










本次我们将从数据的流向和类型带大家深入spark
交叉原则
我们判断数据类型和传输时,可以遵循一个交叉原理来,具体实例如下:
(1)以会员积分的处理举例
此处的数据为:
会员编号,积分
1506001,587
1506002,115
1506003,56
1506004,614
1506005,290
1506001,79
1506004,15
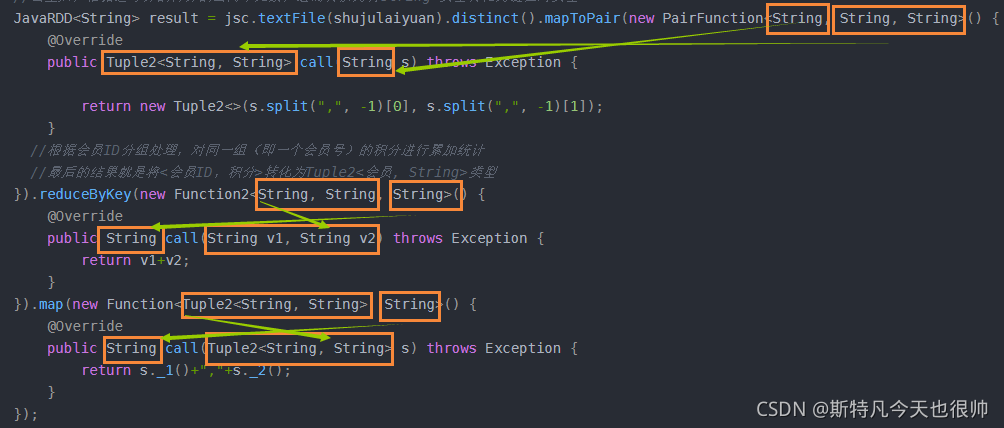
public class Test23 {
public static void main(String[] args) {
//jsc
JavaSparkContext jsc = SparkConfig.Instance("HuiYuanJiFen");
//获取文件
String shujulaiyuan = "/mulu2/zimulu2/zimulu22/huiyuanjifen.csv";
//去重后,根据逗号分割符分割出两个元素,进而转换为将String 类型转化为键值对类型
JavaRDD<String> result = jsc.textFile(shujulaiyuan).distinct().mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<>(s.split(",", -1)[0], s.split(",", -1)[1]);
}
//根据会员ID分组处理,对同一组(即一个会员号)的积分进行累加统计
//最后的结果就是将<会员ID,积分>转化为Tuple2<会员, String>类型
}).reduceByKey(new Function2<String, String, String>() {
@Override
public String call(String v1, String v2) throws Exception {
return v1+v2;
}
}).map(new Function<Tuple2<String, String>, String>() {
@Override
public String call(Tuple2<String, String> s) throws Exception {
return s._1()+","+s._2();
}
});
//写入文件
HdfsUtil.writeRddFile(result,"/mulu2/zimulu2/zimulu22/jifentongji.csv");
}
}
如图所示,数据类型的转换正好呈现一个交叉,所以我们在判断数据传输的时候,可以先查看下方函数返回类型,然后查看数据原本类型,再根据交叉原则对应起来,进而对应每个类型代表的数据字段含义和内容
mapToPair--------->String->Tuple<String, String>
reduceByKey----->String,String->String
map----------------->Tuple<String,String>->String


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









