







对于MySQL层优化我一般遵从五个原则:
- 减少数据访问: 设置合理的字段类型,启用压缩,通过索引访问等减少磁盘IO
- 返回更少的数据: 只返回需要的字段和数据分页处理 减少磁盘io及网络io
- 减少交互次数: 批量DML操作,函数存储等减少数据连接次数
- 减少服务器CPU开销: 尽量减少数据库排序操作以及全表查询,减少cpu 内存占用
- 利用更多资源: 使用表分区,可以增加并行操作,更大限度利用cpu资源
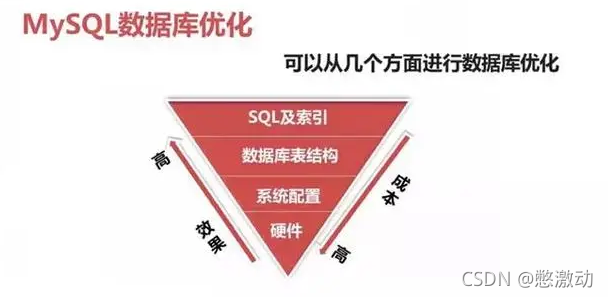
总结到SQL优化中,就三点:
- 最大化利用索引;
- 尽可能避免全表扫描;
- 减少无效数据的查询;
理解SQL优化原理 ,首先要搞清楚SQL执行顺序:
1)Mysql语法(书写)顺序,即当sql中存在下面的关键字时,它们要保持这样的顺序:
select[distinct]
from
join(如left join)
on
where
group by
having
union
order by
limit 2)Mysql执行顺序,即在执行时sql按照下面的顺序进行执行:
from
on
join
where
group by
having
select
distinct
union
order by sql语句通过 from 查找虚表,再通过 where 筛选数据 -> 分组 -> 聚合筛选 -> select 返回结果集 -> 去重 -> 排序
Mysql 逻辑架构
- 和其他数据库相比,MySql的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上 插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需求选择合适的存储引擎。
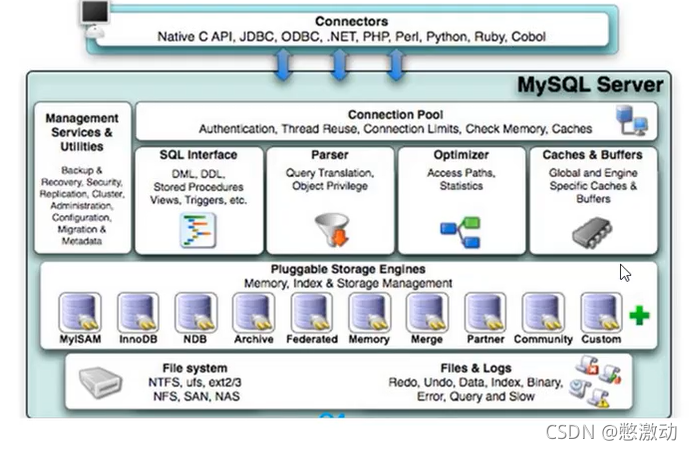
1.链接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。2.服务层
第二层架构主要完成大多少的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定查询列表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。3.引擎层
存储引擎层,存储引擎真正负责了Mysql中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。4.存储层
数据存储层,主要是将数据存储在运行与裸设备的文件系统之上,并完成与存储引擎的交互。存储引擎
##查看mysql现在已提供的存储引擎;
mysql>show engines;
##查看mysql当前默认的存储引擎;
mysql>show variables like '%storage_engine%';
Mysql存储引擎 -> MyISAM 和 InnoDB
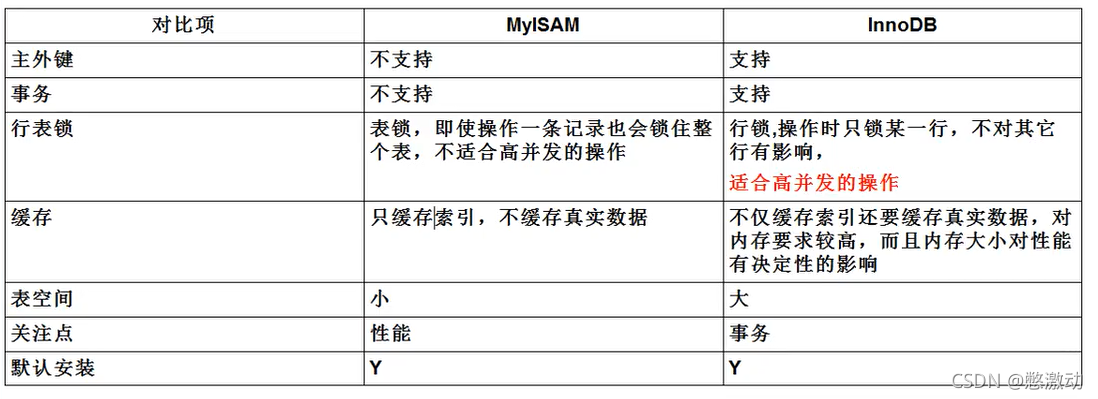
从上面可以看出,MyIsAm 偏向读,InnoDB 偏向写



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











