







 本文探讨了在Python中如何使用ViewModel统一API接口,揭示伪面向对象的特征,并详细介绍了对YuShuBook模块的重构过程,强调了代码解释权反转的概念。同时,文章还对比了单页面应用与传统网站的差异。
本文探讨了在Python中如何使用ViewModel统一API接口,揭示伪面向对象的特征,并详细介绍了对YuShuBook模块的重构过程,强调了代码解释权反转的概念。同时,文章还对比了单页面应用与传统网站的差异。
一. ViewModel
我们获取书籍数据的api, 一个是通过关键字参数, 一个是通过书籍isbn, 得到的数据结构并不相同, 我们想做成统一的接口方便调用。这就需要用到viewmodel
isbn查找: 
关键字查找

使用viewmodel

新建app/viewmodels/book.py:
class BookViewModel:
@classmethod
def package_single(cls, data, keyword): # 单个的,即isbn查找
returned = {'books': [],
'total': 0,
'keyword': keyword
}
if data:
returned['total'] = 1
returned['books'] = [cls.__cut_bookdata(data)]
return returned
@classmethod
def package_collection(cls, data, keyword): # 关键字查找
returned = {'books': [],
'total': 0,
'keyword': keyword
}
if data:
returned['total'] = data['total']
returned['books'] = [cls.__cut_bookdata(book) for book in data['books']]
# __cut_bookdata是处理单个book数据的, 这样使用就可以处理多个book数据了
return returned
@classmethod
def __cut_bookdata(cls, data):
# 处理单个的数据方法, 这样package_single和package_collection都可以用。
#不要想着定义个列表, 然后来的不管是多个数据还是单个数据,都放进去。这样的编码并不好。
book = {'title': data['title'],
'publisher': data['publisher'],
'pages': data['pages'] or '', # 这里使用or, 如果data['pages']返回的是none,我们让它为''
'author': '、'.join(data['author']),# 作者如果有多个的话是列表, 我们把它变成字符串
'price': data['price'],
'summary': data['summary'] or '',
'image': data['image']
}
return book
修改app/web/book.py:
@web.route('/book/search')
def search():
form = SearchForm(request.args)
if form.validate():
q = form.q.data.strip()
page = form.page.data # 最好从form中取, 如果从request.args来取的化, 没有默认值了
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YuShuBook.search_by_isbn(q)
result = BookViewModel.package_single(result, q) # viewmodel统一isbn查找的数据结构
else:
result = YuShuBook.search_by_keyword(q, page)
result = BookViewModel.package_collection(result, q) # viewmodel统一关键字查找的数据结构
return jsonify(result)
else:
return jsonify(form.errors)
这样接口的数据结构就统一了。
二. 伪面对对象:披着面对对象外衣的面向过程
面对对象的编程特点:
1. 描述特征 有类变量、实例变量
2. 行为(方法) 定义函数重新审视app/spider/YuShuBook.py中的代码, 我们发现, YuShuBook只有类方法,没有变量, 这其实依然是面向过程。
判断伪面向对象的方法:
把类的方法 能改成staticmethod或classmethod的都去改一下。
如果改完发现类中有大量的staticmethod或classmethod, 则就是伪面向对象。三. 重构YushuBook
我们将伪面向对象的代码进行修改, 按如下顺序:

重构app/spider/yushu_book.py,使其可以对isbn和关键字搜索得到的结果进行行结构化处理:
from flask import current_app # 导入核心对象app
from app.libs.httper import HTTP
class YuShuBook:
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword_url = 'http://t.yushu.im/v2/book/search?q={}&count={}&start={}'
def __init__(self):
self.total = 0
self.books = []
def search_by_isbn(self, isbn):
url = self.isbn_url.format(isbn) # self. 实例变量找不到,会去找类变量
result = HTTP.get(url)
self.__fill_single(result)
def search_by_keyword(self, keyword, page=1):
url = self.keyword_url.format(keyword, current_app.config['PER_PAGE'], self.calculate_start(page))
result = HTTP.get(url)
self.__fill_collection(result)
def calculate_start(page):
return (page - 1) * current_app.config['PER_PAGE']
def __fill_single(self, data): # 和viewmodel中一样
if data:
self.total = 1
self.books.append(data)
def __fill_collection(self, data):
if data:
self.total = data['total']
self.books = data['books']
重构app/view_models/book.py:
class BookViewModel: # 单本书籍结果存放
def __init__(self, book): # book参数就是yushubook
self.title = book['title']
self.publisher = book['publisher']
self.author = '、'.join(book['author'])
self.image = book['image']
self.price = book['price']
self.summary = book['summary']
self.pages = book['pages']
class BookCollection: # 多yushu_book的结果进行封装, 增加keyword数据
def __init__(self):
self.total = 0
self.book = []
self.keyword = ''
def fill(self, yushu_book, keyword):
self.total = yushu_book.total
self.keyword = keyword
self.book = [BookViewModel(book) for book in yushu_book.books]
app/web/book.py:
from app.libs.helper import is_isbn_or_key
from app.spider.yushu_book import YuShuBook
from flask import jsonify, request
from .blueprint import web
from app.forms.book import SearchForm
from app.view_models.book import BookCollection
@web.route('/book/search')
def search():
form = SearchForm(request.args)
books = BookCollection()
if form.validate():
q = form.q.data.strip()
page = form.page.data
isbn_or_key = is_isbn_or_key(q)
yushu_book = YuShuBook()
if isbn_or_key == 'isbn':
yushu_book.search_by_isbn(q)
else:
yushu_book.search_by_keyword(q, page)
books.fill(yushu_book, q)
return jsonify(books)
else:
return jsonify(form.errors)
运行会报错, 我们需要return jsonify(books)传入的参数变为dict
四. 从json序列化看代码解释权反转
我们如果这样:
books.__dict__ 得到一个字典,再传入jsonify。
结果依然报错。
原因是: books的self.books 是列表, 是一个object(对象)。我们需要对objct对象,进行单独处理:
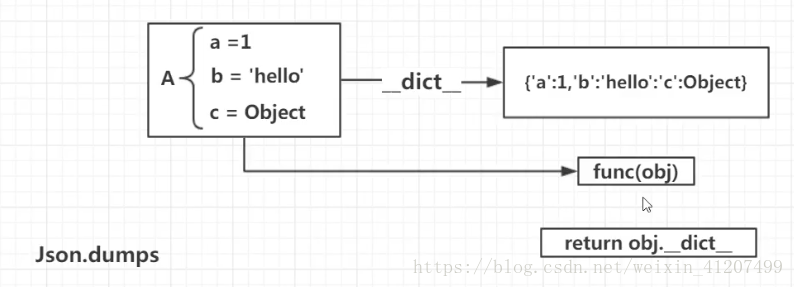
将return jsonify(books)改为return json.dumps(books, default = lambda o: o.__dict__), default参数传入的是函数。
json.dumps的default参数 体现了,一种编程思想:
写接口的时候, 为使用者提供自定义功能。
这样的接口适用性会无限的扩大。五. 单页面与网站的区别:
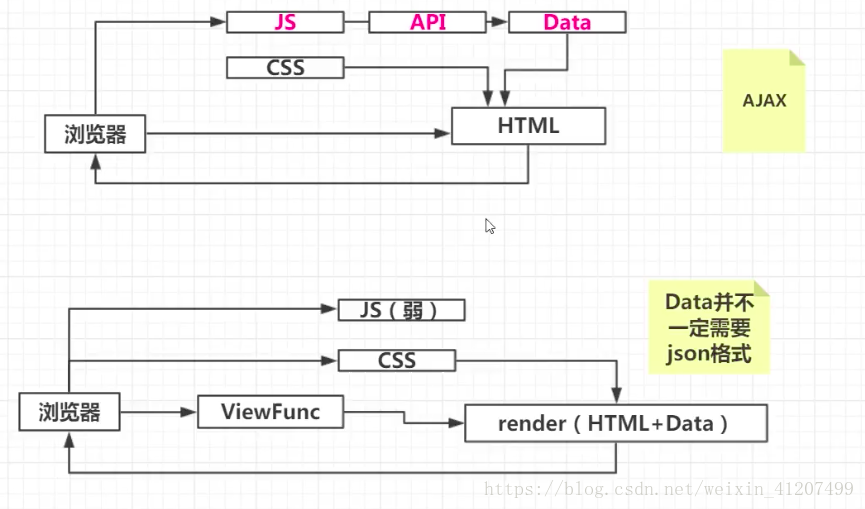
区别1.
单页面 的数据处理主要在客户端
多页面 的数据处理主要在服务器端区别2.
单页面 的渲染和数据填充 在客户端进行
多页面 的渲染和数据填充 在服务器进行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









