



 本文分享了使用Python3和urllib.request库爬取豆瓣电影榜单的全过程,从解决Python版本差异导致的findall()函数错误到get_page()函数的重写,再到中文乱码问题的处理,最后附上了完整代码及运行效果。
本文分享了使用Python3和urllib.request库爬取豆瓣电影榜单的全过程,从解决Python版本差异导致的findall()函数错误到get_page()函数的重写,再到中文乱码问题的处理,最后附上了完整代码及运行效果。
python爬虫学习记录(1)——————python3 应用urllib.request爬取网页数据
第一次尝试python爬虫,利用网上例子https://www.cnblogs.com/xiaoxi-3-/p/9029065.html 发现提示findall()函数错误,原因是因为我所应用的python3而该例子中使用的是python2 所以才会产生错误,改进方法如下:
html=str(html)
items = re.findall(pattern,html)
转换为str类型后运行成功。
第二个遇到的问题是python3 已经不在使用python2的requests包 改为使用urllib.requests包,因此需要对于get_page()函数进行重写,应改为如下形式
def get_page(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(req)
html = response.read()
type = sys.getfilesystemencoding
html = html.decode(type)
return html
这里有两个点要注意
1.header 使用的原因是:如果用 urllib.request.urlopen 方式打开一个URL,服务器端只会收到一个单纯的对于该页面访问的请求,但是服务器并不知道发送这个请求使用的浏览器,操作系统,硬件平台等信息,而缺失这些信息的请求往往都是非正常的访问,例如爬虫。有些网站验证请求信息中的UserAgent(它的信息包括硬件平台、系统软件、应用软件和用户个人偏好),如果UserAgent存在异常或者是不存在,那么这次请求将会被拒绝。所以可以尝试在请求中加入UserAgent的信息。
2.防止中文乱码:
type = sys.getfilesystemencoding
获取当前使用的字符类型
html = html.decode(type)
对内容进行编码
以上是一些重点的记录
下面是完整代码,用于爬取豆瓣电影榜单。
# -*- coding: utf-8 -*-
# @Time : 2018/5/12 上午11:37
# @Author : xiaoxi
# @File : test.py
import json
import re
import urllib.request
import sys
def get_page(url):
#使得能够正常访问url 此处采用火狐浏览器的header
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(req)
html = response.read()
#字符重编码
type = sys.getfilesystemencoding()
html = html.decode(type)
return html
def parse_page(html):
pattern = re.compile('<li.*?list-item.*?data-title="(.*?)".*?data-score="(.*?)".*?>.*?<img.*?src="(.*?)".*?/>', re.S)
html=str(html)
items = re.findall(pattern,html)
for item in items:
yield{
'title': item[0],
'score': item[1],
'image': item[2],
}
def write_to_file(content):
with open('xiaoxi.txt', 'a', encoding='utf-8')as f:
# print(type(json.dumps(content)))
#写入文件中
f.write(json.dumps(content,ensure_ascii=False))
def main():
url = "https://movie.douban.com/cinema/nowplaying/beijing/"
html = get_page(url)
print(html)
for item in parse_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
运行效果图
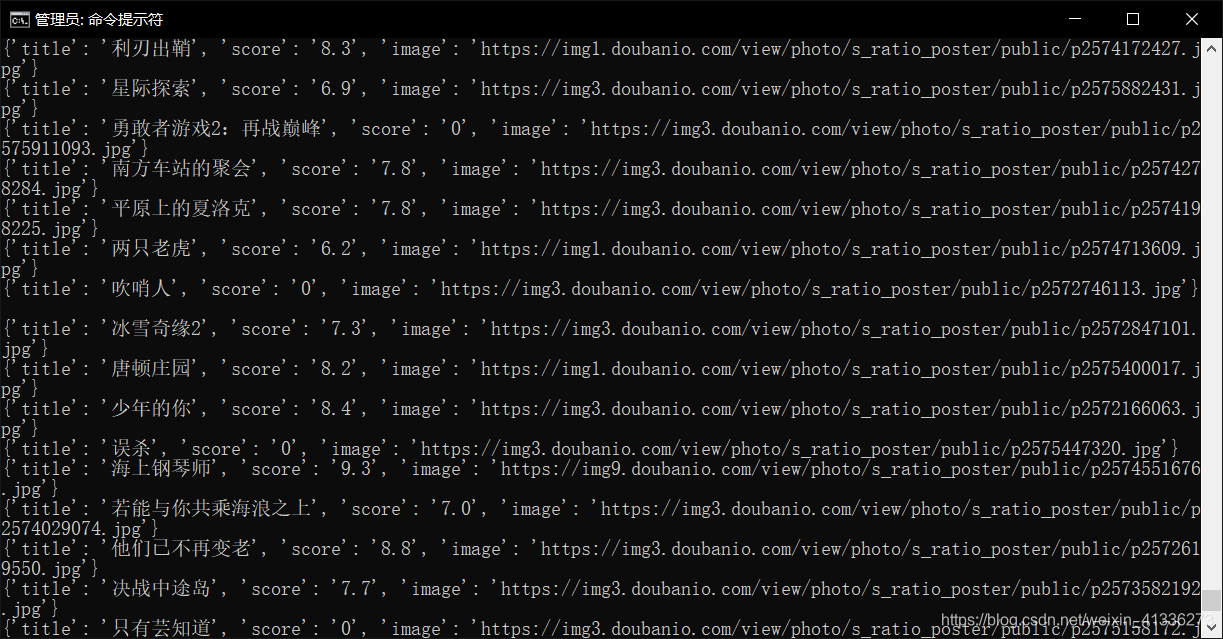
希望可以给你提供一定帮助!
参考网站:
1.https://www.cnblogs.com/xiaoxi-3-/p/9029065.html
2.https://www.cnblogs.com/hixiaowei/p/9721513.html
3.https://www.jb51.net/article/138184.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









