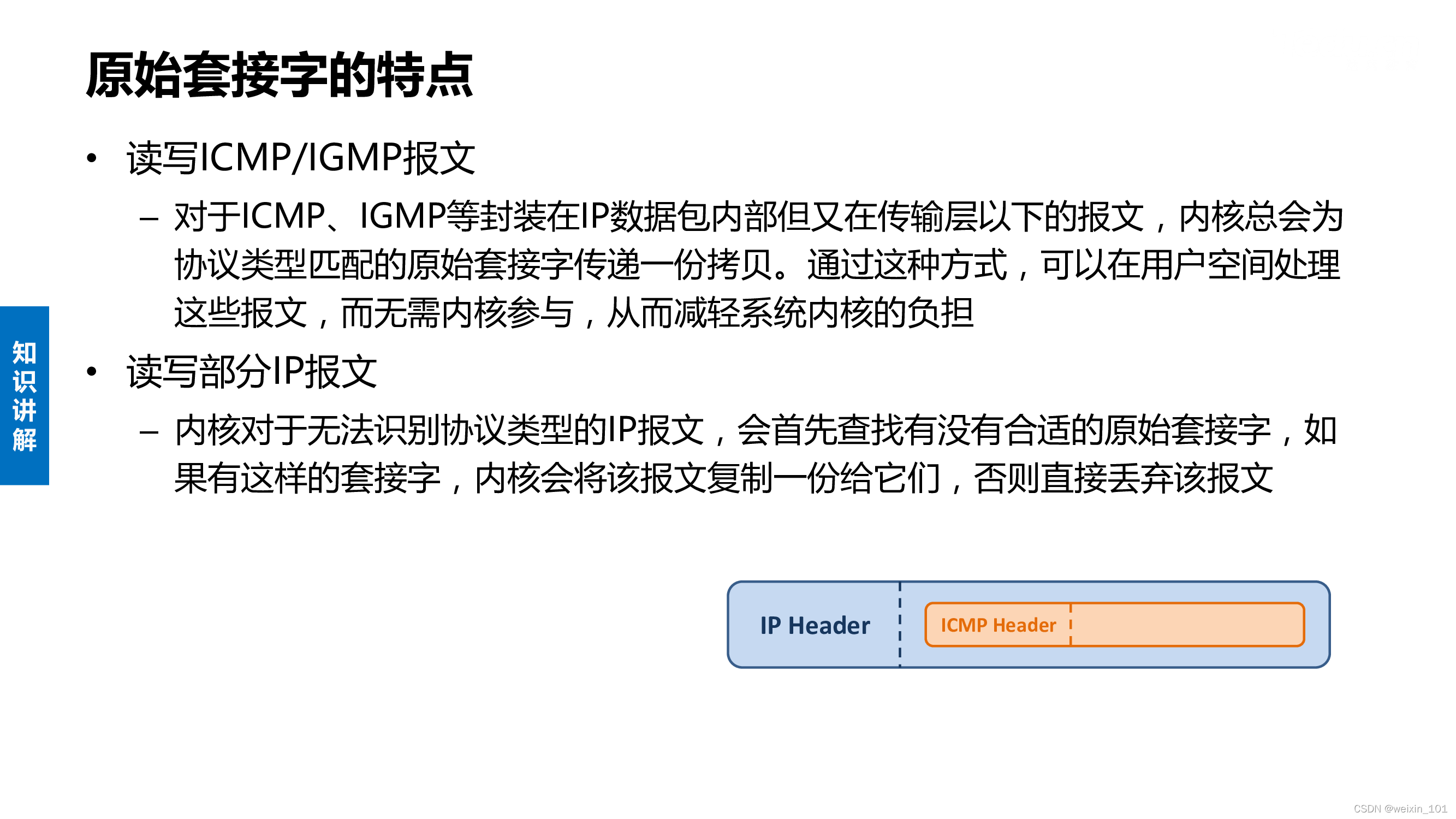
原始套接字







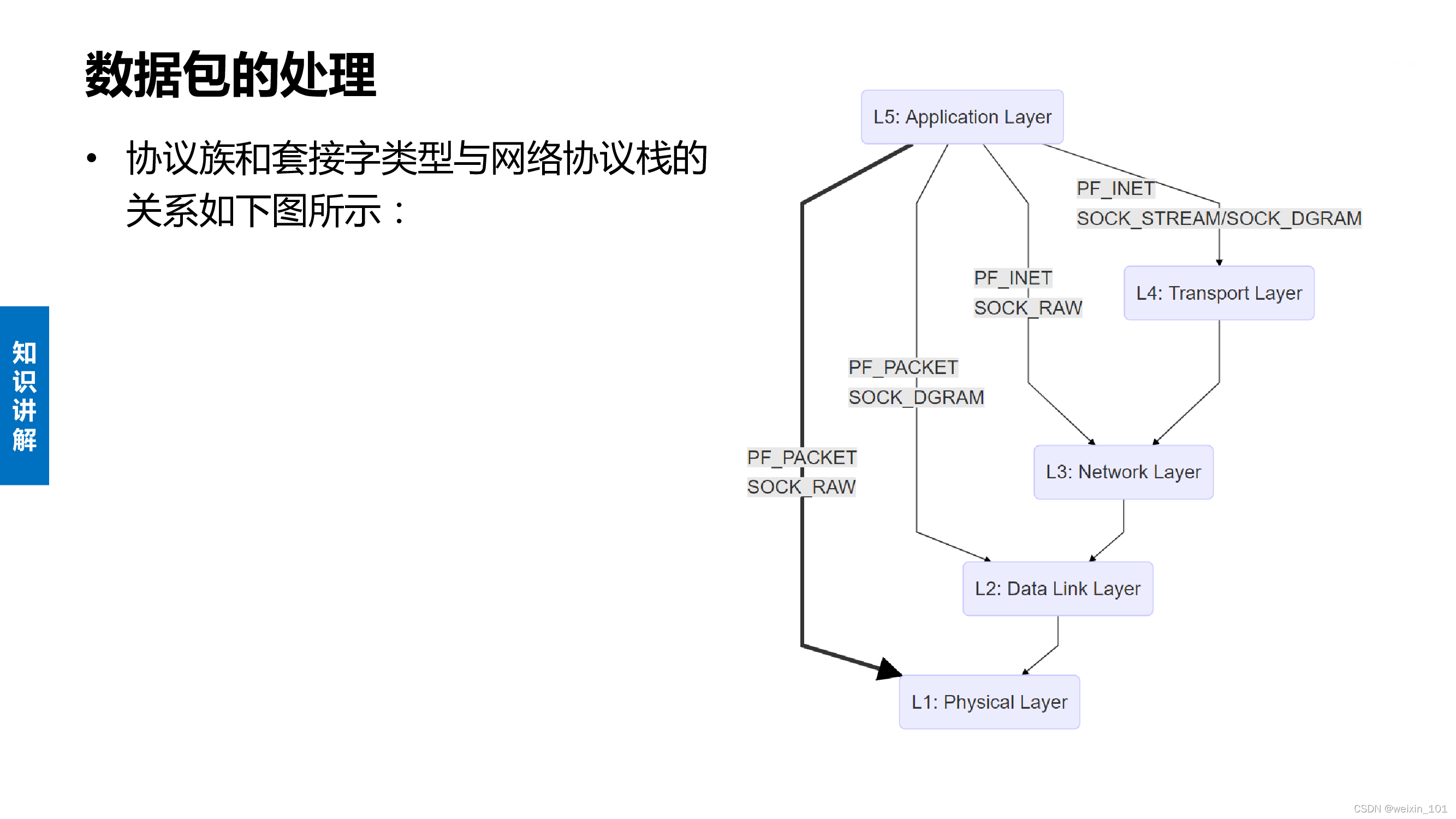

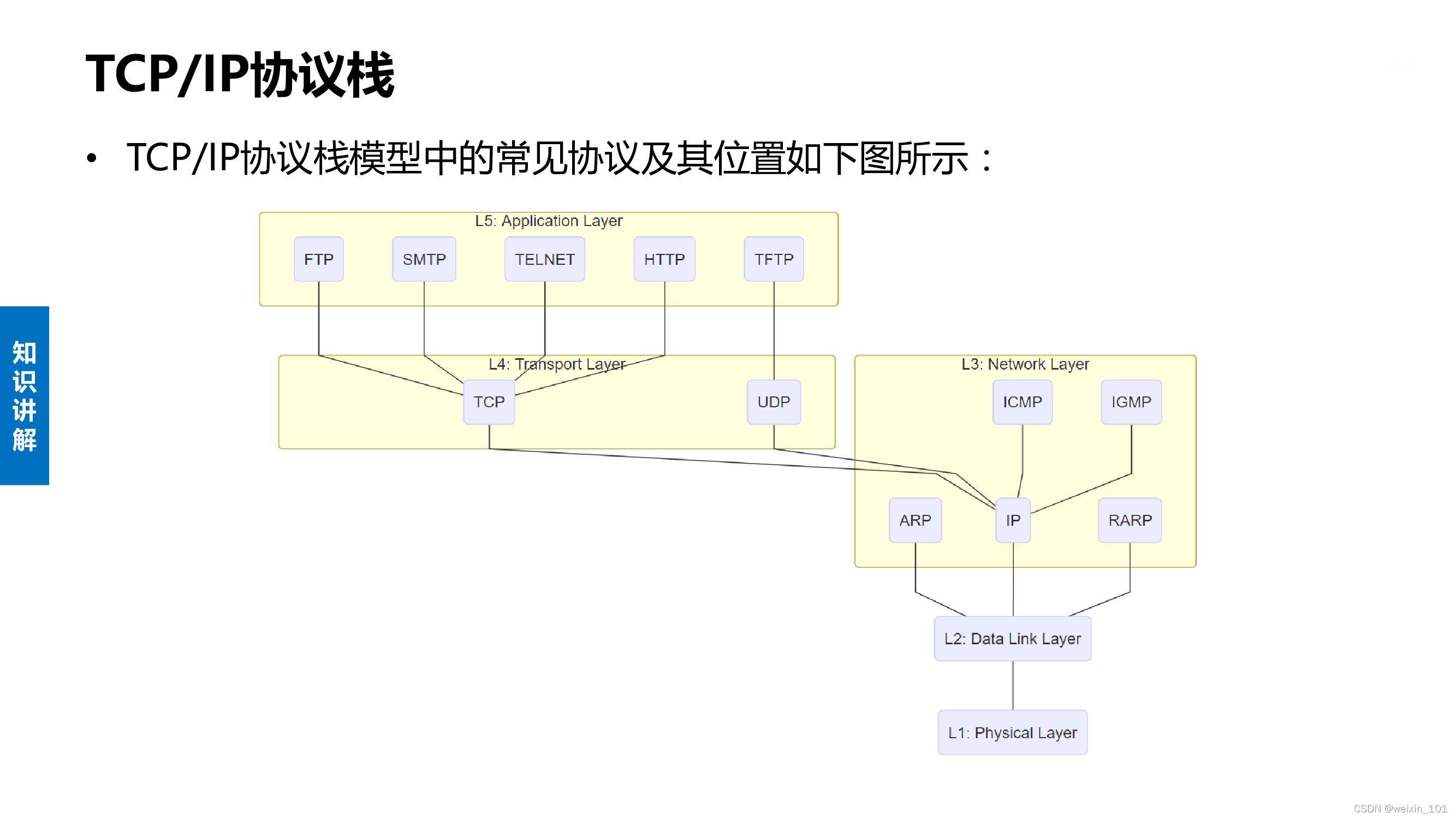
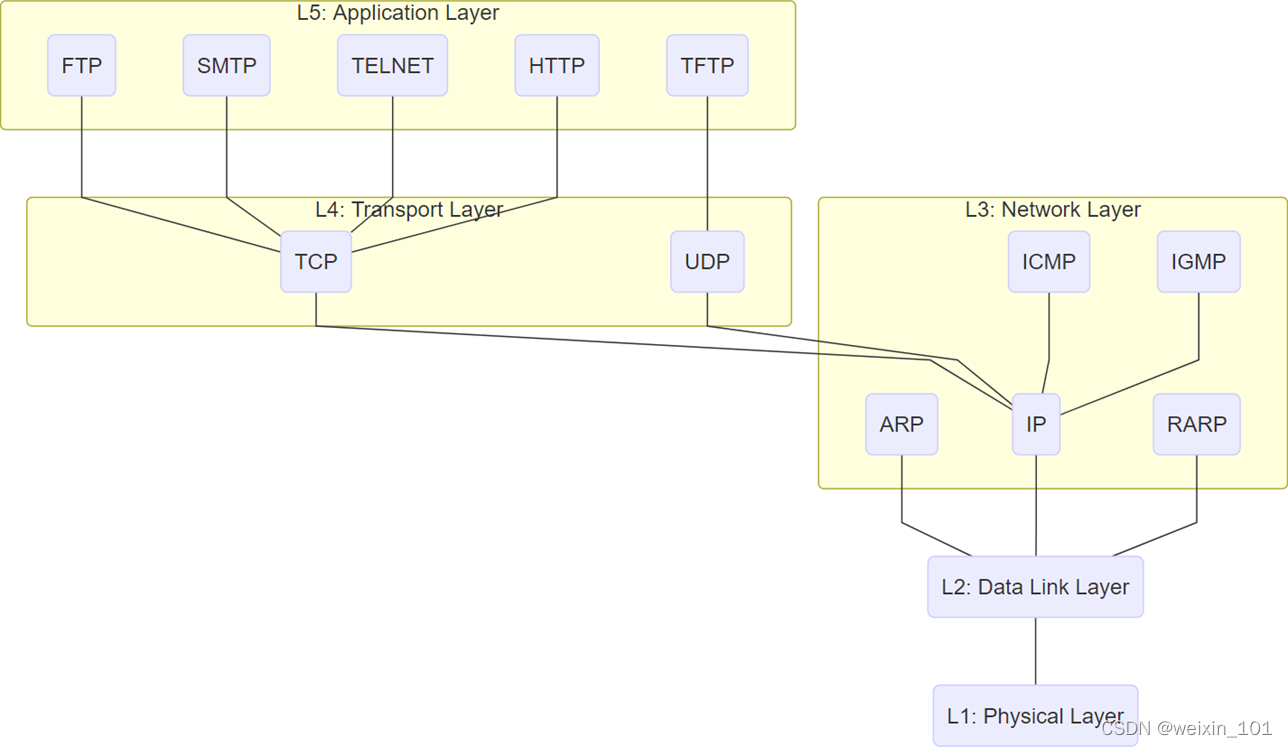
TCP/IP协议栈

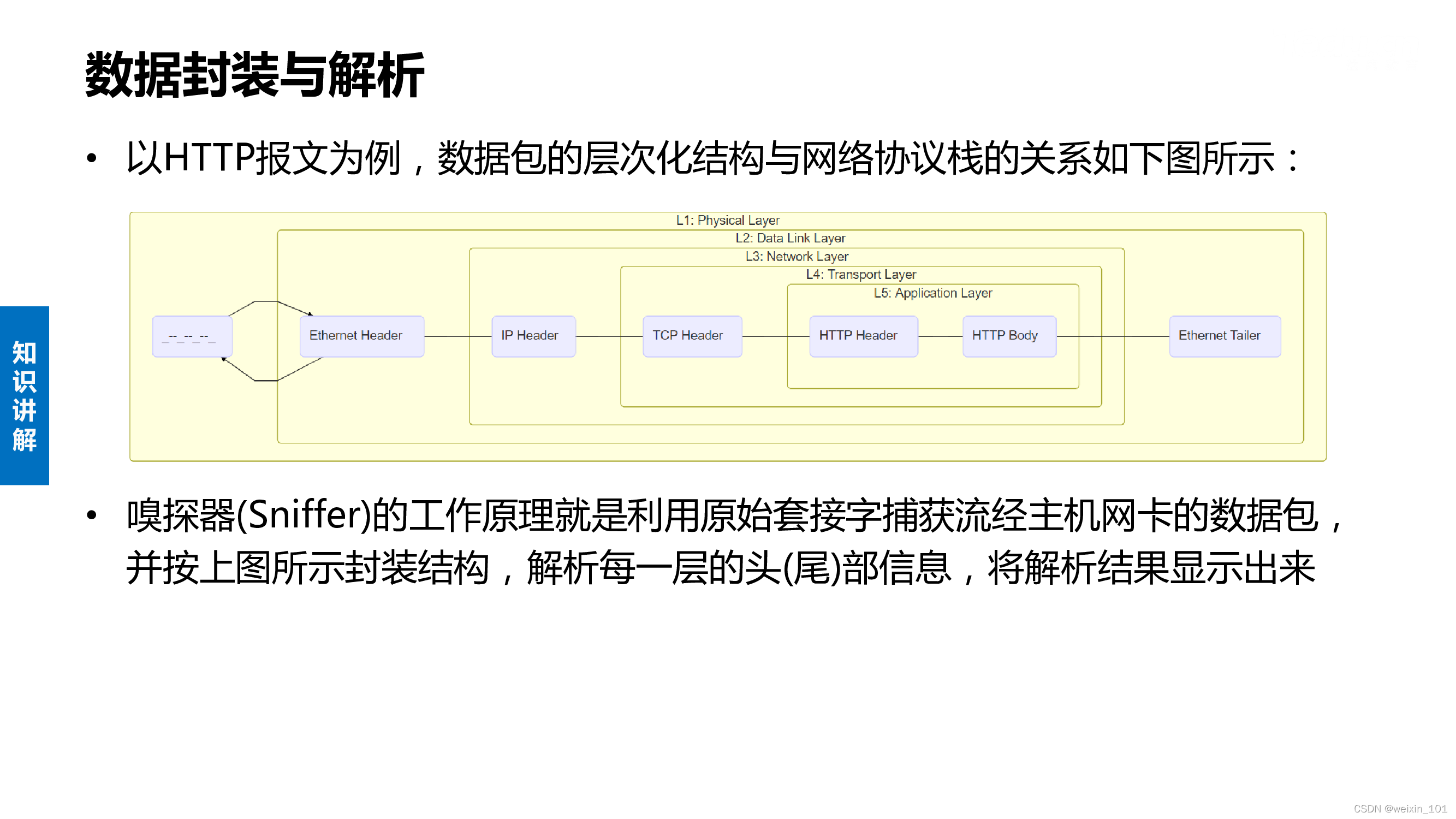
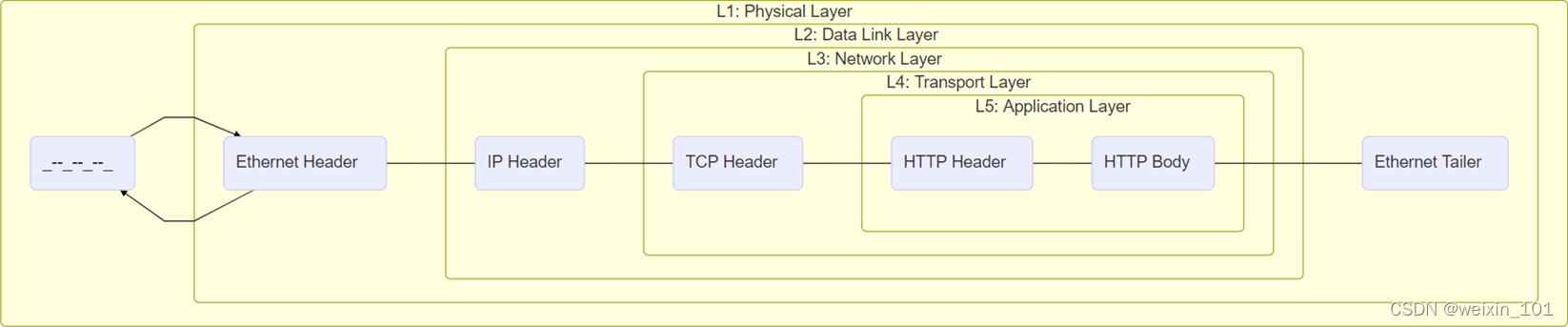
数据封装与解析


实训案例



通过libpcap库捕获数据包



通过tcpdump命令捕获数据包


Unit07

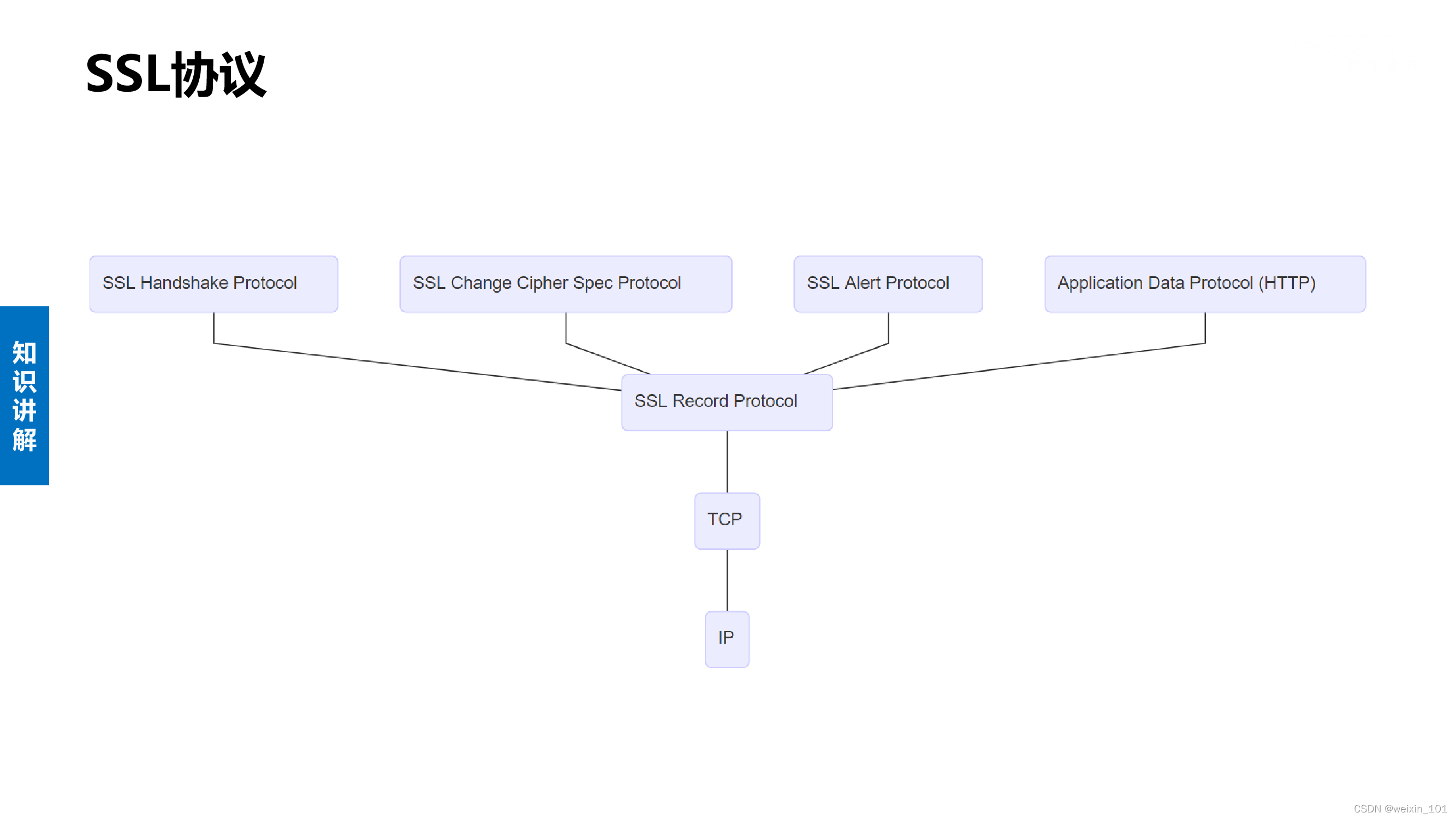
SSL协议




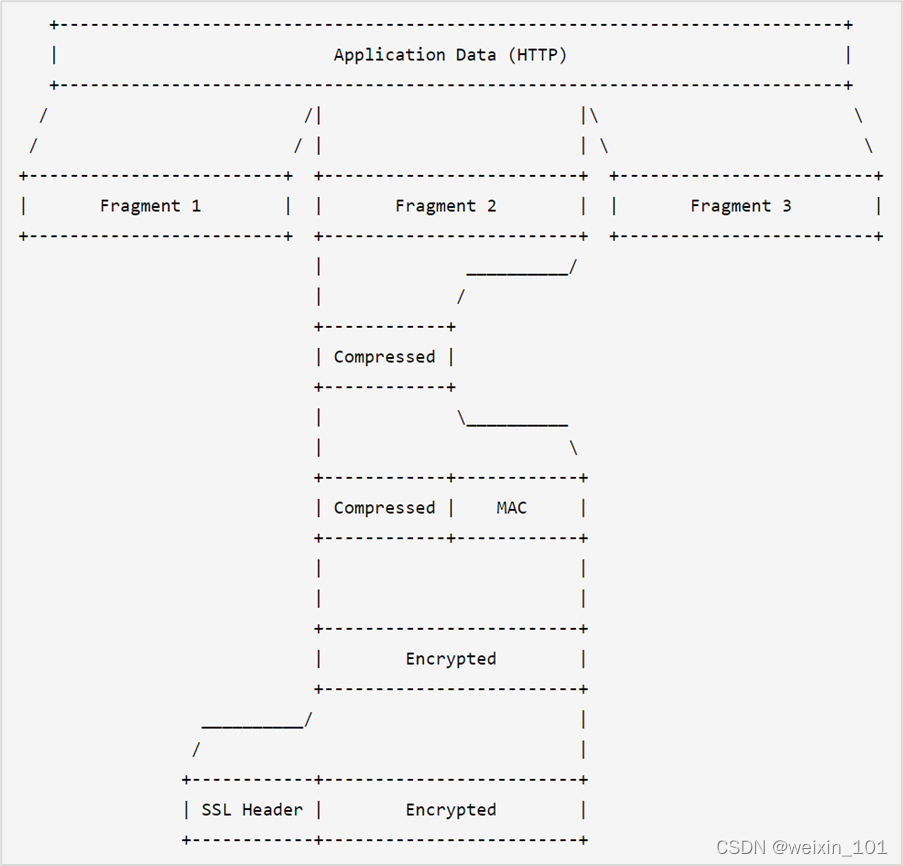







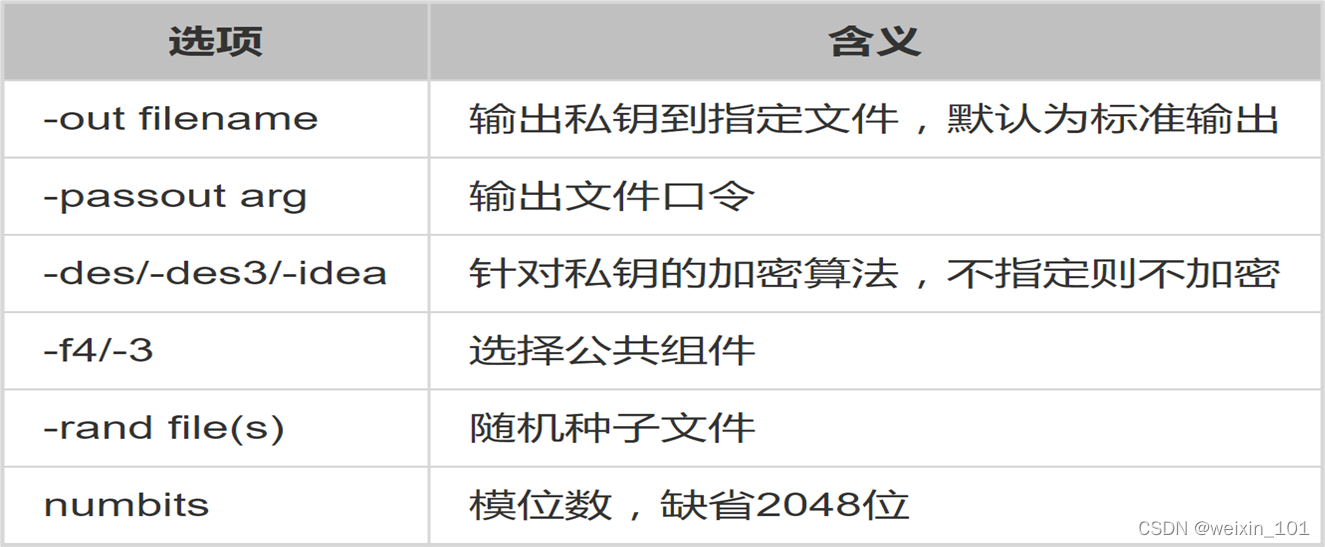
OpenSSL




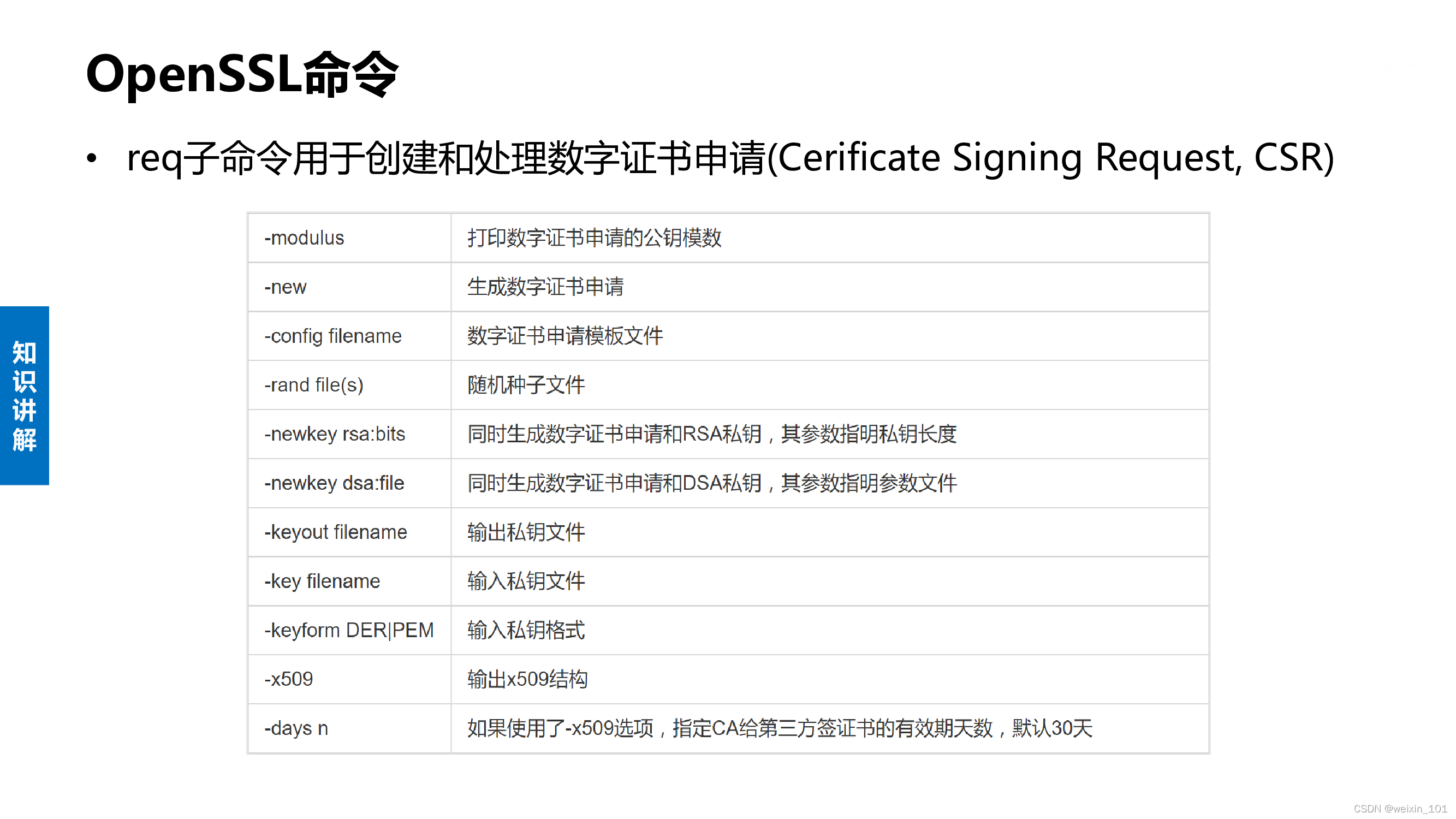
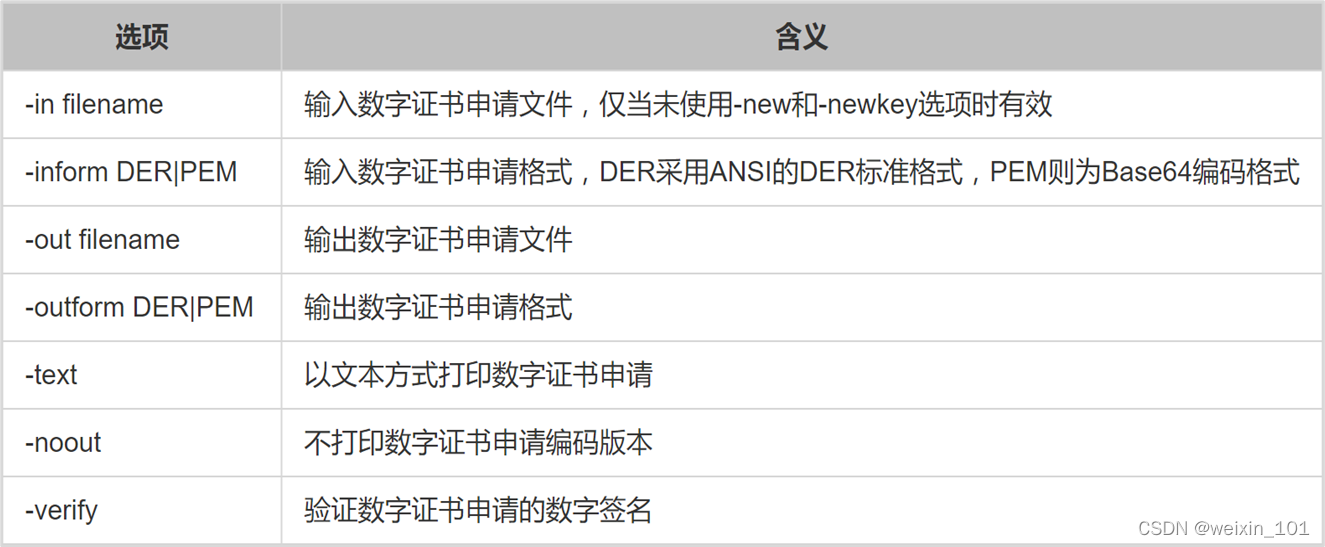
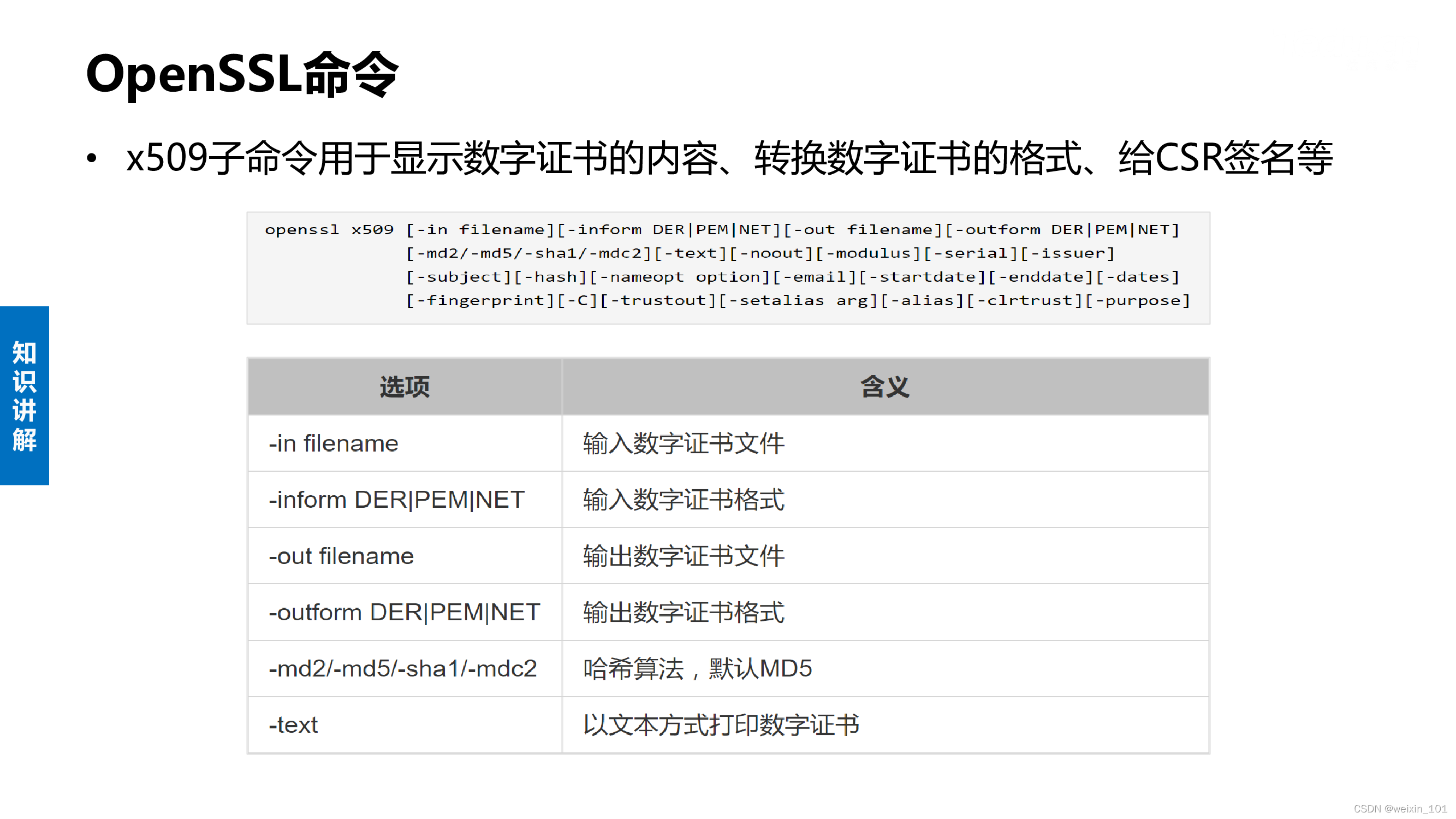
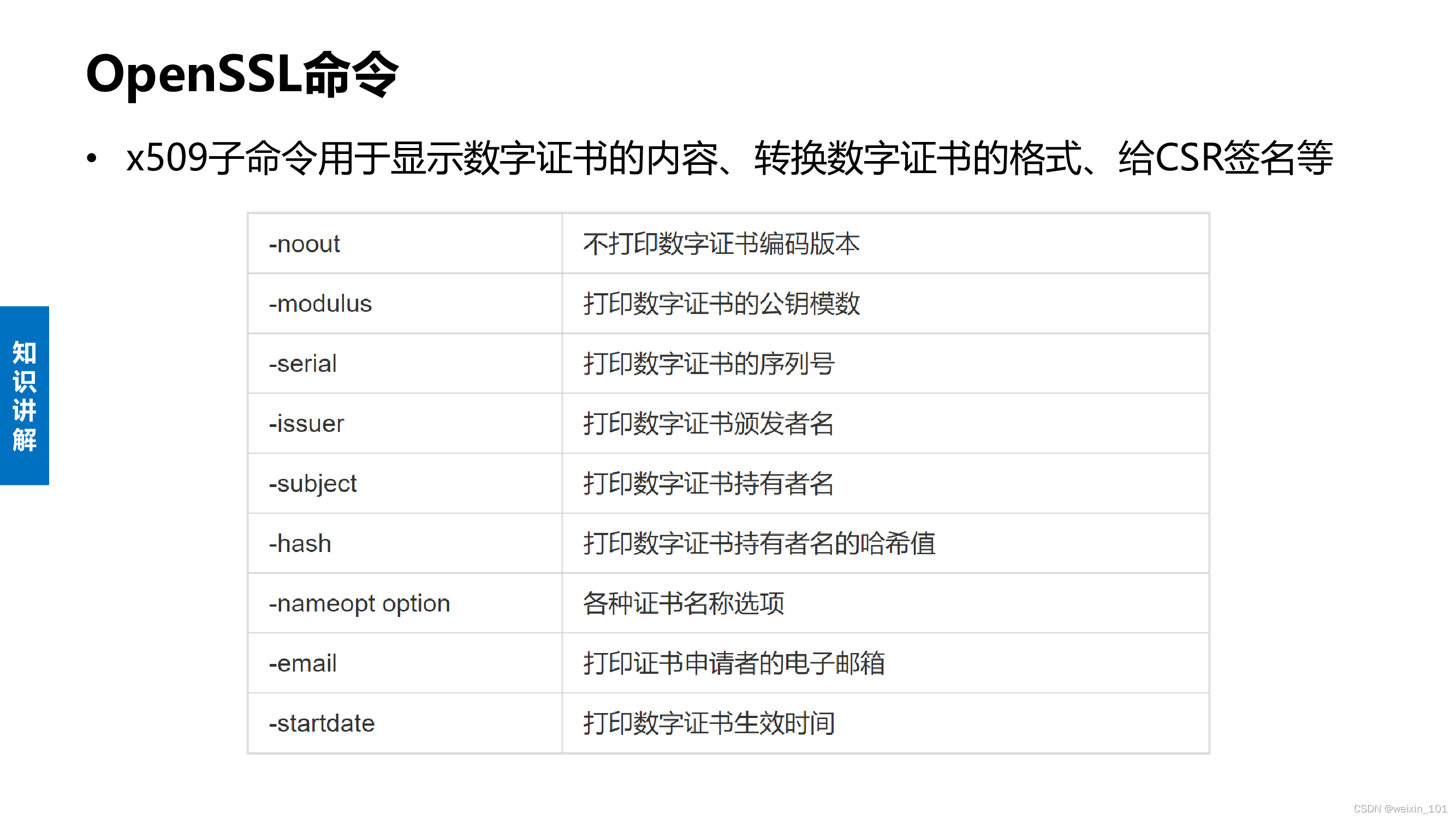
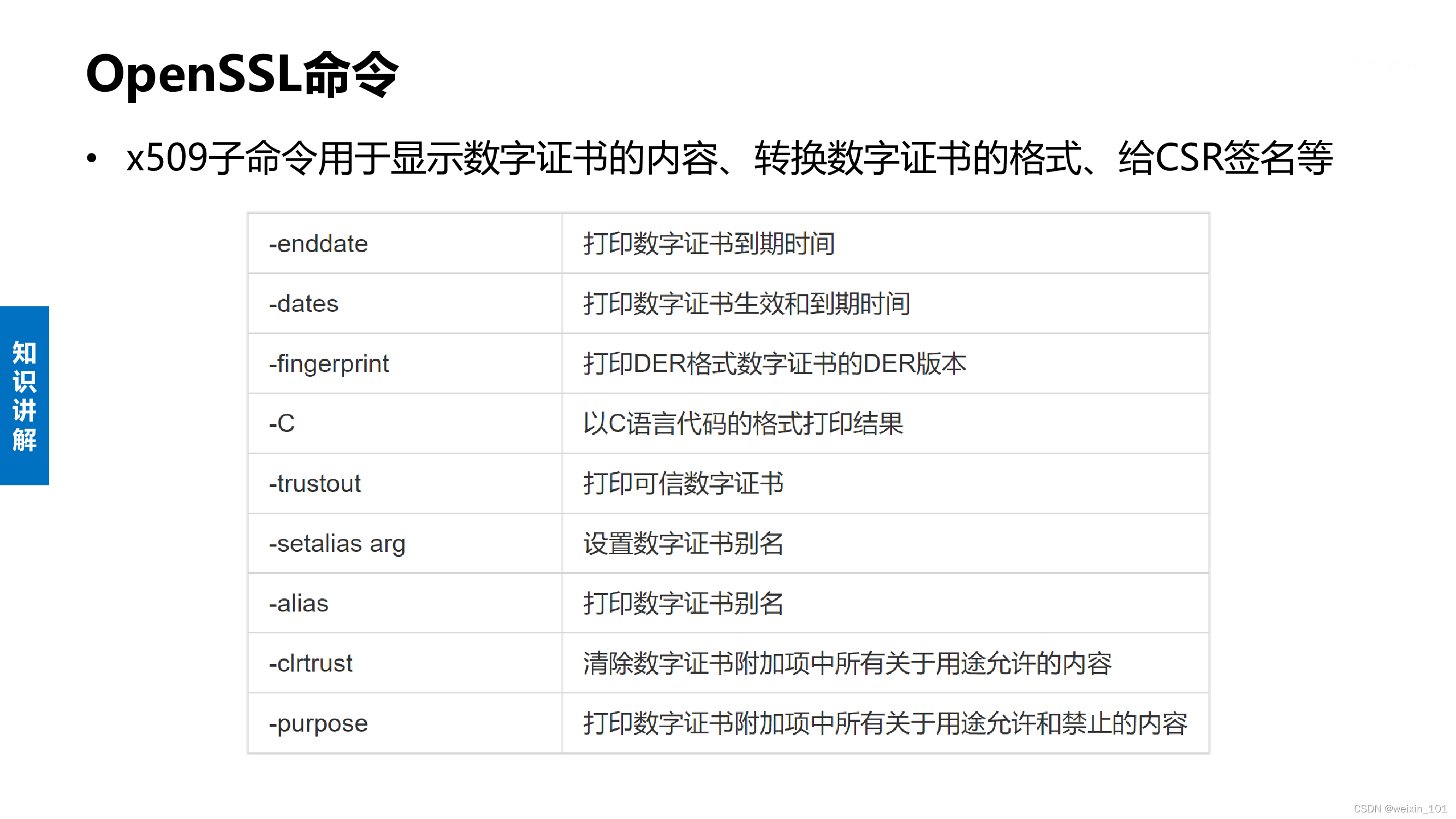
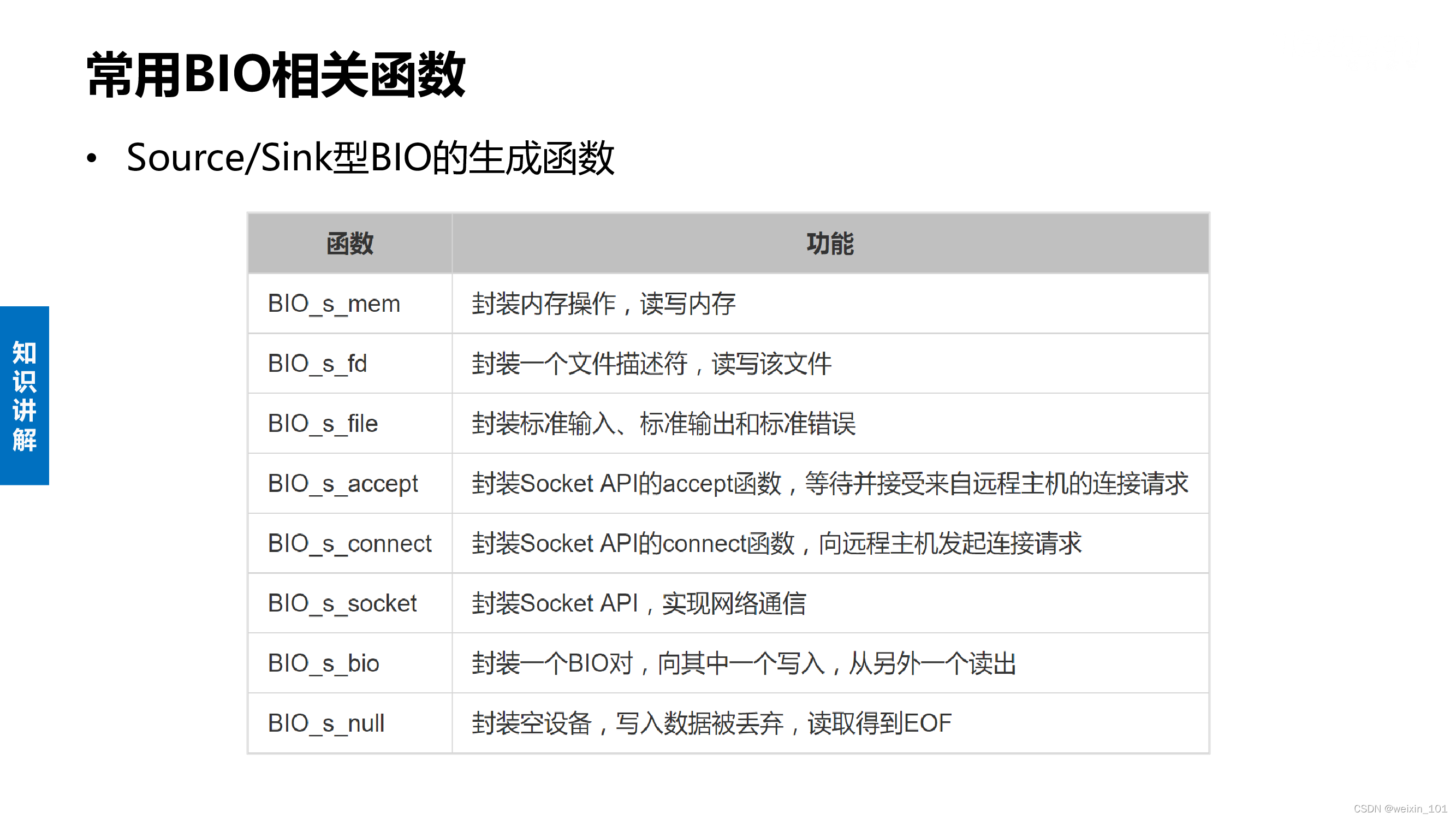
BIO结构








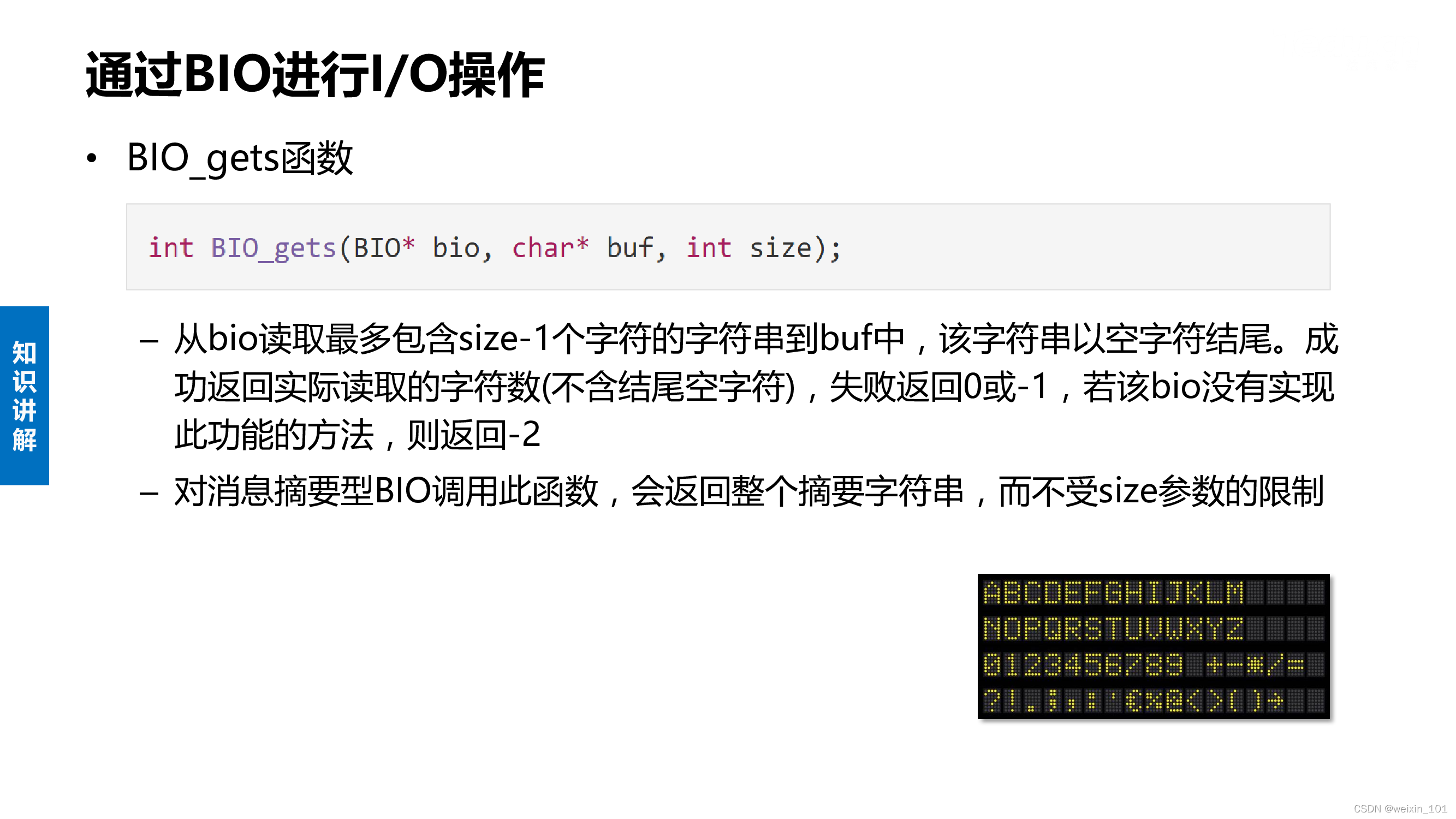
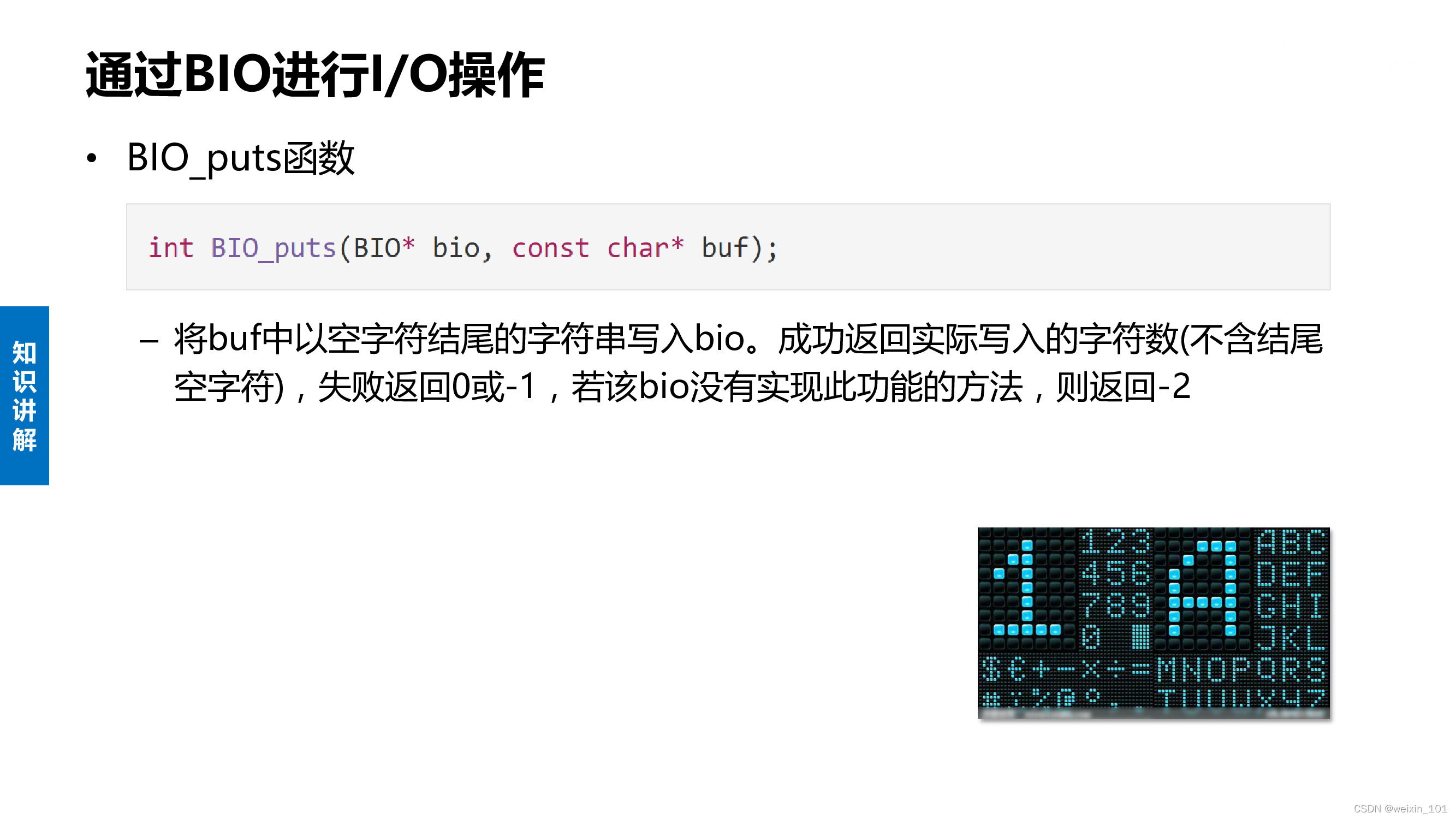

实训案例



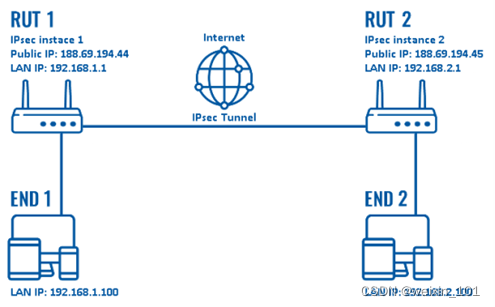
基于IPSec的安全通信



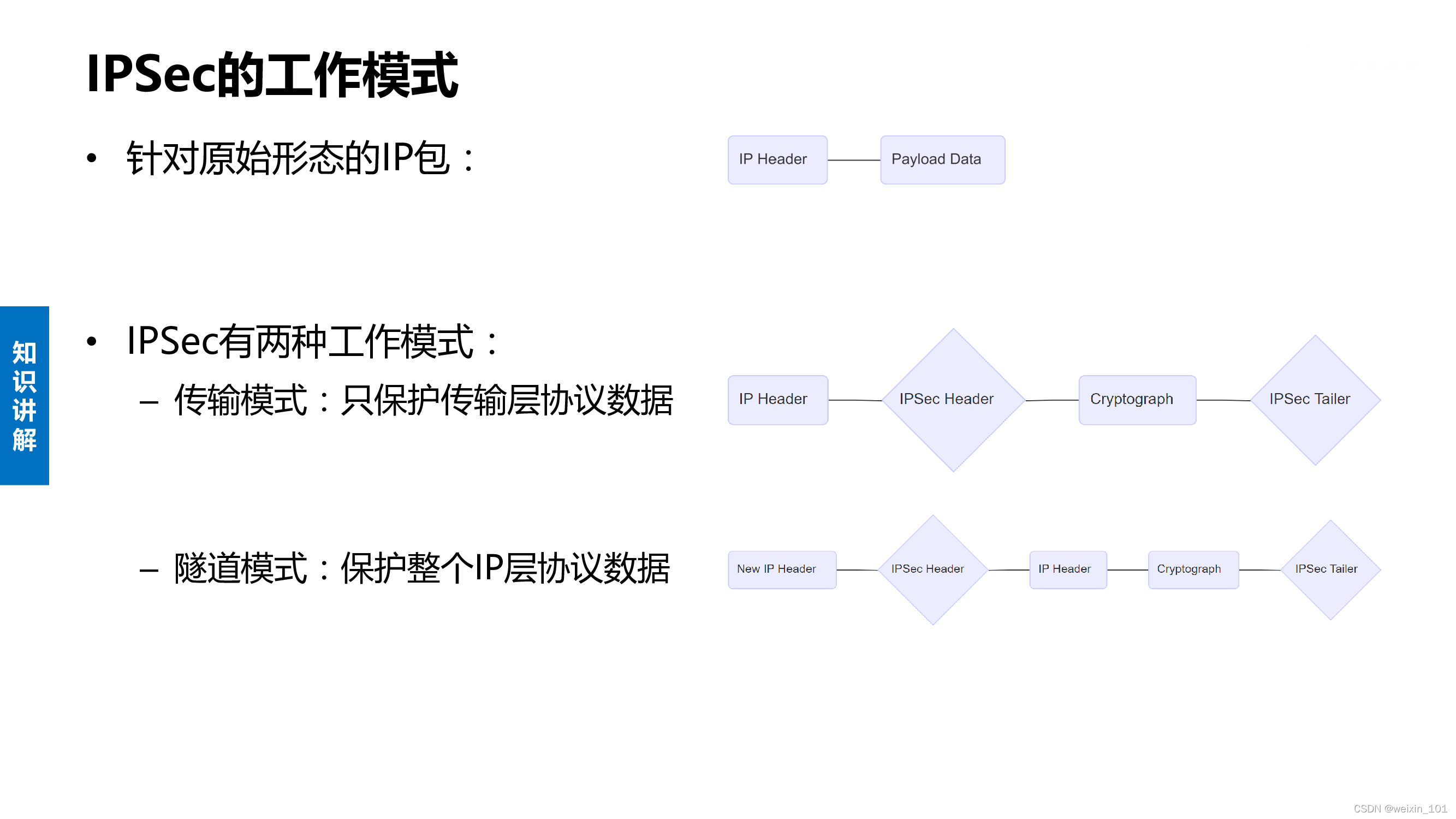
Unit08

ICMP扫描


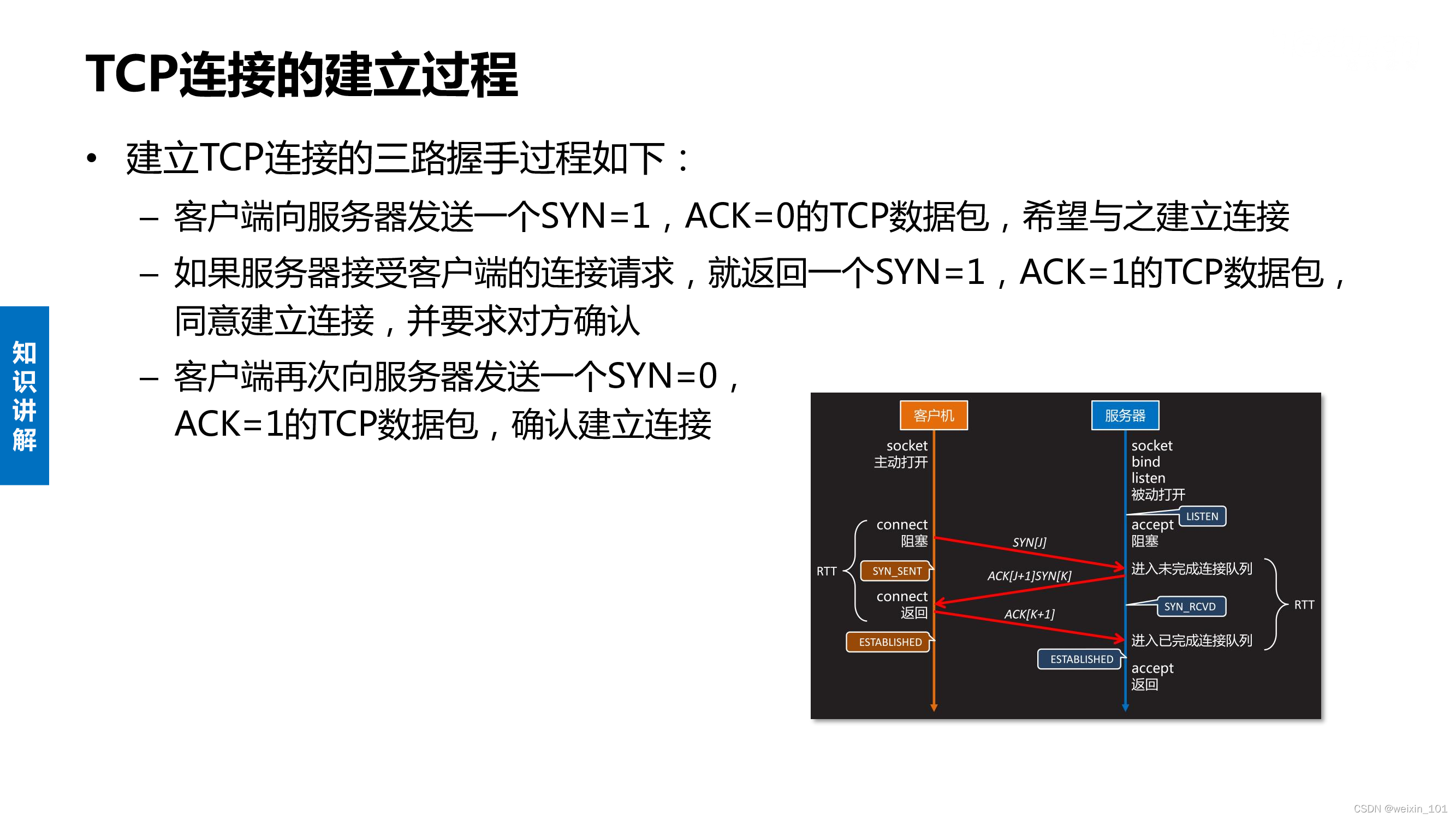
TCP扫描



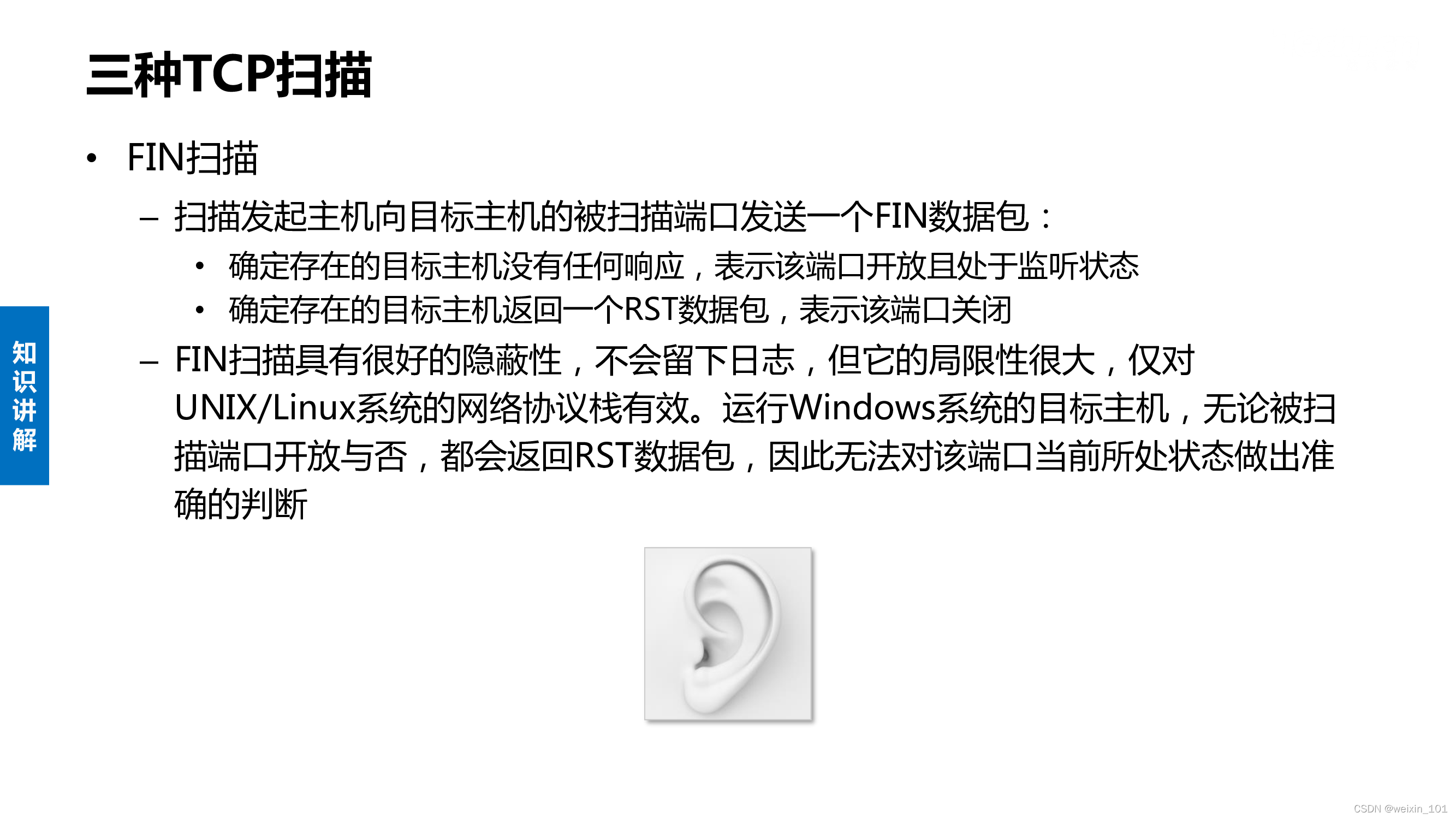
UDP扫描


通过原始套接字发送数据包












实训案例





基于Nmap的网络探测



Unit09
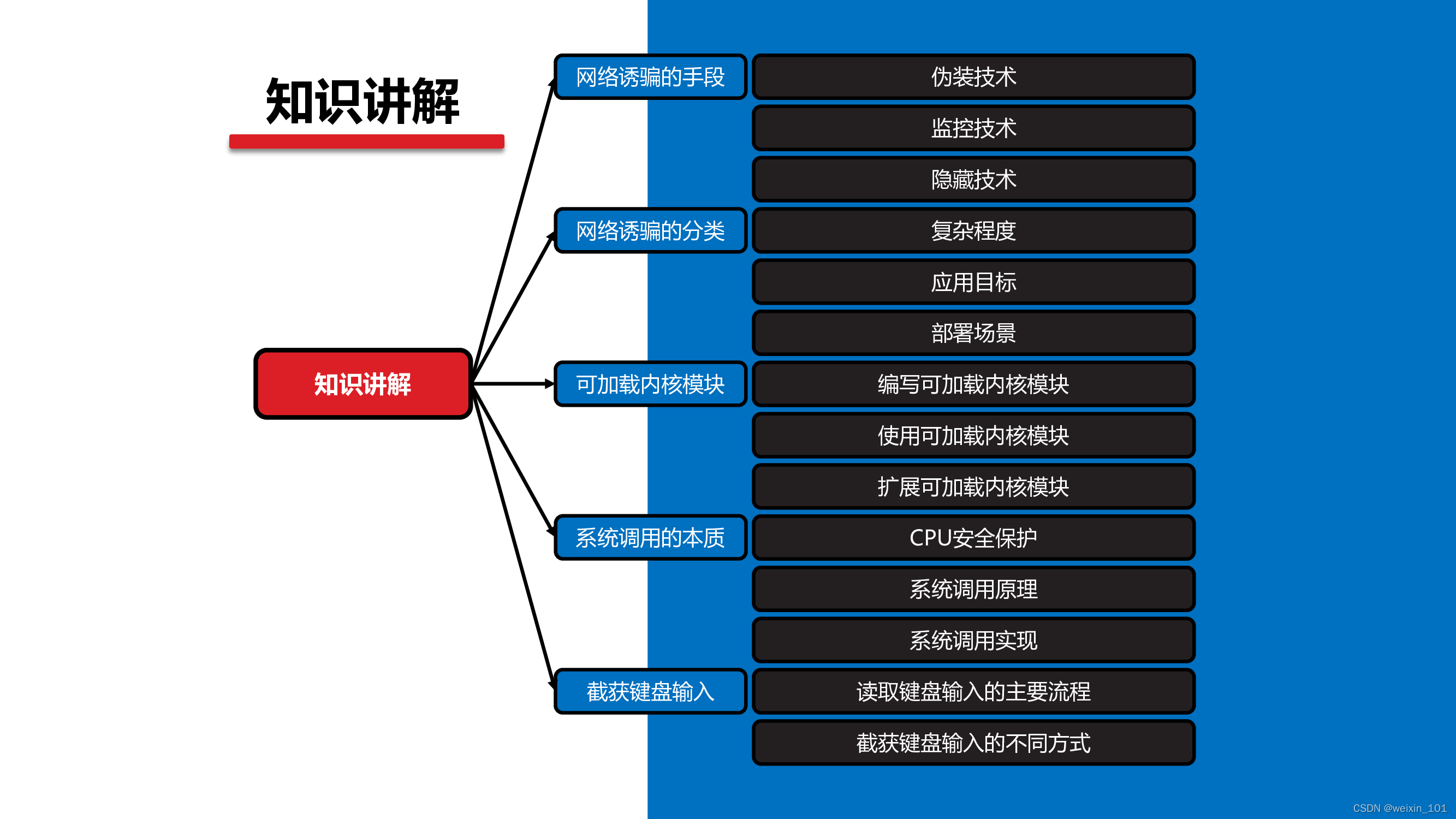
网络诱骗系统的手段





网络诱骗系统的分类




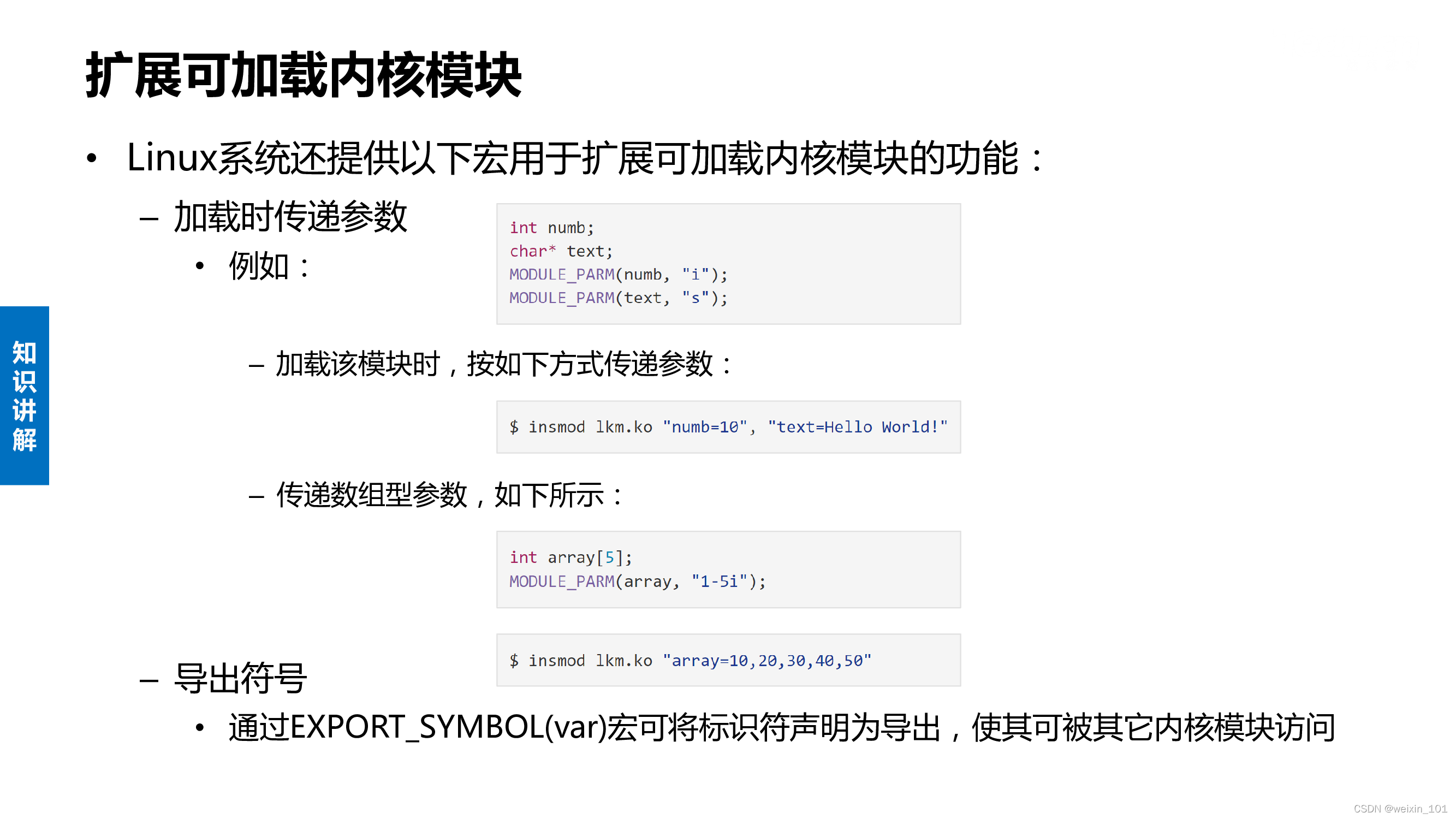
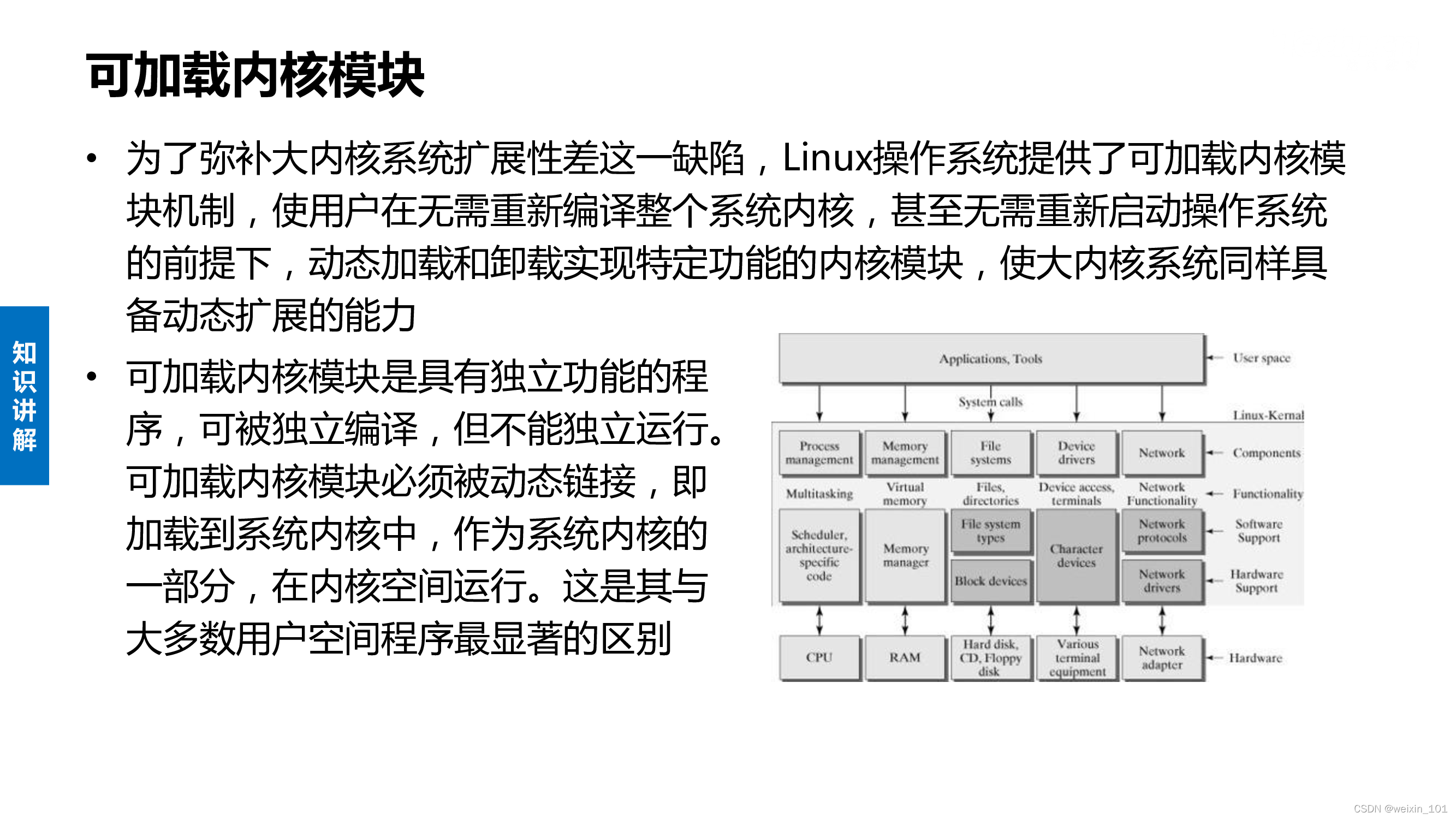
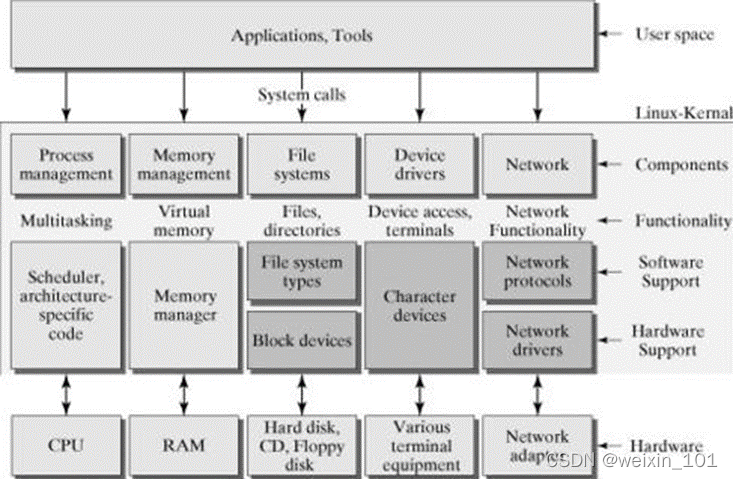
可加载内核模块





系统调用的本质





截获键盘输入


实训案例



启动是自动加载可加载内核模块


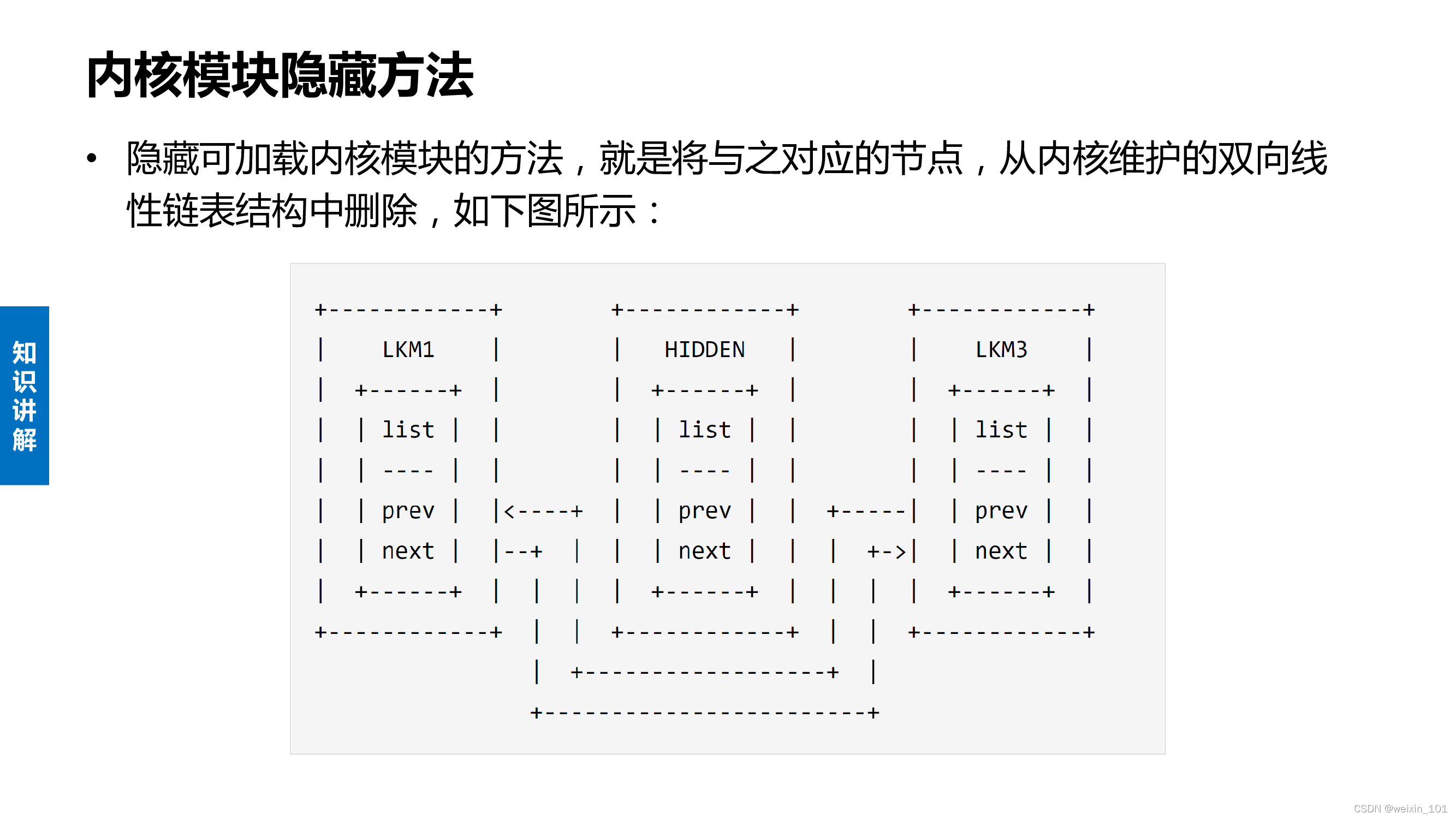
隐藏可加载内核模块



隐藏文件



Unit10

KDD Cup 1999数据集



K-Means聚类算法






K-Means聚类算法的缺陷和扩展



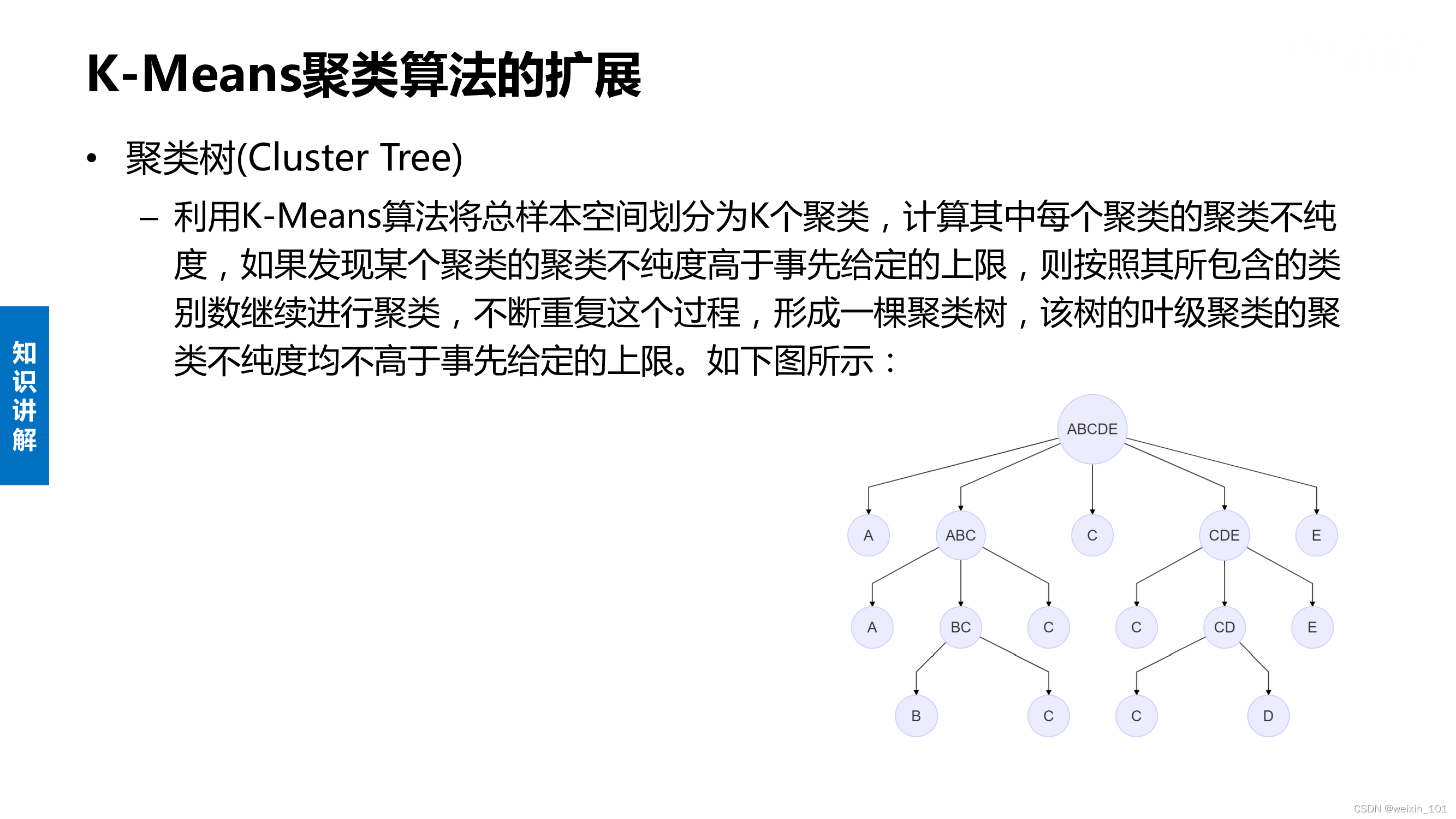
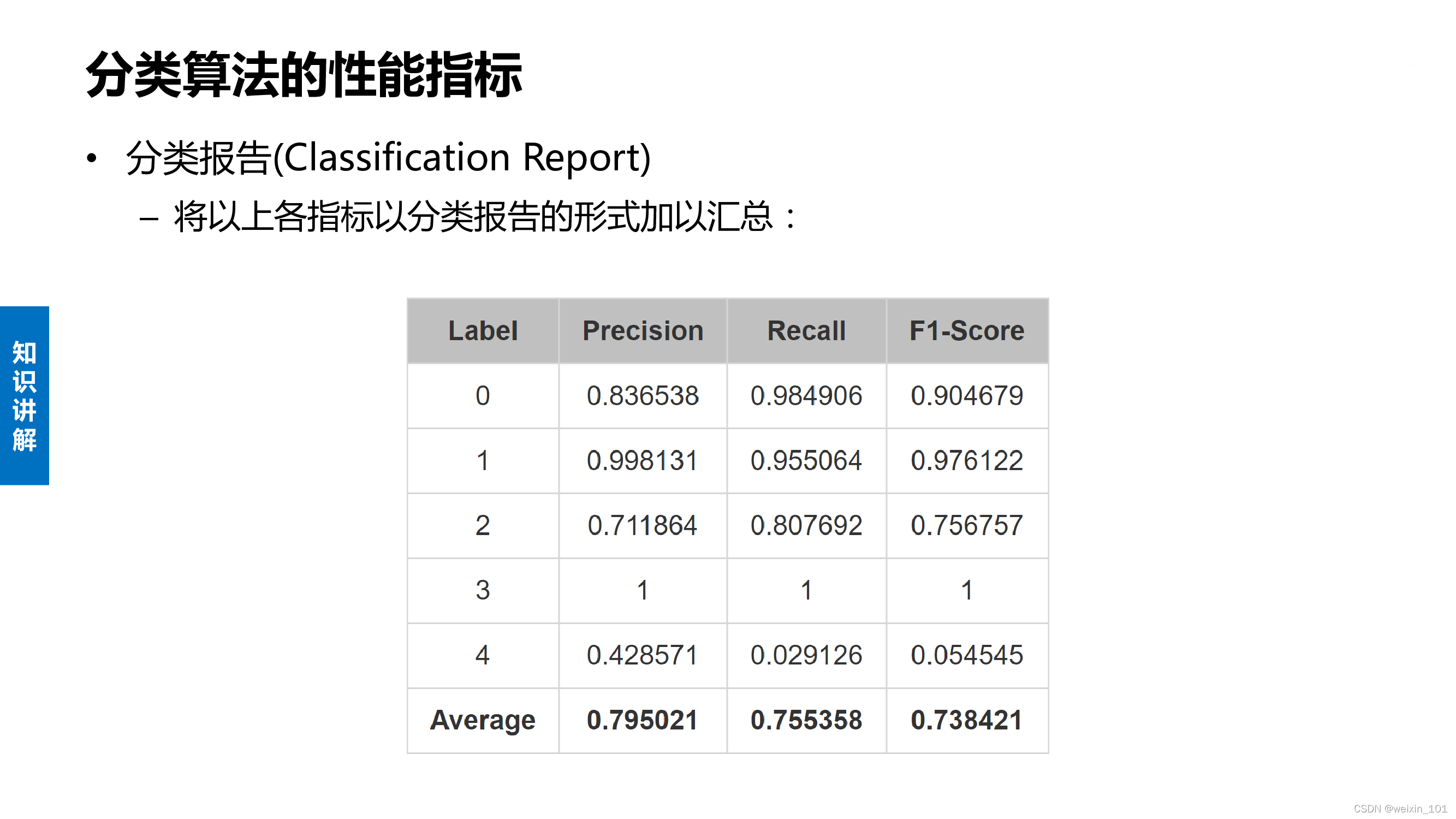
聚类和分类算法的性能指标






实训案例



参考代码:
/// 1 训练数据和测试数据的预处理
#define TRAINING_INPUT "data/kddcup.data_10_percent"
#define TRAINING_OUTPUT "data/training.dat"
#define TESTING_INPUT "data/corrected"
#define TESTING_OUTPUT "data/testing.dat"
int main(void) {
// 1 训练集预处理器
Preprocessor training(TRAINING_INPUT, TRAINING_OUTPUT);
// 预处理训练数据
training.preprocess();
// 2 测试集预处理器
Preprocessor testing(TESTING_INPUT, TESTING_OUTPUT);
// 预处理测试数据
testing.preprocess() ;
}
/// 2 根据预处理数据以及kmeans算法,训练模型,并使用测试数据测试模型,得到测试的结果(分类报告)
#define TRAINING_FILE "data/training.dat"
#define TESTING_FILE "data/testing.dat"
int main(int argc, char* argv[]) {
// 1 创建KMeans 模型对象,特征数为20
KMeans model(20);
/// 训练
// 2 参数是训练集文件,读取文件中的样本训练得到模型(树)
model.train(TRAINING_FILE);
{
// 2.1 读取训练集文件
/// 类的成员:list<vector<double> > training; // 训练集,类的成员
/// list<vector<double>*> samples; // 样本集,///采用指针,提高效率,samples是对training的引用
readTraining(filename);
{
// 读取训练集文件
double sample[features+1];
while (ifs.read ((char*)sample, sizeof(sample))) {
training.push_back(vector<double>(sample,sample + sizeof(sample) / sizeof(sample[0])));
samples.push_back(&training.back());
}
}
// 2.2 训练以得到模型
train();
{
//2.2.1 初始化聚类中心
initCenters();
/// MAXIT是最大迭代次数
for (size_t i = 0; i < MAXIT; ++i) {
// 2.2.2 聚类划分
cluster();
// 2.2.3 更新聚类中心
if (!updateCenters())
break;
} //for
// 检查每个聚类的聚类不纯度,最终得到模型树
for (CCLS cls = clusters.begin(); cls != clusters.end(); ++cls) {
double ci = impurity(*cls);
// 聚类不纯度过高
if (ci > MAXCI && level < MAXLV)
// 在子模型中继续聚类
models[cls->first.back()] = KMeans(level + 1, cls->second);
{
// 训练,得到子模型
train();
}
}
} //2.2
} //2
// 3 打印模型(树)
cout << model;
{
for //遍历聚类集,是聚类的集合;聚类是由聚类中心,和聚类中的样本集组成
{
//打印聚类的类别:聚类中样本的数量
}
// 如何还有子模型,递归打印子模型
}
///测试
// 用来保存测试结果
vector<pair<double, double> > labels;
// 4 测试函数的输入参数是测试样本,返回值是每个样本对应的预测类别和实际类别
model.test(TESTING_FILE, labels);
{
// 保存从文件中读取的测试集
list<vector<double> > testing;
//4.1 读取文件,将数据保存到testing;
readTesting(filename, testing);
// 4.2 根据testing,通过测试得到labels
test(testing, labels );
{
//遍历从testing随机选取的测试样本
for (CTST tst = testing.begin(); tst != testing.end(); ++tst, ++index)
if (indices.find(index) != indices.end())
// 在循环中,调用test函数完成测试结构,形成pair<预测类别,实际类别>,添加到labels
labels.push_back(test(index, *tst));
{
// 1 根据欧几里得公式寻找最近聚类
// 2 如果所属的聚类有子模型,继续在子模型中找最近聚类(递归)
// 3 统计在所属的子模型中类别的数值 map<double,double>,第一个double是类别,第二个double该类别的样本数
// 4 把样本数最多的类别作为测试数据的预测类别,从样本本身可以得到实际类别。
// 5 最终可以得到pair<预测类别, 实际类别>,多个样本就会形成vector<pair<double, double> >。这就是测试结果
}
}
}
// 5 得到混淆矩阵vector<vector<size_t> >
vector<vector<size_t> > cm = KMeans::confusionMatrix(labels);
// 6 根据混淆矩阵,得到分类报告(查准率,召回率和f1得分)
vector<vector<double> > cr = KMeans::classificationReport(cm);
}
Unit11

什么是防火墙




Netfilter


IPTables


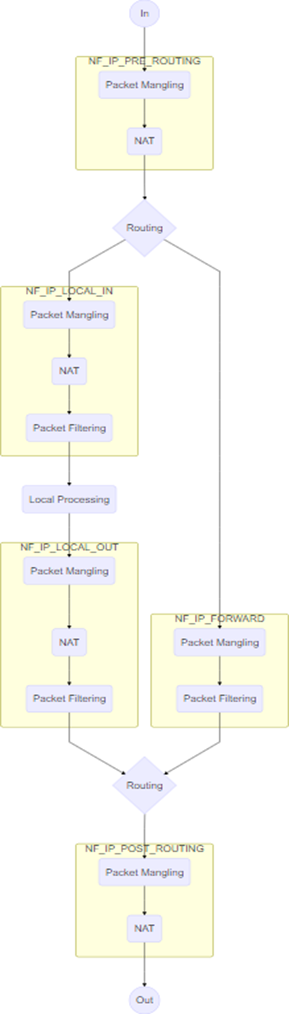

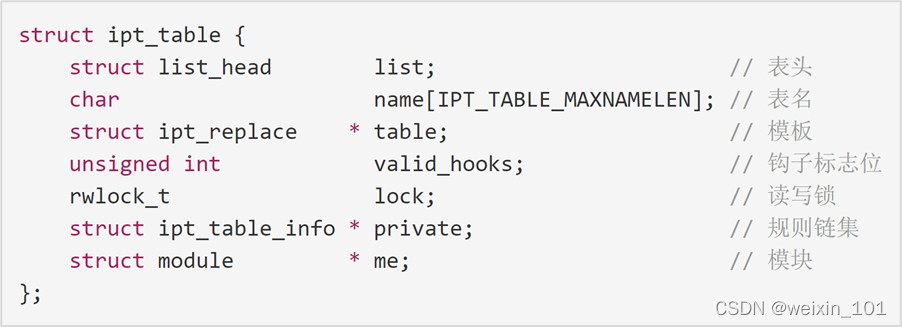
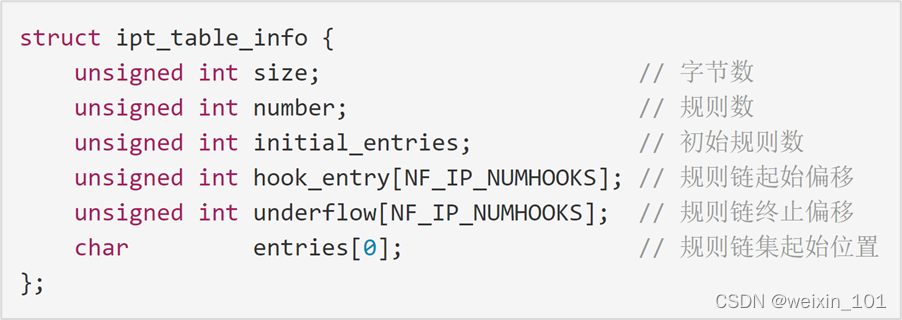
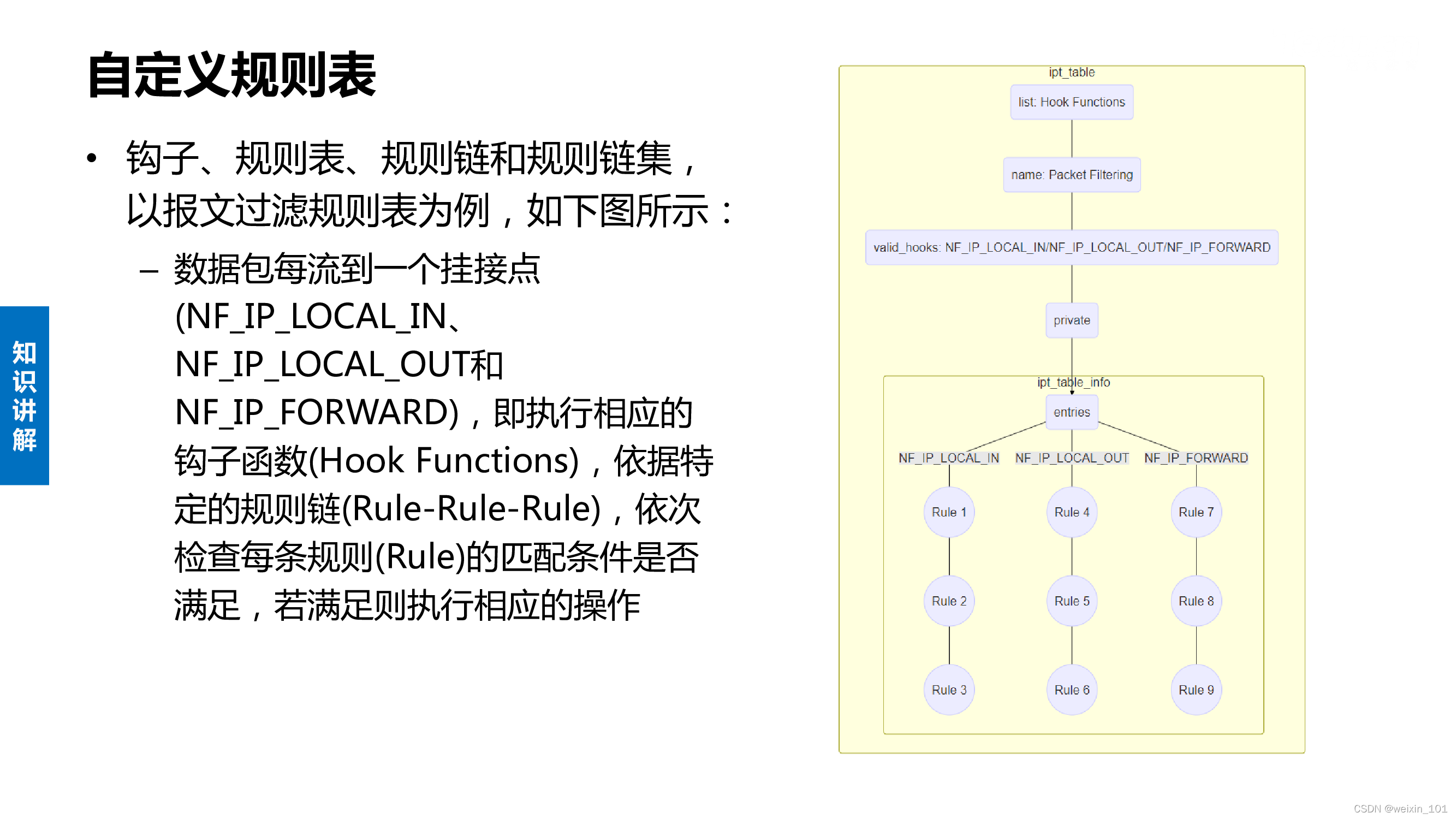
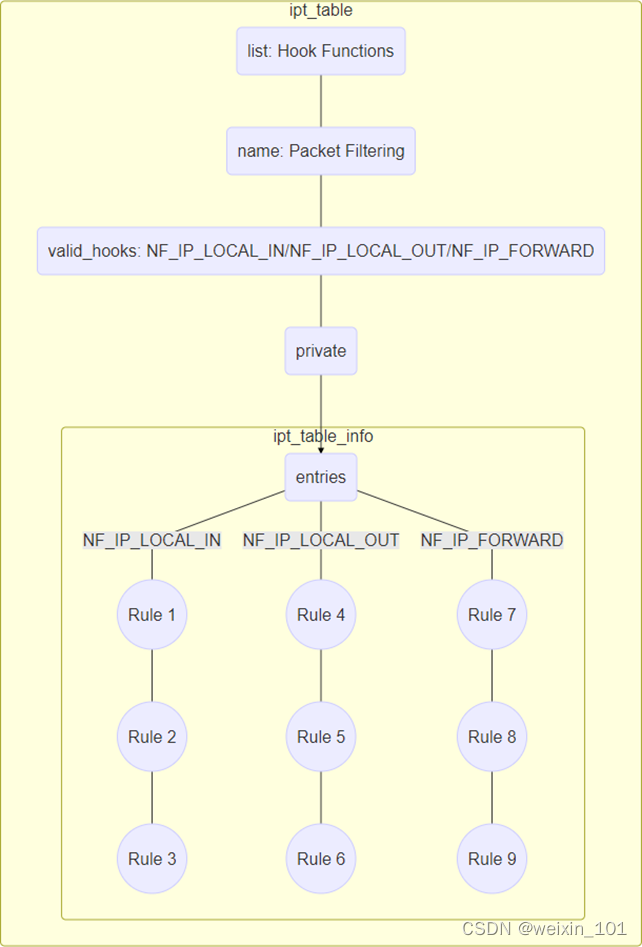

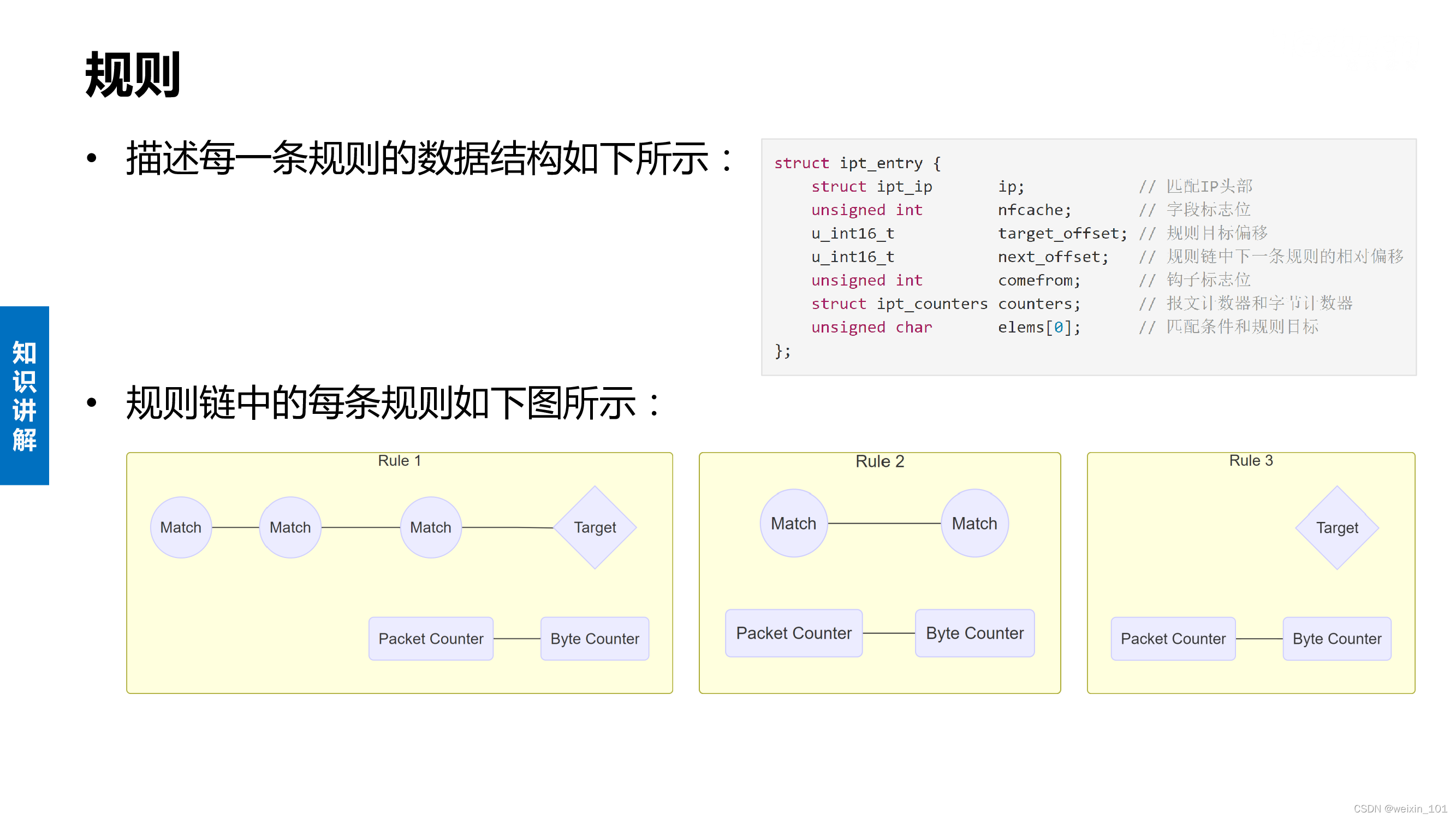

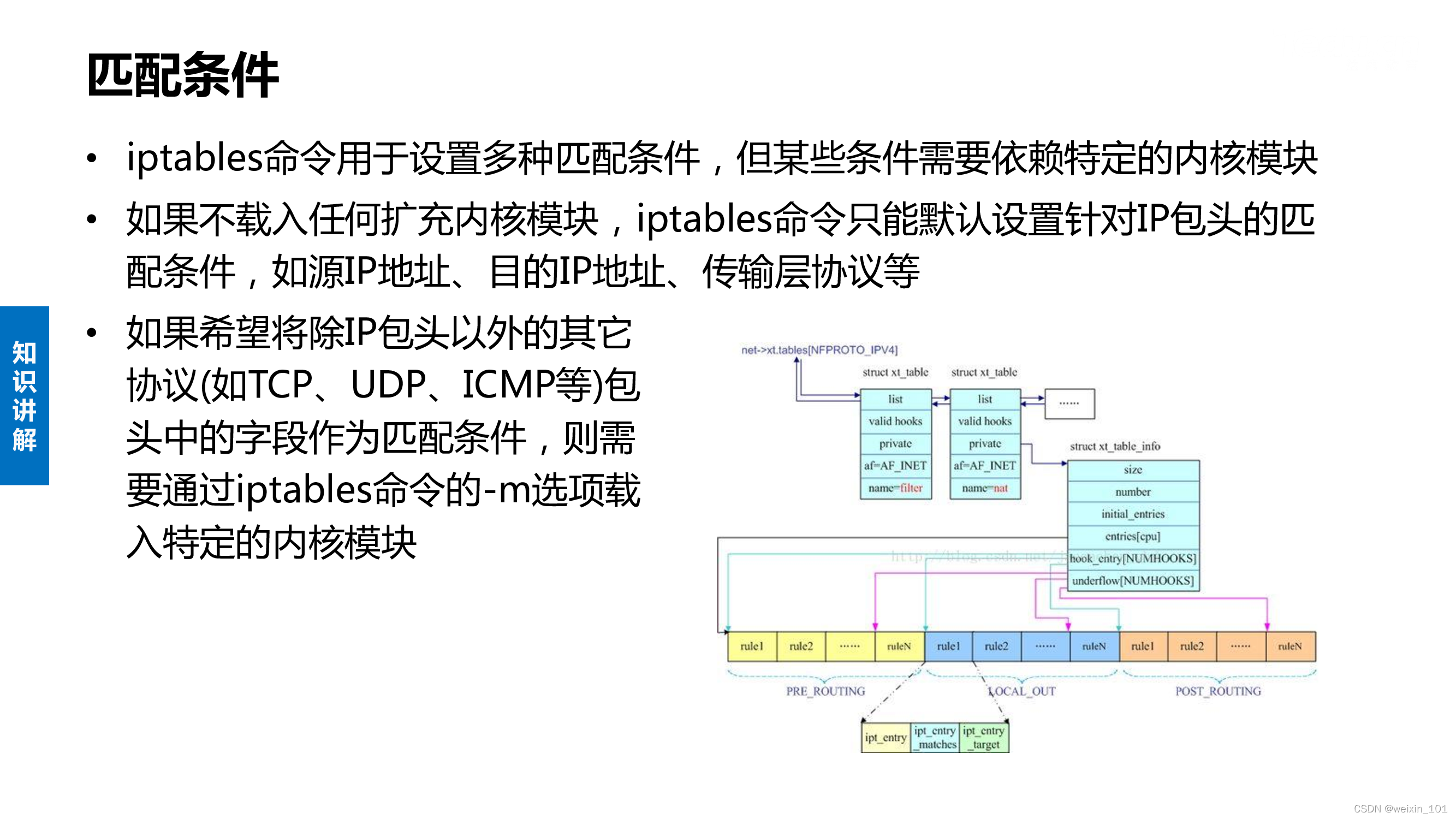
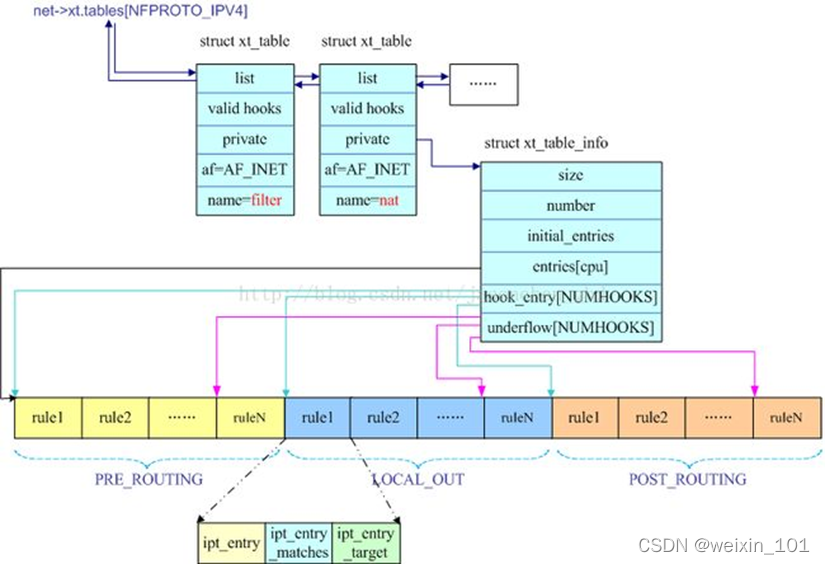

Netfilter内核扩展







实训案例



Unit12

拒绝服务攻击







僵尸网络


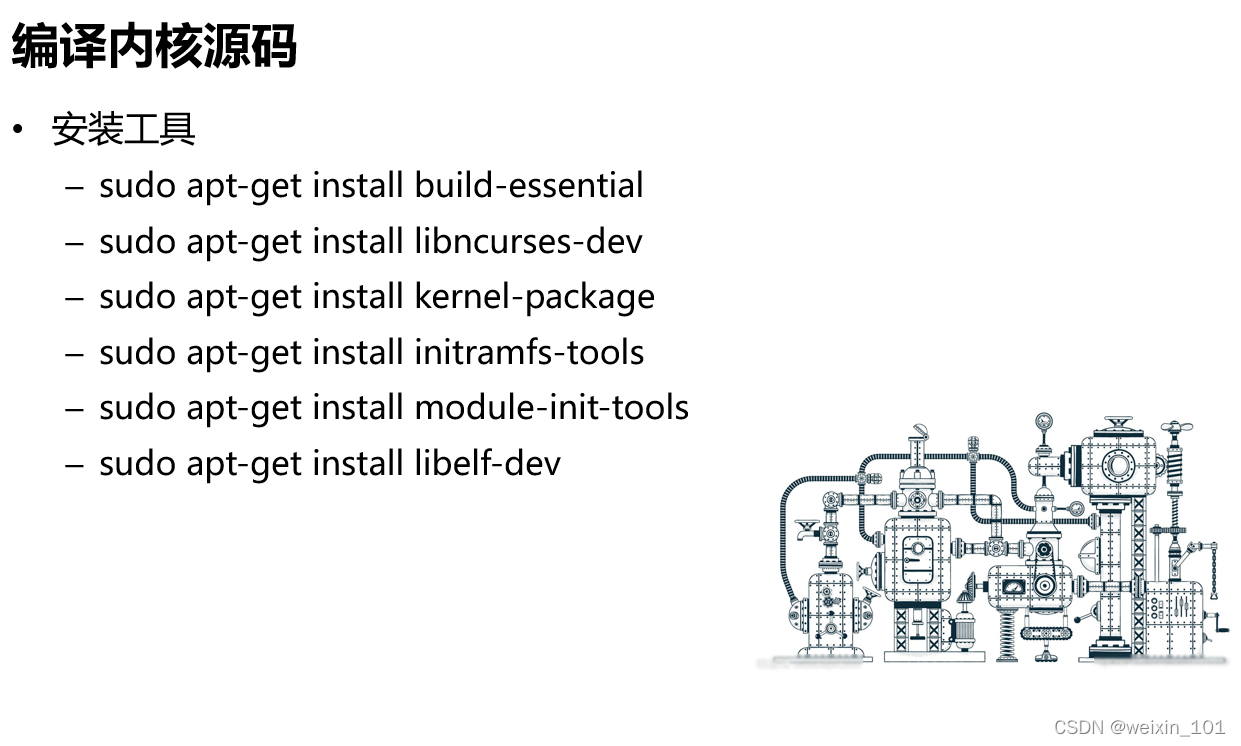
内核强化




















实训案例




















 3760
3760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









