







Map

Entries and the Composition Pattern
As mentioned above, a map stores key-value pairs, called entries. An entry is actually an example of a more general object-oriented design pattern, the composition pattern, which defines a single object that is composed of other objects. A pair is the simplest composition, because it combines two objects into a single pair object.
To implement this concept, we define a class that stores two objects in its first and second member variables, respectively, and provides functions to access and update these variables. In Code Fragment 9.1, we present such an implementation storing a single key-value pair. We define a class Entry, which is templated based on the key and value types. In addition to a constructor, it provides member functions that return references to the key and value. It also provides functions that allow us to set the key and value members.
template<typename K, typename V>
class Entry { // a (key, value) pair
public:
Entry(const K &k = K(), const V &v = V()) // constructor
: key(k), value(v) {}
const K &key() const { return key; } // get key
const V &value() const { return value; } // get value
void setKey(const K &k) { key = k; } // set key
void setValue(const V &v) { value = v; } // set value
private:
K key; // key
V value; // value
};
Hash Tables
The keys associated with values in a map are typically thought of as “addresses” for those values. Examples of such applications include a compiler’s symbol table and a registry of environment variables. Both of these structures consist of a collection of symbolic names where each name serves as the “address” for properties about a variable’s type and value. One of the most efficient ways to implement a map in such circumstances is to use a hash table. Although, as we will see, the worst-case running time of map operations in an n-entry hash table is O(n). A hash table can usually perform these operations in O(1) expected time. In general, a hash table consists of two major components, a bucket array and a hash function.
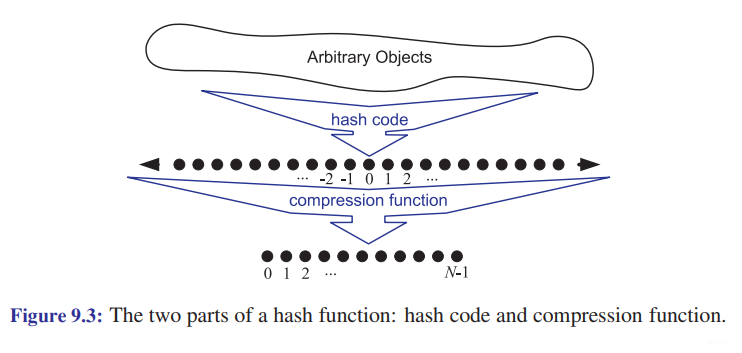
Compression Functions
- The Division Method
- The MAD Method(multiply add and divide)
Collision-Handling Schemes
- Separate Chaining
- Open Addressing
- Linear Probing and its Variants
Ordered Maps
In some applications, simply looking up values based on associated keys is not enough. We often also want to keep the entries in a map sorted according to some total order and be able to look up keys and values based on this ordering. That is, in an ordered map, we want to perform the usual map operations, but also maintain an order relation for the keys in our map and use this order in some of the map functions. We can use a comparator to provide the order relation among keys, allowing us to define an ordered map relative to this comparator, which can be provided to the ordered map as an argument to its constructor.

The ordered nature of the operations given above for the ordered map ADT makes the use of an unordered list or a hash table inappropriate, because neither of these data structures maintains any ordering information for the keys in the map. Indeed, hash tables achieve their best search speeds when their keys are distributed almost at random. Thus, we should consider an alternative implementation when dealing with ordered maps. We discuss one such implementation (Ordered Search Tables and Binary Search) next, and we discuss other implementations in Skip Lists and Search Trees (Binary Search Trees、AVL Trees、Splay Trees、(2,4) Trees、Red-Black Trees).
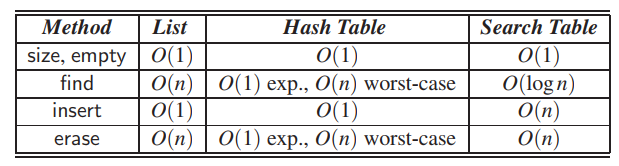
Comparing Map Implementations
Note that we can use an ordered search table to implement the map ADT even if we don’t want to use the additional functions of the ordered map ADT. Table 9.2 compares the running times of the functions of a (standard) map realized by either an unordered list, a hash table, or an ordered search table. Note that an unordered list allows for fast insertions but slow searches and removals, whereas a search table allows for fast searches but slow insertions and removals. Incidentally, although we don’t explicitly discuss it, we note that a sorted list implemented with a doubly linked list would be slow in performing almost all the map operations. (See Exercise R-9.5.) Nevertheless, the list-like data structure we discuss in the next section can perform the functions of the ordered map ADT quite efficiently.
leveldb使用Skip Lists的原因:
但red-black tree实现难度比Skip Lists大很多。
Although AVL trees and (2,4) trees have a number of nice properties, there are some map applications for which they are not well suited. For instance, AVL trees may require many restructure operations (rotations) to be performed after a removal, and (2,4) trees may require many fusing or split operations to be performed after either an insertion or removal. The red-black tree does not have these drawbacks, however, as it requires that only O(1) structural changes be made after an update in order to stay balanced.

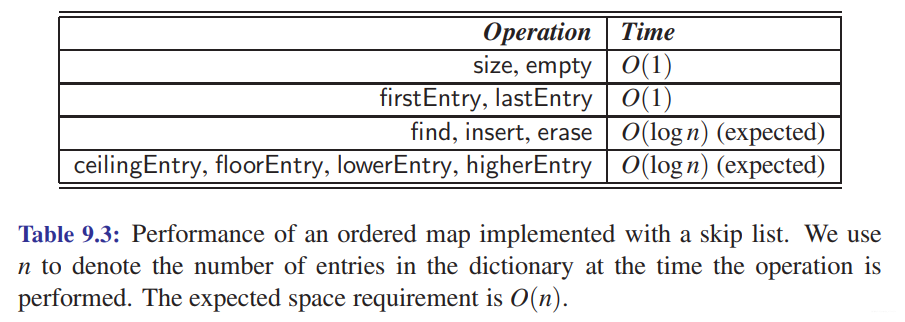
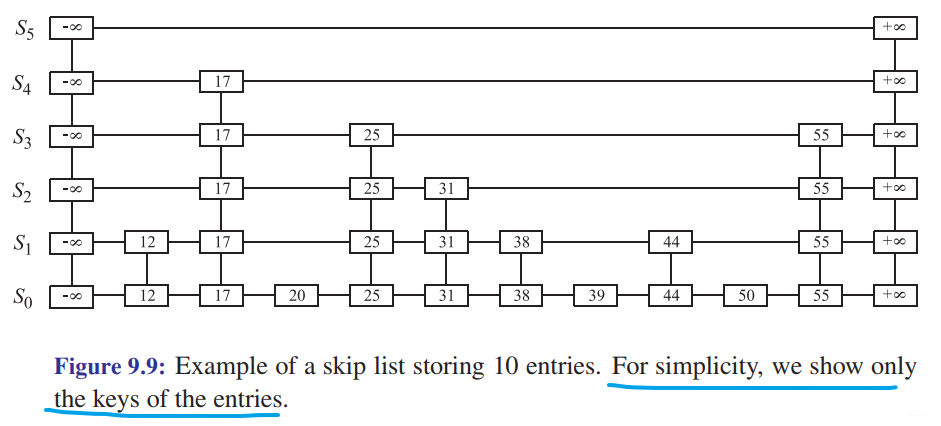
Skip Lists
An interesting data structure for efficiently realizing the ordered map ADT is the skip list. This data structure makes random choices in arranging the entries in such a way that search and update times are O(logn) on average, where n is the number of entries in the dictionary. Interestingly, the notion of average time complexity used here does not depend on the probability distribution of the keys in the input. Instead, it depends on the use of a random-number generator in the implementation of the insertions to help decide where to place the new entry. The running time is averaged over all possible outcomes of the random numbers used when inserting entries.
Because they are used extensively in computer games, cryptography, and computer simulations, functions that generate numbers that can be viewed as random numbers are built into most modern computers. Some functions, called pseudorandom number generators, generate random-like numbers, starting with an initial seed. Other functions use hardware devices to extract “true” random numbers from nature. In any case, we assume that our computer has access to numbers that are sufficiently random for our analysis.
The main advantage of using randomization in data structure and algorithm design is that the structures and functions that result are usually simple and efficient. We can devise a simple randomized data structure, called the skip list, which has the same logarithmic time bounds for searching as is achieved by the binary searching algorithm. Nevertheless, the bounds are expected for the skip list, while they are worst-case bounds for binary searching in a lookup table. On the other hand, skip lists are much faster than lookup tables for map updates.


Dictionaries
Like a map, a dictionary stores key-value pairs (k,v), which we call entries, where k is the key and v is the value. Similarly, a dictionary allows for keys and values to be of any object type. But, whereas a map insists that entries have unique keys, a dictionary allows for multiple entries to have the same key, much like an English dictionary, which allows for multiple definitions for the same word.
The ability to store multiple entries with the same key has several applications. For example, we might want to store records for computer science authors indexed by their first and last names. Since there are a few cases of different authors with the same first and last name, there will naturally be some instances where we have to deal with different entries having equal keys. Likewise, a multi-user computer game involving players visiting various rooms in a large castle might need a mapping from rooms to players. It is natural in this application to allow users to be in the same room simultaneously, however, to engage in battles. Thus, this game would naturally be another application where it would be useful to allow for multiple entries with equal keys.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









