






1 hash 算法
Hash算法将任意长度的数据M映射成为固定长度的数据H(M),存在不同的key映射到同一个值的碰撞情况
2 一致性hash算法
一致性hash算法分布式数据存储数据,中每一个客户端维护一部分数据,并负责一部份区域的检索,从而实现整个网络的寻址与检索。
优点
(1)计算均匀。使用一致性hash算法,不同的key计算出来的结果是均匀的,不会出现集中分布的情况
(2)系统子资源消耗低。在新增数据节点之后,需要进行数据的重新分配,但是这种数据的分配只会出现在将现有节点的数据转移到新增节点之上,而不会出现将现有节点的数据转移到老数据节点的情况。这样的好处就是尽量保证现有数据的位置不变,从而减少数据再分配过程中对系统性能的消耗。
技术细节
使用常用的hash算法将key映射到一个具有232次方个桶空间中,即0-(232-1)的数字空间中。
(1)存储节点
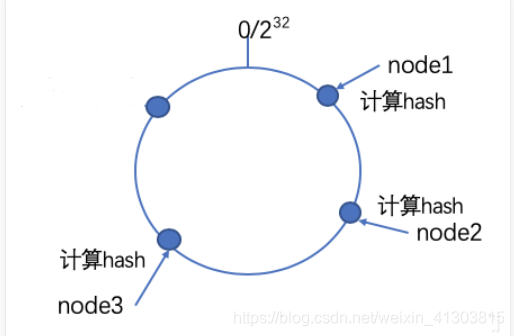
列出虚拟的圆环,上面有0-232个节点位置(0~232-1)。算法首先需要计算出存储节点在圆环上的位置。具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。
现假设有4个存储节点:node1,node2,node3,node4
根据物理节点的ip地址计算hash值,确认在闭环上的位置
Hash(NODE1-ip) = KEY1;
Hash(NODE2-ip) = KEY2;
Hash(NODE3-ip) = KEY3;
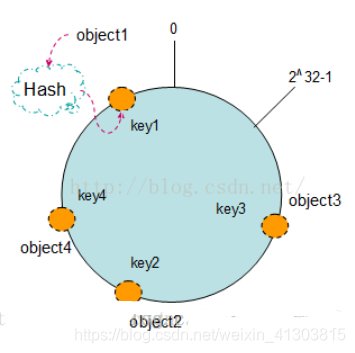
(2)数据key计算
现存储4段数据,根据hash计算数据在闭环位置
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4
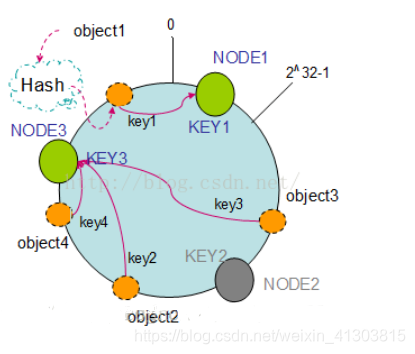
数据在闭环上存储的节点寻找方式为:根据hash值按照顺时针存储在第一个物理节点中
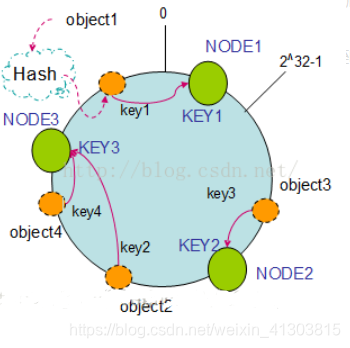
上图为例,数据object的hash闭环位置顺时针寻找,第一个节点为Node1,object1存入Node1。
按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中
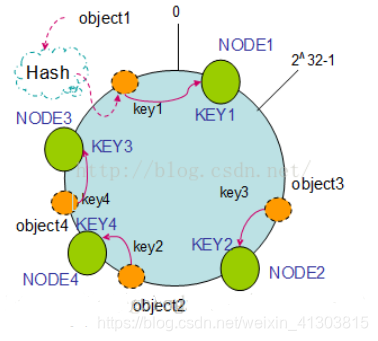
(3)节点新增
再新增物理节点后,每个节点负责维护某一段区域的数据,数据只会更新到新节点中而不会更改老节点的数据存储
如下图,增加新的节点Node4 后 ,计算hash闭环位置
此时,按照数据顺时针存储物理节点,object1、object3、object4不改变数据存储节点,只有节点object2应存储在新节点node4中,此时将object2的数据存储在新增节点node4中,不改变老节点node3的数据状态
(4)节点删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动
(5)平衡性–虚拟节点
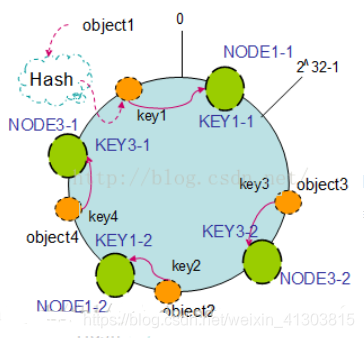
如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就造成了非常不平衡的状态。在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。
——“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一个实际节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
以上面只部署了NODE1和NODE3的情况(NODE2被删除的图)为例,之前的对象在机器上的分布很不均衡,现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:
Java实现
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 不带虚拟节点的一致性Hash算法
* 重点:1.如何造一个hash环,2.如何在哈希环上映射服务器节点,3.如何找到对应的节点
*/
public class ConsistentHashingWithoutVirtualNode {
public static void main(String[] args) {
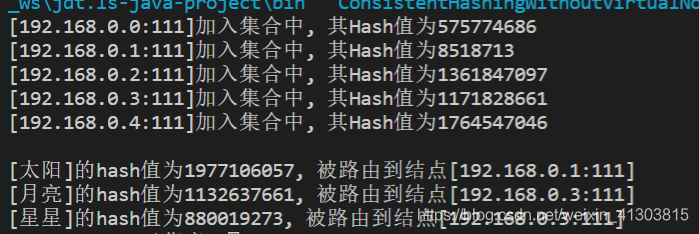
String[] keys = {"太阳", "月亮", "星星"};
for(int i=0; i<keys.length; i++)
System.out.println("[" + keys[i] + "]的hash值为" + getHash(keys[i])
+ ", 被路由到结点[" + getServer(keys[i]) + "]");
}
//待添加入Hash环的服务器列表
private static String[] servers = { "192.168.0.0:111", "192.168.0.1:111",
"192.168.0.2:111", "192.168.0.3:111", "192.168.0.4:111" };
//key表示服务器的hash值,value表示服务器
private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();
//程序初始化,将所有的服务器放入sortedMap中
static {
for (int i=0; i<servers.length; i++) {
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();
}
//得到应当路由到的结点
private static String getServer(String key) {
//得到该key的hash值
int hash = getHash(key);
//得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap = sortedMap.tailMap(hash);
if(subMap.isEmpty()){
//如果没有比该key的hash值大的,则从第一个node开始
Integer i = sortedMap.firstKey();
//返回对应的服务器
return sortedMap.get(i);
}else{
//第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
//返回对应的服务器
return subMap.get(i);
}
}
//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
}

















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









