







对关系型数据库产品(RDBMS)而言,一个重要特性就是:数据信息都被组织为二维数据表,信息的表达可以通过一系列的关联(Join)来完成。具体数据库产品在实现这个标准的时候,又有千差万别的特点。就是一个特定的数据库RDBMS产品,往往也提供不同的实现方法。
1、从堆表(Heap Table)到索引组织表(Index Organization Table)
Oracle作为一款成熟的数据库软件产品,就提供了多种数据表存储结构。我们最常见的就是三种,分别为堆表(Heap Table)、索引组织表(Index Organization Table,简称为IOT)和聚簇表(Cluster Table)。
Heap Table是我们在Oracle中最常使用的数据表,也是Oracle的默认数据表存储结构。在Heap Table中,数据行是按照“随机存取”的方式进行管理。从段头块之后,一直到高水位线一下的空间,Oracle都是按照随机的方式进行“粗放式”管理。当一条数据需要插入到数据表中时,默认情况下,Oracle会在高水位线以下寻找有没有空闲的地方,能够容纳这个新数据行。如果可以找到这样的地方,Oracle就将这行数据放在空位上。注意,这个空位选择完全依“能放下”的原则,这个空位可能是被删除数据行的覆盖位。
如果Heap Table段的HWM下没有找到合适的位置,Oracle堆表才去向上推高水位线。在数据行存储上,Heap Table的数据行是完全没有次序之分的。我们称之为“随机存取”特征。
对Heap Table,索引独立段的添加一般可以有效的缓解由于随机存取带来的检索压力。Index叶子节点上记录的数据行键值和Rowid取值,可以让Server Process直接定位到数据行的块位置。
聚簇(Cluster Table)是一种合并段存储的情况。Oracle认为,如果一些数据表更新频率不高,但是经常和另外一个数据表进行连接查询(Join)显示,就可以将其组织在一个存储结构中,这样可以最大限度的提升性能效率。对聚簇表而言,多个数据表按照连接键的顺序保存在一起。
通常系统环境下,我们使用Cluster Table的情况不太多。Oracle中的数据字典大量的使用聚簇。相比是各种关联的基表之间固定连接检索的场景较多,从而确定的方案。
最后就是本系列的IOT(Index Organization Table)。同Cluster Table一样,IOT是在Oracle数据表策略的一种“非主流”,应用的场景比较窄。但是一些情况下使用它,往往可以起到非常好的效果。
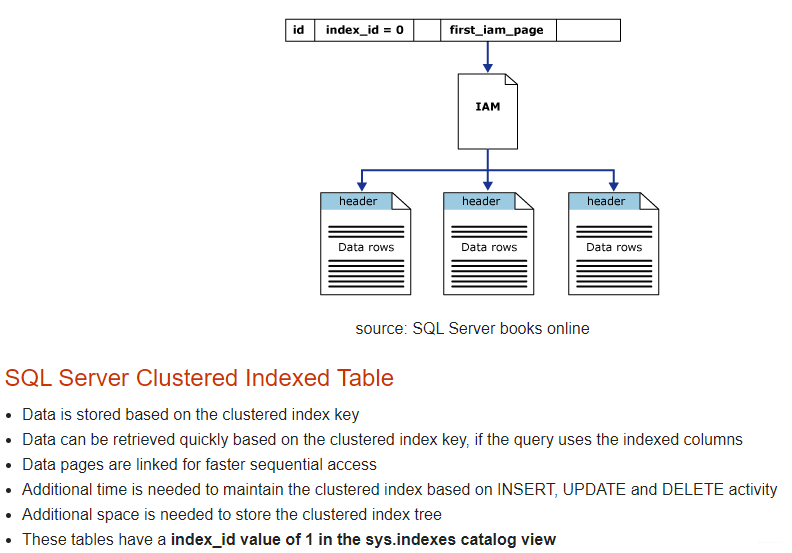
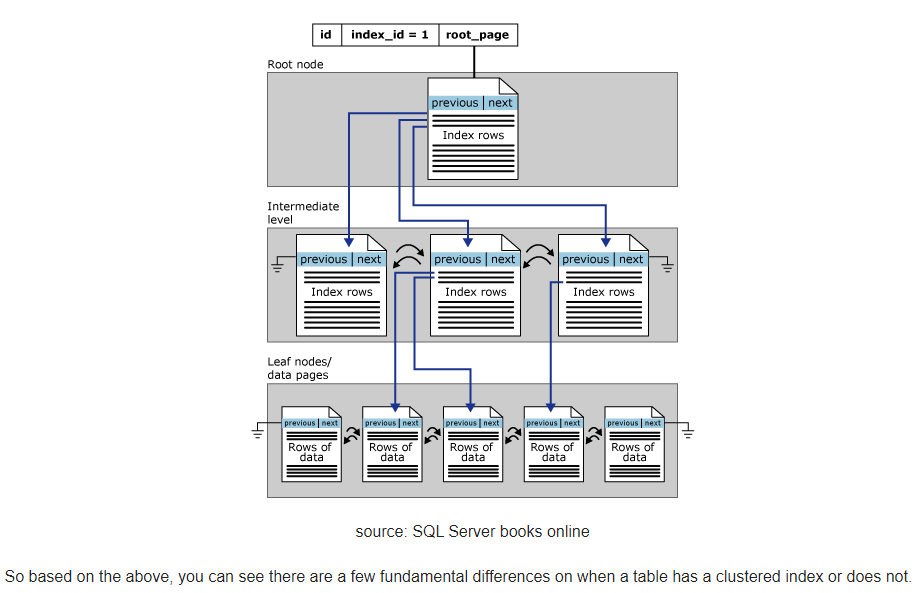
简单的说,IOT区别于堆表的最大特点,就在于数据行的组织并不是随机的,而是依据数据表主键,按照索引树进行保存。从段segment结构上看,IOT索引段就包括了所有数据行列,不存在单独的数据表段。
IOT在保存结构上有一些特殊之处,应用在一些特殊的场景之下。本系列将逐个分析IOT的一些特征,最后讨论我们究竟在什么样的场景下,可以选择IOT作为数据表方案。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









