






 本文详细介绍了ActiveMQ的配置文件activemq.xml和jetty.xml,特别是activemq.xml中关于用户权限的配置,以及消息持久化机制,包括KahaDB、JDBC和LevelDB等存储方式的优缺点。还涵盖了消息的持久性、事务处理、签收模式、消息过期和死信队列的管理,以及如何设置消息不被持久化。此外,讨论了消息的优先级和消费顺序,以及如何通过消息过滤实现消费负载均衡。
本文详细介绍了ActiveMQ的配置文件activemq.xml和jetty.xml,特别是activemq.xml中关于用户权限的配置,以及消息持久化机制,包括KahaDB、JDBC和LevelDB等存储方式的优缺点。还涵盖了消息的持久性、事务处理、签收模式、消息过期和死信队列的管理,以及如何设置消息不被持久化。此外,讨论了消息的优先级和消费顺序,以及如何通过消息过滤实现消费负载均衡。
需要关心的两个配置文件:
activemq.xml activemq的配置文件
jetty.xml web容器的配置文件 就是访问8161的web容器
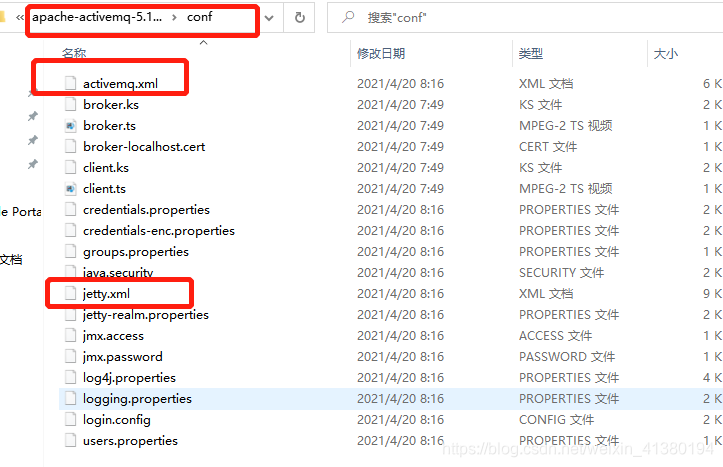

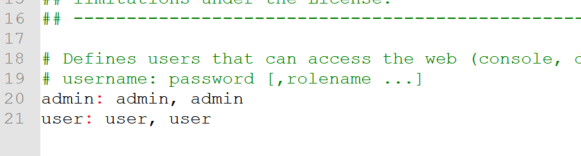
web容器登录的用户名密码在这里。
代码链接activemq的时候所需要的密码:
// 1. 建立工厂对象,
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory(
ActiveMQConnectionFactory.DEFAULT_USER,
ActiveMQConnectionFactory.DEFAULT_PASSWORD,
“tcp://localhost:61616”
);
ActiveMQConnectionFactory.DEFAULT_USER, 都是null
ActiveMQConnectionFactory.DEFAULT_PASSWORD, 都是null
这样的话所有人都能链接到mq,就有可能消费消息。如果测试不小心把链接配置为线上的 那么消息可能就会被测试消费。
所以一个项目一个账户。如何新增呢?
activemq.xml中配置

在broker节点的最后加上:
这个配置是给当前的borker配置的,代码在连接的时候必须有配置中任一用户名密码,否则会报错。
所有需要持久化的内容都在这个文件夹中:

data目录下的kahadb目录中。
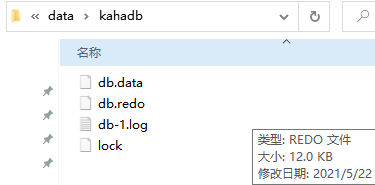
这是默认的持久方式。
持久性
JMS 支持以下两种消息提交模式:
PERSISTENT。指示JMS Provider持久保存消息,以保证消息不会因为JMS Provider的失败而丢失。
NON_PERSISTENT。不要求JMS Provider持久保存消息。
持久存储有以下集中方式:
存储
KahaDB存储
KahaDB是默认的持久化策略,所有消息顺序添加到一个日志文件中,同时另外有一个索引文件记录指向这些日志的存储地址,还有一个事务日志用于消息回复操作。是一个专门针对消息持久化的解决方案,它对典型的消息使用模式进行了优化。
在data/kahadb这个目录下,会生成四个文件,来完成消息持久化
1.db.data 它是消息的索引文件,本质上是B-Tree(B树),使用B-Tree作为索引指向db-*.log里面存储的消息
2.db.redo 用来进行消息恢复 *
3.db-.log 存储消息内容。新的数据以APPEND的方式追加到日志文件末尾。属于顺序写入,因此消息存储是比较 快的。默认是32M,达到阀值会自动递增
4.lock文件 锁,写入当前获得kahadb读写权限的broker ,用于在集群环境下的竞争处理
<kahaDBdirectory="${activemq.data}/kahadb"journalMaxFileLength=“16mb”/>
特性:
1、日志形式存储消息;
2、消息索引以 B-Tree 结构存储,可以快速更新;
3、 完全支持 JMS 事务;
4、支持多种恢复机制kahadb 可以限制每个数据文件的大小。不代表总计数据容量。
AMQ 方式
只适用于 5.3 版本之前。 AMQ 也是一个文件型数据库,消息信息最终是存储在文件中。内存中也会有缓存数据。
<amqPersistenceAdapterdirectory="${activemq.data}/amq"maxFileLength=“32mb”/>
性能高于 JDBC,写入消息时,会将消息写入日志文件,由于是顺序追加写,性能很高。
为了提升性能,创建消息主键索引,并且提供缓存机制,进一步提升性能。
每个日志文件的 大小都是有限制的(默认 32m,可自行配置) 。
当超过这个大小,系统会重新建立一个文件。
当所有的消息都消费完成,系统会删除这 个文件或者归档。
主要的缺点是 AMQ Message 会为每一个 Destination 创建一个索引,如果使用了大量的 Queue,索引文件的大小会占用很多磁盘空间。
而且由于索引巨大,一旦 Broker(ActiveMQ 应用实例)崩溃,重建索引的速度会非常 慢。
虽然 AMQ 性能略高于 Kaha DB 方式,但是由于其重建索引时间过长,而且索引文件 占用磁盘空间过大,所以已经不推荐使用。
JDBC存储
使用JDBC持久化方式,数据库默认会创建3个表,每个表的作用如下:
activemq_msgs:queue和topic的消息都存在这个表中
activemq_acks:存储持久订阅的信息和最后一个持久订阅接收的消息ID
activemq_lock:跟kahadb的lock文件类似,确保数据库在某一时刻只有一个broker在访问
ActiveMQ 将数据持久化到数据库中。
不指定具体的数据库。 可以使用任意的数据库 中。
本环节中使用 MySQL 数据库。 下述文件为 activemq.xml 配置文件部分内容。
首先定义一个 mysql-ds 的 MySQL 数据源,然后在 persistenceAdapter 节点中配置 jdbcPersistenceAdapter 并且引用刚才定义的数据源。
dataSource 指定持久化数据库的 bean,createTablesOnStartup 是否在启动的时候创建数 据表,默认值是 true,这样每次启动都会去创建数据表了,一般是第一次启动的时候设置为 true,之后改成 false。
Beans中添加
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="true" />
</persistenceAdapter>
依赖jar包
commons-dbcp commons-pool mysql-connector-java
表字段解释
activemq_acks:用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存。
主要的数据库字段如下:
container:消息的destination
sub_dest:如果是使用static集群,这个字段会有集群其他系统的信息
client_id:每个订阅者都必须有一个唯一的客户端id用以区分
sub_name:订阅者名称
selector:选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性and和or操作
last_acked_id:记录消费过的消息的id。
2:activemq_lock:在集群环境中才有用,只有一个Broker可以获得消息,称为Master Broker,其他的只能作为备份等待Master Broker不可用,才可能成为下一个Master Broker。这个表用于记录哪个Broker是当前的Master Broker。
3:activemq_msgs:用于存储消息,Queue和Topic都存储在这个表中。
主要的数据库字段如下:
id:自增的数据库主键
container:消息的destination
msgid_prod:消息发送者客户端的主键
msg_seq:是发送消息的顺序,msgid_prod+msg_seq可以组成jms的messageid
expiration:消息的过期时间,存储的是从1970-01-01到现在的毫秒数
msg:消息本体的java序列化对象的二进制数据
priority:优先级,从0-9,数值越大优先级越高
xid:用于存储订阅关系。如果是持久化topic,订阅者和服务器的订阅关系在这个表保存。
LevelDB存储
LevelDB持久化性能高于KahaDB,虽然目前默认的持久化方式仍然是KahaDB。并且,在ActiveMQ 5.9版本提供 了基于LevelDB和Zookeeper的数据复制方式,用于Master-slave方式的首选数据复制方案。 但是在ActiveMQ官网对LevelDB的表述:LevelDB官方建议使用以及不再支持,推荐使用的是KahaDB
Memory 消息存储
顾名思义,基于内存的消息存储,就是消息存储在内存中。persistent=”false”,表示不设置持 久化存储,直接存储到内存中
在broker标签处设置。 消息容易丢失消失,mq不能重启。
JDBC Message store with ActiveMQ Journal
这种方式克服了JDBC Store的不足,JDBC存储每次消息过来,都需要去写库和读库。 ActiveMQ Journal,使用延迟存储数据到数据库,当消息来到时先缓存到文件中,延迟后才写到数据库中。
当消费者的消费速度能够及时跟上生产者消息的生产速度时,journal文件能够大大减少需要写入到DB中的消息。 举个例子,生产者生产了1000条消息,这1000条消息会保存到journal文件,如果消费者的消费速度很快的情况 下,在journal文件还没有同步到DB之前,消费者已经消费了90%的以上的消息,那么这个时候只需要同步剩余的 10%的消息到DB。 如果消费者的消费速度很慢,这个时候journal文件可以使消息以批量方式写到DB。
持久存储就是为了在activemq宕机后重启,消息不会丢失。
代码设置是否持久化:

默认设置是持久化的。
消息消费后,持久化的消息就会被删除。
事务:
session.commit();用来提交
session.rollback(); 回滚事务 不会将消息提交给mq.
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
false 表示不开启事务。
如果是true 就表示开启事务。
如果开启事务的话,在发送消息的时候就要commit。
就是 在producer.send(message); 的后面要有 session.commit();
如果没有commit的话,消息是不会被发送的。

也可以多条commit一次。
签收模式
签收代表接收端的session已收到消息的一次确认,反馈给broker
ActiveMQ支持自动签收与手动签收
Session.AUTO_ACKNOWLEDGE
当客户端从receiver或onMessage成功返回时,Session自动签收客户端的这条消息的收条。
Session.CLIENT_ACKNOWLEDGE
客户端通过调用消息(Message)的acknowledge方法签收消息。在这种情况下,签收发生在Session层面:签收一个已经消费的消息会自动地签收这个Session所有已消费的收条。
Session.DUPS_OK_ACKNOWLEDGE
Session不必确保对传送消息的签收,这个模式可能会引起消息的重复,但是降低了Session的开销,所以只有客户端能容忍重复的消息,才可使用。
如果建立连接的时候选择事务模式的话:签收模式就是固定的事务模式的签收.源码如下:如果不开启事务,签收模式就是参数设置的签收模式。
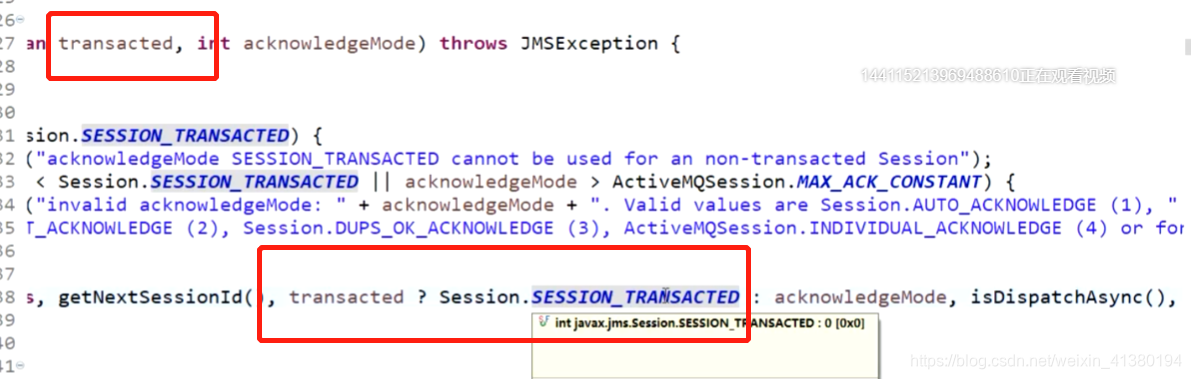
如果消息始终没有被确认,重启动消费者会消费这些没有被确认的消息。如果一条消息发送给消费者后,状态改为待执行,那么不会再把这个消息发送给别的消费者,除非这个消费者返回失败的ACK,否则会一直等待,直到session消失,才会将状态改为未确认状态。直到新的消费者上线后,会从持久数据库中获取没有被确认的消息。
如果是事务的确认模式 不仅仅需要acknowledge 还需要commit 否则activemq无法确认消息而删除。如下图:
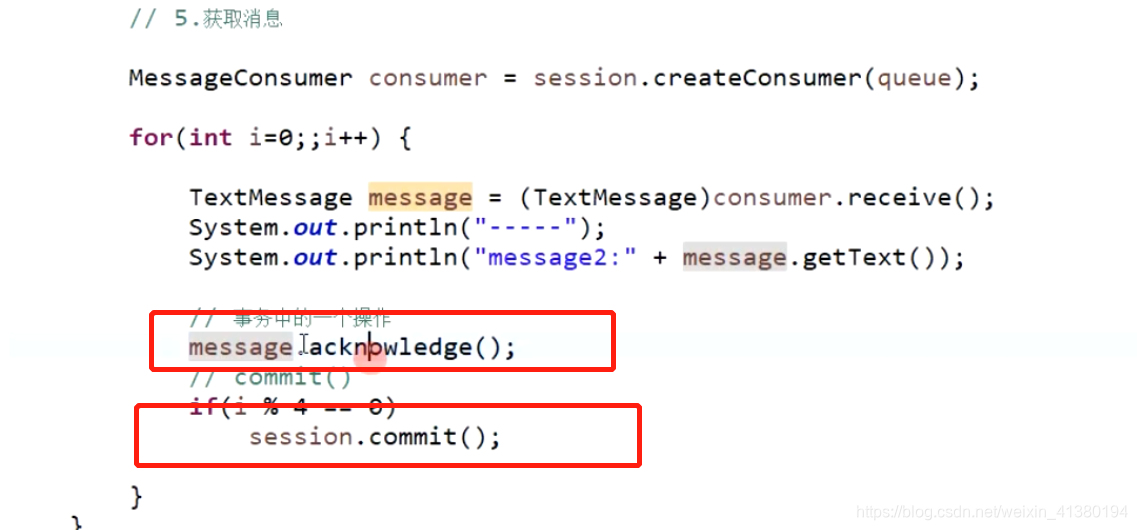
如果消费者拿到一个消息 异常或者未ack,mq会将消息发给另一个消费者,如果这个消费者异常或者未ack,会发给另一个消费者…
所有的消费者都没有返回ack或者异常,这个消息就在持久华中,必须等消费者重启后,才会消费这个消息。注意新的消费者也不会接收到这个消息,除非这个mq跟其他的消费者断开连接,不在等待了。新的消费者就可以消费。所以需要重新启动消费失败的消费者。
消息在待确认状态的时候是不会分发给别的消费者的,只有不属于等待确认状态并且没有被确认的时候,消费者可以消费这条消息。
持久化
默认持久化是开启的 如果需要不持久化就要手动设置
producer.setDeliveryMode(DeliveryMode.NON_PERSISTENT)
优先级
可以打乱消费顺序
producer.setPriority
配置文件需要指定使用优先级的目的地
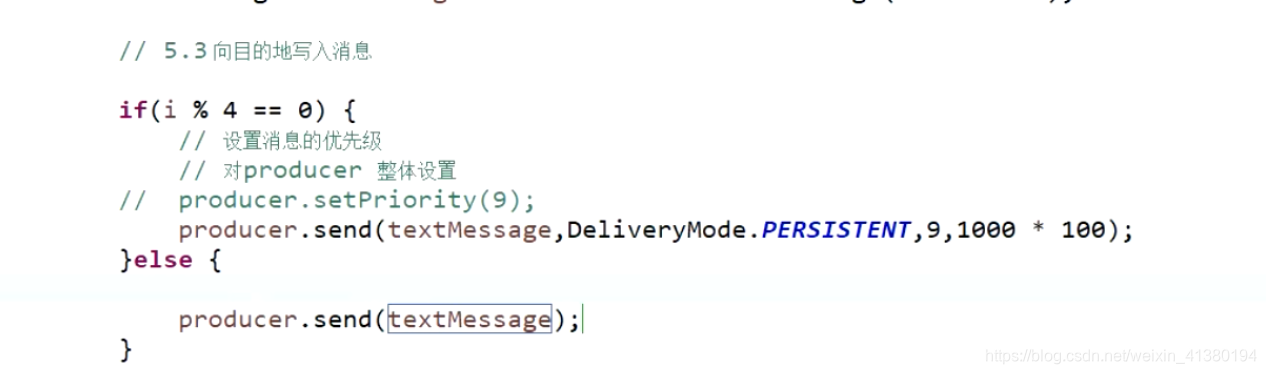
消息超时/过期
producer.setTimeToLive
设置了消息超时的消息,消费端在超时后无法在消费到此消息。
给消息设置一个超时时间 -> 死信队列 -> 拿出来 -> 重发
topic
生产者生产消息后,如果没有消费者,就不发送了,消息还会在内存中,不会持久化,有消费者上来,也不会再次消费这些消息。如图:

如图这1000消息不会再有人消费了,只能等待超时后,就会进入死信队列。
如果有消费者需要这写消息呢?
这时候就要通过死信队列 然后再次重发。
生产者可以监听私信队列,如果死信队列中有消息,就拿出来放入activemq,只要有消费者消费,消息就不存在了( 只要有一个消费者消费,消息就不存在了)。
如果不从死信队列中获取文件的话,死信队列就会无尽的堆积。死信队列是持久的。
或者在acticvemq设置重新投递策略。不管之前是否收到过,只要消费者还存在,都会收到。
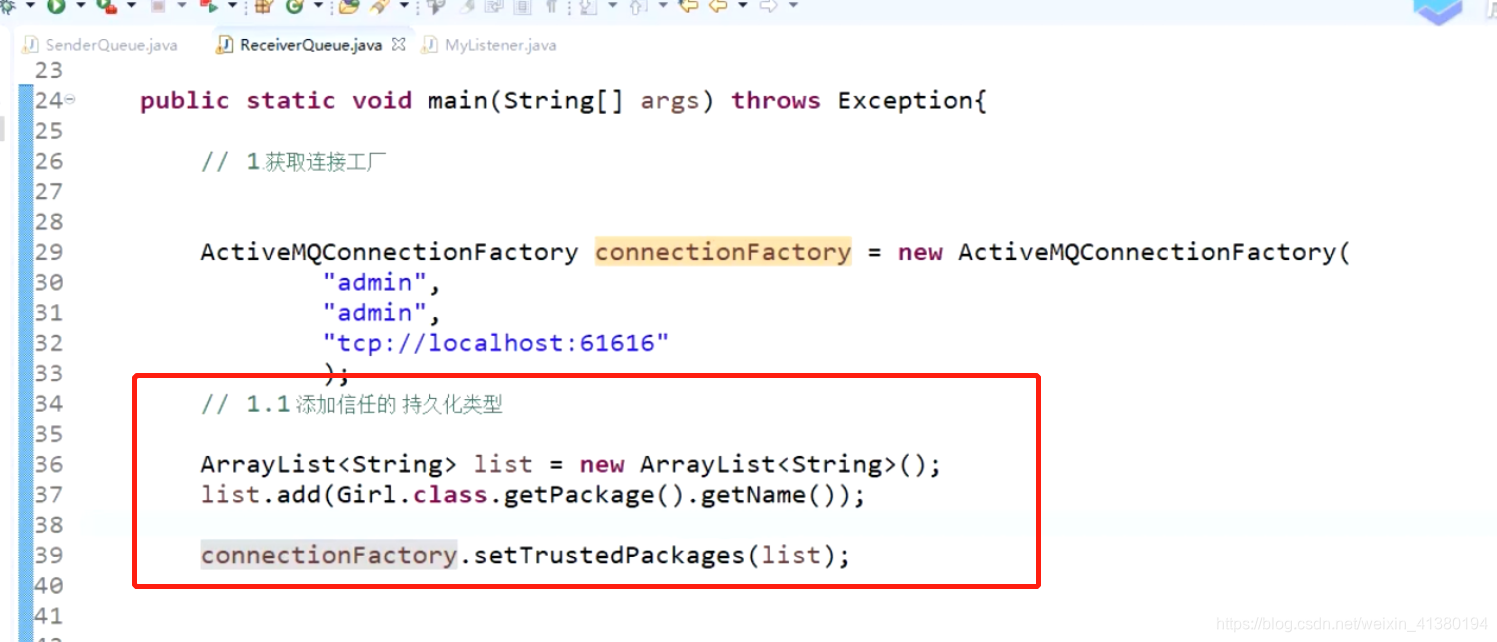
发送对象的序列化的时候,需要做信任。
消息进入死信队列:如果没有设置timetolive的话 queue会等到消费者消费后才会消失


虽然看上去消费了 ,但是这是假象 其实消费者没有消费(这是点对点测试。只有开启消费者才能出现上图情况,如果没有开启消费者就不会出现上述图的情况)
从死信队列中获取数据:
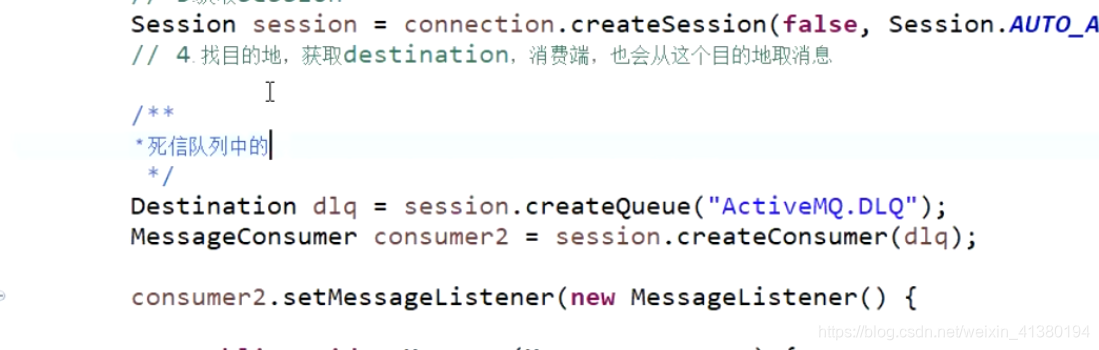

死信
此类消息会进入到ActiveMQ.DLQ队列且不会自动清除,称为死信
此处有消息堆积的风险
修改死信队列名称
<individualDeadLetterStrategy queuePrefix="DLxxQ." useQueueForQueueMessages="true" />
</deadLetterStrategy>
</policyEntry>
useQueueForQueueMessages: 设置使用队列保存死信,还可以设置useQueueForTopicMessages,使用Topic来保存死信
注意默认情况下:不持久化的消息不进入死信队列,一旦超过时间,从网页上看是消费了的,其实没人消费。如下图:

但是可以设置 :让非持久化的消息也进入死信队列
processNonPersistent=“true”
死信队列中的数据实是会持久化的。
过期消息不进死信队列配置:
如图:
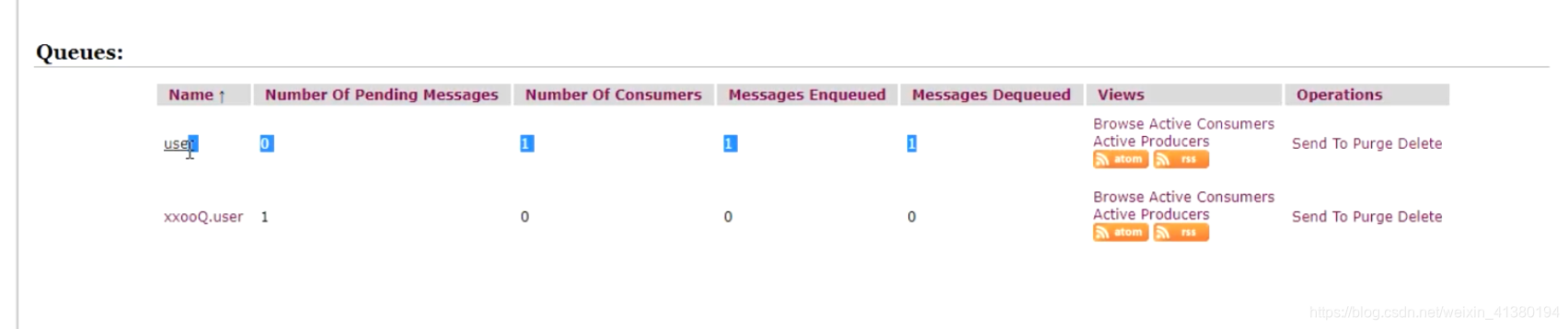
这个消息是持久化的,当过期以后 消息还在持久化的文件中,只有当消费者消费时,才会触发检查消息过期的机制,才会从持久化文件中删除,同时不会进入死信队列。
独占消费者 那个消费者先抢到那个就一直消费 除非这个消费者挂了,其他消费者其中的一个抢到后接着一直消费除非挂了
Queue queue = session.createQueue(“xxoo?consumer.exclusive=true”);
还可以设置优先级
Queue queue = session.createQueue(“xxoo?consumer.exclusive=true&consumer.priority=10”);
独占消费者保证了消费的顺序。
消息分组:其实就是定向分发消费 负载均衡
消息过滤 注意消息过滤不能根据消息体过滤 而是消息header过滤 所以写代码要注意:

消息发送
MapMessage msg1 = session.createMapMessage();
msg1.setString(“name”, “qiqi”);
msg1.setString(“age”, “18”);
msg1.setStringProperty("name", "qiqi");
msg1.setIntProperty("age", 18);
MapMessage msg2 = session.createMapMessage();
msg2.setString("name", "lucy");
msg2.setString("age", "18");
msg2.setStringProperty("name", "lucy");
msg2.setIntProperty("age", 18);
MapMessage msg3 = session.createMapMessage();
msg3.setString("name", "qianqian");
msg3.setString("age", "17");
msg3.setStringProperty("name", "qianqian");
msg3.setIntProperty("age", 17);
消息接收
String selector1 = "age > 17";
String selector2 = "name = 'lucy'";
MessageConsumer consumer = session.createConsumer(queue,selector2);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









