




1、打开抖音APP
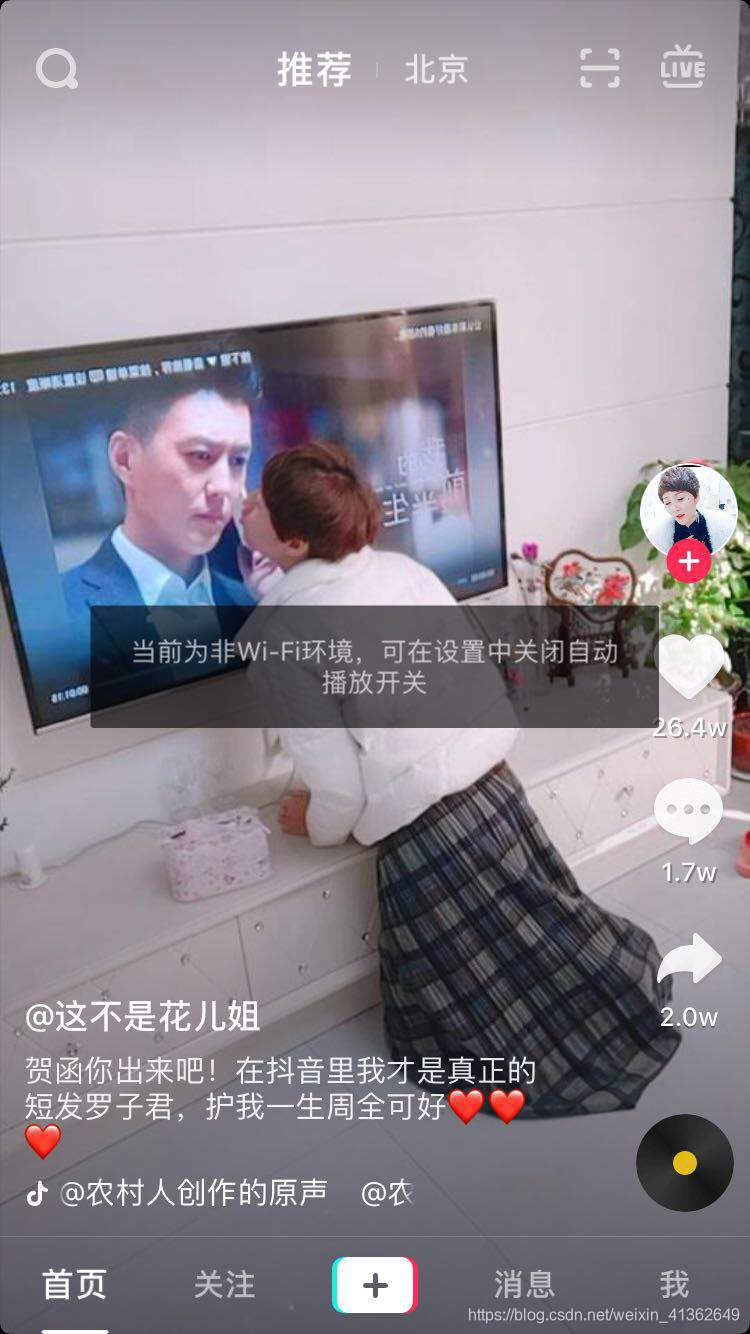
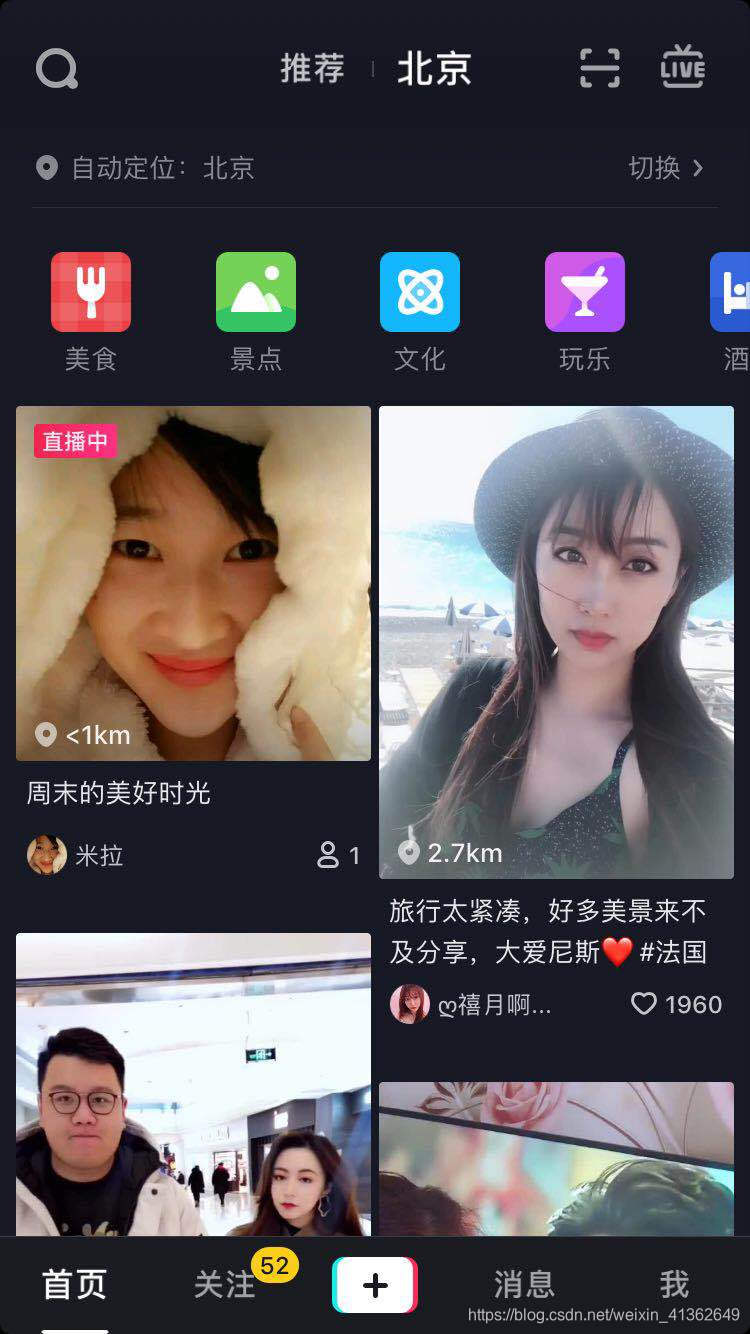
2、点开一个用户
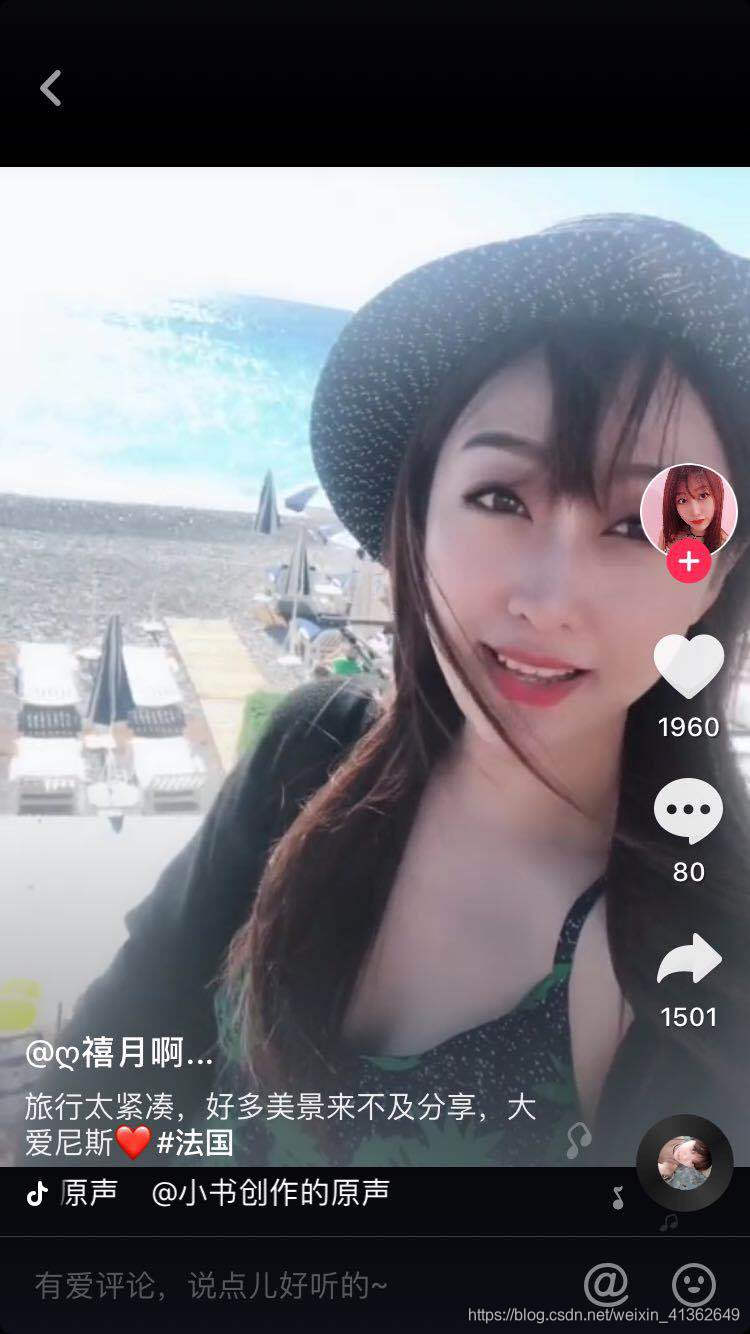
3、点击她的头像(带有+号的地方),查看它的主页
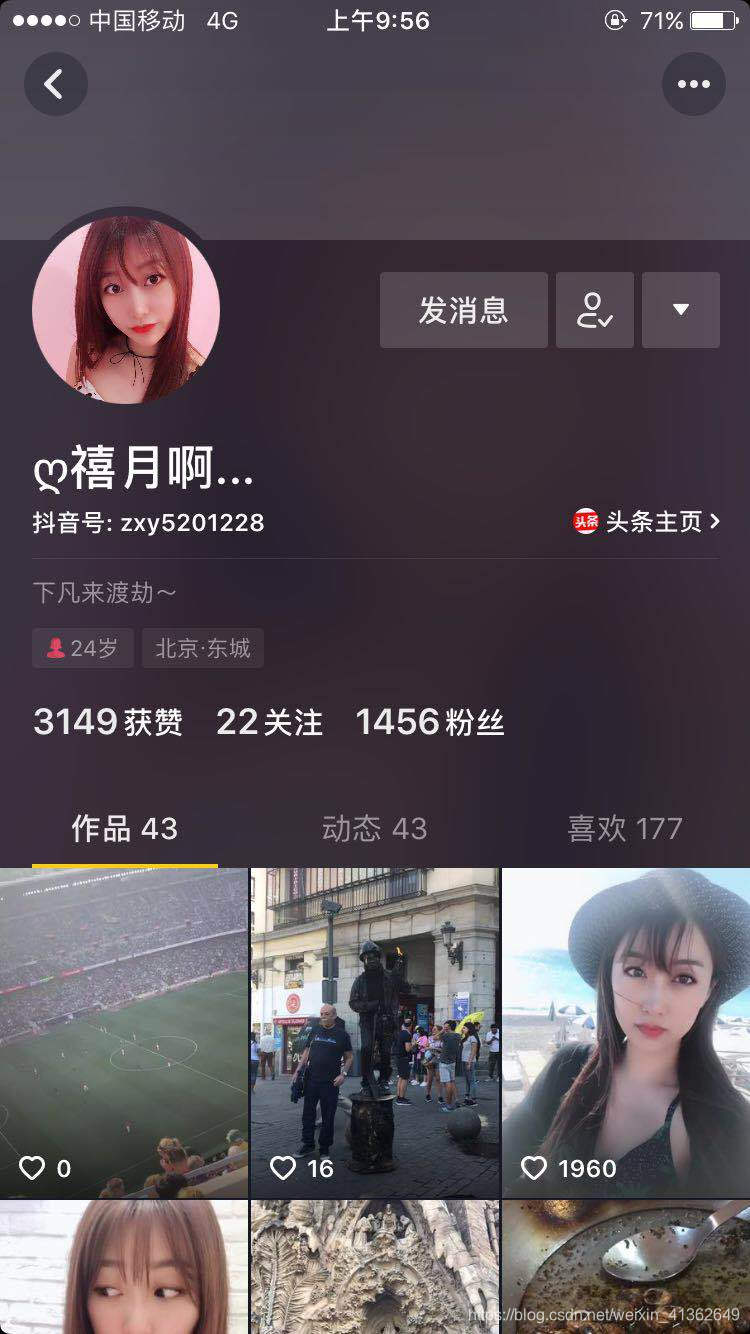
4、点击右上角,如下图所示:
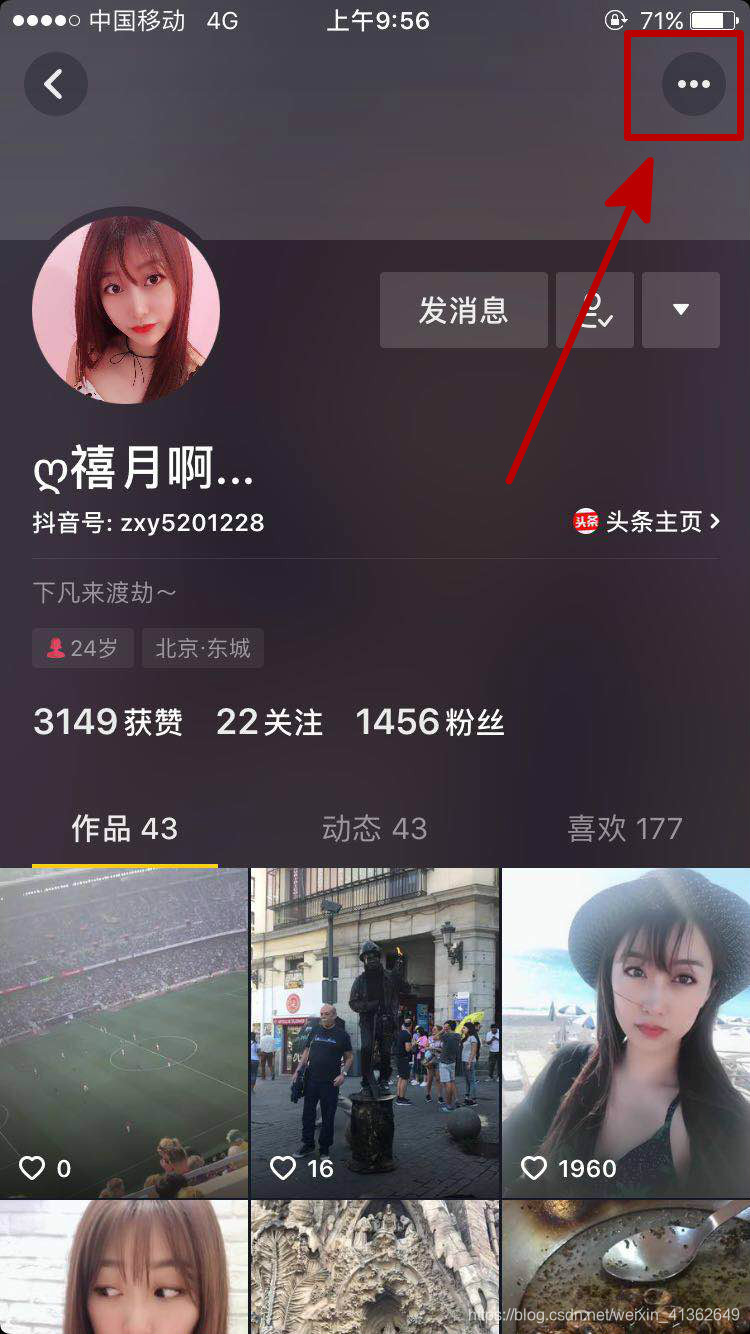
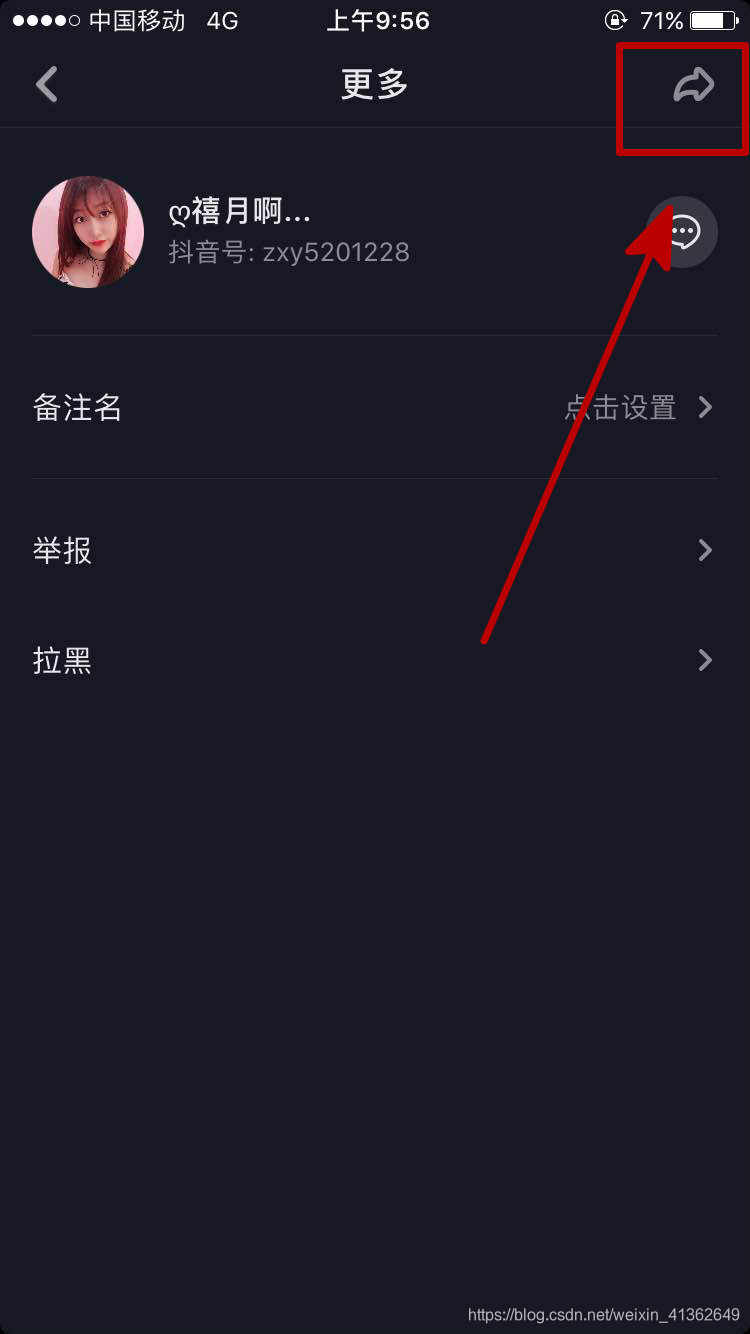
5、点击转发,右上角,如下图所示:
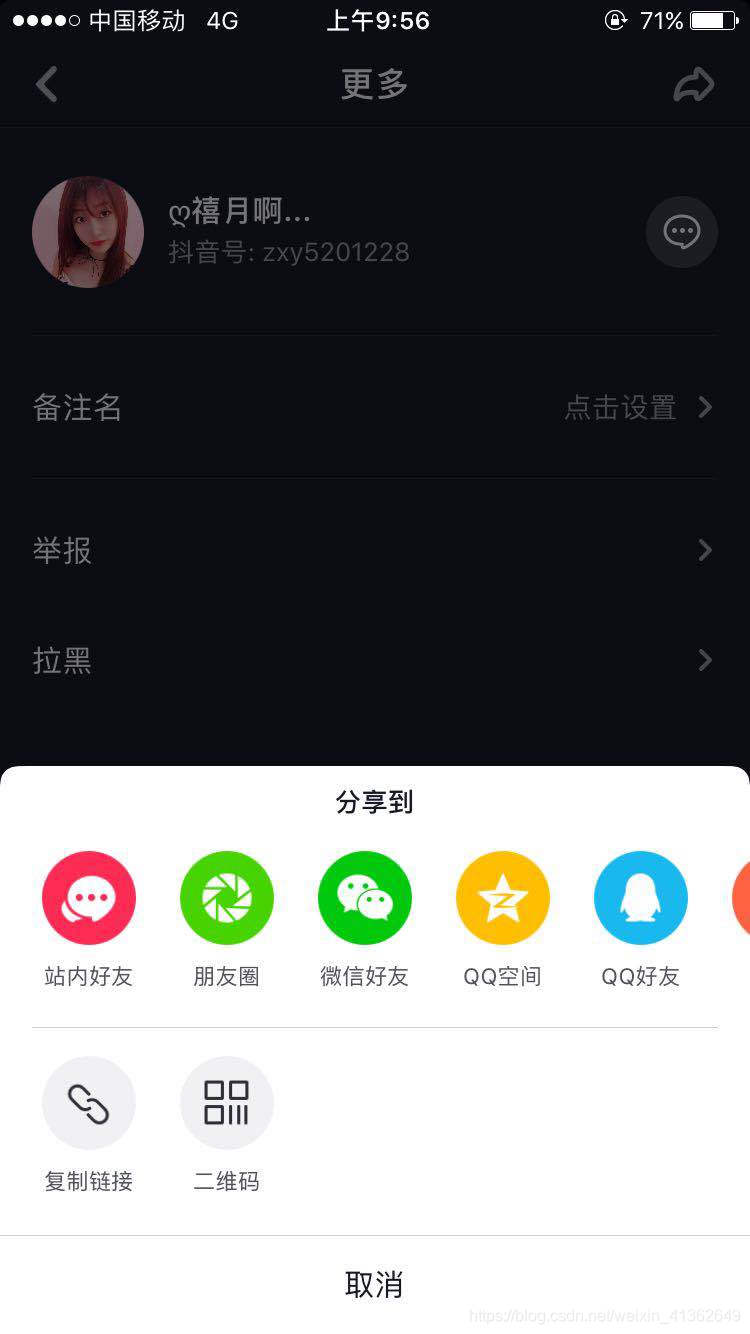
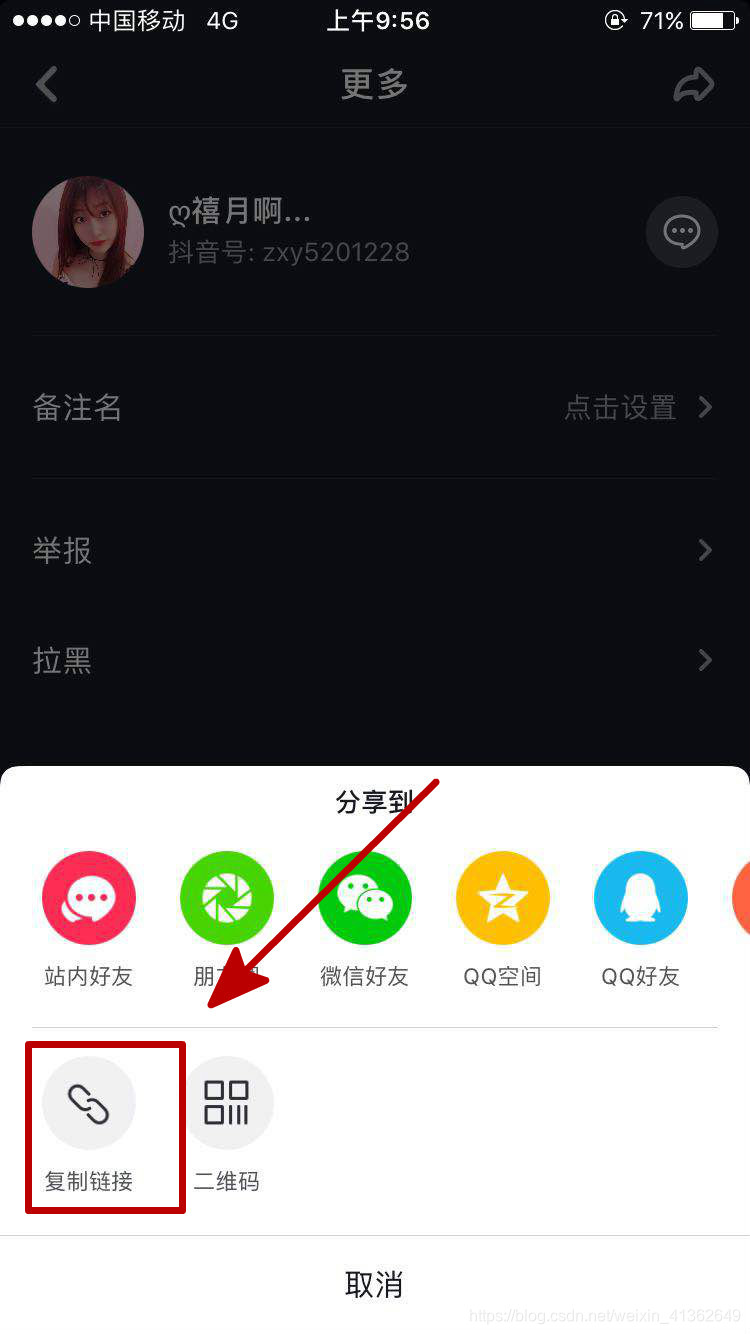
6、获取短连接,如下图所示:
7、把复制的短连接放到写好的代码里面,就可以爬取这个小姐姐所有的短视频啦,如下图所示:

8、等待一会,小姐姐所有的视频都会被下载下来,保存到demo里面设置好的文件夹下
9、这样就?啦
1、打开抖音APP
2、点开一个用户
3、点击她的头像(带有+号的地方),查看它的主页
4、点击右上角,如下图所示:
5、点击转发,右上角,如下图所示:
6、获取短连接,如下图所示:
7、把复制的短连接放到写好的代码里面,就可以爬取这个小姐姐所有的短视频啦,如下图所示:
8、等待一会,小姐姐所有的视频都会被下载下来,保存到demo里面设置好的文件夹下
9、这样就?啦
 5536
5536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























