



 本文深入探讨了Java集合框架的两个主要分支:Collection和Map。详细对比了HashMap与Hashtable的区别,并介绍了它们的工作原理。此外,还讨论了ArrayList、LinkedList、Vector等集合类的特点及使用场景。
本文深入探讨了Java集合框架的两个主要分支:Collection和Map。详细对比了HashMap与Hashtable的区别,并介绍了它们的工作原理。此外,还讨论了ArrayList、LinkedList、Vector等集合类的特点及使用场景。
java集合相关
首先java集合类主要有两大分支:
(1)Collection (2)Map
关系如下:
(1)Collection
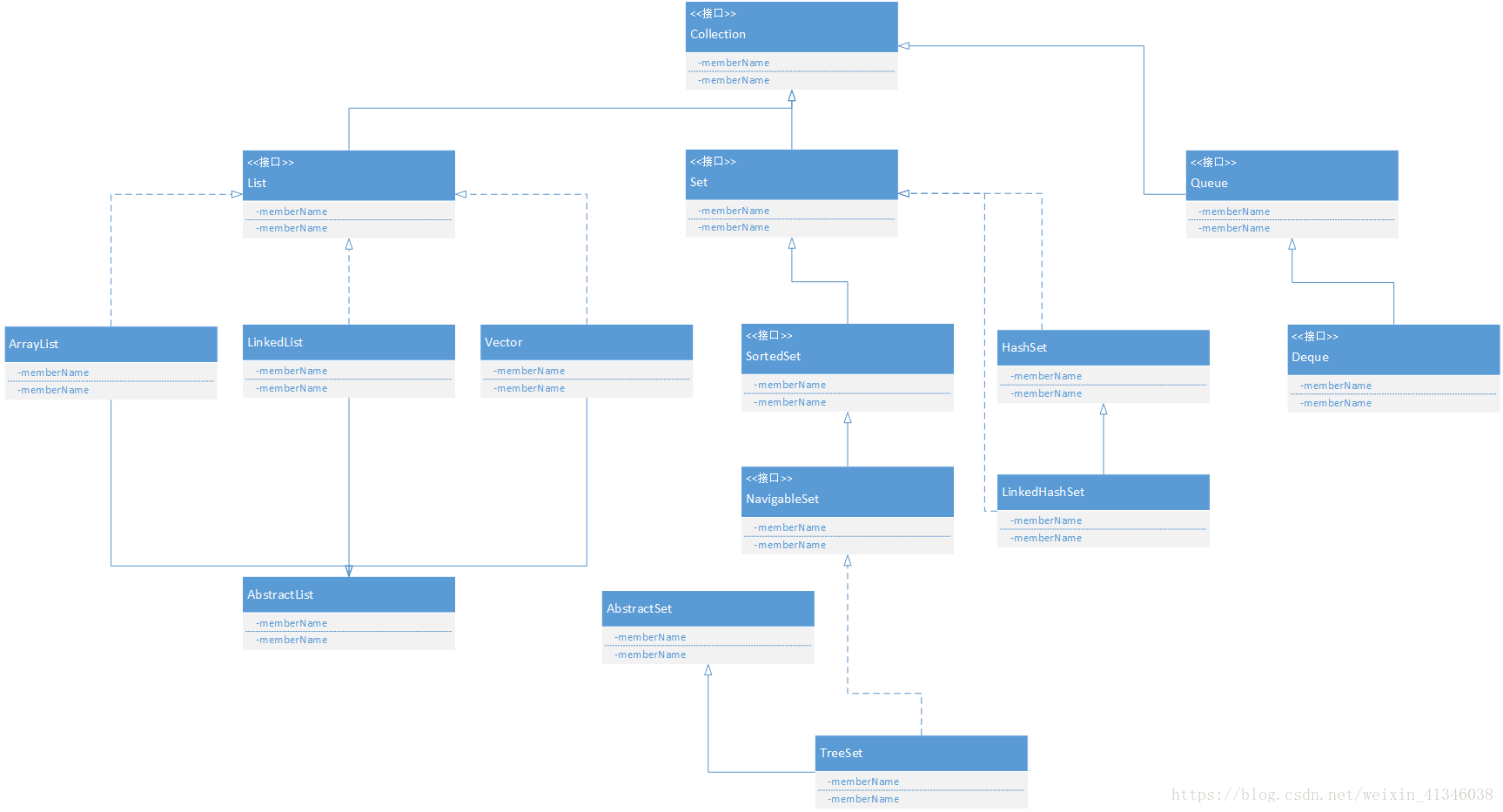
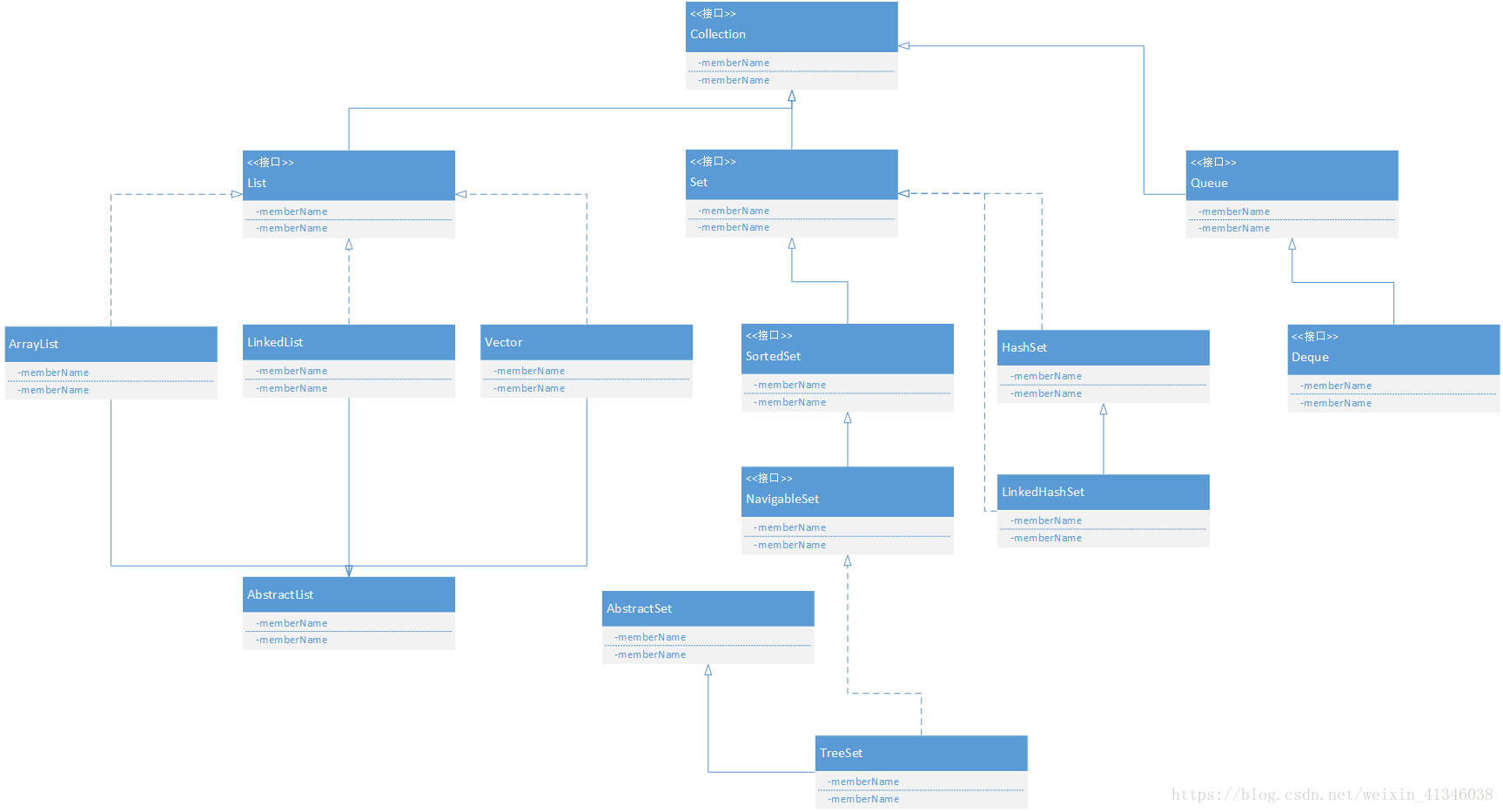
(2)Map
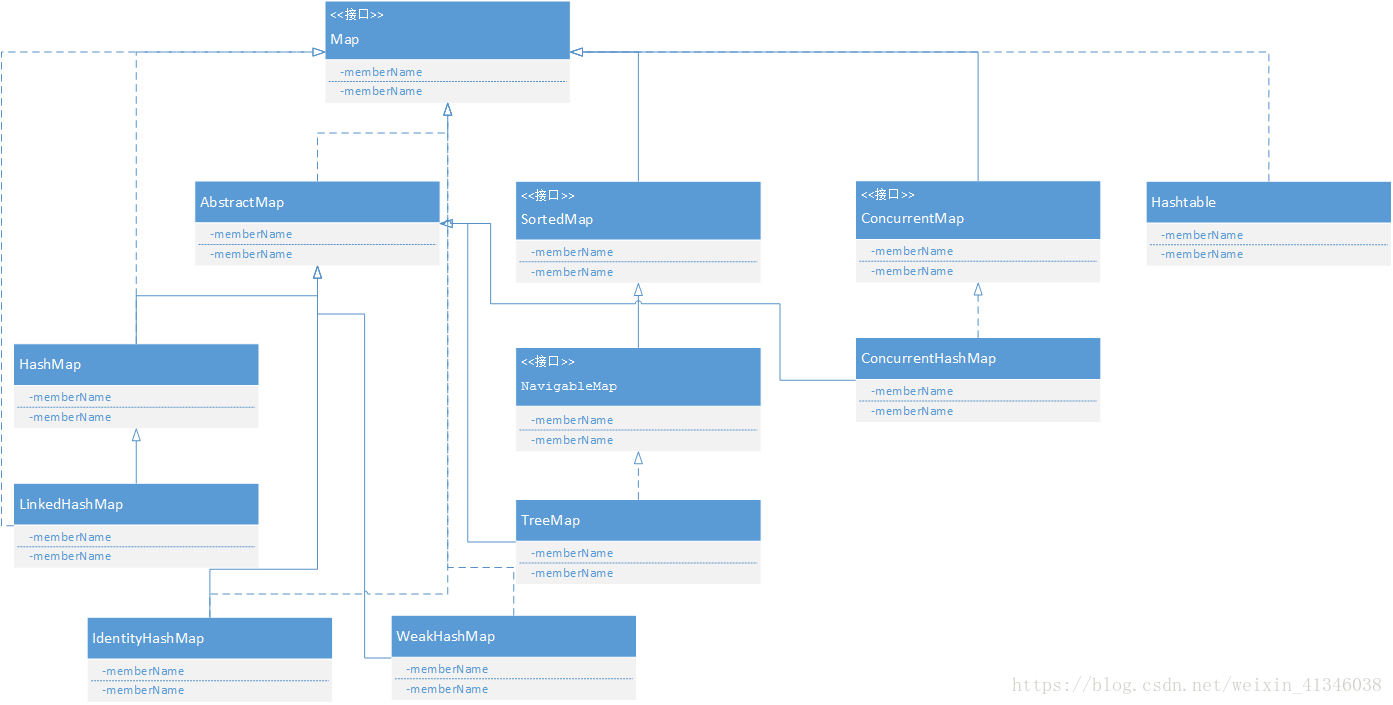
梳理顺序:先Map,后Collection
(1)HashMap和Hashtable
a.HashMap是线程不安全的,Hashtable是线程安全的,其线程安全是通过Synchronize实现
b.由于和这个原因,HashMap效率高于Hashtable
c.HashMap的键可以为null,Hashtable不介意
d.多线程时,也不推荐使用Hashtable,因为效 率低,HashMap配合Collection工具类使用可以实现线程安全。同时,还有CurrentHashMap可以选择,该类的线程安全使用Lock的方式实现,所以效率高于Hashtable
比较他们的不同之后,讲讲他们的原理
数组,链表,哈希表。各有优劣,数组在内存中连续,查找速度快,增删慢;链表充分利用了内存,存储空间不连续,首尾存储下一个节点的信息,所以寻址麻烦,查询速度慢,但是增删快;哈希表,则结合了两者的特点,一个哈希表,由数组和链表组成。假如一条链表有1000个节点,现在要查找最后一个几点没需要从第一个遍历到最后一个;如果用哈希表,将这条链表分为10组,用一个容量为10的数组存储10组链表的头结点,这样寻址就快了(a[0] = 0,a[1] = 100,a[2] = 200 ....).
HashMap实现原理就是上述原理了,当然具体实现还有很多其他东西。Hashtable同理,只不过做了同步处理
Hash碰撞,不同的key根据hash算法算出的值可能一样,如果一样就是Hash碰撞
优化措施:
(1)HashMap的库容代价非常大,要生成一个新的桶数组,然后要把所有元素重新落桶一次,几乎等于重新执行了一次所有元素的put。所以如果我们队map的大小有一个范围的话,可以再构造时给定大小,一般大小设置为:(int)(float)expectedSize/0.75F+1.0F).
(2)key的设计尽量简洁
HashMap的一些使用功能:
value去重:
对于HashMap而言,key不能重复,但是value可以重复,有时候需要将重复的部分去掉。
方法:将HashMap的key-value对调,然后复制给一个新的HashMap,由于key的不可重复性,此时就将重复值去掉。最后将新得到的HashMap的key-value再对调一次即可.
Demo:

HashMap线程同步:
①Map<Integer , String> hs = new HashMap<Integer , String>();
hs = Collections.synchronizedMap(hs);
②:ConcurrentHashMap<Integer , String> hs = new ConcurrentHashMap<Integer , String>();
Collection接口及其子类:
ArrayList , LinkedList , Vector
ArrayList和Vector本质都是用数组实现的,而LinkList是用双链表实现的;所以,ArrayList和Vector在查找效率上比较高,增删效率比较低;LinkedList则正好相反。ArrayList是线程不安全的,Vector是线程安全的,效率没有ArrayList高。实际上一般不怎么使用Vector,可以自己做线程同步,也可以用Collections配合ArrayList实现线程同步
去重:
第一种:用iterator遍历,遍历出来的放到一个临时List中,放之前用contains判断一下
第二种:利用set的不可重复性
Stack
Stack呢,是继承自Vector的,所以用法啊,线程安全什么的跟Vector都差不多,只是有几个地方需要注意:
第一:add()和push(),stack是将最后一个element作为栈顶的,所以这两个方法对stack而言是没什么区别的,但是,它们的返回值不一样,add()返回boolean,就是添加成功了没有;push()返回的是你添加的元素。为了可读性以及将它跟栈有一丢丢联系,推荐使用push。
第二:peek()和pop(),这两个方法都能得到栈顶元素,区别是peek()只是读取,对原栈没有什么影响;pop(),从字面上就能理解,出栈,所以原栈的栈顶元素就没了。
HashSet和TreeSet
Set集合类的特点就是可以去重,它们的内部实现都是基于Map的,用的是Map的key,所以知道为什么可以去重复了吧。
既然要去重,那么久需要比较,既然要比较,那么久需要了解怎么比较的,不然它将1等于2了,你怎么办?
比较是基于hascode()方法和equals()方法的,所以必要情况下需要重新这两个方法。

















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









