







针对磁盘I/O性能瓶颈引发的查询延迟问题,结合大数据场景的特点,可以从以下维度进行诊断和优化:
一、诊断流程与大数据关联分析
-
系统级监控
- 使用
iostat -x 1观察%util、await、svctm指标,识别磁盘I/O利用率是否持续超过80% - 通过
pidstat -d 1定位高I/O进程(如mysqld),统计其kB_read/s和kB_wrtn/s - 大数据场景下需注意:分布式存储(如HDFS)的I/O压力可能分散在多个节点,需结合集群监控工具(如Prometheus)全局分析
- 使用
-
数据库层分析
- 慢查询定位:启用慢查询日志(MySQL配置
slow_query_log=1,PostgreSQL配置log_min_duration_statement=2000)
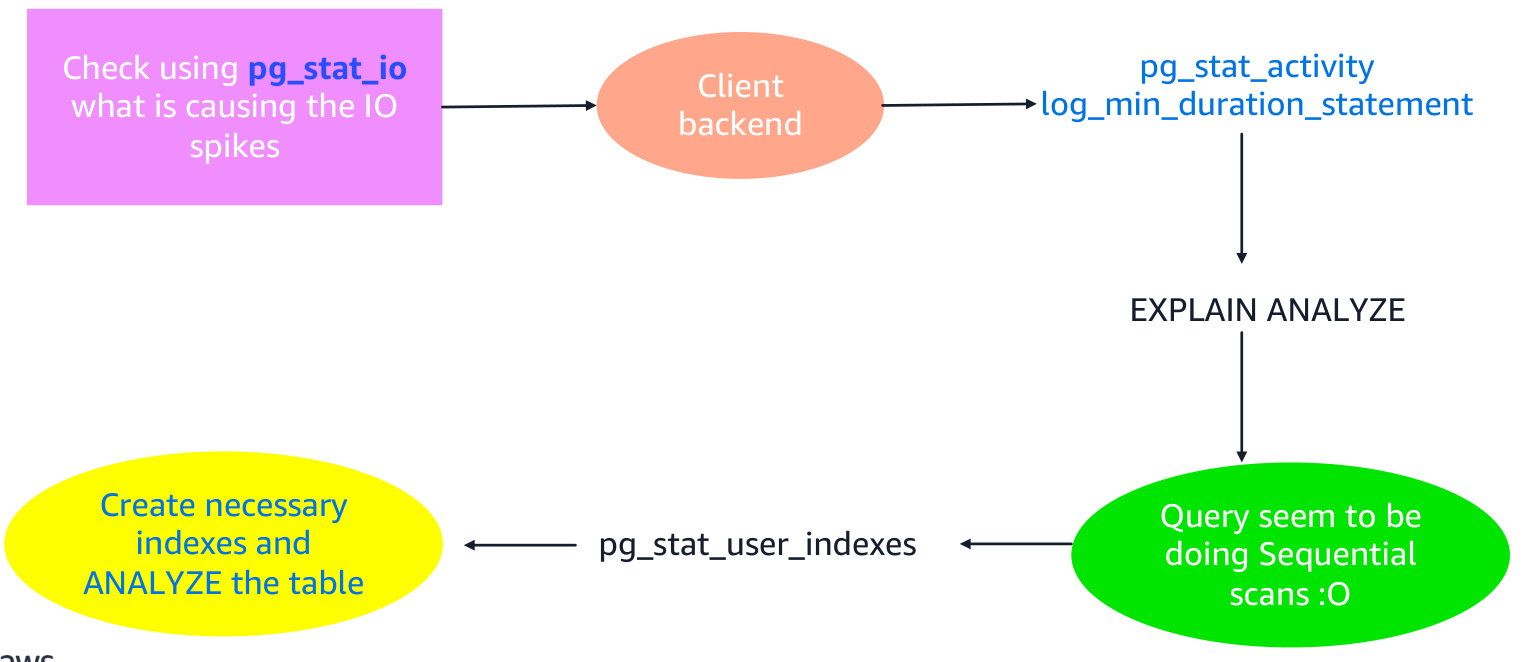
- 执行计划分析:通过
EXPLAIN ANALYZE查看是否触发全表扫描(Seq Scan),大数据表顺序扫描会显著增加I/O
- 慢查询定位:启用慢查询日志(MySQL配置
-- 示例:分析查询计划
EXPLAIN ANALYZE SELECT * FROM orders WHERE date > '2023-01-01';
-- 若发现Seq Scan,需创建索引 [[1,8]]
CREATE INDEX idx_orders_date ON orders(date);
- 存储结构分析
- 区分不同存储区域:
- Data dbspace:检查大表是否未分区,导致全表扫描
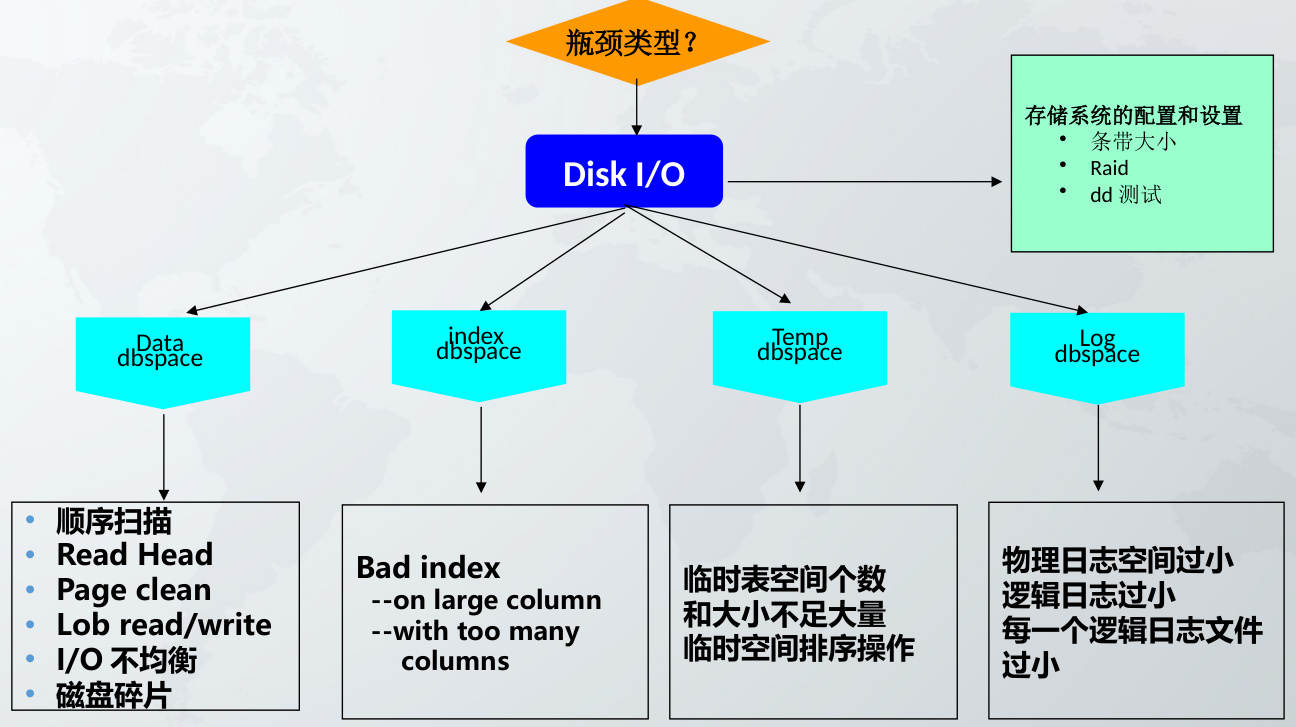
- Temp dbspace:临时表空间不足会导致频繁磁盘交换,需扩展或优化排序操作
- Log dbspace:日志文件过小会引发频繁切换,调整逻辑日志大小
二、优化策略与代码示例
1. 查询与索引优化
- 避免全表扫描:
-- 添加复合索引优化多条件查询
CREATE INDEX idx_users_age_name ON users(age, name);
- 覆盖索引减少I/O:
-- 仅通过索引返回数据
SELECT age FROM users WHERE age > 30; -- 需索引`CREATE INDEX idx_age ON users(age)`
2. 存储架构优化
- 冷热数据分离:
- 使用分区表将历史数据归档(如按时间分区),减少活跃数据集大小
-- PostgreSQL分区表示例
CREATE TABLE sales PARTITION BY RANGE (sale_date);
CREATE TABLE sa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











