






目录
写在前面
一、LambdaLR
二、PolynomialLR
三、CyclicLR
四、CosineAnnealingWarmRestarts
五、SequentialLR
六、ChainedScheduler
写在前面
上一篇文章介绍了一些常用的学习率衰减策略,下面我们再来看看稍微冷门一点的,废话不多说,我们开始。
图解Pytorch学习率衰减策略(一):
一、LambdaLR
基于自定义 lambda 函数调整学习率,极为灵活。可以根据训练的需要,自由地设计学习率的变化规律。
示例:
参数:
lr_lambda: 一个函数或函数列表,决定每个 epoch 的学习率调整比例。
学习率变化曲线:
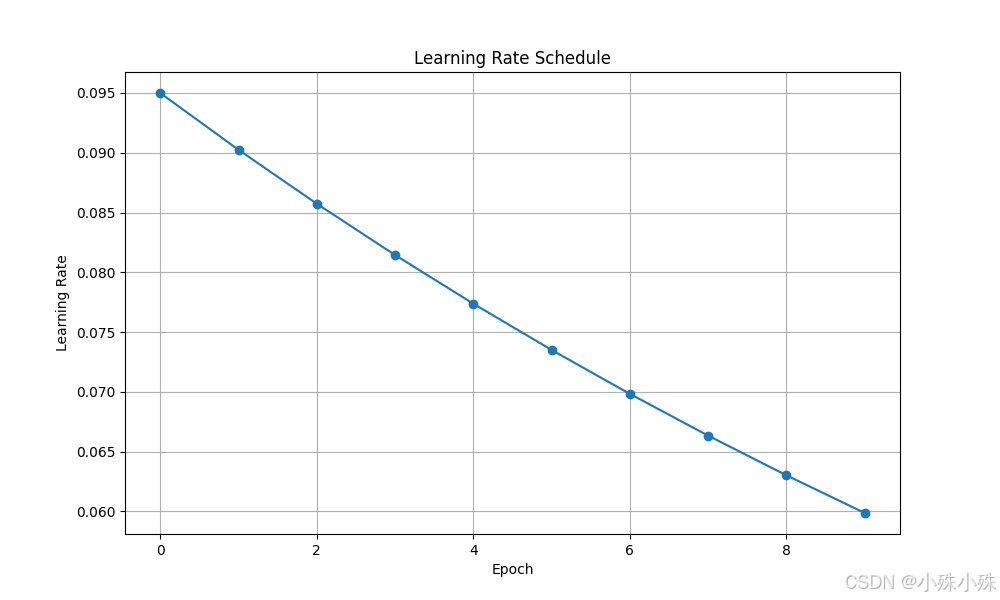
使用场景:
适用于需要高度自定义学习率策略的场景,适合对训练过程有特殊要求的任务。
推荐程度:一般
二、PolynomialLR
多项式衰减,通常在训练的最后阶段将学习率降至极低值,适合需要缓慢收敛的任务。它常常用于迭代次数已知的训练任务。
多项式公式如下:
 ^{ power}")
示例:
参数:
total_iters:学习率衰减的步数
power:多项式的幂,这个数越大,曲线越向左下弯
学习率变化曲线:
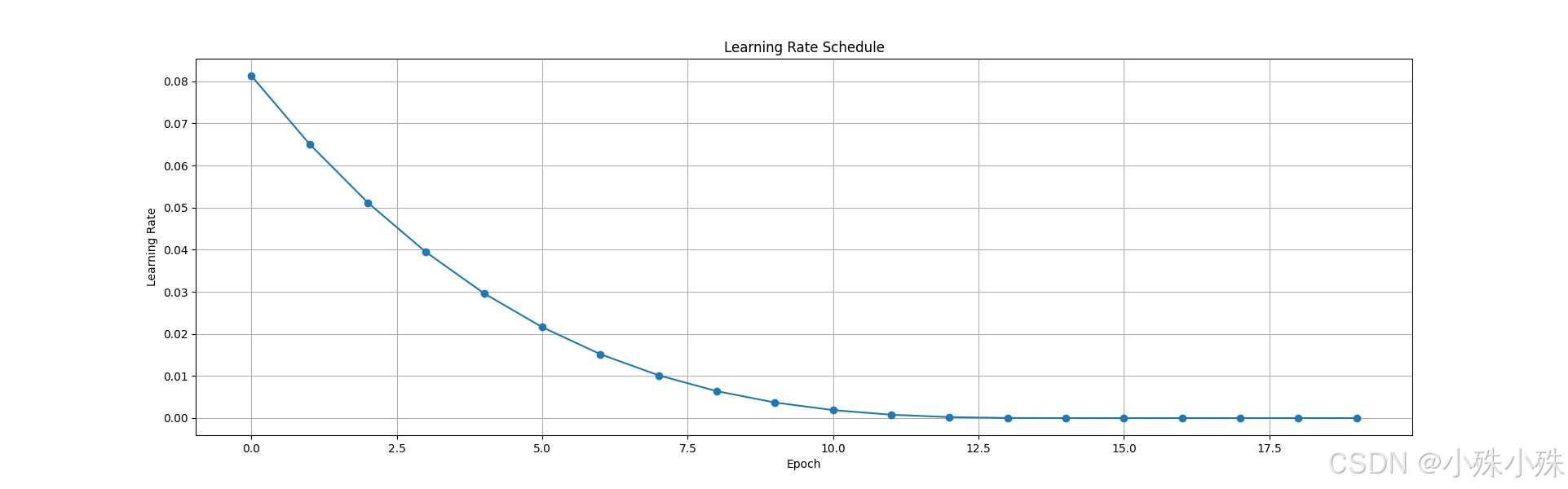
使用场景:
适用于需要在训练的最后阶段将学习率降得非常低的场景,通常在一些长时间训练的任务中使用。
推荐程度:很少用,不推荐
三、CyclicLR
学习率在两个边界值之间循环变化,可以防止模型陷入局部最优,有助于早期训练探索。常用于防止模型陷入局部最优。
示例:
参数:
base_lr: 学习率的下限。
max_lr: 学习率的上限。
step_size_up: 学习率上升step_size_up步。
step_size_down: 学习率下降step_size_down步。
mode :可选参数有三个,triangular、triangular2 和 exp_range ,代表了不同的学习率调整方式。
"triangular"模式下,学习率在周期内按三角波形变化。在每个周期中,学习率从 base_lr 增加到 max_lr,然后再减少回 base_lr。
"triangular2"与 "triangular" 模式类似,但每个周期的学习率峰值逐渐减小。学习率在每个周期内以三角波形变化,但每个周期的 max_lr 会减半。
"exp_range" 在每个周期内,学习率的变化按照指数衰减的方式进行。学习率从 base_lr 增加到 max_lr,然后按指数衰减回 base_lr。
使用场景:
适合于需要避免局部最优且探索较大学习率范围的任务,如早期训练阶段或复杂优化问题。
学习率变化曲线:
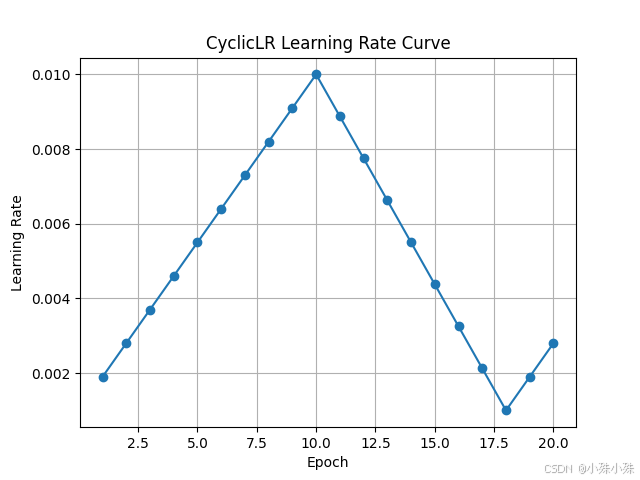
使用场景:
适用于训练过程中需要探索不同学习率,尤其在早期阶段有助于跳出局部最优解。
推荐程度:不常用,不推荐
四、CosineAnnealingWarmRestarts
CosineAnnealingWarmRestarts 是余弦退火和周期性重新启动的结合。这种策略在每个周期内,学习率按照余弦函数曲线下降,然后在周期结束时重置为初始值并进入下一个周期。
示例:
参数:
T_0: 初始周期的步数。
T_mult: 每次重启后周期步数的倍增因子。
eta_min: 最小学习率。
学习率变化曲线:
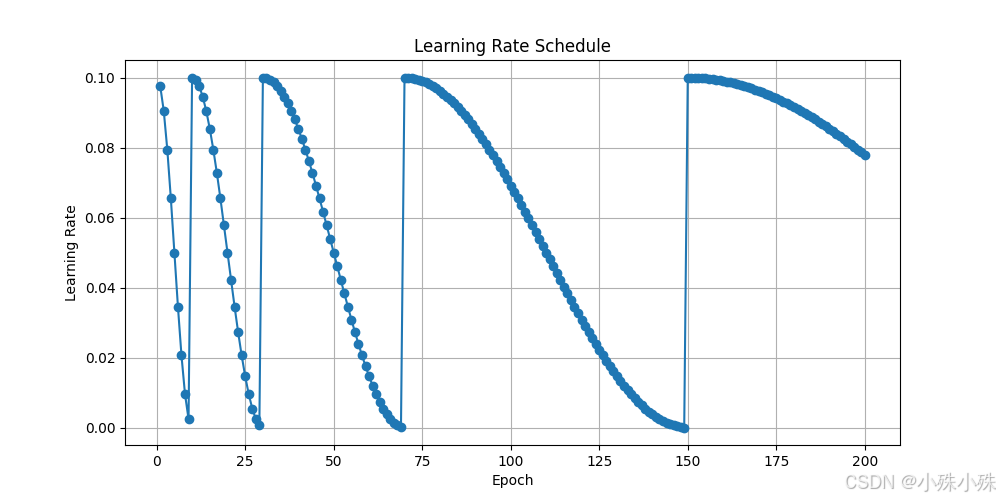
使用场景:
适用于各种类型的模型和任务,尤其是那些训练周期较长、训练过程复杂的情况。因此,不论是图像分类、自然语言处理、生成模型还是强化学习任务,都可以考虑使用这种调度策略。
推荐程度:推荐
五、SequentialLR
组合多个学习率调度器,按顺序执行不同策略,提供了更高的灵活性。例如,你可以先使用 StepLR,然后在后期切换到 ExponentialLR。
示例:
参数:
schedulers: 包含多个调度器的列表。
milestones: 一个列表,定义每个调度器的切换点。
学习率变化曲线:
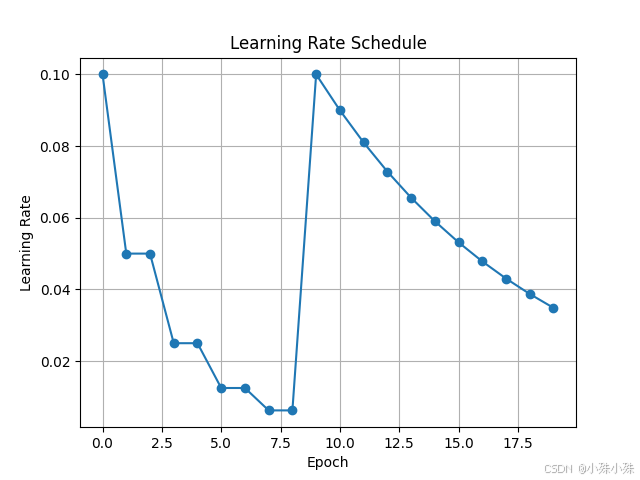
使用场景:
适用于需要在训练的不同阶段使用不同学习率策略的复杂训练任务,如从预训练到微调的过程。
推荐程度:不推荐,用的不多。
六、ChainedScheduler
多个调度器链在一起同时执行,适用于需要结合多种学习率调整策略的任务。
示例:
参数:
schedulers: 需要链在一起的调度器列表。
学习率变化曲线:
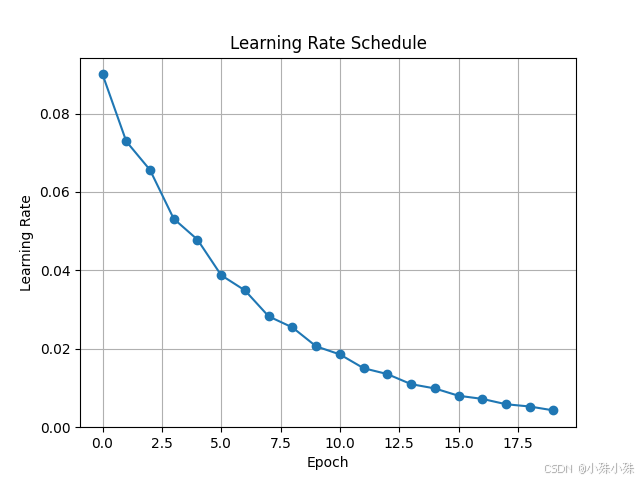
使用场景:
适用于希望结合多种学习率调整策略的复杂任务。
推荐程度:不推荐,这个功能比较抽象,从没见谁用过。
学习率衰减策略就到这里,关注不迷路(*^▽^*)
关注订阅号了解更多精品文章


















 2941
2941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









