






为什么会有增量更新和原始快照两种算法?
1:本次应该清理的对象,被用户线程更新为存活对象,逃过本次清理
2:将原本存活的对象的标记为已消亡,一个程序还需要使用的对象被回收了,那程序肯定会因此发生错误
在了解增量更新和原始快照之前,首先先理解三色标记
白色:表示对象尚未被垃圾回收器访问过。显然,在可达性分析刚刚开始的阶段,所有的对象都是白色的,若在分析结束的阶段,仍然是白色的对象,即代表不可达。标记结束,清除所有的白色对象
黑色:表示对象已经被垃圾回收器访问过,且这个对象的所有引用都已经扫描过。黑色的对象代表已经扫描过,它是安全存活的,如果有其它的对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接(不经过灰色对象)指向某个白色对象。
灰色:表示对象已经被垃圾回收器访问过,但这个对象至少存在一个引用还没有被扫描过。标记结束,不存在灰色对象
因为并发标记的时候,回收线程和用户一起并发,可能导致的情况就是
1.用户线程错误的将原本消亡的对象错误的标记为存活,这不是好事,但是其实是可以容忍的,只不过产生了一点逃过本次回收的浮动垃圾而已,下次清理就可以。按照可达性算法分析1,2,3是得被回收的,但是可能用户线程增加了3–>4的引用导致1,2,3无法在本次垃圾回收中回收
标记开始

标记结束
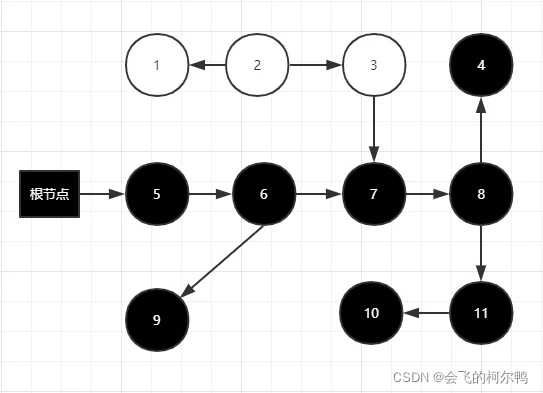
2.把原本存活的对象错误的标记为已消亡,一个程序还需要使用的对象被回收了,那程序肯定会因此发生错误。这种错误一定要阻止
对象消失的情况:删除了灰色对白色对象的引用,且新增了5到9的引用,导致了如果重新进行可达分析,9应该是存活的,但是现实是9将在本次垃圾回收中被清除,
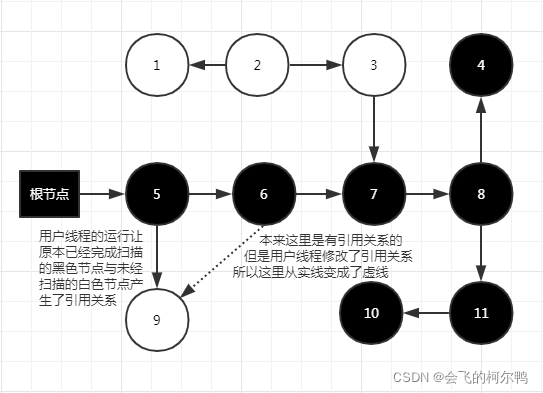
对象消失的条件:
1:赋值器插入了一条或者多条从黑色对象到白色对象的新引用。 ------->增量更新
2:赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。------->原始快照
增量更新要破坏的是第一个条件(赋值器插入了一条或者多条从黑色对象到白色对象的新引用),当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一次。可以简化的理解为:黑色对象一旦插入了指向白色对象的引用之后,它就变回了灰色对象。
原始快照要破坏的是第二个条件(赋值器删除了全部从灰色对象到该白色对象的直接或间接引用),当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束之后,再将这些记录过的引用关系中的灰色对象为根,重新扫描一次。这个可以简化理解为:无论引用关系删除与否,都会按照刚刚开始扫描那一刻的对象图快照开进行搜索。就是会在6的位置找到9,不会因为用户线程修改了引用而将其对象回收。因为在扫描开始的时候只要有对象树上面有变动就会被记录
参考链接:https://www.cnblogs.com/thisiswhy/p/12354864.html

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









