







1,数据集
数据集:中、英文数据集各一份
中文数据集:THUCNews
THUCNews数据子集:https://pan.baidu.com/s/1hugrfRu 密码:qfud
英文数据集:IMDB数据集 Sentiment Analysis
THUCNews 数据集是根据新浪新闻RSS订阅频道2005年-2011年的历史数据筛选过滤生成,包含74万新闻文档(2.19GB),均为UTF-8纯文本格式。该数据集使用了取其中的10个分类,每个分类6500条数据,总共65000条数据
数据集共有三个文件,如下
cnews.train.txt 训练集(500010条)
cnews.val.txt 验证集(50010条)
cnews.test.txt测试集(100*10条)
IMDB数据集椒keras内部集成的,初次导入需要下载一下,之后就可以直接使用了。
IMDB数据集包含来自互联网的50000条严重分化的评论,该数据集被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价,
2,IMDB数据集下载和探索
参考TensorFlow官方教程:影评文本分类 | TensorFlow
``
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
输入结果是2.0.0-alpha0
下载数据
``
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
将整数转换为回字词
``
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
``
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
使用pad_sequence函数将长度标准化,post的值可以是pre或者post,pre是在序列的起始补,post是在结尾补。
``
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
model = keras.Sequential()
# 顺序模型,可以理解为堆叠
model.add(keras.layers.Embedding(vocab_size, 16))
# 嵌入层,将正证书的下标转换为具有固定大小的向量,
model.add(keras.layers.GlobalAveragePooling1D())
# 全局平均池化层
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
# 激活函数是relu
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
# 激活函数sigmod
model.summary()
# 打印出模型的基本情况
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])
# 配置模型,优化器是adam,损失函数是交叉熵损失函数
# 创建验证集
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
# 训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 评估模型,损失函数是交叉熵损失函数
results = model.evaluate(test_data, test_labels)
print(results)
# 创建准确率和损失的变化趋势
history_dict = history.history
history_dict.keys()
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
3,THUCNews数据集下载和探索
参考博客中的数据集部分和预处理部分:CNN字符级中文文本分类-基于TensorFlow实现 - 一蓑烟雨 - 优快云博客
参考代码:text-classification-cnn-rnn/cnews_loader.py at mas…
4,学习召回率,准确率,ROC曲线,AUC,PR曲线这些基本概念
参考1:机器学习之类别不平衡问题 (2) —— ROC和PR曲线_慕课手记
对于二分类问题而言,分类结果又以下4种:
- TP (true postitve) 真正例,正->正
- FP(false positive) 假正例,反->正
- TN(true negative) 真反例,反-反
- FN(false negative) 假反例,正-反
如何记忆呢,先看P/N,P就是预测为正例,N就是预测为反例,再看T/F,T就是和第二个字母相同,F就是和第二个字母相反
召回率:
recall = TP/(TP+FN) = TP/P,又称查全率
ROC曲线:
2.20
A U C = 1 2 ∑ i = 1 m − 1 ( x i + 1 − x i ) ⋅ ( y i + y i + 1 ) AUC=\cfrac{1}{2}\sum_{i=1}^{m-1}(x_{i+1} - x_i)\cdot(y_i + y_{i+1}) AUC=21i=1∑m−1(xi+1−xi)⋅(yi+yi+1)
[解析]:由于图2.4(b)中给出的ROC曲线为横平竖直的标准折线,所以乍一看这个式子的时候很不理解其中的$ \cfrac{1}{2} 和 和 和 (y_i + y_{i+1}) 代 表 着 什 么 , 因 为 对 于 横 平 竖 直 的 标 准 折 线 用 代表着什么,因为对于横平竖直的标准折线用 代表着什么,因为对于横平竖直的标准折线用 AUC=\sum_{i=1}^{m-1}(x_{i+1} - x_i) \cdot y_i 就 可 以 求 出 A U C 了 , 但 是 图 2.4 ( b ) 中 的 R O C 曲 线 只 是 个 特 例 罢 了 , 因 为 此 图 是 所 有 样 例 的 预 测 值 均 不 相 同 时 的 情 形 , 也 就 是 说 每 次 分 类 阈 值 变 化 的 时 候 只 会 划 分 新 增 ∗ ∗ 1 个 ∗ ∗ 样 例 为 正 例 , 所 以 下 一 个 点 的 坐 标 为 就可以求出AUC了,但是图2.4(b)中的ROC曲线只是个特例罢了,因为此图是所有样例的预测值均不相同时的情形,也就是说每次分类阈值变化的时候只会划分新增**1个**样例为正例,所以下一个点的坐标为 就可以求出AUC了,但是图2.4(b)中的ROC曲线只是个特例罢了,因为此图是所有样例的预测值均不相同时的情形,也就是说每次分类阈值变化的时候只会划分新增∗∗1个∗∗样例为正例,所以下一个点的坐标为 (x+\cfrac{1}{m^-},y) 或 或 或 (x,y+\cfrac{1}{m^+}) , 然 而 当 模 型 对 某 个 正 样 例 和 某 个 反 样 例 给 出 的 预 测 值 相 同 时 , 便 会 划 分 新 增 ∗ ∗ 两 个 ∗ ∗ 样 例 为 正 例 , 于 是 其 中 一 个 分 类 正 确 一 个 分 类 错 误 , 那 么 下 一 个 点 的 坐 标 为 ,然而当模型对某个正样例和某个反样例给出的预测值相同时,便会划分新增**两个**样例为正例,于是其中一个分类正确一个分类错误,那么下一个点的坐标为 ,然而当模型对某个正样例和某个反样例给出的预测值相同时,便会划分新增∗∗两个∗∗样例为正例,于是其中一个分类正确一个分类错误,那么下一个点的坐标为 (x+\cfrac{1}{m-},y+\cfrac{1}{m+}) KaTeX parse error: Expected 'EOF', got '\*' at position 156: …方案,也即 **(上底+下底)\̲*̲高\* \cfrac{1}{2} $**
2.21
l r a n k = 1 m + m − ∑ x + ∈ D + ∑ x − ∈ D − ( I ( f ( x + ) < f ( x − ) ) + 1 2 I ( f ( x + ) = f ( x − ) ) ) l_{rank}=\cfrac{1}{m^+m^-}\sum_{x^+ \in D^+}\sum_{x^- \in D^-}(\mathbb{I}(f(x^+)<f(x^-))+\cfrac{1}{2}\mathbb{I}(f(x^+)=f(x^-))) lrank=m+m−1x+∈D+∑x−∈D−∑(I(f(x+)<f(x−))+21I(f(x+)=f(x−)))
[解析]:
首先,重新对AUC图进行一下解释,AUC的X轴是TPR,Y轴是FPR,这里对TPR和FPR重新进行一下说明,以加深理解,同时点名AUC的变化趋势。
TPR:真正例率,True Positive Rate
T
P
R
=
T
P
T
P
+
F
N
=
正
→
正
正
→
正
+
正
→
反
=
正
→
正
所
有
正
例
的
数
量
=
正
→
正
m
+
TPR = \frac {TP}{TP+FN} = \frac{正\rightarrow正}{正\rightarrow正+正\rightarrow反}=\frac{正\rightarrow正}{所有正例的数量} = \frac {正\rightarrow正}{m^{+}}
TPR=TP+FNTP=正→正+正→反正→正=所有正例的数量正→正=m+正→正
FPR:假正例率,False Positive Rate
F
P
R
=
F
P
T
N
+
F
P
=
反
→
正
反
→
反
+
反
→
正
=
反
→
正
所
有
反
例
的
数
量
=
反
→
正
m
−
FPR =\frac{FP}{TN+FP}= \frac{反\rightarrow正}{反\rightarrow反+反\rightarrow正}=\frac{反\rightarrow正}{所有反例的数量}=\frac{反\rightarrow正}{m^{-}}
FPR=TN+FPFP=反→反+反→正反→正=所有反例的数量反→正=m−反→正
按照书上所示,在刚开始的时候,分类阈值设置到最大,这个时候,反例会被为反例,FPR=0,正例会被判为反例,TPR=0,之后降低分类阈值,正例被判为正例的数量越来越多,反例被判为正例的也越来越多,直至最后,分类阈值被降为最低的时候,正例和反例都会被判为正例。TPR和FPR都为1。此外,
m
+
m^{+}
m+代表样例中正例的数量,是定值。
m
−
m^{-}
m−代表样例中负例的数量,是定值。
此公式正如书上所说,$ l_{rank} $为ROC曲线之上的面积,假设某ROC曲线如下图所示:
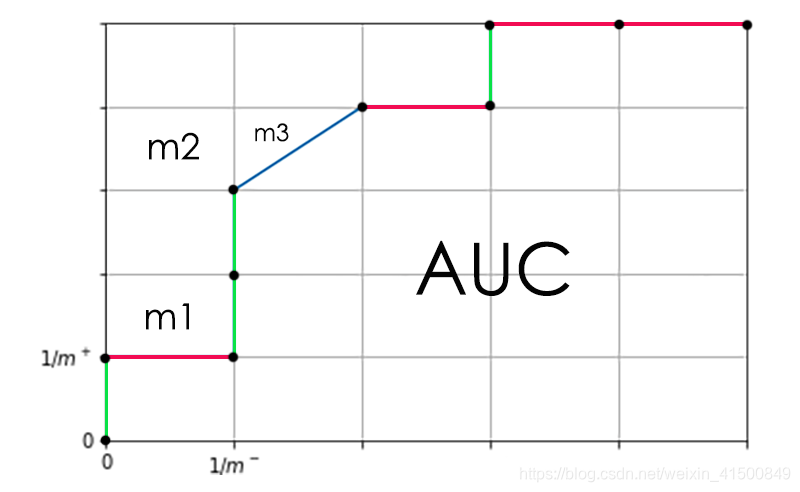
上图的要点如下:
- Y轴向上变化,就是正例预测为正例,
- X轴向右变化,就是反例预测为正例。
- 计算的是曲线与Y轴的面积。
观察ROC曲线易知:
- 每增加一条绿色线段对应着有1个正样例($ x^+_i ) 被 模 型 正 确 判 别 为 正 例 , 且 该 线 段 在 Y 轴 的 投 影 长 度 恒 为 )被模型正确判别为正例,且该线段在Y轴的投影长度恒为 )被模型正确判别为正例,且该线段在Y轴的投影长度恒为 \cfrac{1}{m^+} $;
- 每增加一条红色线段对应着有1个反样例($ x^-_i ) 被 模 型 错 误 判 别 为 正 例 , 且 该 线 段 在 X 轴 的 投 影 长 度 恒 为 )被模型错误判别为正例,且该线段在X轴的投影长度恒为 )被模型错误判别为正例,且该线段在X轴的投影长度恒为 \cfrac{1}{m^-} $;
- 每增加一条蓝色线段对应着有a个正样例和b个反样例同时被判别为正例,且该线段在X轴上的投影长度=$ b * \cfrac{1}{m^-} , 在 Y 轴 上 的 投 影 长 度 = ,在Y轴上的投影长度= ,在Y轴上的投影长度= a * \cfrac{1}{m^+} $;
- 任何一条线段所对应的样例的预测值一定小于其左边和下边的线段所对应的样例的预测值,这个地方可以根据分类阈值的变化规律去理解,左下的部分(即在开始的时候),分类阈值较大,现在(任何一条线段对应的时刻)分类阈值较小,而TPR和FPR是和分类阈值息息相关的,举个生活中的例子,A在及格线是90 的时候就及格了,而B在及格线未60的时候才及格,则B的成绩肯定小于A的。在这里,就是线段对应的样例的预测值一定小于其左边和下边的线段所对应的样例的预测值。其中蓝色线段所对应的a+b个样例的预测值相等,这个地方是因为从蓝线的左端点到右端点,分类阈值只变化了一次,而根据AUC的绘制过程,将分类阈值一次设定为每个样例的预测值,所以,蓝线对应的a+b个样例的预测值相等。
公式里的$ \sum_{x^+ \in D^+} 可 以 看 成 一 个 遍 历 可以看成一个遍历 可以看成一个遍历 x^+_i $的循环:
for $ x^+_i $ in $ D^+ $:
$ \cfrac{1}{m+}\cdot\cfrac{1}{m-}\cdot\sum_{x^- \in D-}(\mathbb{I}(f(x+_i)<f(x-))+\cfrac{1}{2}\mathbb{I}(f(x+_i)=f(x^-))) $ #记为式S
这里 x i + x_i^{+} xi+的含义是正例中的一个样例,其预测结果只可能有两种 正 → 正 正\rightarrow正 正→正和 正 → 负 正\rightarrow负 正→负,在计算的时候只关心后者,即 正 → 负 正\rightarrow负 正→负,所以每个$ x^+_i 都 对 应 着 一 条 绿 色 或 蓝 色 线 段 , 遍 历 都对应着一条绿色或蓝色线段,遍历 都对应着一条绿色或蓝色线段,遍历 x^+_i $可以看成是在遍历每条绿色和蓝色线段,并用式S来求出每条绿色线段与Y轴构成的面积(例如上图中的m1)或者蓝色线段与Y轴构成的面积(例如上图中的m2+m3)。
对于每条绿色线段: 将其式S展开可得:
1
m
+
⋅
1
m
−
⋅
∑
x
−
∈
D
−
I
(
f
(
x
i
+
)
<
f
(
x
−
)
)
+
1
m
+
⋅
1
m
−
⋅
∑
x
−
∈
D
−
1
2
I
(
f
(
x
i
+
)
=
f
(
x
−
)
)
\cfrac{1}{m^+}\cdot\cfrac{1}{m^-}\cdot\sum_{x^- \in D^-}\mathbb{I}(f(x^+_i)<f(x^-))+\cfrac{1}{m^+}\cdot\cfrac{1}{m^-}\cdot\sum_{x^- \in D^-}\cfrac{1}{2}\mathbb{I}(f(x^+_i)=f(x^-))
m+1⋅m−1⋅x−∈D−∑I(f(xi+)<f(x−))+m+1⋅m−1⋅x−∈D−∑21I(f(xi+)=f(x−))
其中$ x^+i 此 时 恒 为 该 线 段 所 对 应 的 正 样 例 , 是 一 个 定 值 。 此时恒为该线段所对应的正样例,是一个定值。 此时恒为该线段所对应的正样例,是一个定值。 \sum{x^- \in D-}\cfrac{1}{2}\mathbb{I}(f(x+_i)=f(x^-) 是 在 通 过 遍 历 所 有 反 样 例 来 统 计 和 是在通过遍历所有反样例来统计和 是在通过遍历所有反样例来统计和 x^+_i 的 预 测 值 相 等 的 反 样 例 个 数 , 即 的预测值相等的反样例个数,即 的预测值相等的反样例个数,即x^{-}\in D^{-}$是遍历所有的负例, $\mathbb{I}(f(x+_i)=f(x-) 的 含 义 是 正 例 的 预 测 值 和 反 例 的 预 测 值 是 相 等 的 。 由 于 没 有 反 样 例 的 预 测 值 和 的含义是正例的预测值和反例的预测值是相等的。由于没有反样例的预测值和 的含义是正例的预测值和反例的预测值是相等的。由于没有反样例的预测值和 x^+i 的 预 测 值 相 等 ( 在 蓝 线 会 存 在 这 种 情 况 , 在 绿 线 不 存 在 ) 。 所 以 的预测值相等(在蓝线会存在这种情况,在绿线不存在)。所以 的预测值相等(在蓝线会存在这种情况,在绿线不存在)。所以 \sum{x^- \in D-}\cfrac{1}{2}\mathbb{I}(f(x+i)=f(x^-)) 此 时 恒 为 0 , 于 是 其 式 S 可 以 化 简 为 : 此时恒为0,于是其式S可以化简为: 此时恒为0,于是其式S可以化简为:$ \cfrac{1}{m+}\cdot\cfrac{1}{m-}\cdot\sum{x^- \in D-}\mathbb{I}(f(x+i)<f(x^-)) $ 其 中 其中 其中 \cfrac{1}{m^+} 为 该 线 段 在 Y 轴 上 的 投 影 长 度 , 为该线段在Y轴上的投影长度, 为该线段在Y轴上的投影长度, \sum{x^- \in D-}\mathbb{I}(f(x+_i)<f(x^-)) 同 理 是 在 通 过 遍 历 所 有 反 样 例 来 统 计 预 测 值 大 于 同理是在通过遍历所有反样例来统计预测值大于 同理是在通过遍历所有反样例来统计预测值大于 x^+_i 的 预 测 值 的 反 样 例 个 数 , 这 个 时 候 , 反 例 会 被 预 测 为 正 例 , 原 因 是 反 例 的 预 测 值 太 高 。 也 即 该 线 段 左 边 和 下 边 的 红 色 线 段 个 数 + 蓝 色 线 段 对 应 的 反 样 例 个 数 ( 只 能 数 左 下 的 , 左 下 的 阈 值 较 大 ) , 所 以 的预测值的反样例个数,这个时候,反例会被预测为正例,原因是反例的预测值太高。也即该线段左边和下边的红色线段个数+蓝色线段对应的反样例个数(只能数左下的,左下的阈值较大),所以 的预测值的反样例个数,这个时候,反例会被预测为正例,原因是反例的预测值太高。也即该线段左边和下边的红色线段个数+蓝色线段对应的反样例个数(只能数左下的,左下的阈值较大),所以 \cfrac{1}{m-}\cdot\sum_{x- \in D-}(\mathbb{I}(f(x+)<f(x^-))) $便是该线段左边和下边的红色线段在X轴的投影长度+蓝色线段在X轴的投影长度,也就是该绿色线段在X轴的投影长度(绿线在X的投影长度为0),观察ROC图像易知绿色线段与Y轴围成的面积=该线段在Y轴的投影长度 * 该线段在X轴的投影长度。
对于每条蓝色线段: 将其式S展开可得:
1
m
+
⋅
1
m
−
⋅
∑
x
−
∈
D
−
I
(
f
(
x
i
+
)
<
f
(
x
−
)
)
+
1
m
+
⋅
1
m
−
⋅
∑
x
−
∈
D
−
1
2
I
(
f
(
x
i
+
)
=
f
(
x
−
)
)
\cfrac{1}{m^+}\cdot\cfrac{1}{m^-}\cdot\sum_{x^- \in D^-}\mathbb{I}(f(x^+_i)<f(x^-))+\cfrac{1}{m^+}\cdot\cfrac{1}{m^-}\cdot\sum_{x^- \in D^-}\cfrac{1}{2}\mathbb{I}(f(x^+_i)=f(x^-))
m+1⋅m−1⋅x−∈D−∑I(f(xi+)<f(x−))+m+1⋅m−1⋅x−∈D−∑21I(f(xi+)=f(x−))
其中前半部分表示的是蓝色线段和Y轴围成的图形里面矩形部分的面积,后半部分表示的便是剩下的三角形的面积,矩形部分的面积公式同绿色线段的面积公式一样很好理解,而三角形部分的面积公式里面的$ \cfrac{1}{m^+}
为
底
边
长
,
为底边长,
为底边长, \cfrac{1}{m-}\cdot\sum_{x- \in D-}\mathbb{I}(f(x+_i)=f(x^-)) $为高。
综上分析可知,式S既可以用来求绿色线段与Y轴构成的面积也能求蓝色线段与Y轴构成的面积,所以遍历完所有绿色和蓝色线段并将其与Y轴构成的面积累加起来即得$ l_{rank} $。
脚注:ROC曲线
roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity),纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)。
参考:
ROC和AUC介绍以及如何计算AUC
ROC曲线-阈值评价标准
PR线:
以查准率为纵轴,查全率为横轴,即可得到查准率-查全率曲线,简称P-R曲线。
如果一个学习器的P-R曲线被另外一个学习器的曲线完全包围,则可断言后者的性能优于前者,如果曲线相交,则比较PR曲线的面积,平衡点是查全率=差准率的点,这也是比较学习器性能的一种方式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









