




当我们拿到一个题是海量数据问题,内存不能够同时处理,首先考虑特殊数据结构能否处理比如:位图和布隆过滤器。如果不能处理我们一般需要把大的文件哈西切割为几份,在分别处理。
- 哈希切割——top K问题
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?如何找到top K的IP?如何直接用Linux系统命令实现?
我的思路:100G大小的文件,而且里面存储的是ip字符串,所以内存一般不能够一次性处理,所以我们考虑特殊的数据结构位图,位图是专门处理整数存在与否问题,所以位图不可以,其次考虑布隆过滤器,他专门是处理字符串是否存在问题,所以也排除。所以我们一般需要采用哈希切割该文件,假设切割1000份文件(最好不要少于100,过少可能导致有更多的ip落入到相同文件,最终导致还是一个海量数据文件)。下面采用图示说明:
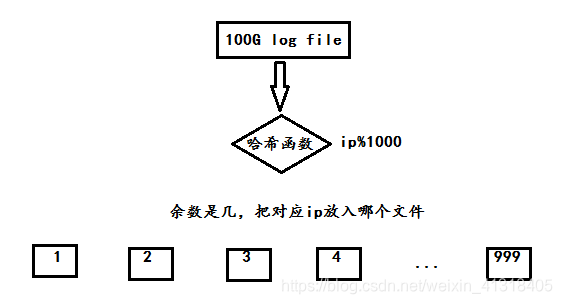
在对每一个文件进行哈希表统计每个ip地址出现的次数,最后选出最多出现的ip地址。
如果是top K,使用小堆得到最大的K个ip。Linux命令awk可以处理。
两个问题:(1)为什么使用哈希切割而不采用平均切割?因为哈希切割可以使相同ip地址落入同一个文件。(2)为什么求出现次数最多的几个ip采用小堆?因为先建立含有K个元素的小堆,然后如果剩余元素比堆顶大则交换,进行向下调整,以此类推得出出现次数最多的ip地址。
- 位图应用
给定100亿个整数,设计算法找到只出现一次的整数 ?
两种方法:
- 哈希切割(万能法)
- 位图
(1)哈希切割:把100个整数文件分为许多个小文件,然后每个小文件里面的数据到对应的搜索结构(平衡搜索树)中找对应整数是否存在,存在对应count加1,最后找到出现次数为1的整数。
(2)位图:这道题是一个三元信息(没出现/出现一次/出现多次),而位图是处理二元信息(存在/不存在)。表示三元信息最多需要两个比特位来标识:00表示没出现,01表示出现一次,11表示出现多次。所以我们可以需要两个位图分别表示这两个比特位,最终只需要两个位图异或,如果位置为1,则对应整数出现一次。
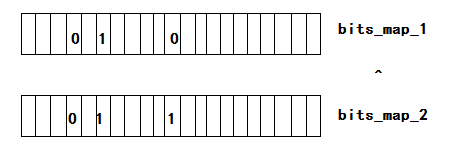
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
两种方法:
- 哈希切割两个文件,分别对应查找两个小文件
- 位图
(1)哈希切割两个文件,得到两个大文件对应的许多小文件,下面图示说明(小文件不只是6个):
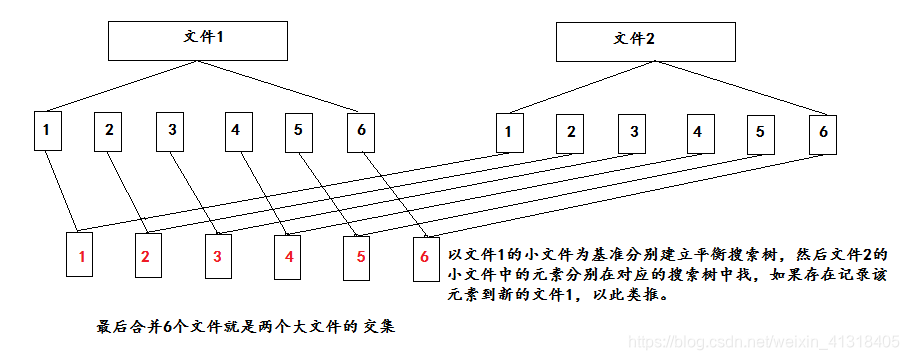
(2)位图:两个文件中元素关系可能出现四种情况所以是四元信息,元素在两个文件中都不存在(00),元素只存在于文件1(01),元素只存在于文件2(10),元素在两个文件中都存在(11)。同样我们需要两个位图来标识两位比特位。最终两个位图按位与,如果相应位置是1,则对应元素存在于两个文件。
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
同上,也可以使用位图,三元信息,只出现1次(00),出现两次(01),出现三次以上(11)。按位与如果为0,则记录该数字。
- 布隆过滤器应用
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
精确解法:哈希切割
近似解法:布隆过滤器,对第一个文件建立布隆过滤器,然后判断第二个文件元素是否已经存在于布隆过滤器。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











