






 本文分享了爬虫技术的实用技巧,包括如何通过设置User-Agent和Referer进行网页伪装,使用BeautifulSoup解析网页并抓取图片资源,以及如何批量获取特定网站上的所有图片链接。
本文分享了爬虫技术的实用技巧,包括如何通过设置User-Agent和Referer进行网页伪装,使用BeautifulSoup解析网页并抓取图片资源,以及如何批量获取特定网站上的所有图片链接。
第二篇爬虫学习笔记
第一篇只是简单爬取一下:https://blog.youkuaiyun.com/weixin_41263513/article/details/82469336
第二篇的学习希望能更深入,更安全,参考了很多资料
目标:掌握更安全的爬取,提高效率与安全性
ps:之后可能会暂时放置一下爬虫的事,开始学习机器学习!
主要参考资料:
我觉得这个作者的教程很不错,很朴实,很容易吸收:https://cuiqingcai.com/author/aiyo
反爬虫,通俗易懂,很容易调动兴趣的文章:https://segmentfault.com/a/1190000005840672
csdn内大神Jack-Cui:https://blog.youkuaiyun.com/c406495762/article/list/2
运行环境:windows
python版本:python35
IDE:pycharm
搜索目标
有句话虽然算是调侃,但某种程度上也是真理:sex是第一生产力
so,想提高兴趣,从学习中找到乐趣
【妹子图】真的是一个非常非常非常激励(滑稽)的一个网站
那么有了目标就开始行动吧!!
1.欺骗
关于爬虫与反爬虫:https://segmentfault.com/a/1190000005840672
↑↑非常建议大家看一下,看了燃起了我的爬虫热血!!!dio,我不做人啦!!
借用大神的理解,十分平实

所以要应对也很简单,就两步!
- 利用 user-agent 欺骗!
- 利用 ip 欺骗!
一般user-agent不需要怎么换,但ip如果太乱来太频繁被封了还是很难受的
所以更应该关注利用ip欺骗,要用ip欺骗最好要有一个ip代理池,前辈们提及的几个免费的ip池的网站貌似都挂掉了,默哀:www.haoip.cc/tiqu.htm,只能自己爬取自己维护自己创建一个ip代理池了,那么这个ip代理池以后再来实现吧(挖坑)
目标很明确,就西刺网:http://www.xicidaili.com/
把里面的ip挖来供自己享用,喜滋滋啦~
所以关于欺骗,其实只是非常简单的加了一个headers进去而已啦
2.尝试爬图
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.mzitu.com/149163'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Referer': 'http://www.mzitu.com/149163'}
#分析网页
req = urllib.request.Request(url, headers = headers)
html = urllib.request.urlopen(req).read().decode('utf-8')
#分析所需元素
soup = BeautifulSoup(html, 'html5lib')
div = soup.find('div', class_='main-image')
img = div.find('img')['src']
#解析图片
pic_req = urllib.request.Request(img, headers = headers)
pic_url = urllib.request.urlopen(pic_req).read()
#成图
with open(img.split('/')[-1], 'wb') as f:
f.write(pic_url)
这个妹子图网站其实搞了我几天,因为之前我不能拿到图片,出现403错误,之后才发现了,这个网站弄了个防盗链,下载的图片全部失效,解决办法就是要在headers里面加个referer(其实referer就是该网址本身)
最后成功取得图片,尺度问题,我就不截图了好吧
copy到.py文件里能直接运行,将会弄到一张图!
3.获取分页链接
简单分析一下网址不难发现猫腻
分页只是在后面加了个斜杠+数字(页数)
思路也很清晰,直接获取最大的那个数字

如图,44是我们需要获得的数字!
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.mzitu.com/140658'
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
headers['Referer'] = 'http://www.mzitu.com/140658'
req = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(req).read().decode('utf-8')
soup = BeautifulSoup(html, 'html5lib')
pages = soup.find('div', class_ = 'pagenavi').find_all('span')[-2] #获取44这个数字
a = pages.text #注意,这里还是str类型
for i in range(int(a)):
print(i+1)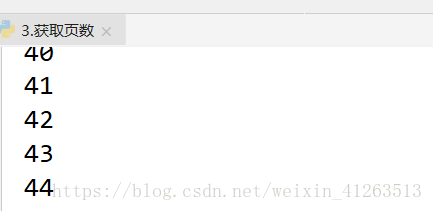
笔记:一定!!一定!!一定!!要注意各种变量的类型!!!
4.获取各种页面的链接
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.mzitu.com/all'
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
headers['Referer'] = 'http://www.mzitu.com'
req = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(req).read().decode('utf-8')
soup = BeautifulSoup(html, 'html5lib')
data_list = soup.find_all('p', class_ = 'url')
'''
以下最好自己打一遍,便于理解
简单说,url_list是一个列表
a_list是a标签的列表
href_list是href的列表
'''
for a_list in data_list:
for href_list in a_list.find_all('a'):
print(href_list['href'] + ' ' + href_list.text)

标题都让我有点把持不住了,差一点!!
这一步不难,主要要掌握好BeautifulSoup对数据的处理,慢慢来,老哥稳
5.代码整合!
这是最让激动的时刻了,因为离成功只剩一步了(滑稽)!
一定一定要注意要改变referer才能下载到图片
import urllib.request
from bs4 import BeautifulSoup
import os
file_name = [] #文件夹名字
img_url = [] #图片地址
#解析网页,注意referer
def url_open(url):
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
headers['Referer'] = url
req = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(req).read()
return html
#获得链接+名字+referer
def data_get(html):
html = html.decode('utf-8')
soup = BeautifulSoup(html, 'html5lib')
data_list = soup.find_all('p', class_='url')
for a_list in data_list:
for href_list in a_list.find_all('a'):
file_name.append(href_list.text)
img_url.append(href_list['href'])
#获取页数
def page_get(url):
html = url_open(url).decode('utf-8')
soup = BeautifulSoup(html, 'html5lib')
pages = soup.find('div', class_='pagenavi').find_all('span')[-2] # 获取44这个数字
page = int(pages.text)
return page
#获取图片
def img_get(url):
html = url_open(url)
soup = BeautifulSoup(html, 'html5lib')
div = soup.find('div', class_='main-image')
img = div.find('img')['src']
pic_url = url_open(img)
with open(img.split('/')[-1], 'wb') as f:
f.write(pic_url)
if __name__ == '__main__':
data_get(url_open('http://www.mzitu.com/all'))
os.mkdir('./妹子图')
os.chdir('./妹子图')
file_num = 0
for urls in img_url:
page = page_get(urls)
os.mkdir('./' + file_name[file_num][:15])
os.chdir('./' + file_name[file_num][:15])
for i in range(page):
url = urls + '/' + str(i + 1)
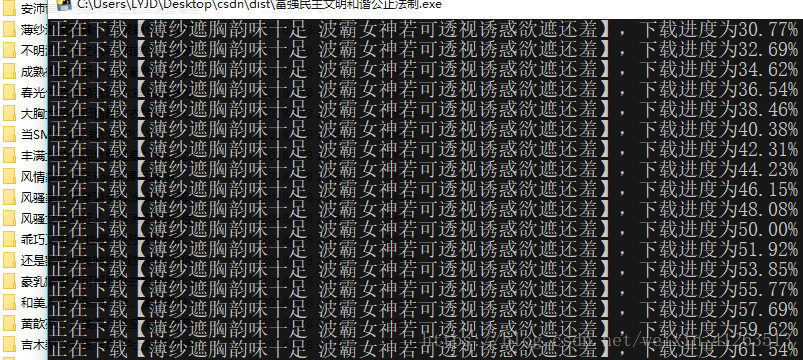
print('正在下载【' + file_name[file_num] + '】', end = '')
print(',下载进度为%.2f%%'%(i / page * 100))
img_get(url)
os.chdir(os.path.dirname(os.getcwd()))
file_num += 1我还用pyinstaller打包了一个exe文件
下一篇我想学什么?
爬完文字,爬完图片,下一篇肯定开始爬视频啦
除此之外,希望自己能掌握一下scrapy框架,把数据存到数据库mysql里,还有听说多进程会提升效率我也学一下哈哈哈哈!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









