







这里将会介绍通过url来获取url所在的域名,协议
一 使用python的标准库
但是标准库无法区分获取一级域名和二级域名
导入模块
from urllib.request import urlparse
from urllib.request import urlparse
url = "https://blog.youkuaiyun.com/weixin_41238134/article/details/90199649"
# 域名
domain = urlparse(url).netloc
# 协议
scheme = urlparse(url).scheme
print("获取到的域名是:{}".format(domain))
print("获取到的协议是:{}".format(scheme)) 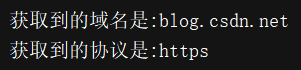
二 使用第三方库 tldextract
安装方法 pip install tldextract
import tldextract
url = 'http://m.windowscentral.com'
# 一级域名
domain = tldextract.extract(url).domain
# 二级域名
subdomain = tldextract.extract(url).subdomain
# 后缀
suffix = tldextract.extract(url).suffix
print("获取到的一级域名:{}".format(domain))
print("获取到二级域名:{}".format(subdomain))
print("获取到的url后缀:{}".format(suffix)) 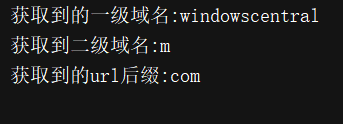
domain 一级域名
subdomain 二级域名
suffix 后缀 比如com,cn,net


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









