



 本文深入解析了线性回归的基本公式与代价函数的概念,通过梯度下降法寻找最佳参数θ0和θ1,以实现代价函数的最小化。介绍了梯度下降法的工作原理及其在参数更新过程中的应用。
本文深入解析了线性回归的基本公式与代价函数的概念,通过梯度下降法寻找最佳参数θ0和θ1,以实现代价函数的最小化。介绍了梯度下降法的工作原理及其在参数更新过程中的应用。
本文参考吴恩达机器学习课程第2章
线性回归公式:
f(x)=θ0+θ1xf(x)=\theta_0 + \theta_1xf(x)=θ0+θ1x
代价公式(误差均值中的2用来抵消求导得来的2):
J(θ0,θ1)=12m∑i=1m(fθ(x)i−yi)2J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^m(f_{\theta}(x)^i - y^i)^2J(θ0,θ1)=2m1∑i=1m(fθ(x)i−yi)2
目标:代价最小化
这里演示单变量线性回归时:
令θ0=0\theta_0=0θ0=0, f(x)=θ1xf(x)=\theta_1xf(x)=θ1x
可对J(θ1)J(\theta_1)J(θ1)求导,
J′(θ1)=1m∑i=1m(θ1xi−yi)J^{'}(\theta_1)=\frac{1}{m}\sum_{i=1}^m(\theta_1x^i - y^i)J′(θ1)=m1∑i=1m(θ1xi−yi)
此时J′(θ1)=0J^{'}(\theta_1)=0J′(θ1)=0方可求出θ1\theta_1θ1
实际上,由于代价函数经常含有2个及以上参数,目前函数处于三维空间x, y, z分别为θ0,θ1,J(θ0,θ1)\theta_0,\theta_1,J(\theta_0,\theta_1)θ0,θ1,J(θ0,θ1),无法直接求导获得最佳参数组合
所以我们实际上,是不断尝试θ0,θ1\theta_0,\theta_1θ0,θ1不同的值,找到损失结果最小的那组(θ0,θ1)(\theta_0,\theta_1)(θ0,θ1)。
我们如何找到合适的尝试方法来找到这组参数呢,目前使用
梯度下降法
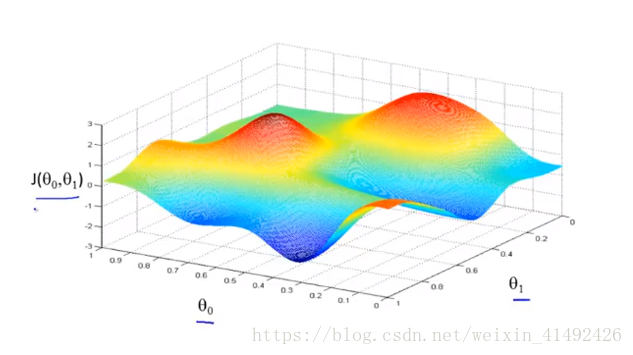
算法特点:从不同的起始值开始,获得的局部最优解是不一样
为了方便,设 θ0=0,θ1=0\theta_0=0,\theta_1=0θ0=0,θ1=0
α\alphaα为学习率(不变),ddθiJ(θi)\frac{d}{d\theta_i}J(\theta_i)dθidJ(θi)为偏导数,参数更新公式:
θi:=θi−αddθiJ(θ0,θ1)\theta_i:= \theta_i - \alpha\frac{d}{d\theta_i}J(\theta_0,\theta_1)θi:=θi−αdθidJ(θ0,θ1)(i=0,1i=0,1i=0,1)
具体展开:
θ0:=θ0−αddθ0J(θ0,θ1)=θ0−1m∑i=1m(θ0+θ1xi−yi)\theta_0:=\theta_0-\alpha\frac{d}{d\theta_0}J(\theta_0,\theta_1)=\theta_0-\frac{1}{m}\sum_{i=1}^m(\theta_0 + \theta_1x^i-y^i)θ0:=θ0−αdθ0dJ(θ0,θ1)=θ0−m1∑i=1m(θ0+θ1xi−yi)
θ1:=θ1−αddθ1J(θ0,θ1)=θ0−1m∑i=1m(θ0+θ1xi−yi)∗xi\theta_1:=\theta_1-\alpha\frac{d}{d\theta_1}J(\theta_0,\theta_1)=\theta_0-\frac{1}{m}\sum_{i=1}^m(\theta_0 + \theta_1x^i-y^i)*x^iθ1:=θ1−αdθ1dJ(θ0,θ1)=θ0−m1∑i=1m(θ0+θ1xi−yi)∗xi
- 导数项: 达到局部最优解时(图中某一处局部最低点时),此时导数项为0,θi:=θi−α∗0\theta_i:= \theta_i - \alpha*0θi:=θi−α∗0,参数不再更新,且随着J(θ)J(\theta)J(θ)接近最低点,导数项也会越来越小,所以暂时学习率可不变。
- 梯度下降可以用于更新任何可微(因为需要求导)的代价函数J,目前使用的梯度下降用到了∑i=1m\sum_{i=1}{m}∑i=1m,意味着每下降一次遍历一整个数据集,也称batch梯度下降算法。

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









