







 本文记录了一则在处理Redis `info memory` 命令响应时遇到的问题,即通过正则表达式提取`used_memory`失败。问题出现在不精确的匹配模式上,解决方案是采用更精确的正则表达式。博客强调了在使用正则匹配时,模式的准确性至关重要,以避免潜在的陷阱,并提供了改进后的匹配模式和Python的类似用例。
本文记录了一则在处理Redis `info memory` 命令响应时遇到的问题,即通过正则表达式提取`used_memory`失败。问题出现在不精确的匹配模式上,解决方案是采用更精确的正则表达式。博客强调了在使用正则匹配时,模式的准确性至关重要,以避免潜在的陷阱,并提供了改进后的匹配模式和Python的类似用例。
记录一则使用regex 的异常case:问题背景
对redis执行命令“info memroy”后返回的结果进行了处理转化成了字符串,然后通过regex匹配目标项,就出现了诡异的现象,暂时没有对regex的内部做深入研究,欢迎理解原因的大佬不吝赐教
对redis执行info memroy并处理后的结果集存入变量replySlice中,为string类型
func TestSendRedisExecMsgToServer(t *testing.T) {
var syncMsg *pb.ManagerTaskMsg
syncMsg = &pb.ManagerTaskMsg{
Timestamp: time.Now().Unix(),
TaskId: 111,
TaskType: pb.TaskType_REDIS_CMD_EXEC,
MsgType: &pb.ManagerTaskMsg_TaskExecRedis{
TaskExecRedis: &pb.ManagerTaskExecRedis{
ServerType: "redis",
Port: 7017,
RedisCmd: "info memory",
},
},
}
redisRespons, err := SendRedisExecMsgToServer(syncMsg, "xx.xx.xx.xx:6999")
Convey("send redis exec message to proxy success", t, func() {
So(err, ShouldBeNil)
})
reply, err := AnalyseRedisStrReply(redisRespons)
fmt.Printf("replySlice: %v\n", reply)
replySlice输出为
replySlice: ��[]uint8
�~�z# Memory
used_memory:202238584
used_memory_human:192.87M
used_memory_rss:3141632
used_memory_rss_human:3.00M
used_memory_peak:202279552
used_memory_peak_human:192.91M
used_memory_peak_perc:99.98%
used_memory_overhead:202214628
used_memory_startup:787800
used_memory_dataset:23956
used_memory_dataset_perc:0.01%
total_system_memory:134627131392
total_system_memory_human:125.38G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:8589934592
maxmemory_human:8.00G
maxmemory_policy:volatile-lru
mem_fragmentation_ratio:0.02
mem_allocator:jemalloc-4.0.3
active_defrag_running:0
lazyfree_pending_objects:0
出现异常现象匹配模式
regx, err := regexp.Compile("used_memory:.*")
// regx, err := regexp.Compile("used_memory:[0-9]+")
usedMemBytes := regx.FindString(reply)
var usedMemG, usedMemBytesF float64
if usedMemBytes != "" {
usedMemBytes = strings.Split(usedMemBytes, ":")[1] //截取数字字符串
fmt.Println(usedMemBytes)
fmt.Printf("[%v]\n", usedMemBytes)
usedMemBytesF, _ = strconv.ParseFloat(usedMemBytes, 64) //数字字符串转换为float64
usedMemG, _ = strconv.ParseFloat(fmt.Sprintf("%.2f", usedMemBytesF/1024/1024/1024), 64) //保留2位小数
}
fmt.Printf("usedMemG:%v,usedMemBytes:%v", usedMemG, usedMemBytes)
输出如下,格式化输出数字字符串不符合预期,再结合转化为float64不成功(为0说明字符串中包含除数字之外的字符),猜测问题处于两个地方,要不是原本的字符串有问题,要不是匹配模式不对,第一个可疑点是通过strings.Trim来排除的,接下来验证第二个可疑点

正则匹配模式更为精准匹配后符合预期
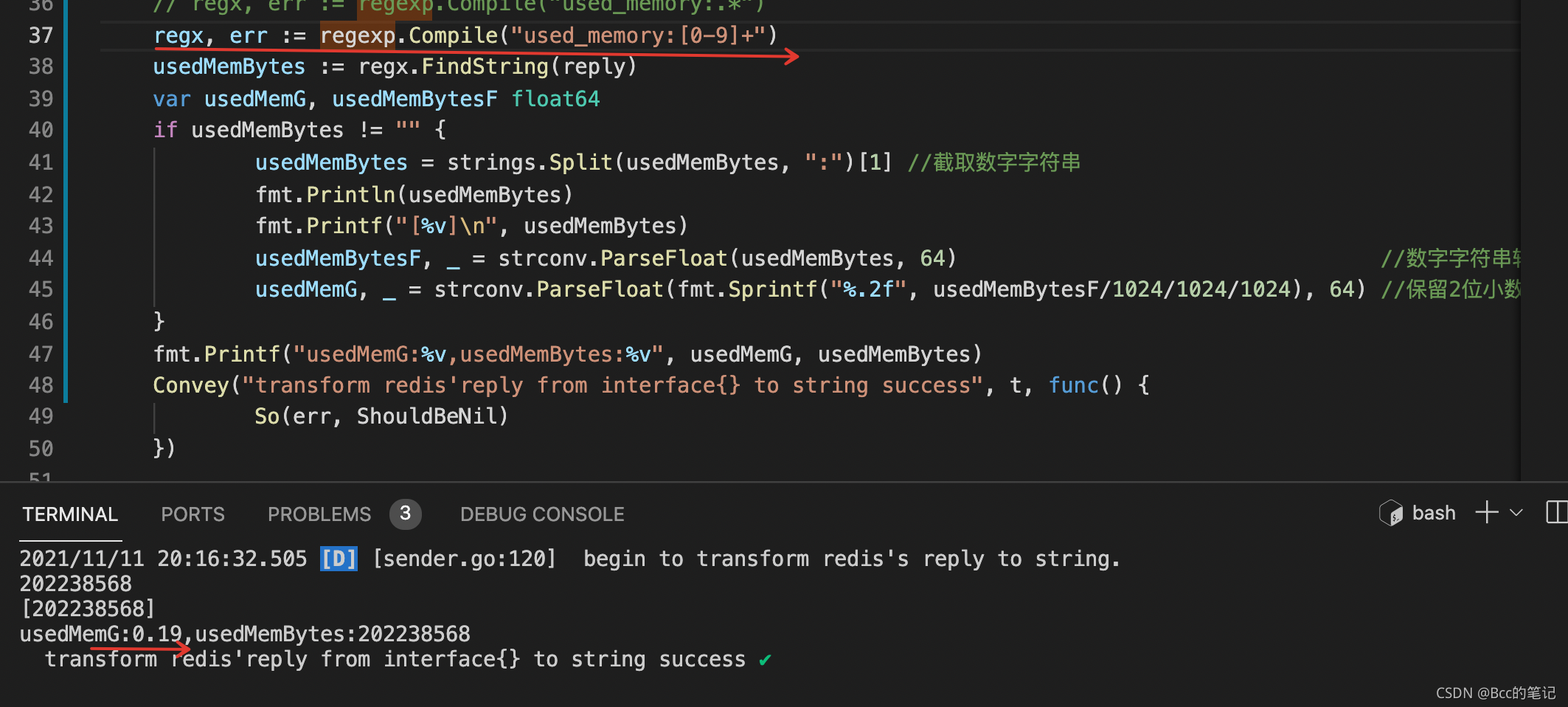
看来regex的匹配模式尽量精准,否则容易掉坑里,究其根本原因待有时间再细究
补充:可以使用strings.Fields(match)[0] 去除匹配的字符串match尾部的特殊字符
其他使用案例
1、分组匹配,即将同一行的目标匹配项放到一个数组中,类似python中的groups,具体实现如下
slaveMat, err := regexp.Compile(`slave[0-9]+:ip=(.*),port=(.*),state=(.*),offset.*`)
if err != nil {
common.Log.Warn("fail to regexp. matchString=[%v] error=[%v]", slaveMsg, err)
return nil, err
}
slaveRes := slaveMat.FindAllStringSubmatch(slaveMsg, -1)
if slaveRes == nil {
errInfo := fmt.Sprintf("has no slave matched. matchString=%v", slaveMsg)
common.Log.Warn(errInfo)
return nil, errors.New(errInfo)
}
slaveMatch := slaveRes[0]
slaveIp := slaveMatch[1]
slavePortStr := slaveMatch[2]
python中的实现方式为
import re
url='jdbc.url=jdbc:mysql://${mysql_57_master}:6010/xm_nnd_t?u'
match_re = re.compile(r'\$\{([a-z_0-9]+)\}:(\d+)/([a-z_0-9]+)')
m=match_re.search(url)
print m.groups()

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









