




第一章 什么是大语言模型
1.1 概念
大语言模型(Large Language Model, LLM)是一种基于人工智能(AI)和深度学习(DL)的自然语言处理(NLP)模型,能够理解、生成和操作人类语言。这类模型通过海量文本数据训练,学习语言的统计规律、语义关系和上下文信
息,从而完成各种语言相关任务。
1.2 工作机制
大语言模型每一步推理过程本质是一个概率预测过程,即根据输入内容预测最有可能的下
一个字符(Token)。让大语言模型学习预测下一个字符能力的过程就是大模型的训练过程。
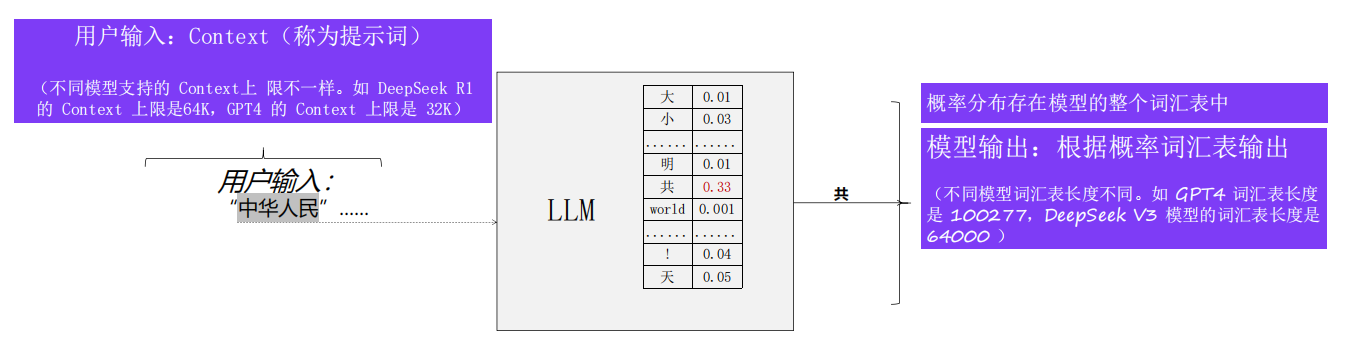
1.3 大语言模型(LLM)的训练
1.3.1 训练整体流程
大语言模型的训练分为预训练、后训练、应用模型三个阶段。通过预训,形成基础模型,再此基础模型上,选择合适的后训练技术,得到应用模型。
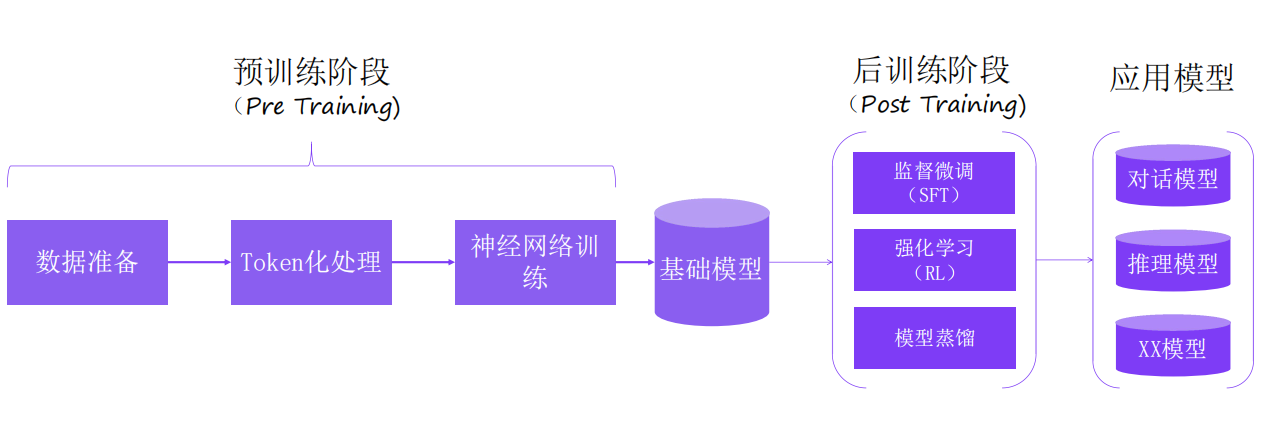
1.3.2 训练关键步骤的原理
1、数据准备
原始大模型数据集来自于FineWeb(高质量网络文本数据集)。FineWeb 的初始数据来自96个 CommonCrawl 镜像(使用WARC格式数据)44TB文本数据。

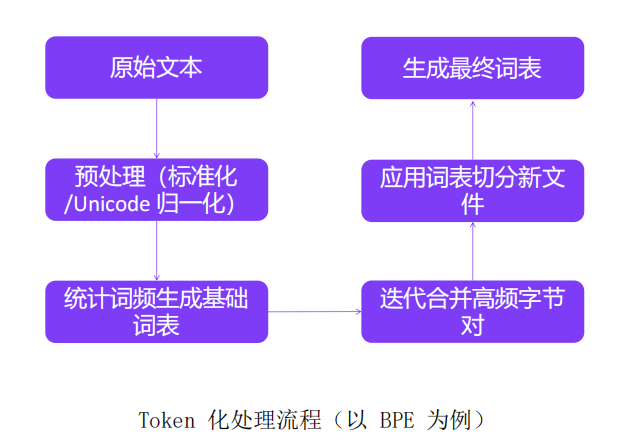
2、Token 化处理
Token 化处理是将原文本分割成可处理的离散单元(Token)。
Token化处理的关键作用:第一,影响模型的计算效率(Token数量≈计算量);第二,决定语言覆盖能力(尤其对非英语文本);第三,间接影响模型性能(不合理的切分会导致语义损失)。
3、神经网络训练
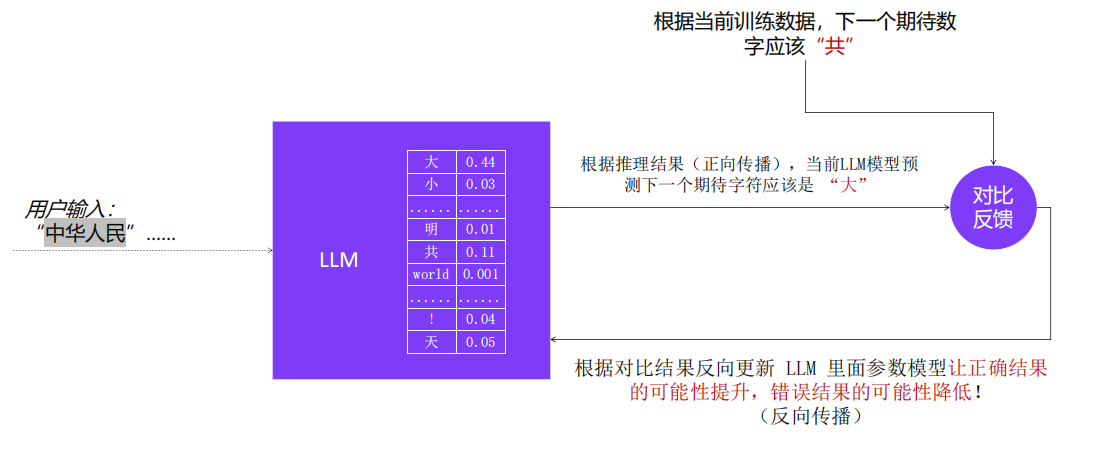
以上训练过程在庞大的预训练数据集上反复执行,不断迭代 LLM 内的参数值,以此不断缩小正向传播推理结果和预期值之间的概率差距。
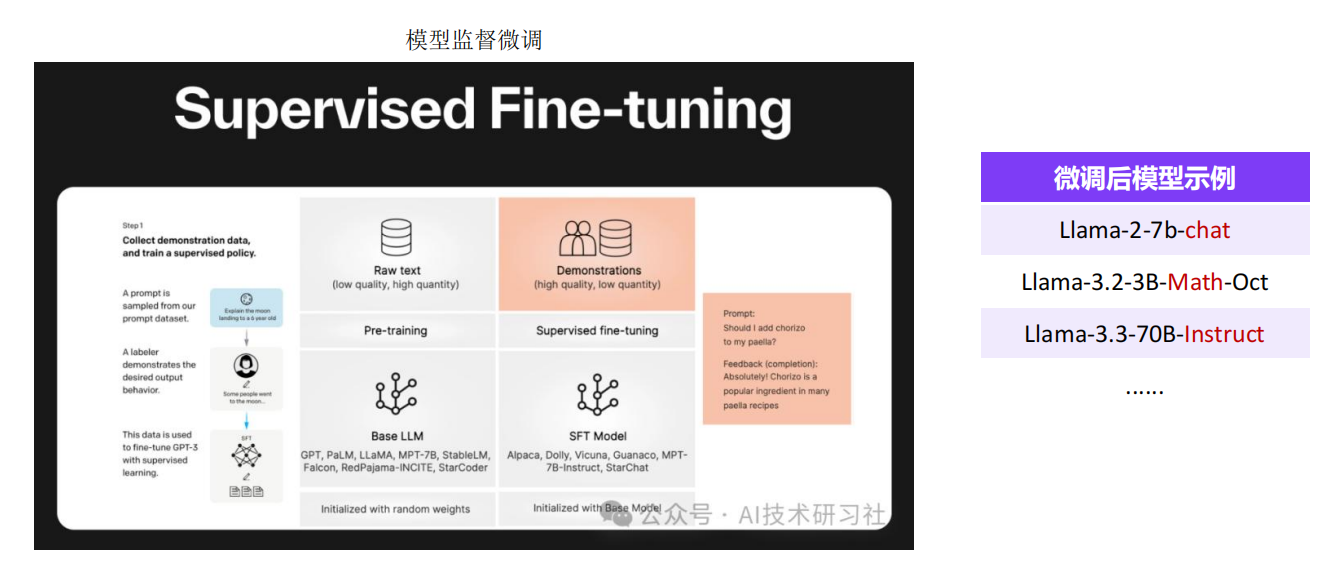
4、模型微调
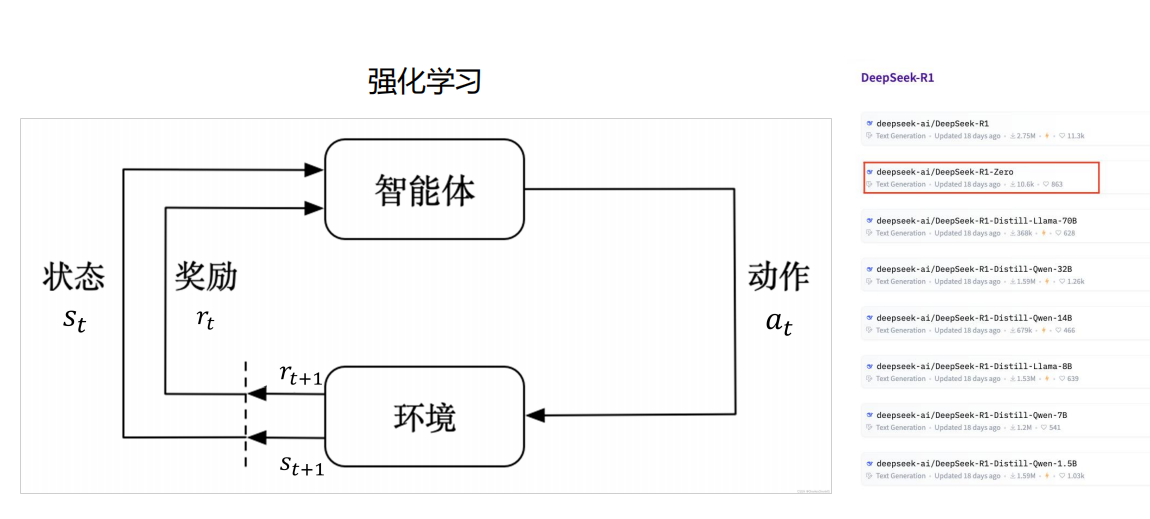
5、强化学习
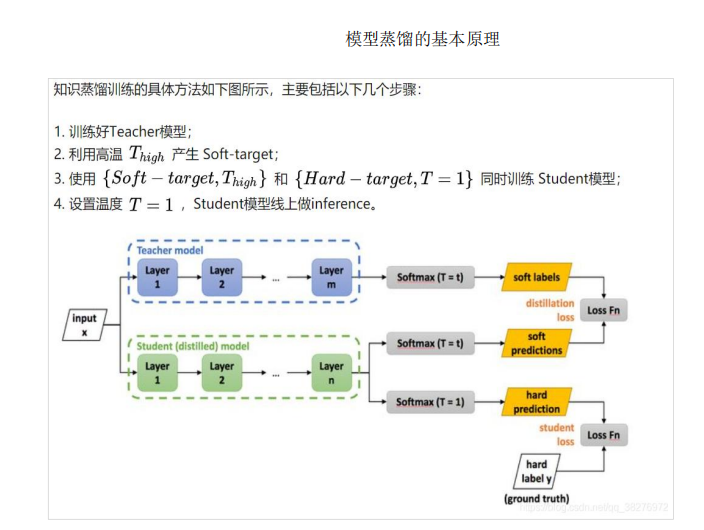
6、模型蒸馏
模型蒸馏是一种将大型复杂模型(教师模型)的知识迁移到轻量级模型(学生模型)的技术,模型蒸馏在保持效率的同时,实现了知识的有效传递。
第二章 RAG技术及原理
RAG 是 “Retrieval-Augmented Generation” 的缩写,中文可以翻译为“检索增强生成”。这是一种结合了检索(Retrieval)和生成(Generation)的自然语言处理技术,用于提高语言模型在特定任务上的性能和准确性。在加上一个数据向量和索引的工作,我们对 RAG 就可以总概方式地理解为“ 索引、检索和生成 ”。
(1)检索(Retrieval):在这个阶段,模型会从预先构建的大规模数据集中检索出与当前任务最相关的信息。这些数据集可以是文档、网页、知识库等。
(2)生成(Generation):在检索到相关信息后,模型会使用这些信息来生成答案或完成特定的语言任务。这个阶段通常涉及到序列生成技术,如基于 Transformer 的模型。
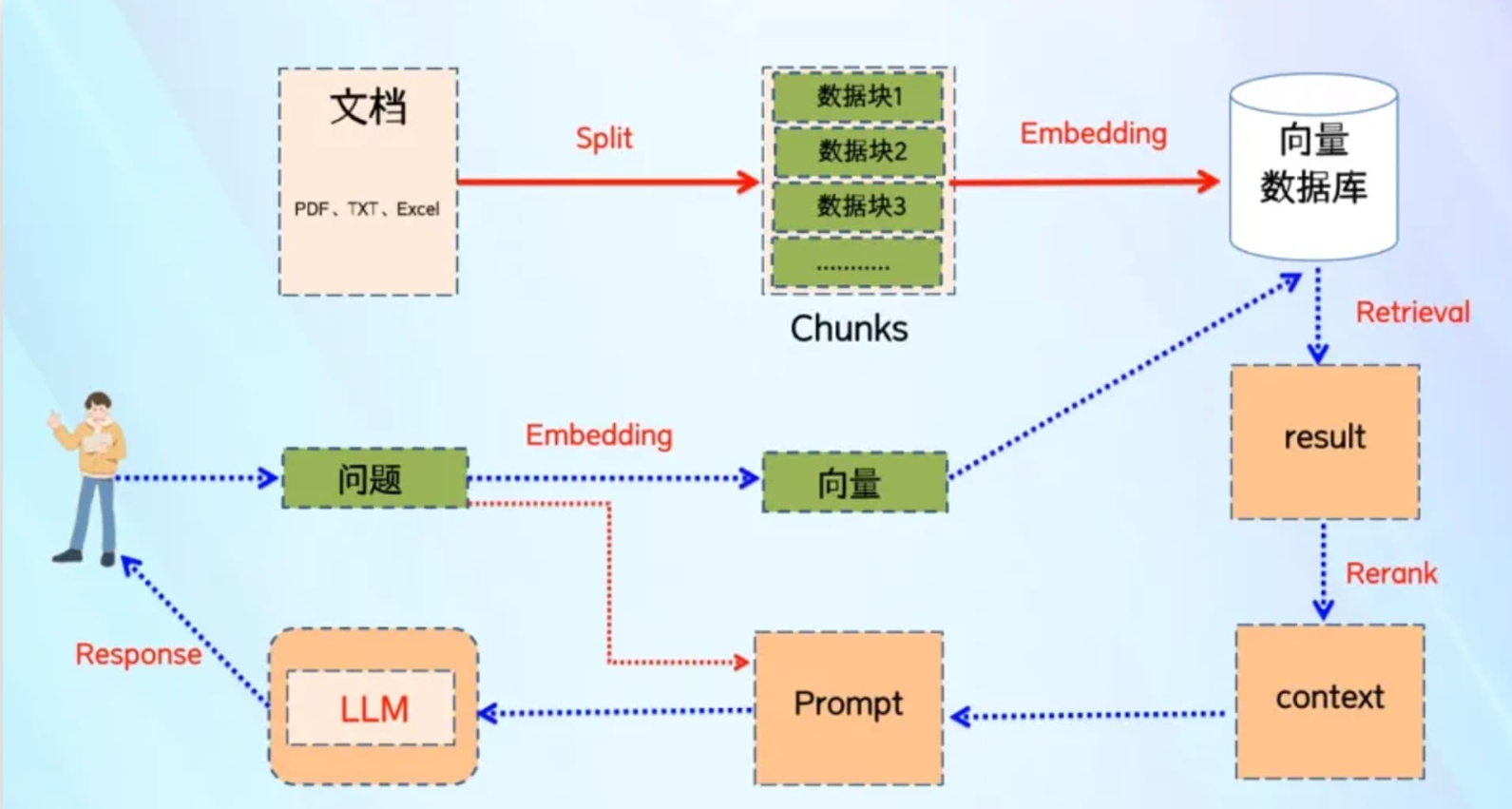
(1)创建索引:将输入的文档切割成不同的数据块,进行向量化处理后,存储到向量数据库,并创建索引。
(2)向量检索:将用户的提问信息向量化,再到向量数据库进行搜索,根据向量相似度的算法,寻找相关性最强的文档片段
第三章 大模型+RAG的私有化应用部署方法(云上部署)
3.1 总体方案
以下介绍本地部署总体方案,本地算力设备不满足条件时,也可以采用云上部署的方案。以接入DeepSeek 大模型为示例,也可以接入其他大模型,如kimi、讯飞星火、千山等等。
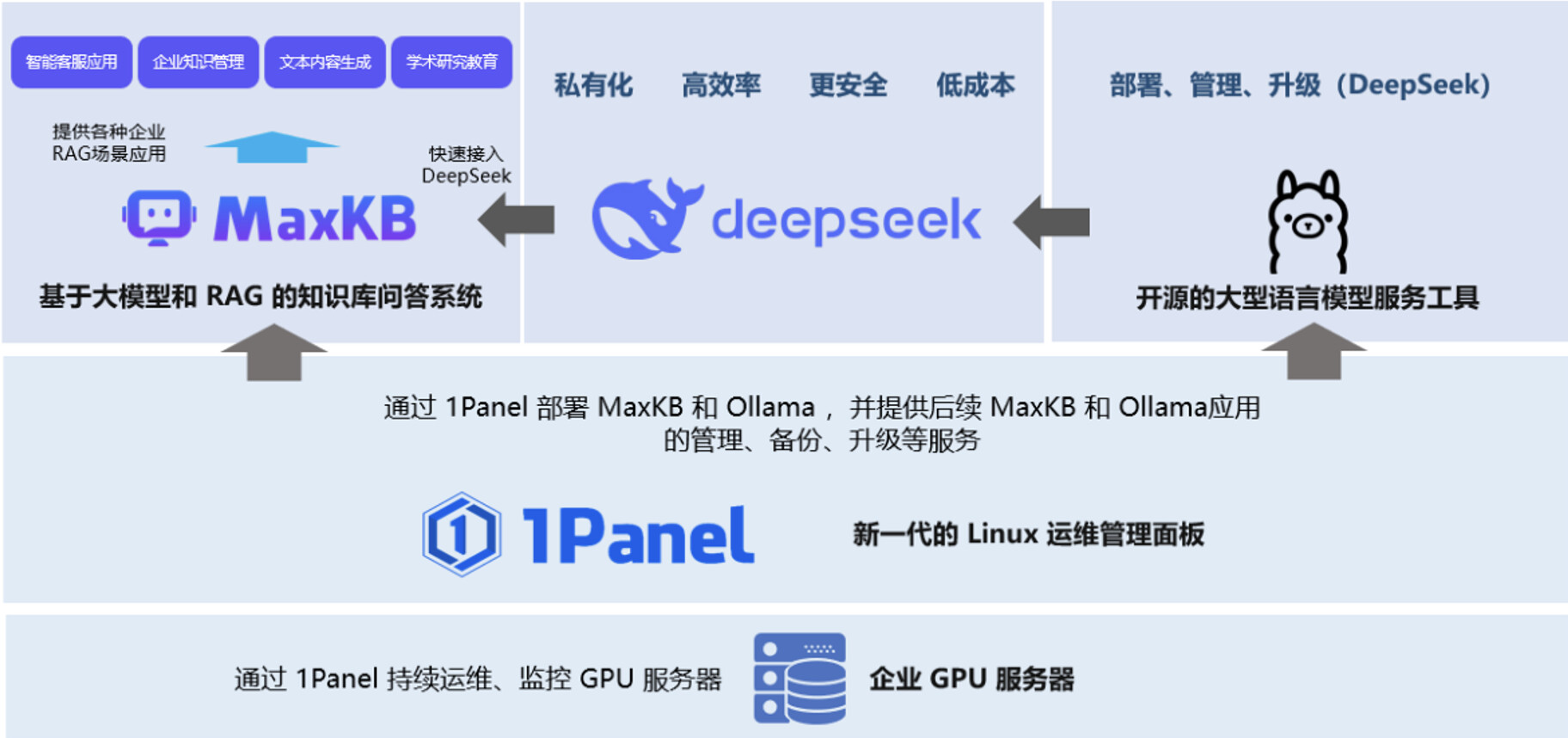
首先基于 GPU 服务器承载 DeepSeek 大模型,其次基于 1Panel (是一种 Linux 开源运维管理面板)完成 Ollama(是一种LLM服务管理开源工具)和 MaxKB(是一种课接入大模型,搭建私人知识库,构建智能体的开源工具) 的安装运维管理,通过 Ollama 安装管理 DeepSeek-R1 模型,最后再通过 MaxKB 完成本地知识库的搭建,快速构建本地 AI 知识库。
3.2 MaxKB平台上关键步骤
在本地或云上完成了1Pane、Ollama、 MaxKB开源三件套的部署安装后,最后在 MaxKB平台完成四个步骤:对接大语言模型 ——> 创建本地知识库 ——> 创建应用 ——> 调试发布。
3.2.1 第一步:对接大语言模型
1、添加模型
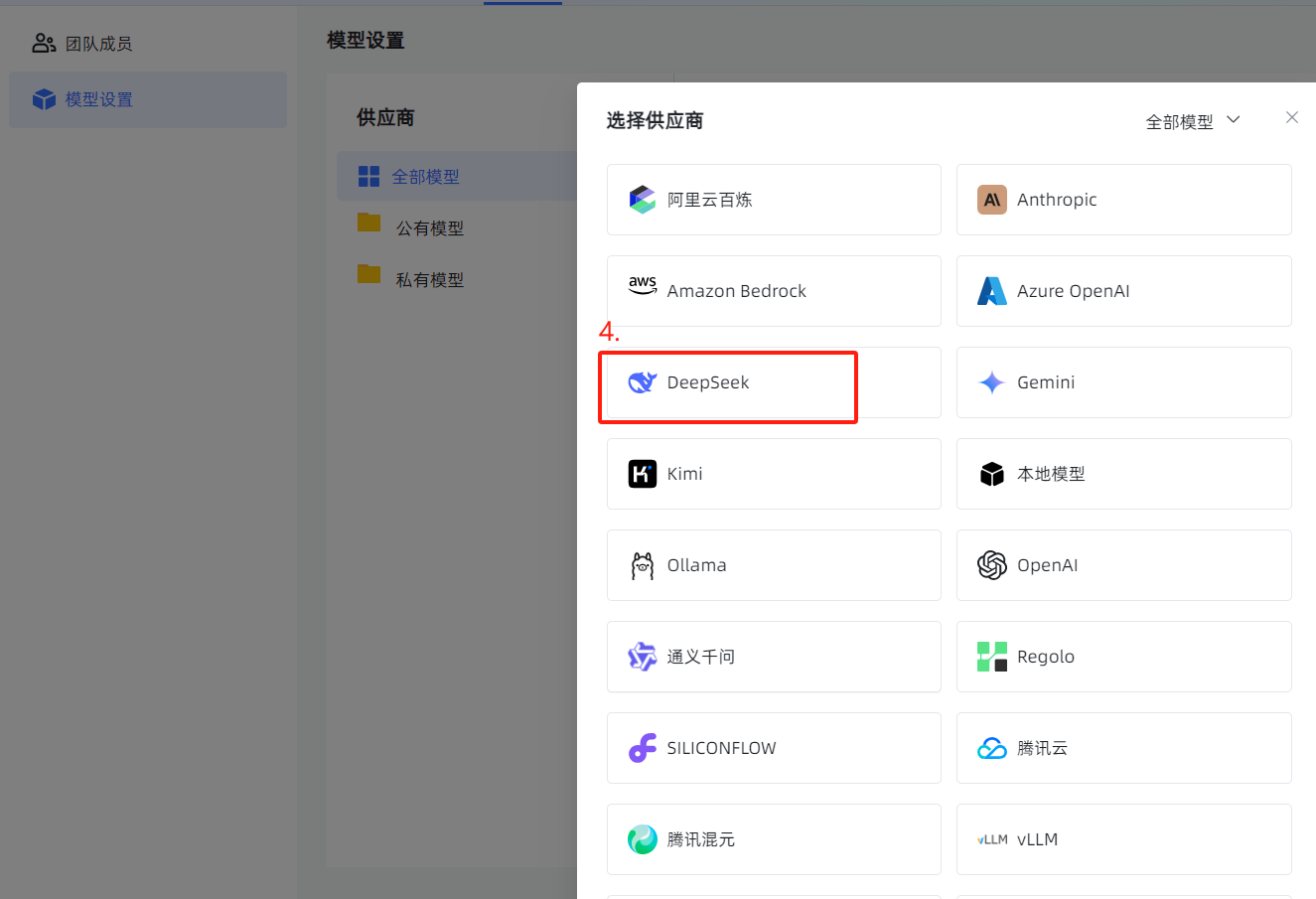
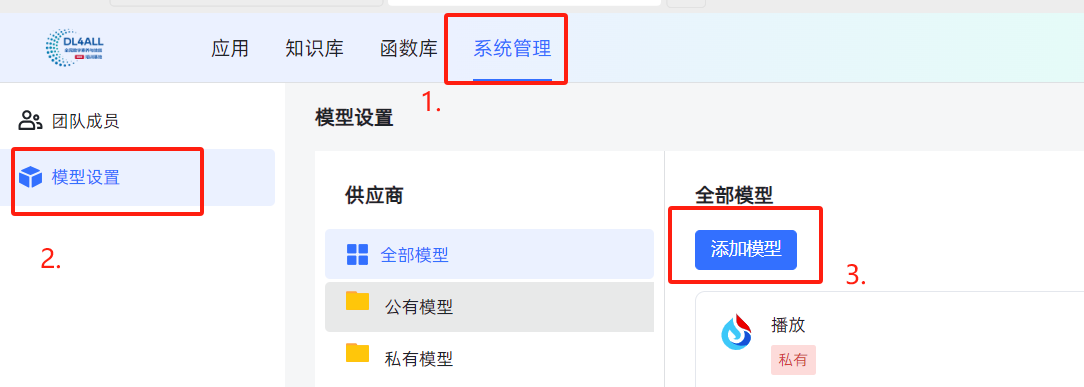 2、选择供应商(也就是各种大模型的厂商)
2、选择供应商(也就是各种大模型的厂商)
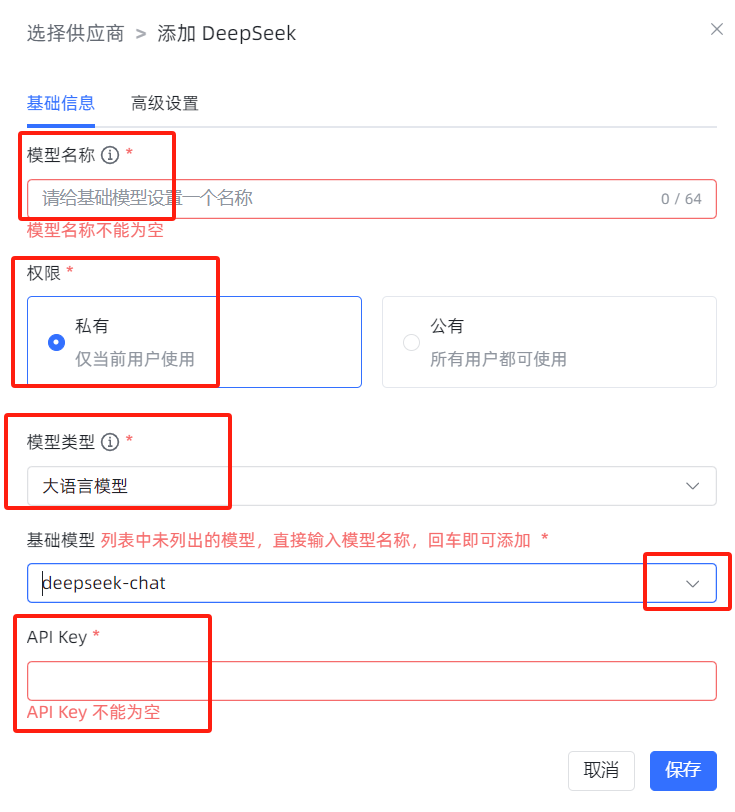
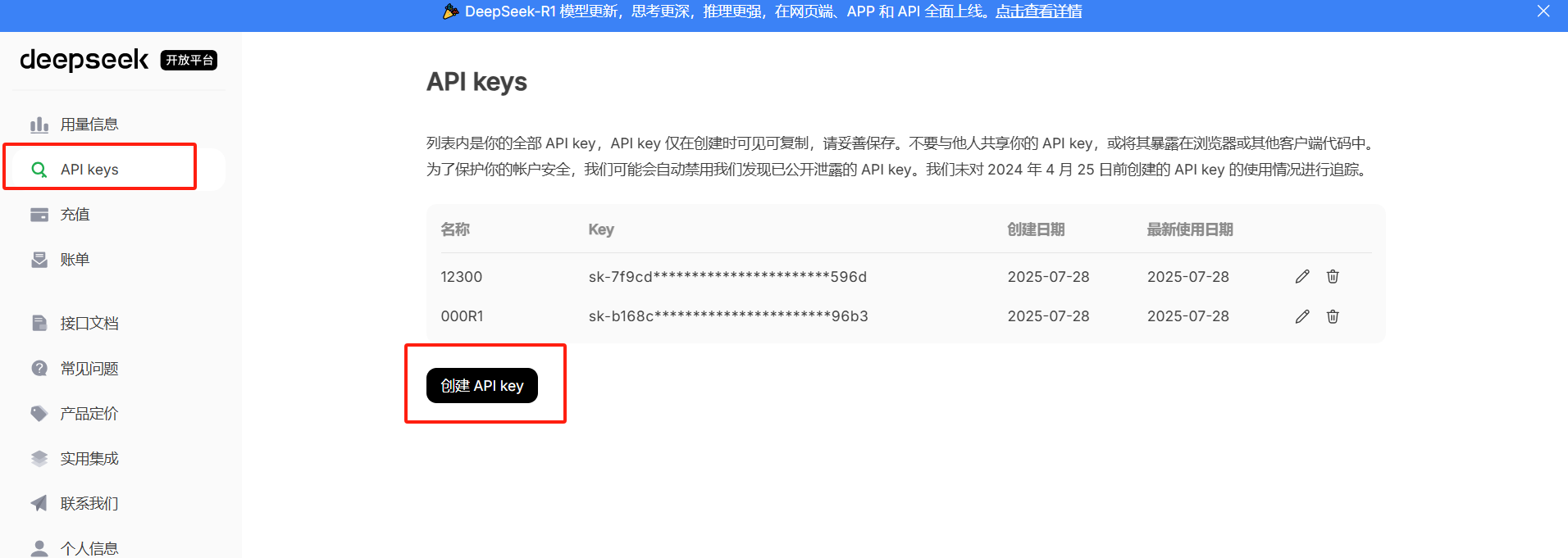
补充:API key需要到模型官网获取。(以下展示以deep seek模型的API key获取为例)
(1)进入deep seek官网的开放平台(https://platform.deepseek.com/usage)
(2)完成网站的注册、登录、认证、充值后,可以创建API Keys.
(3)完成创建后,复制API Key到MaxKB平台去填写。
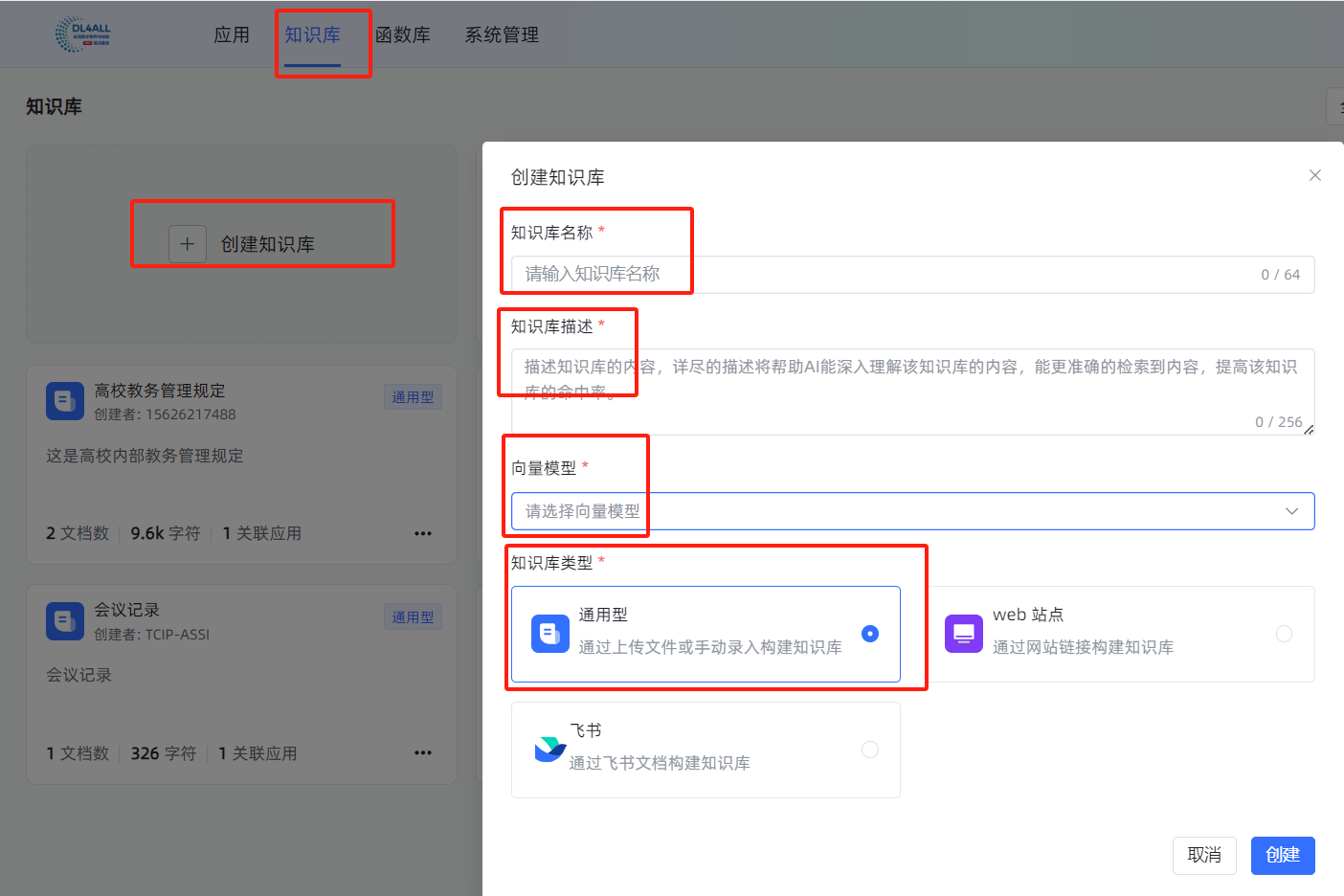
3.2.2 第二步:创建本地知识库
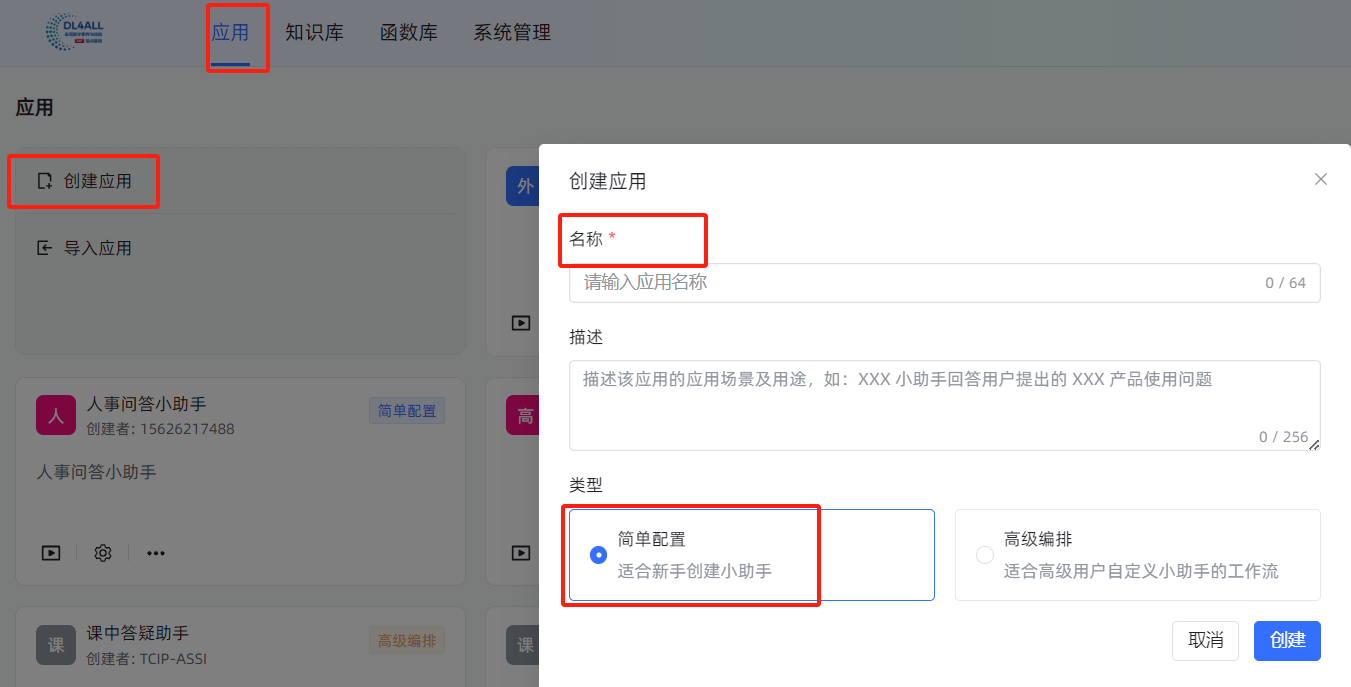
3.2.3 第三步:创建并设置应用
(1)创建应用
(2)设置应用
要选择AI模型(即第一步自己创建并命名的模型)
要关联知识库(即第二步创建的本地知识库)
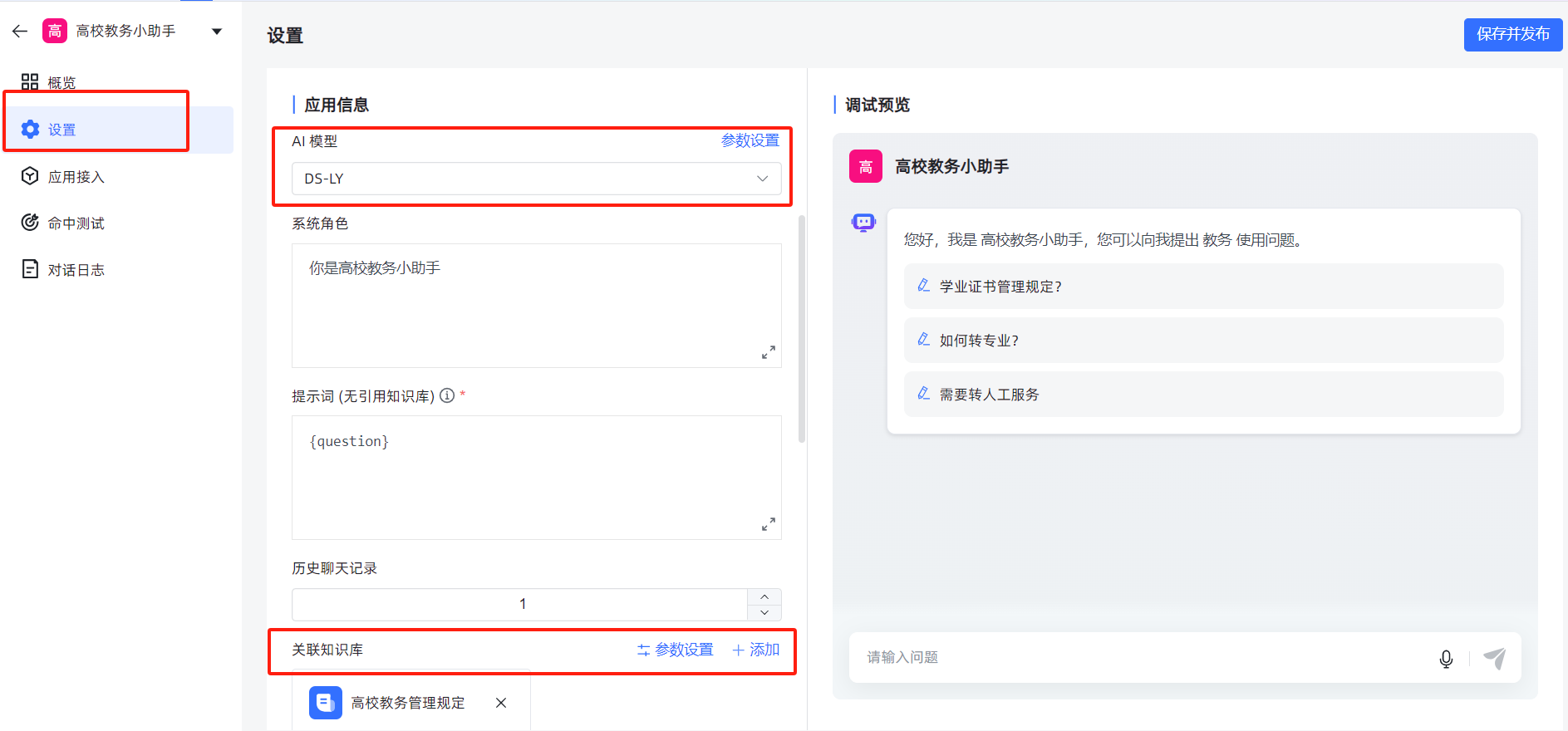
3.2.4 调试发布
保存发布后,观察调试预览,有必要时可以调整“系统角色”或“提示词”的描述。
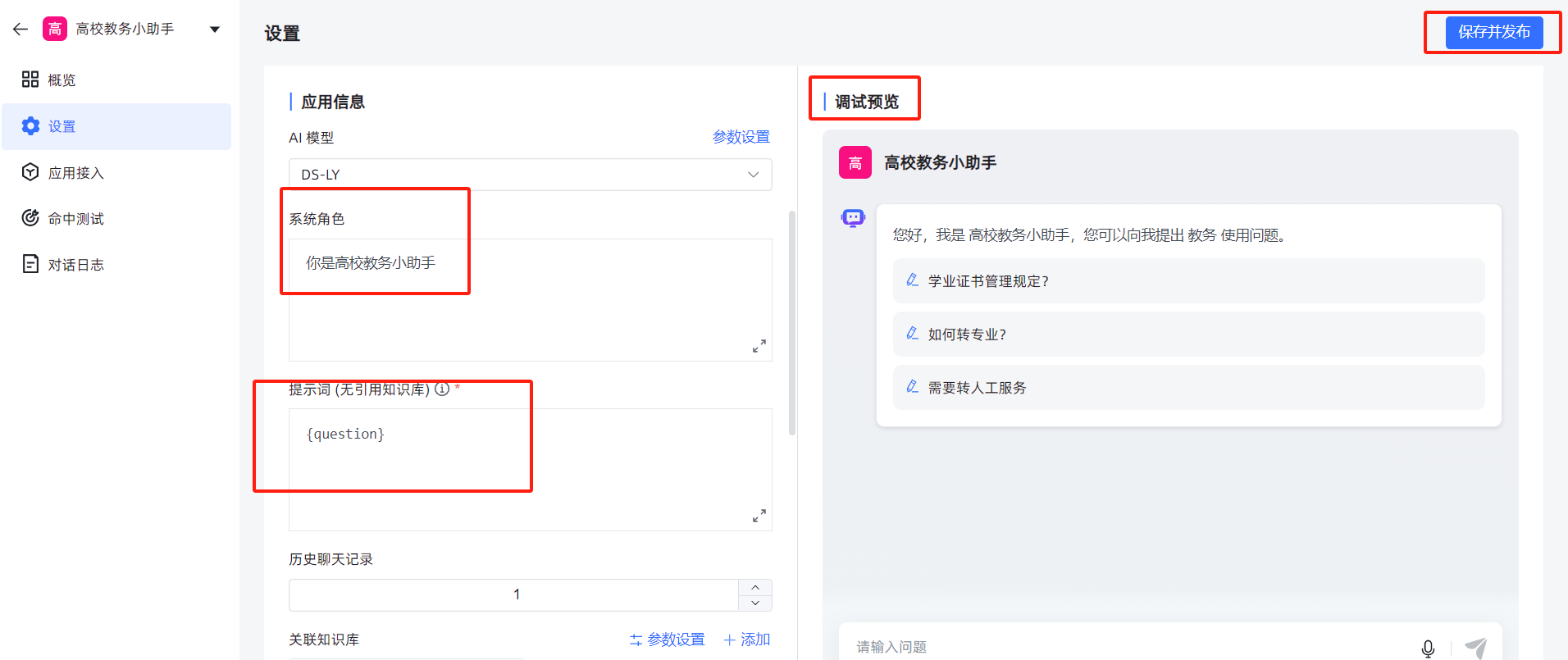
到此,简单的私有化应用发布成功!

















 7012
7012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









