






 本文介绍了ASCII和Unicode编码系统,特别是ASCII在0-255范围内的使用。讨论了Python中的chr和ord函数,以及字符编码在字符串和控制台输出中的应用。还涵盖了Python的基本数据类型,如整数、浮点数、复数和字符串,以及数据类型转换、运算符、逻辑操作和位运算。此外,文章涉及列表、元组、字符串的操作,包括列表推导、序列转换和正则表达式的基础知识。
本文介绍了ASCII和Unicode编码系统,特别是ASCII在0-255范围内的使用。讨论了Python中的chr和ord函数,以及字符编码在字符串和控制台输出中的应用。还涵盖了Python的基本数据类型,如整数、浮点数、复数和字符串,以及数据类型转换、运算符、逻辑操作和位运算。此外,文章涉及列表、元组、字符串的操作,包括列表推导、序列转换和正则表达式的基础知识。
超简版
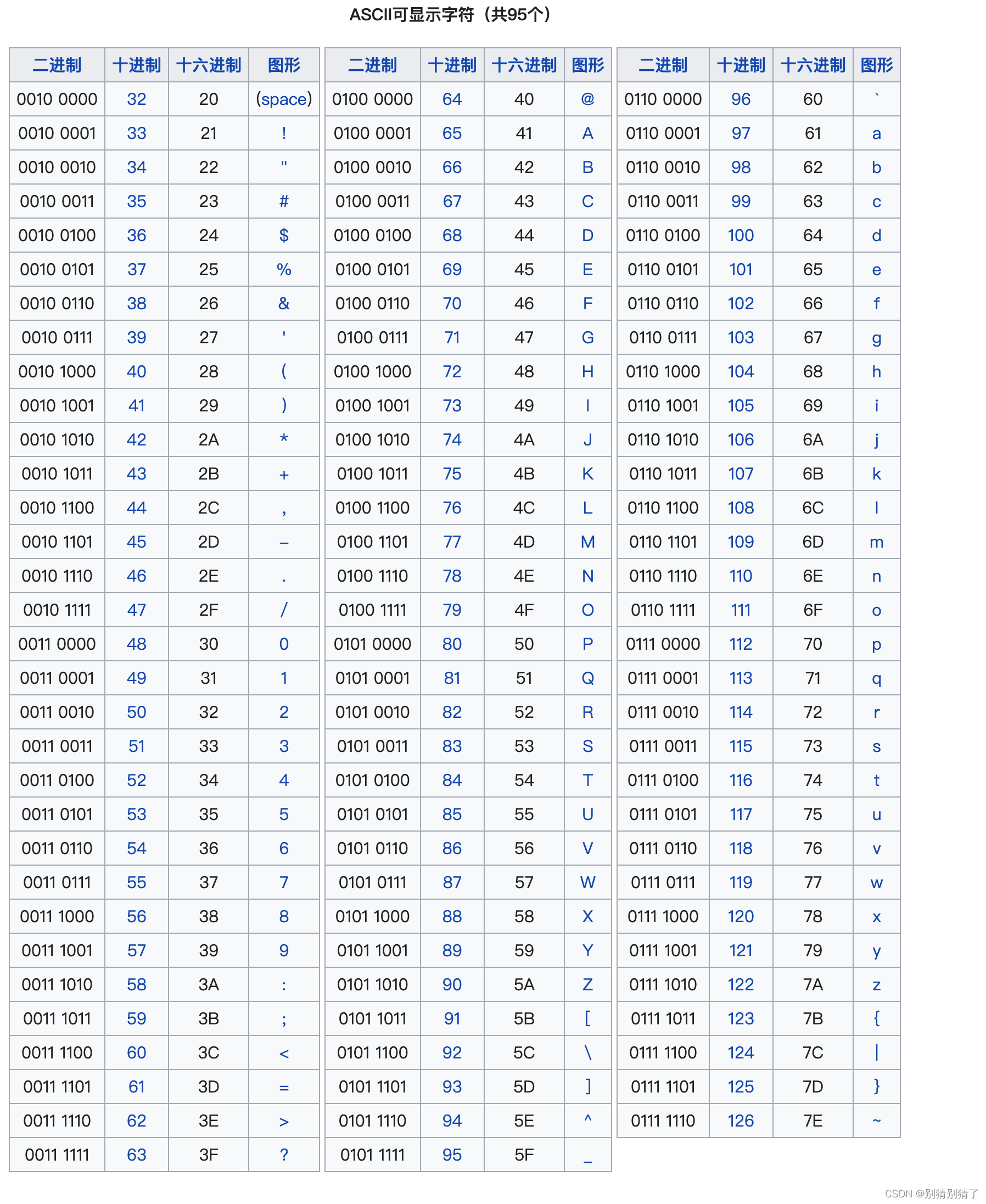
ASCII:American Standard Code for Information Interchange,美国信息交换标准代码,基于拉丁字母的一套电脑编码系统,等同于国际标准ISO/IEC 646。
推荐学习网站:菜鸟编程
各种字符编码可看:字浮集和字符编码
print(chr(66))
chr(i)里面可,ASCII=十进制吗?、ASCII用在0~255的范围内,i可以十进制也可也可16进制,例如:chr(0x31) 控制台:0
Unicode\(#下属的)UTF-8
print("字符串") 函数输出在控制台上
控制台:Pycharm或其他开发工具上
i ="\u4e2d\u56fd"
print(ord(i))
新:chr 括号里 十进制0〰️255,或者是字符串,返回的是ascii,就是d,z什么的
ord 括号里 Ascii值 或Unicode 0〰️255 返回ascii
ascii与ascii码值不一样哦
注释
单行注释 #
多行注释 '''
'''
"""
"""
中文编码声明注释
# coding = utf-8
# -*- coding:utf-8 -*- (-*-只为了美观)
代码缩进
<Tab>
编码规范与命名规范
变量与基本数据类型
关键词
and as assert break class continue def
del elif else except finally for from false
global if import in is lambda nonlocal not none or pass raise return try true
while with yield
包
import keyword
keyword.kwlist
type()数据类型
id()返回内存地址
基本数据类型
整数(十进制、八进制、十六进制、二进制)
浮点数、复数(?)
字符串类型:
转义字符:
\续航浮,\n换行符,\0空,\t(?)
\"双引号,\'单引号,\\反斜杠,\f换页
\\0dd八进制,\xhh十六进制
布尔类型 none与false
数据类型转换
int、float、complex,str,repr,ecal,chr,ord,hex十六进制,oct八进制
运算符
+,-,×,/,%取余数,//取整,**幂
请学习时区分\与/的不同和模糊记忆
赋值运算
x+=y,x=x+y
以此类推
比较运算符
>,<,==,!=不等于,>=,<=
逻辑运算符
and与,or或,not非
位运算符
&位与,|位或,,^位异或,取反~,左移位<<,右移位>>
运算符的优先级
列表
索引,a [ 下标 ],切片 a [ 开始 : 结尾 : 步长 ]
序列 的 相加 和 乘法
长度 len(a),
规定:在一堆数中找最?值
max(a),min(a)
序列与列表的不同
⭐拿到pycharm自己试一试
list(),将序列转为列表
str(),将序列转为字符串
sum(),计算元素和
sorted(),元素进行排序
reversed(),反向序列中的元素
enumerate(),??
创建空列表 list = [ ]
删除del list 或 del list[1]
添加元素在尾部,list.append(obj)
将列表元素全部添加另一个元素extend()
修改元素i[?下标]=?
下标是数字几几几,可以是负数,可以是零
删除del a[2] 或者del a
删除某元素: a.remove(元素)
某元素存在次数: a.count(元素),
获取元素首次的下标 index(元素),控制台为3
sum(列表),的合,求和
对列表进行排序
a.sort()默认升序,a.sort(reverse=True)
sorted 与 sort
三目运算法 90页???
元组
a = ( )
type 类型
range(10,20,2)
删除 del i
import random 导入random标准库
random.randint(10,20)
三目运算符
for i in range(10)
⭐ end=" "
字符串与正则表达式
str( ) 字符串
len ( )长度
爬虫,编码
a.encode("gbk")
一、
str.split 消除两边(sep=默认空字符,也可以其他,maxsplit分割次数)
空字符:...103
二、次数 = count("元素")
下标 = str.find("g")与index差不多
三、布尔值
i的开头是startswith("g")这个吗?
反之结尾endswith呢
四、PASS
lower()把字母大转小
upper反之
五、
str.strip(元素),去除两边
lstrip 左去除 rstrip 右去除
六、%操作符合
像嵌套一样:(内容里%?),百分号,()
内容里百分号是:
("%(可-+0m .n,又可加数字,以及常用格式化字符)")%(填的内容) #把最后%后面填的内容,按照前面%的规则显示出来。
又可:
%s,字符串,采用str显示
%r 字符串,repr(显示)?
%c 单个字符
%o 八制整数
%d或者%i 十进制整数
%e 指数(基底写为e)
%x 十六进制整数
%E 指数(基底写为E)
%f或者%F 浮点数
%% 字符%
%后规则,%分隔,要参与规则的元素
format {}
"{}激昂流派,{}".format("你","我们")
f' "没空格的哈{} "
{ }里面可以有下标数字,以及数字、函数
例子:{:*^}
用法很多,省略
s 对字符串类型格式化
b 将十进制整数自动转换二进制再格式化
o 十转八
x或X 十转十六
例子 {%b}
f 或F 浮点数默认保留6位
d 十进制整数
c 十进制,unicode
e或E 科学计算法再格式化
g或G ?
% 百分比,默认显示小数点后6位
正则表达式基础
行定位符,^am$
^是行的开始,$是行的结尾
.匹配换行符以外的任意字符
\w匹配字母、数字、下划线、汉字
\W匹配除了\w匹配的
\s匹配单个的空白符
\S除\s匹配的都匹配
\d匹配数字
\b匹配单词的开始或结束???
怎么用?匹配哪部分
限定符:
?匹配前面的字符零次或一次
例子:cokiu?r 可cokiur或cokir
➕匹配前面字符一次或多次
例子:gohao+gu 可gohaogu或gohaooogu
*匹配前面的字符串零次或多次
依次类推
{n} 匹配前面的字符
{n,} 匹配前面字符至少n次 go{3}
{n,m} 最少n次,最多m次
字符类:
匹配用[aeiou]就可以了,重点
排除字符:[^a-zA-Z]
选择字符:
转义字符\
分组: 利用|或 * ^
在Python中使用正则表达式
使用re模块实现正则表达式操作
match 控制台输出布尔值
r.match(pattern,string字符串,[flags])
flags为:
一、A或ASCII
对于\w、\W、\b、\B、\d、\D、\s和\S只进行ASCII匹配(仅适用于Python 3.x)
二、I或IGNORECASE
执行不区分字母大小写的匹配
三、M或MULTILINE
将^和$用于包括整个字符串的开始和结尾的每行(默认情况下,仅适用于整个字符串的开始和结尾处)
四、S或DOTALL
使用(.)字符匹配所有字符,包括换行符
五、X或VERBOSE
忽略模式字符串中未转义的空格和注释
例如,匹配字符串是否以“mr”开头
目的:是不是以这个开头,布尔值
01 import re
02 pattern = r'mr_ \W+'
#模式字符串
03 string = 'MR_ SHOP mr_ shop'
#要匹配的字符串
04match = re.match(pattern, string,re.I)
#匹配字符串,不区分大小写
05 print(match)
#输出匹配结果
06 string = ' 项目名称MR_ SHOP mr_ shop'07
match = re.match( pattern, string,re.I)
#匹配字符串,不区分大小写
08print (match)#输出匹配结果
执行结果如下
<_ sre.SRE_ Match object; span=(0, 7), match= 'MR_ SHOP' >
None
出现r'
match.start可接end、span、string、group
search格局跟前面一样的,目的是搜索以mr为开头的字符串。
findall()寻找整个字符串中替换字符串符合正则表达式
替换字符串
re.sub(pattern,repl,string,count,flags)
re.sub成立!
1、正则表达式转换而来
2、替换的字符串
3、被查找替换的原始字符
4、可选参数,最大次数
5、可选参数,标志位、、、
使用正则表达式分割字符串:
re.split(pattern,string,[maxsplit],[flags])
1、可选参数,最大拆分数
第8章
if 选择及判断语句:
1、顺序结构
2、选择结构 (elif) else
!= 不等于
不至于if里面又嵌套if
and两边都得符合
or 两边有一个OK就行
not不是这样的吧
true是对执行,false是错误的
循环结构语句
for i in 列表a:
循环不代表输出 就在控制台
range(开始,末尾,步长)
for可遍历字符串
while 条件符合继续循环,直到不符合为止
break停止跳出 与 continue暂停继续
第10章字典与集合
字典 {键key:值value}
dict()
dict(zip(list1,list2))
变成{list1[0:list2[0,....}
disk.fromkeys 空字典
{a:sign}❓❓❓❓
del 删除,a.clear,
键值对访问字典:
dictionary.get(“”)
遍历字典:
a.items 或
for item in a.item():
10,1,4
dic[key]=value
if "奇" in a
del 防止元素没有出错
import random
random.randint(随机数)
集合
直接{}
set()函数创建
a=set(iteration)
mr.add("我们")添加
删除 remove 156页 pop
交集&,并集|,查集运算-
大大大区别
列表:可变,重复,有序,[]
元组:不可变,可重复,有序,()
字典:可变,可重复,无序,{key:value}
集合:可变,不可重复,无序,{}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









