






对数字求和到给定值
编写一个sumTo(n)计算1 + 2 + ... + n 的和。
举个例子:
sumTo(1) = 1
sumTo(2) = 2 + 1 = 3
sumTo(3) = 3 + 2 + 1 = 6
sumTo(4) = 4 + 3 + 2 + 1 = 10
...
sumTo(100) = 100 + 99 + ... + 2 + 1 = 5050使用三种方式实现:
- 使用循环
- 使用递归,对n > 1 执行sumTo(n) = n + sumTo(n-1)
- 使用等差数列求和公式
使用循环解法:
function sumTo(n) {
let sum = 0
for(let i = 1; i <= n; i++) {
sum += i
}
return sum
}
console.log(sumTo(100))使用递归的解法:
function sumTo(n) {
if(n === 1) return 1
return n + sumTo(n-1)
}
console.log(sumTo(100))使用公式sumTo(n) = n * (n+1) / 2的解法:
function sumTo(n) {
return n * (n+1) / 2;
}
console.log(sumTo(100));讨论:
1. 哪种方式最快?哪种最慢?为什么?
当然是公式解法最快。对于任何数字n, 只需要进行3次运算
循环的速度次之。再循环和递归的方法里,我们对相同的数字求和。但是递归涉及嵌套调用和执行堆栈管理。这也会占用资源,因此递归的速度更慢一些
2. 我们可以使用递归来计算sumTo(100000)吗?
一些引擎支持“尾调用“(tail call)”优化:如果递归调用的是函数中最后一个调用(例如上面的sumTo),那么外部的函数就不再需要恢复执行,因此引擎也就不再需要记住他的执行上下文。这样就减轻了内存的负担,因此计算sumTo(100000)就变得可能。但是如果你的JavaScript引擎不支持尾调用那就会报错:超出最大堆栈深度,因为通常总堆栈的大小是由限制的。
计算阶乘
自然数的阶乘是指,一个数乘以数字减去1,然后乘以数字减去2,以此类推直到乘以1.n 的阶乘被记作 n!。
我们可以将阶乘的定义写成这样:
n! = n * (n-1) * (n-2) * ... * 1不同n的阶乘值:
1! = 1
2! = 2 * 1 = 2
3! = 3 * 2 * 1 = 6
4! = 4 * 3 * 2 * 1 = 24
5! = 5 * 4 * 3 * 2 * 1 = 120根据定义:阶乘 n! 可以写成n * (n-1)!
编写函数factorial(n)使用递归计算n!。由定义我们可以将factorial(n)的结果写成 n * factorial(n-1)的结果来获得。对n-1的调用同理可以依次地递减,直到1。
function factorial(n) {
return (n !== 1) ? n * factorial(n-1) : 1
}
console.log(factorial(5)) //120递归的基础是数值 1。我们也可以用 0 作为基础,不影响,除了会多一次递归步骤:
function factorial(n) {
return n ? n * factorial(n - 1) : 1;
}
alert( factorial(5) ); // 120斐波那契数
斐波那契数序列有这样地公式: Fn = Fn-1 + Fn-2。换句话说,下一个数字是前两个数字的和。
前面两个数字是1,然后是2(1+1),然后是3(1+2),5(2+3)等: 1,1,2,3,5,8,13,21.。。。
斐波那契数与黄金比例 以及我们周围的许多自然现象有关。
编写一个函数fib(n)返回第n个斐波那契数。
要求: 函数运行速度要快,对fib(77)地调用不应该超过几分之一秒。
代码实现
// 方式一:递归
function fib(n) {
if(n === 1 || n === 2) return 1
return fib(n-1) + fib(n-2)
}……但是 n 比较大时会很慢。比如 fib(77) 会挂起引擎一段时间,并且消耗所有 CPU 资源。
因为函数产生了太多的子调用。同样的值被一遍又一遍地计算。
例如,我们看下计算 fib(5) 的片段:
...
fib(5) = fib(4) + fib(3)
fib(4) = fib(3) + fib(2)
...可以看到,fib(5) 和 fib(4) 都需要 fib(3) 的值,所以 fib(3) 被独立计算了两次。
这是完整的递归树:
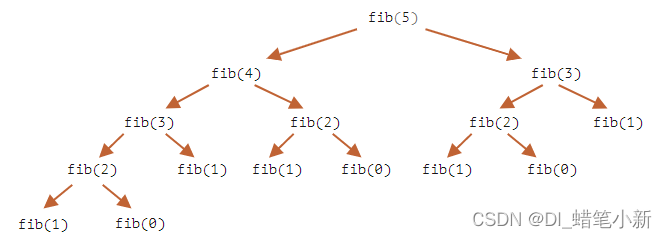
我们可以清楚的看到 fib(3) 被计算了两次,fib(2) 被计算了三次。总计算量远远超过了 n,这造成仅仅对于计算 n=77 来讲,计算量就是巨大的。
我们可以通过记录已经计算过的值来进行优化:如果一个值比如 fib(3) 已经被计算过一次,那么我们可以在后面的计算中重复使用它。
另一个选择就是不使用递归,而是使用完全不同的基于循环的算法。
与从 n 到降到更小的值相反,我们可以使用循环从 1 和 2 开始,然后得到它们的和 fib(3),然后再通过前两个数的和得到 fib(4),然后 fib(5),以此类推,直至达到所需要的值。在每一步,我们只需要记录前两个值就可以。
下面是新算法的细节步骤:
开始:
// a = fib(1), b = fib(2),这些值是根据定义 1 得到的
let a = 1, b = 1;
// 求两者的和得到 c = fib(3)
let c = a + b;
/* 现在我们有 fib(1),fib(2) 和 fib(3)
a b c
1, 1, 2
*/现在我们想要得到 fib(4) = fib(2) + fib(3)。
我们移动变量:a,b 将得到 fib(2),fib(3),c 将得到两者的和:
a = b; // 现在 a = fib(2)
b = c; // 现在 b = fib(3)
c = a + b; // c = fib(4)
/* 现在我们有这样的序列
a b c
1, 1, 2, 3
*/下一步得到另一个序列数:
a = b; // 现在 a = fib(3)
b = c; // 现在 b = fib(4)
c = a + b; // c = fib(5)
/* 现在序列是(又加了一个数):
a b c
1, 1, 2, 3, 5
*/……依次类推,直到我们得到需要的值。这比递归快很多,而且没有重复计算。
完整代码:
function fib(n) {
let a = 1;
let b = 1;
for(let i = 3; i <= n; i++) {
let c = a + b;
a = b;
b = c;
}
return b
}
alert( fib(3) ); // 2
alert( fib(7) ); // 13
alert( fib(77) ); // 5527939700884757循环从 i=3 开始,因为前两个序列值被硬编码到变量 a=1,b=1。
这种方式称为自下而上地动态规划。
输出一个单链表
假设我们有一个单链表:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};编写一个可以逐个输出链表元素的函数 printList(list)。
循环解法
function printList(list) {
let tmp = list;
while(tmp) {
alert(tmp.value)
tmp = tmp.next
}
}
printList(list)递归解法
function printList(list) {
alert(list.value) //输出当前元素
if(list.next) {
printList(list.next) //链表中其余部分同理
}
}
printList(list)哪个更好呢?
从技术上讲,循环更有效。这两种解法的做了同样的事儿,但循环不会为嵌套函数调用消耗资源。
另一方面,递归解法更简洁,有时更容易理解
反向输出单链表
反向输出前一个任务输出一个单链表中地单链表。
使用递归
递归逻辑在这稍微有点儿棘手。
我们需要先输出列表的其它元素,然后 输出当前的元素:
function printReverseList(list) {
if(list.next) {
printReverseList(list.next)
}
alert(list.value)
}
printReverseList(list)使用循环
循环解法也比直接输出稍微复杂了点儿。
在这而没有什么方法可以获取 list 中的最后一个值。我们也不能“从后向前”读取。
因此,我们可以做的就是直接按顺序遍历每个元素,并把它们存到一个数组中,然后反向输出我们存储在数组中的元素:
function printReverseList(list) {
let arr = [];
let tmp = list;
while(tmp) {
arr.push(tmp.value)
tmp = tmp.value
}
for(let i = arr.length - 1; i >= 0; i--) {
alert(arr[i])
}
}
printReverseList(list)请注意,递归解法实际上也是这样做的:它顺着链表,记录每一个嵌套调用里链表的元素(在执行上下文堆栈里),然后输出它们。

















 3577
3577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









