







 本文详细介绍了深度优先和广度优先遍历的概念,并通过一个无向图的实例解释了遍历过程。在深度优先遍历中,从顶点A开始,依次访问B、C、D、E,使用递归或栈来实现。而广度优先遍历则使用队列,先访问A的所有邻接顶点,然后依次遍历它们的邻接顶点,确保一层一层地遍历整个图。
本文详细介绍了深度优先和广度优先遍历的概念,并通过一个无向图的实例解释了遍历过程。在深度优先遍历中,从顶点A开始,依次访问B、C、D、E,使用递归或栈来实现。而广度优先遍历则使用队列,先访问A的所有邻接顶点,然后依次遍历它们的邻接顶点,确保一层一层地遍历整个图。
以具体的例子来距离,假设我们现在有如下一个图:
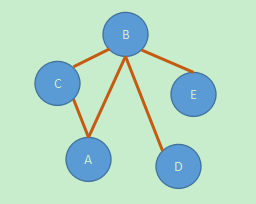
我们要遍历上述这个无向图,就需要用到深度优先和广度优先遍历了,图的邻接矩阵为:
[0, 1, 1, 0, 0]
[1, 0, 1, 1, 1]
[1, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
提一嘴邻接矩阵的意思吧,就是说 A到B是可达的,也就是1,A到C也是1,A到D并没有路线,所以A到D 是0,也就是(0,3)位置是0
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 1 | 1 | 0 | 0 |
| B | 1 | 0 | 1 | 1 | 1 |
| C | 1 | 1 | 0 | 0 | 0 |
| D | 0 | 1 | 0 | 0 | 0 |
| E | 0 | 1 | 0 | 0 | 0 |
深度优先遍历
假设我们遍历顶点的顺序是A B C D E,那么我们先从A开始,A的第一个邻接顶点是B,之后我们以B作为初始顶点,遍历B的第一个邻接节点C,之后以C为起始点,遍历C的第一个邻接顶点,但是发现A和B已经遍历过了,于是我们返回C的上一层也就是B,找到B在C的下一个邻接顶点,也就是D,之后再遍历D的首个邻接顶点。
上述是具体的步骤,思路如下:
- 从第一个顶点开始,找它的第一个邻接顶点
- 找到之后,判断是否被访问过,如果没有被访问过,我们以找到的邻接顶点为起点,继续找新起点的邻接顶点
- 如果被访问过,我们就去找这个邻接顶点的下一个顶点,比如 A到B,发现B被访问过了,那么我们就找A除了B之外的下一个邻接顶点
- 如果找不到邻接顶点了或者新的邻接顶点已被访问过,我们就回到这个邻接顶点的上一个,以此为起点找下一个邻接顶点 举个栗子,A接B,B除了A谁也没接,那么从A开始,先找到B,B再找,找不到了,那就回到A,用A找B的下一个邻接顶点,抽象来说就是找当前邻接顶点的下一个邻接顶点。
之后当前一个顶点找完之后,我们去找下一个没被访问过的顶点,开始遍历就好
以上面这个无向图为例
- 我们拿到A顶点,输出A
- 之后以A找到了B,这时,输出B
- 以B为初始,找B的邻接顶点,找到了C
- 输出C,在以C开始找C的邻接顶点
- 发现C的邻接顶点是A ,A被访问过了,找A的下一个,找到了B,B也被访问过了,之后发现没有C的邻接顶点了,我们就返回B
- 这时候B开始访问下一个邻接顶点D
- 我们以D为起始,发现这个D除了B谁也没连,B还是被访问过的,所以又退回B
- 这时候回到B,我们又去找到E,发现E未被访问过,我们进入E
- 输出E后发现E和D一样,是个羞涩的顶点,除了B没有其他邻接顶点,于是又返回B
- B终于没有邻接节点了,这时候它就返回回到A
- A也没了邻接顶点了,A顶点的深度优先遍历就完成了
- 这时候我们循环 A B C D E,如果没有被访问过,我们就以该顶点为起点,进行1-11步。
应该讲的很通透了吧…
接下来上代码,看代码逻辑应该也能看懂:
构建一个图
package com.nansl.graph;
import java.util.ArrayList;
import java.util.Arrays;
public class Graph {
// 存储顶点
private ArrayList<String> vertexList;
// 邻接矩阵存储图
private int[][] edges;
// 存储边的个数
private int edgeNum;
public static void main(String[] args) {
int n = 5;
String[] vertexes = {
"A", "B", "C", "D", "E"};
Graph graph = new Graph(n);
for (String vertex:
vertexes) {
graph.insertVertex(vertex);
}
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, < 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









