







 Redis作为缓存数据库,不采用多线程而是利用I/O多路复用(如epoll)技术解决网络IO瓶颈,避免了多线程的资源争用和上下文切换问题,保持高性能。Redis使用Reactor模式,通过注册文件事件和事件处理方法,实现单线程高效处理网络请求。
Redis作为缓存数据库,不采用多线程而是利用I/O多路复用(如epoll)技术解决网络IO瓶颈,避免了多线程的资源争用和上下文切换问题,保持高性能。Redis使用Reactor模式,通过注册文件事件和事件处理方法,实现单线程高效处理网络请求。
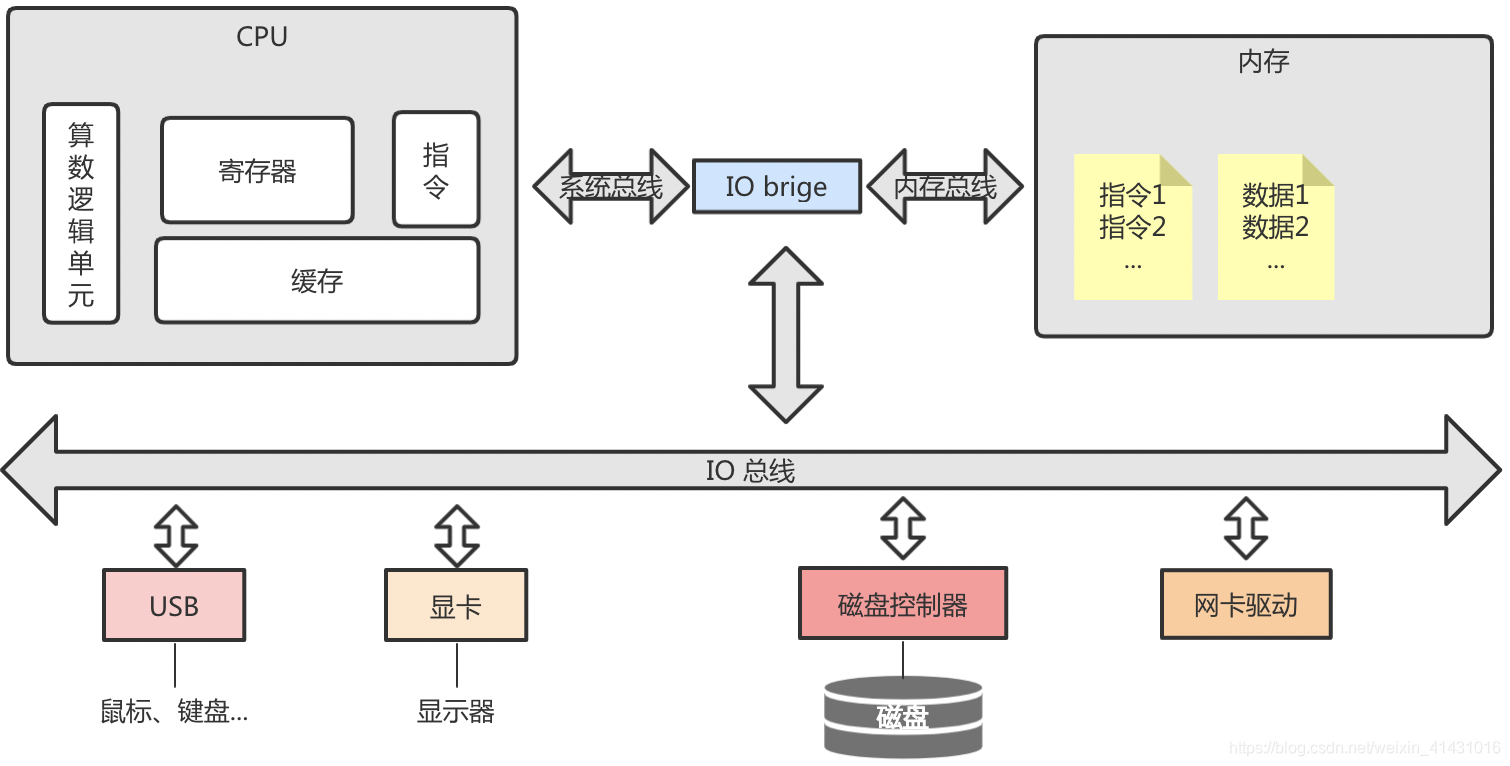
先来简单看一下一个应用启动后在操作系统中是如何运行的:
- 程序启动后其一系列的指令和数据被加载到内存中,程序可以实现为单线程也可以是多线程或者多进程,只不过进程间的内存空间是独享的,而线程间是共享的,除了一些栈和指令独享外(这里以线程为例);
- 内核调度器负责将线程分配给cpu,如果是多线程且数量大于cpu核数,则多个线程可能会被同时被分配到一同一个cpu核上,cpu通过总线访问内存中线程的指令和数据,将内存中的数据页拷贝到自己的缓存中,待执行的指令放到寄存器中,算数逻辑单元负责计算逻辑,指令中存放当前线程正在执行的指令等数据信息;
- 内核控制设备的访问,即对设备的访问是在内核态进行的,用户程序运行在用户态,不能直接访问内核态的资源,所以用户程序对设备的操作(如I/O)请求通过系统调度完成;
用户程序什么情况下采用多线程会提高性能
当用户程序是I/O密集型的服务时,比如文件系统、存储型数据库,频发的访问磁盘,而磁盘IO相对是低速操作,如果是单线程,cpu大多数都是等待磁盘IO的空闲状态,线程性能低且cpu资源又得不到充分利用。所以需要采用多线程模式。
多线程带来的问题
- 资源争用
如初始化变量v=0,开启10个线程,并发对v累加1,每个线程累加1000次,则最终预期的结果是v=10000,但是实际值会发现比10000小,主要原因如下图所示
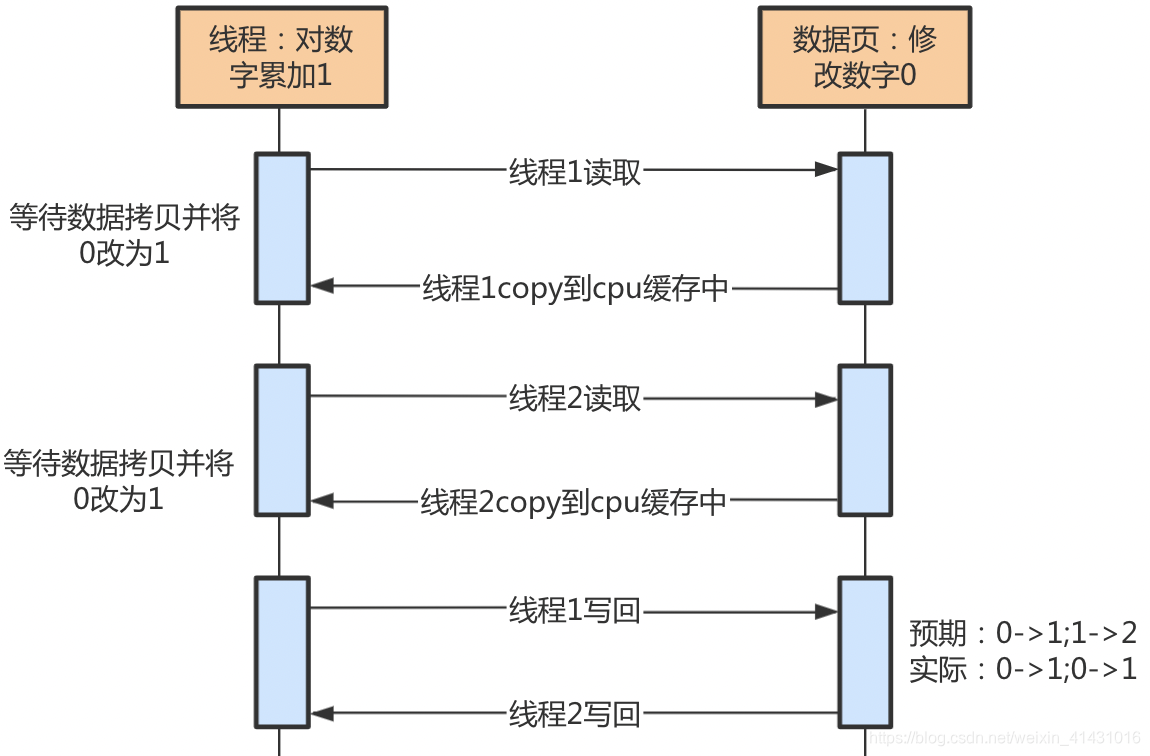
比如两个线程被分配到了不同的cpu核上,则他们可以并行操作相同的资源,线程1所运行的cpu读取变量v所在的数据页,从内存中读取到自己的缓存中,然后执行v=0+1,但是在写回的过程中,线程2所在的另一cpu也读取到相同的v=0,也将其+1变为1,所以v最终为1,而不是预期的2;
要想解决此类问题就需要对数据结构v加锁,来保证同一时间只能同时有一个线程操作v ;
这样实现起来增加了代码的复杂度和死锁风险,且锁资源的创建和销毁也是有成本的,所以如果要保证数据的一致性就需要牺牲一定的性能。 - 线程上线文切换
如果线程的数量大于cpu的数量,内核调度器会为每个cpu维护一个进程队列,高优先级的线程先执行;
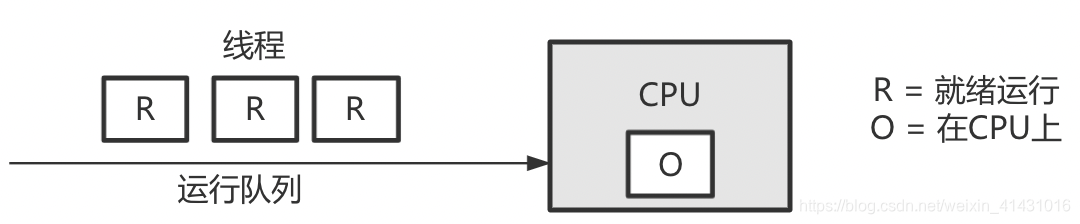
cpu是线性模式,为了防止cpu因等待低速的IO调度而空闲,所以为了保证所有线程得到公平调度,cpu的时间被划分为很多时间片,这些时间片再被轮流分配给各个线程,单某个线程的时间分片用完但是此线程还未结束,这时cpu会保存当前线程1的栈和寄存器,然后切换到下一个线程2,这就发生一次上下文切换;
根据测试报告,每次上下文切换都需要几十纳秒到数微秒的 CPU 时间,所以频繁的上线文切换会折损一定的cpu性能。
那么redis为什么不采用多线程
由于redis是缓存行数据库,相对于磁盘IO,缓存的存取速度可以忽略不计,即使是单进程cpu每周期处理的指令数(IPC)也非常高,所以可以充分利用cpu资源且不存在多线程带来的资源争用以及上线文切换等问题;
但是网络IO可能会成为它的主要性能瓶颈
服务侧会为每个客户端连接创建一个与之对应的socket接口(net fd),以此来和客户端进行通信,然后监听此接口,当客户端发送网络请求时,服务端会调用系统层接口函数如read、write等处理网络事件;以read请求为例,系统调度器会为每个线程分配一个内核线程(补充:对于协程和内核线程是m对n的关系,即为多个协程分配一个内核进程,这也是为什么起上万个协程也不会使内核层出现性能瓶颈的问题,因为内核线程是顺序操作的,同时只能操作一个协程的请求,其他均排队等待),内核线程从fd中拷贝数据再返回给用户态的线程,在这个过程中线程一直处于阻塞状态,无法处理其他的客户端请求;
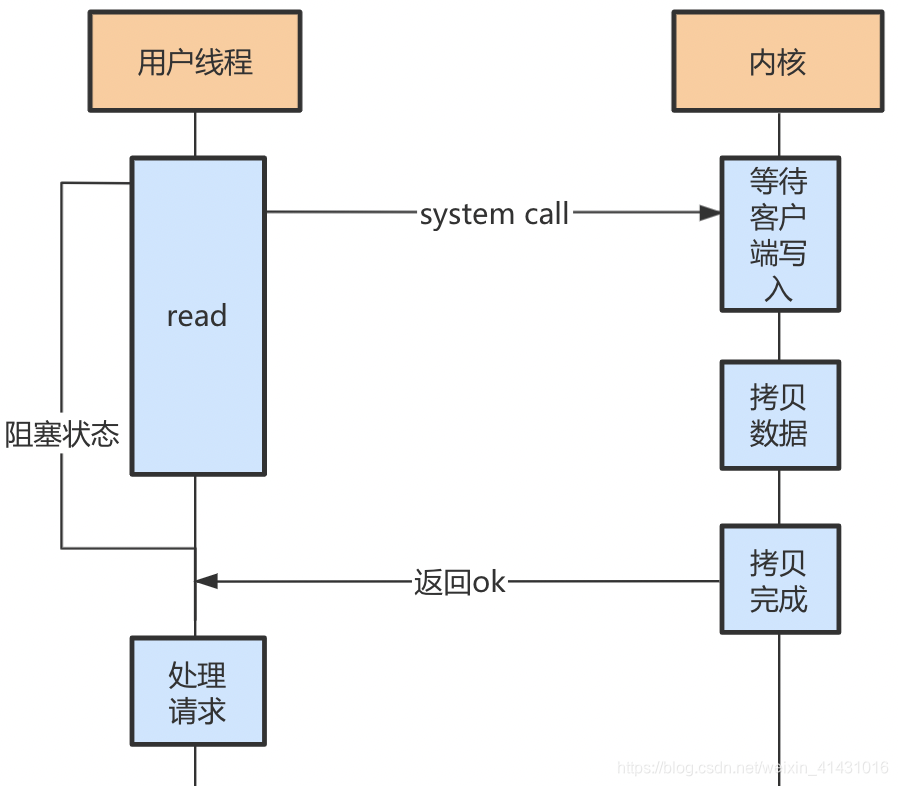
所以redis通过I/O多路复用来解决这个问题
多路指多个网络连接,复用指复用同一个线程;I/O多路复用模块封装了底层多种用来实现多路复用的函数,如select、poll、epoll,主要实现逻辑是将需要监听的fd注册到集合中,然后监听集合中fd的可读性,如果监听到有客户端的网络事件到达fd,则通知事件处理器处理请求;相比较于select、poll(返回的是fd的数量,服务侧还需要轮询所有已注册的fd),epool检测到网络事件后返回的是发生的网络事件及其对应的具体fd,效率更高;Linux操作系统下的redis采用的epoll的方式;
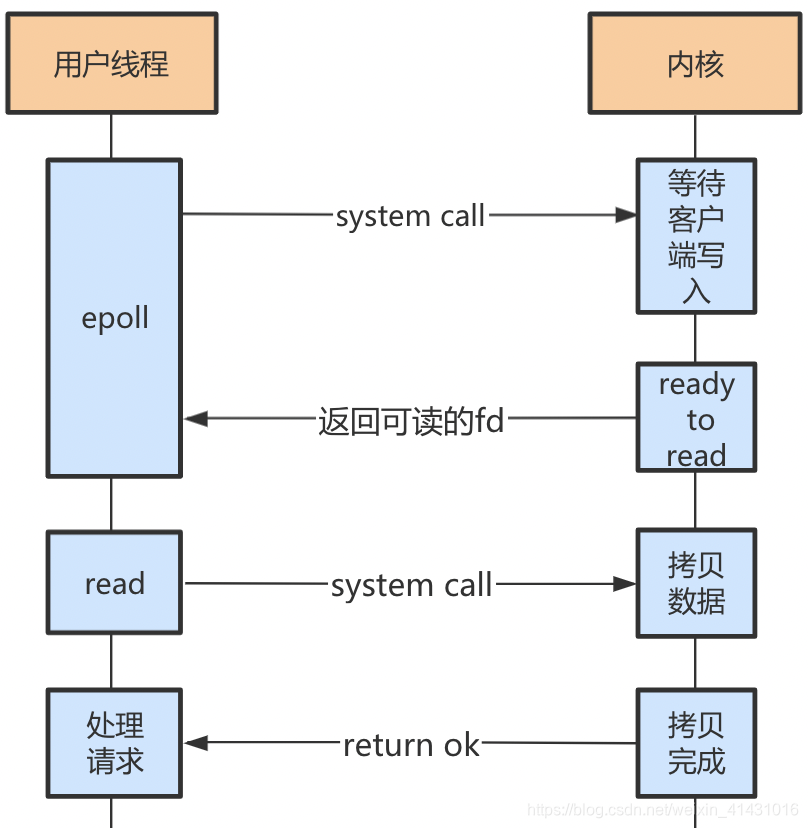
redis采用Reactor网络编程模型,redis主程序将文件事件及事件处理的方法如accept、read、write、close注册到reactor事件处理器中,事件处理器通过I/O多路复用模块监听,I/O多路复用模块返回监听到的文件事件及其对应的FD,事件处理器回调FD绑定的方法;
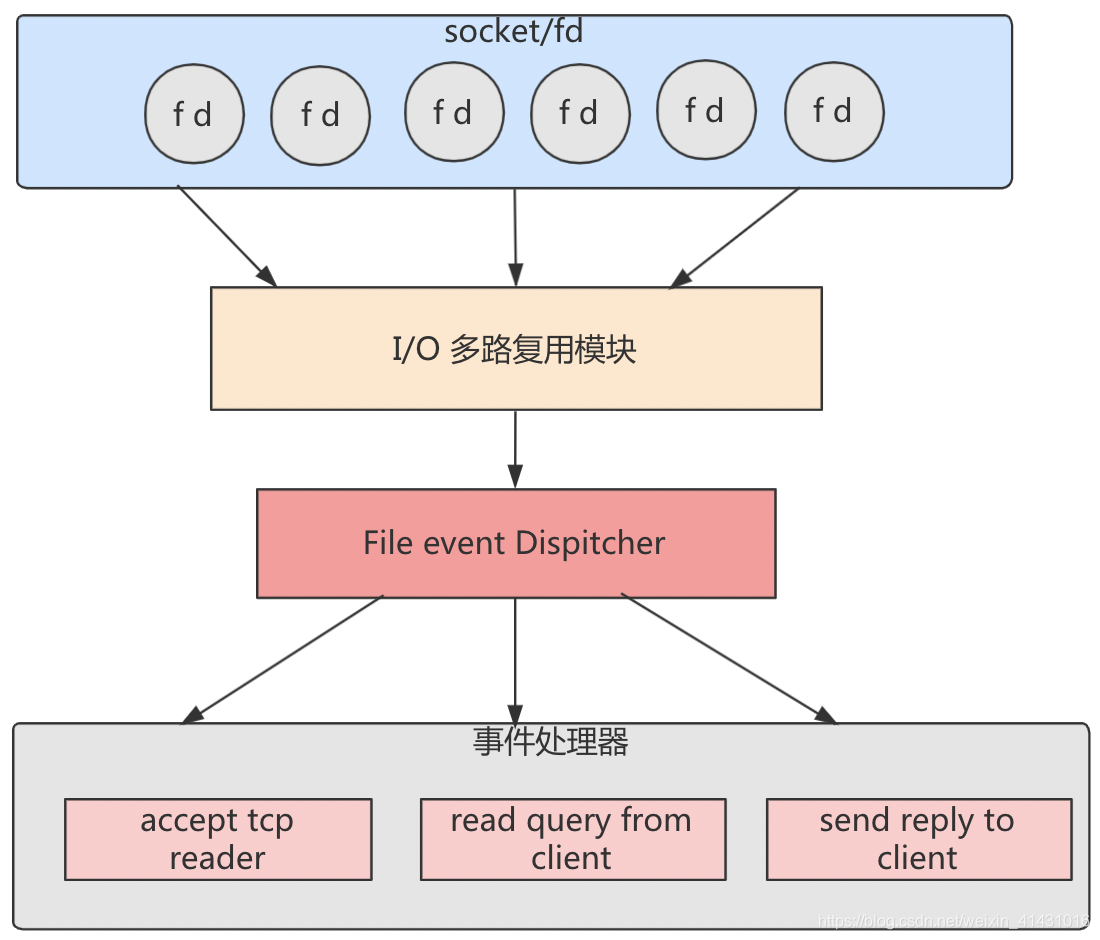
采用事件驱动的reactor模式,redis即使是单线程也可以高效的处理网络事件,使得cpu的利用率最大化。

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









