







 本文概述了图表示学习的深度结构导向方法,重点介绍了高阶邻近度保全网络嵌入和全局结构保全网络嵌入。讨论了深度递归网络嵌入(DRNE)模型,该模型利用LSTM保持网络的全局结构,通过邻居节点的嵌入聚合来学习节点的表示。
本文概述了图表示学习的深度结构导向方法,重点介绍了高阶邻近度保全网络嵌入和全局结构保全网络嵌入。讨论了深度递归网络嵌入(DRNE)模型,该模型利用LSTM保持网络的全局结构,通过邻居节点的嵌入聚合来学习节点的表示。
文献题目:Deep Learning for Learning Graph Representations
文献来源:清华大学 朱文武
文献原文:https://arxiv.org/abs/2001.00293v1
Abstract
图表示学习将拓扑图映射到低维向量空间,同时保持原始图结构并支持图推理。
本文中,将介绍一些图表示的基本思想及代表性模型。
Introduction
对于图表示学习的文献有两个名称:图表示和网络嵌入,其实图(Graph)和网络(Network)均指相同类型的结构,本文中对此不作区分。
传统的图表示方法直接基于其拓扑结构,存在稀疏性、高计算复杂性等问题。这促使了基于机器学习表示方法的出现,除了图的拓扑结构以外,此类方法还尝试捕获额外信息的潜在表示。
图表示学习面临以下挑战:
- High non-linearity: 网络具有高度非线性结构
- Structure-preserving: 为支持图的分析应用,嵌入表示需要保留图的结构
- Property-preserving: 现实中的图具有不确定性和动态性
- Sparsity: 现实中的图都比较稀疏,无法提供足够的链路信息
传统的网络嵌入方法很难再高度非线性结构中取得好的效果,深度学习在处理非线性结构中的成功促使对基于深度学习表示方法的大量尝试,本文将图表示方法分为两类:面向结构的深层方法和面向属性的深层方法。具体来说:
面向结构的深层方法
- 结构性深层网络嵌入(Structural Deep Network Embedding,SDNE):重点是保持高阶邻近度
- 深度递归网络嵌入(Deep Recursive Network Embedding,DRNE):重点是保持全局结构
- 深度超网络嵌入(Deep Hyper-network Embedding,DHNE):重点是保持超结构
面向属性的深层方法
- 深度变异性网络嵌入(Deep Variational Network Embedding,DVNE):重点是不确定性
- 基于深度转换高阶拉普拉斯高斯过程的网络嵌入(Deeply Transformed High-order Laplacian Gaussian Process,DepthLGP)重点是动态属性
Deep Structure-oriented Methods
1、High Order Proximity Preserving Network Embedding
2、Global Structure Preserving Network Embedding
保留全局结构的嵌入网络
网络嵌入的一个基本问题是如何在嵌入空间中保持顶点相似性,即如果两个顶点在原始网络中具有相似的局部结构,则它们应具有相似的嵌入向量。
为了量化节点相似性,引入
- 结构等效(Structural Equivalence):当两个节点共享了大量的邻居网络时称其结构等效
- 规则等效(Regular Equivalence):当两个节点具有相似的邻居网络时被称为规则等效的顶点对
规则对等可以看作宽泛的结构对等,且具有更好的灵活性。
--- 例如 ---
两位母亲,她们均与孩子和父亲有关联
“结构等效”规则下,两位母亲被判定为不同节点
“规则等效”规则下,两位母亲被判定为相似节点
------
受到规则等效定义的递归性质启发,《Deep recursive network embedding with regular equivalence》一文中,提出了以递归的方式学习网络嵌入,即一个节点的嵌入可以通过邻居的嵌入聚合而成。
--- 例如 ---
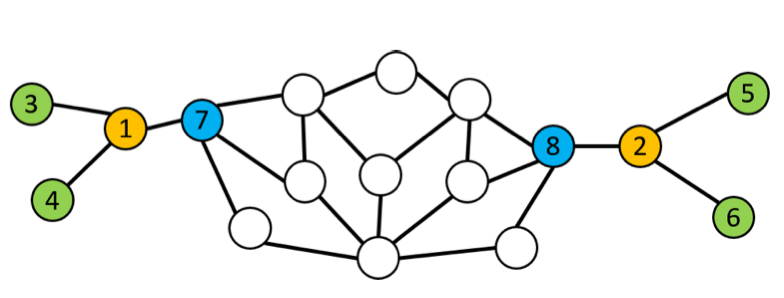
节点7-8、4-6、3-5分别规则等效,因此具有相似的向量嵌入
则节点1-2也将具有相似的向量嵌入,从而规则相等
------
正是这种想法激发了深度递归网络嵌入(DRNE)模型的设计,将节点的邻居转换为有序序列,并提出了层标准化的 LSTM,以非线性方式将邻居的嵌入聚合到目标节点的嵌入中。
2.1 相关定义
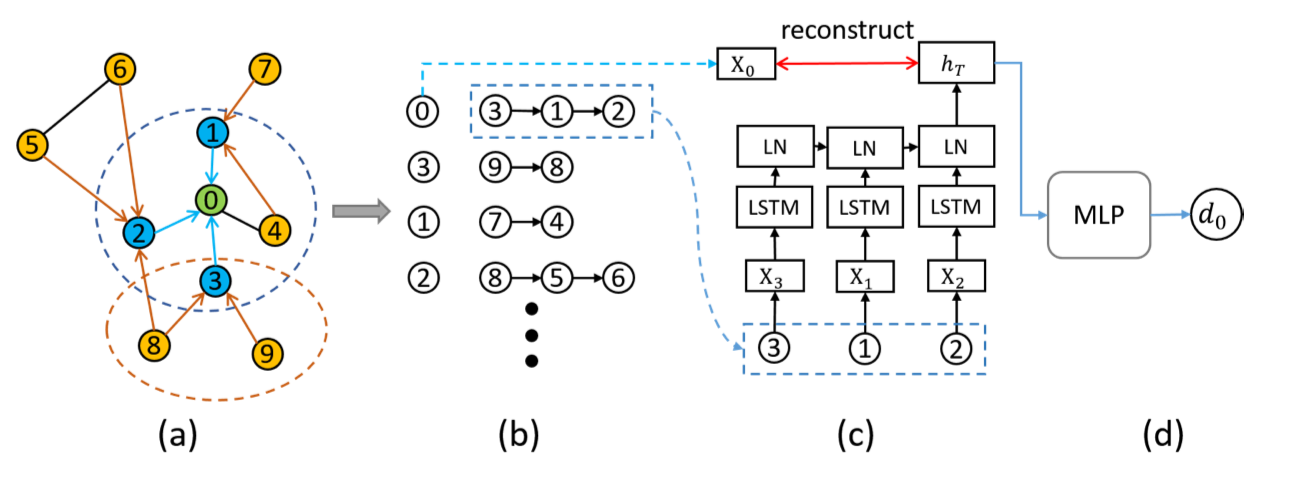
上图是深度递归网络嵌入(DRNE)的模型结构图,其中:
- (a)邻居节点采样;
- (b)按度(degree)对邻居进行排序;
- (c)归一化 LSTM 层,将邻居节点的嵌入聚合到目标节点的嵌入中, X i X_i Xi 是节点 i i i 的嵌入,LN 表示层归一化;
- (d)正则弱化器
--- 例如 ---
(a)以节点0为例,从领域中采样三个节点:1,2,3
(b)按度对三个节点排序:3,1,2
(c)使用领域序列的嵌入 X 3 , X 1 , X 2 X_3, X_1, X_2 X3,X1,X2 作为输入,通过归一化的LSTM层对其进行聚合,以得到聚合表示 h T h_T hT,根据聚合表示重建节点0的嵌入 X 0 X_0 X0
(d)同时,用度 d 0 d_0 d0 作为中心衡量的弱监督信息,将 h T h_T hT 输入到多层感知器 MLP 中,以近似得到 d 0 d_0 d0
对网络中的其他节点执行同样的过程。当我们更新 X 3 , X 1 , X 2 X_3, X_1, X_2 X3,X1,X2 时,节点0的嵌入 X 0 X_0 X0 也会随之更新。通过反复的迭代更新过程,那么嵌入的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









