







 博客介绍了场景识别方法,先收集图片计算特征存于数据库,查询时以特征距离查找。还阐述了VLAD特征计算方法及NetVlad对其的改进,包括网络结构和训练过程,使用谷歌街景数据集训练,在匹兹堡和东京数据集测试。
博客介绍了场景识别方法,先收集图片计算特征存于数据库,查询时以特征距离查找。还阐述了VLAD特征计算方法及NetVlad对其的改进,包括网络结构和训练过程,使用谷歌街景数据集训练,在匹兹堡和东京数据集测试。
@InProceedings{Arandjelovic16,
author = “Arandjelovi’c, R. and Gronat, P. and Torii, A. and Pajdla, T. and Sivic, J.”,
title = “{NetVLAD}: {CNN} architecture for weakly supervised place recognition”,
booktitle = “IEEE Conference on Computer Vision and Pattern Recognition”,
year = “2016”,
}
场景识别
-
预先收集大量图片;
-
人工计算出每张图片的feature(例如SIFT),保存到数据库中;
-
输入一张查询图片,使用相同的feature计算方法,得出查询图片的feature后,以feature之间的距离作为查询条件,到数据库中查询feature最接近的图片,作为查询结果。
VLAD
Vector of Locally Aggregated Descriptors,一种feature的计算方法。NetVlad可以看作是采用了深度学习的方法对VLAD进行的改进。
-
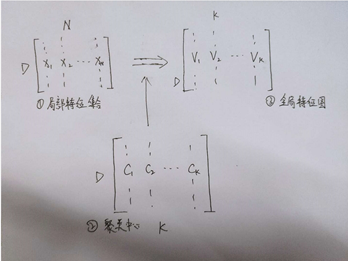
对于一张图片,先得出N个D维的局部特征。N*D
-
对所有的ND特征图进行K-means聚类,获得K个聚类中心。KD
-
通过下述公式将图片的特征图转为全局特征图。K*D
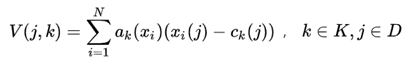
x i x_ixi表示第i个局部特征,c k c_kck示第k个聚类中心,都是D维的向量。
a k ( x i ) = { 0 , x i 不 属 于 c k 1 , x i 不 属 于 c k a_k(x_i)=
{0,xi不属于ck1,xi不属于ck{0,xi不属于ck1,xi不属于ck
ak(xi)={0,xi不属于ck1,xi不属于ck
以矩阵3的第一列为例,其实就是矩阵1的每一列去减矩阵2中的第一列乘上a k ( x i ) a_k(x_i)ak(xi)后再求和。这样做的好处:(1)这K个全局特征表达了聚类范围内局部特征的某种分布,这种分布通过x i − c k x_i-c_kxi−ck抹去了图像本身的特征分布差异,只保留了局部特征与聚类中心的分布差异。(2)将一个若干局部特征压缩为特定大小全局特征的方法。把原来大小不一样的矩阵1变成了大小一致的矩阵3。
NetVlad
因为a k ( x i ) a_k(x_i)ak(xi)只能取1或者0,因此Vlad函数是不可导的,NetVlad将a k ( x i ) a_k(x_i)ak(xi)参考softmax,重新设计了a k ( x i ) a_k(x_i)ak(xi),将其平滑为一个0到1之间的权重函数,x i x_ixi与c k c_kck越近,a k ( x i ) a_k(x_i)ak(xi)越接近1,反之越接近0。
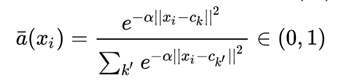
α是一个大于0的参数,将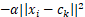 展开,约去
展开,约去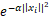 得
得
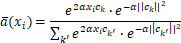
令w k = 2 α c k w_k=2\alpha c_kwk=2αck , b k = − α ∣ ∣ c k ∣ ∣ 2 b_k=-\alpha ||c_k||^2bk=−α∣∣ck∣∣2
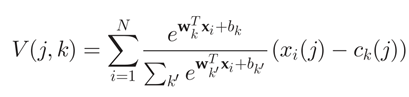
w k , b k , c k w_k,b_k,c_kwk,bk,ck由网络训练得到。
网络结构
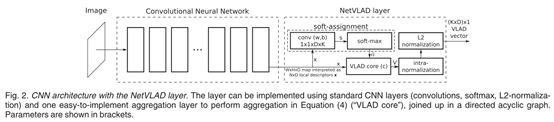
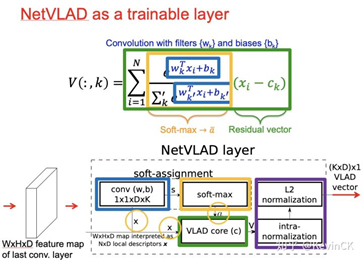
-
从N ∗ D N*DN∗D到K ∗ D K*DK∗D的转化公式
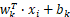 是通过1*1卷积实现(蓝色部分);
是通过1*1卷积实现(蓝色部分); -
黄色部分是softmax公式,通过softmax函数实现;
-
绿色部分是局部特征与聚类中心的残差分布,通过VLAD core来实现。
-
紫色部分是两步归一化操作:
intra-normalization:是将每个中心点k的特征分别做归一化,通过此操作抹去了聚类中残差的绝对大小,只保留了残差的分布。
L2 normalization:将得到的K*D数据再整体做一次归一化处理。
训练
使用谷歌街景数据集训练,一个全景相机对着某个地方拍了很久。数据集有相机的GPS信息,但是由于是全景相机,所以即使GPS相同,可能拍摄的方向并不相同。
训练数据集预处理:对于每一张图片制作正样本和负样本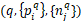 ,正样本
,正样本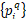 是GPS和查询图像q相近的,其中至少包含一张能与q匹配的图片;负样本
是GPS和查询图像q相近的,其中至少包含一张能与q匹配的图片;负样本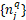 是GPS远离q的,一定不能与q匹配的。因为负样本数量远大于正样本,所以负样本采用“难例挖掘”策略生成。
是GPS远离q的,一定不能与q匹配的。因为负样本数量远大于正样本,所以负样本采用“难例挖掘”策略生成。
使用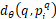 表示查询图片q与[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SoFRUw52-1606286529514)(C:/Users/16492/AppData/Local/Temp/msohtmlclip1/01/clip_image010.png)]的特征图距离
表示查询图片q与[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SoFRUw52-1606286529514)(C:/Users/16492/AppData/Local/Temp/msohtmlclip1/01/clip_image010.png)]的特征图距离
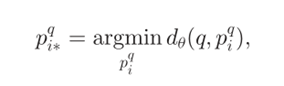
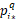 表示被匹配到的图片,其与查询图片q的特征图距离小于所有负样本。
表示被匹配到的图片,其与查询图片q的特征图距离小于所有负样本。
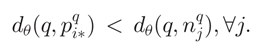
**损失函数:**其中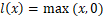 ,m是一个常数(论文里取m=0.1)。如果最佳匹配图片的d+m依旧小于负样本,则取0,反正取计算得到的值。
,m是一个常数(论文里取m=0.1)。如果最佳匹配图片的d+m依旧小于负样本,则取0,反正取计算得到的值。
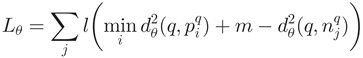
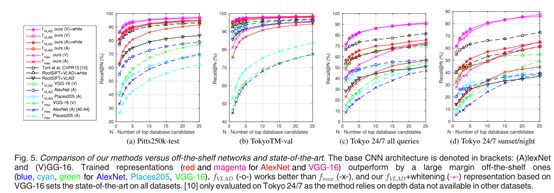
实验:匹兹堡和东京数据集上测试。
纵坐标表示recall
横坐标:前N个里面有一个d<=25米,就认为已经成功位置识别。The query image is deemed correctly localized if at least one of the top N retrieved database images is within d=25 meters from the ground truth position of the query.
top N retrieved database images is within d=25 meters from the ground truth position of the query.

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









