







 本文深入探讨了大数据的5V特性,介绍了关系型数据库(RDBMS)与非关系型数据库(NoSQL)的优缺点,以及BigTable的分布式架构。此外,还讨论了图数据库Neo4j、Bloom Filters在数据去重中的应用,以及虚拟化技术如Hypervisor的工作原理。文章最后聚焦于Hadoop生态系统,包括HDFS的高容错性和MapReduce的分布式计算框架,以及Spark的内存计算优势和Storm的实时流处理。
本文深入探讨了大数据的5V特性,介绍了关系型数据库(RDBMS)与非关系型数据库(NoSQL)的优缺点,以及BigTable的分布式架构。此外,还讨论了图数据库Neo4j、Bloom Filters在数据去重中的应用,以及虚拟化技术如Hypervisor的工作原理。文章最后聚焦于Hadoop生态系统,包括HDFS的高容错性和MapReduce的分布式计算框架,以及Spark的内存计算优势和Storm的实时流处理。
1. Database systems
1.1 BD定义——5V
- Volume(大量):包括采集,存储,管理,分析的数据量很大,超出了传统数据库软件工具能力范围的海量数据集合。因此,对数据存储的要求变大。
- Velocity(高速):数据增长速度快,要求实时分析与数据处理及丢弃,而非事后批处理。这是大数据区别于传统数据挖掘的地方。
- Variety(多样):数据种类和来源多样性,包括不同种类的数据,比如文本图像音频视频定位等,以及各种结构化,半结构化,非结构化数据,不连贯的语义或句意。这对数据处理能力提出了更高的要求。集合了数学,心理学,神经生理学与生物学的机器学习在数据挖掘,自然语言处理,搜索引擎,医学诊断方面不断寻求突破。
- Value(低价值密度):海量信息中的价值密度相对较低,如何在大数据中条分缕析披沙拣金,进行分析预测,找到数据的意义和价值所在,是机器学习和人工智能努力的方向。
- Veracity(真实性) : 指大数据的质量,大数据的内容是与真实世界息息相关的,真实不一定代表准确,但一定不是虚假数据,这也是数据分析的基础。基于真实的交易与行为产生的数据,才有意义,如何Mock数据,是一个话题。如何识别造假数据,更是值得研究的领域。
1.2 database两大类(relational & non-relational)
-
relational (RDBMS)
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:SQL语言通用,可用于复杂查询;
3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
4、Traditional RDBMS do not scale to truly massive level. -
non-relational
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、高扩展性;
4、成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、无事务处理;
3、数据结构相对复杂,复杂查询方面稍欠。 -
补:CAP theorem
Consistency一致性,Availability可用性,Partition tolerance分区容错性
C, A互斥 -
补: ACID vs BASE
关系数据库, 最大的特点就是事务处理, 即满足ACID;
Ø 原子性(Atomicity):事务中的操作要么都做,要么都不做。 Ø 一致性(Consistency):系统必须始终处在强一致状态下。 Ø 隔离性(Isolation):一个事务的执行不能被其他事务所干扰。 Ø 持续性(Durability):一个已提交的事务对数据库中数据的改变是永久性的。分布式数据库, 最大的特点就是分布式,即满足BASE,ASE方法通过牺牲一致性和孤立性来提高可用性和系统性能。
Ø 基本可用(Basically Available):系统能够基本运行、一直提供服务。 Ø 软状态(Soft-state):系统不要求一直保持强一致状态。 Ø 最终一致性(Eventual consistency):系统需要在某一时刻后达到一致性要求。
1.3 NoSQL四类
- key-value型

- column-oriented型

- document-oriented型

- graph/tree oriented型
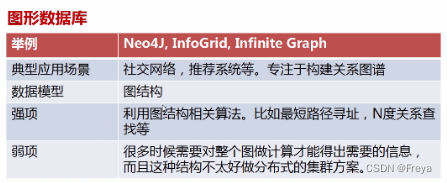
1.4 NoSQL vs RDBMS vs NewSQL

1.5 BigTable (分布式结构化数据表)
column-oriented NoSQL
Bigtable 是一个分布式, 多维, 映射表. 表中的数据通过一个行关键字(Row Key)、一个列关键字(Column Key)以及一个时间戳(Time Stamp)进行索引. 在Bigtable中一共有三级索引. 行关键字为第一级索引,列关键字为第二级索引,时间戳为第三级索引。
-
基本架构
我们有 Chubby, 主服务器, 子服务器, 子表.
Chubby 负责元数据的存储和选择主服务器.
主服务器复杂子服务器的负载均衡
子服务器负责子表的管理,一个子服务器可以有很多很多张子表,处理对其子表的读写请求,以及子表的分裂或合并。
每个子表的大小在100-200MB范围,一旦超出范围就将分裂成更小的子表,或者合并成更大的子表。 -
子表地址组成
Bigtable系统的内部采用的是一种类似B+树的三层查询体系
首先是第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了。
第二层是root tablet。root tablet其实是元数据表(METADATA table)的第一个分片,它保存着元数据表其它子表的位置。root tablet很特别,为了保证树的深度不变,root tablet从不分裂。
第三层是其它的元数据子表,它们和root tablet一起组成完整的元数据表。每个元数据片都包含了许多用户子表的位置信息。
可以看出整个定位系统其实只是两部分,一个Chubby文件,一个元数据表。注意元数据表虽然特殊,但也仍然服从前文的数据模型,每个子表也都是由专门的子服务器负责,这就是不需要主服务器提供位置信息的原因。客户端会缓存子表的位置信息,如果在缓存里找不到一个子表的位置信息,就需要查找这个三层结构了,包括访问一次Chubby服务,访问两次子服务器。
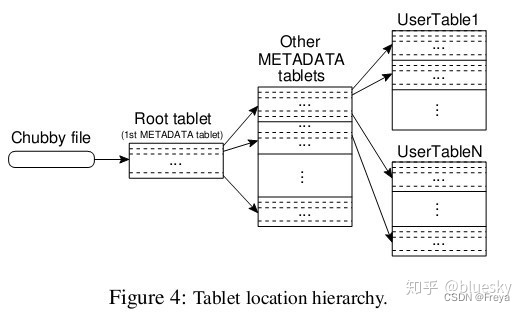
-
Bigtable 数据存储及读/写操作
子表的数据最终还是写到GFS里的,子表在GFS里的物理形态就是若干个SSTable文件。
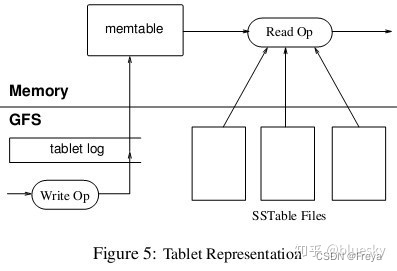
当子服务器收到一个写请求,子服务器首先检查请求是否合法。如果合法,先将写请求提交到日志去,然后将数据写入内存中的 memtable。memtable相当于SSTable的缓存,当memtable成长到一定规模会被冻结,Bigtable随之创建一个新的memtable,并且将冻结的memtable转换为SSTable格式写入GFS,这个操作称为minor compaction。For some applications, a small amount of tablet server memory used for storing Bloom filters drastically reduces the number of disk seeks required for read ops.
SSTable 是Google为Bigtable设计的内部数据存储格式。所有的SSTable文件都存储在GFS上,用户可以通过键来查询相应的值。
1.6 Neo4j (Graph database)
-
Graph database
节点(node)
表示一个实体记录、就像关系数据库当中一条记录。 一个节点包含多个属性和标签。
关系(relationship)
关系用于将节点关联起来构成图,关系也称为图论的边(Edge)。
属性(property)
节点和关系都可以有多个属性。属性是由键值对组成的,就像JAVA当中哈希。
标签(Label)
标签指示一组拥有相同属性的节点,但不强制要求相同,一个节点可以有多个标签。
路径(path)
图中任意两个节点都存在由关系组成的路径,路径有长短之分。
-
cypher query language slide5 P14
Cypher是一种声明式图数据库查询语言,类似关系数据库中当中SQL示例
2. Bloom Filters
2.1 Data Warehousing and Deduplication
- Data Warehousing定义 slide6 P8
- ETL process slide6 P12
- Data Deduplication
file level, block level, byte level slide6 P16
Source-based vs Target-based slide6 P20
2.3 Bloom Filters slide7
3. Virtualisation Cloud Computing
3.1 virtualisation优劣 slide8 P9
3.2 VMM(Hypervisor)
-
定义
Hypervisor 是一种运行在物理服务器和操作系统之间的中间软件层,它可以协调访问服务器上的所有物理设备和虚拟机,也叫虚拟机监视器VMM。
Hypervisor是所有虚拟化技术的核心。非中断地支持多工作负载迁移的能力是Hypervisor的基本功能。当服务器启动并执行Hypervisor时,它会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统。
-
两种类型
一种是裸机型,直接运行在硬件设备上的,这种架构搭建的虚拟化环境称Bare-Metal Hardware Virtualization裸机虚拟化环境;
一种是主机托管型,运行在具有虚拟化功能的操作系统上的,构建的是Hosted Virtualization 主机虚拟化环境。
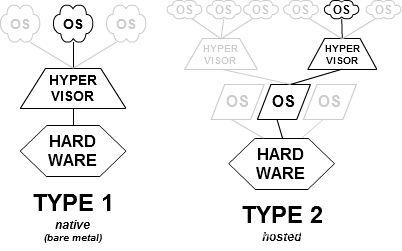
3.3 Virtualisation techniques
-
full virtualisation
guest OS 直接与“硬件”对话,性能损耗大
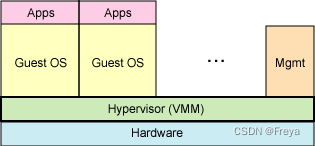
-
HVM(硬件辅助虚拟化)
不完全依赖host OS来模拟硬件设备,采用微处理器架构的一些指令来辅助硬件虚拟化 -
partial virtualisation
guest OS知道并直接与host OS对话,例KVM
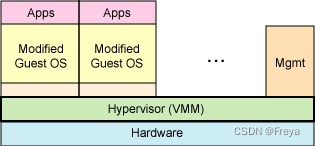
-
全虚拟化和部分虚拟化的对比 slide8 P19
-
hybrid virtualisation slide8 P20
-
XEN, VMware ESX, KVM, VirtualBox slide8 P23
3.3 Mobile Virtualisation
- 分类 slide9 P9
3.4 Cloud Computing
- 定义(5特征) slide10 P19
- 对比传统
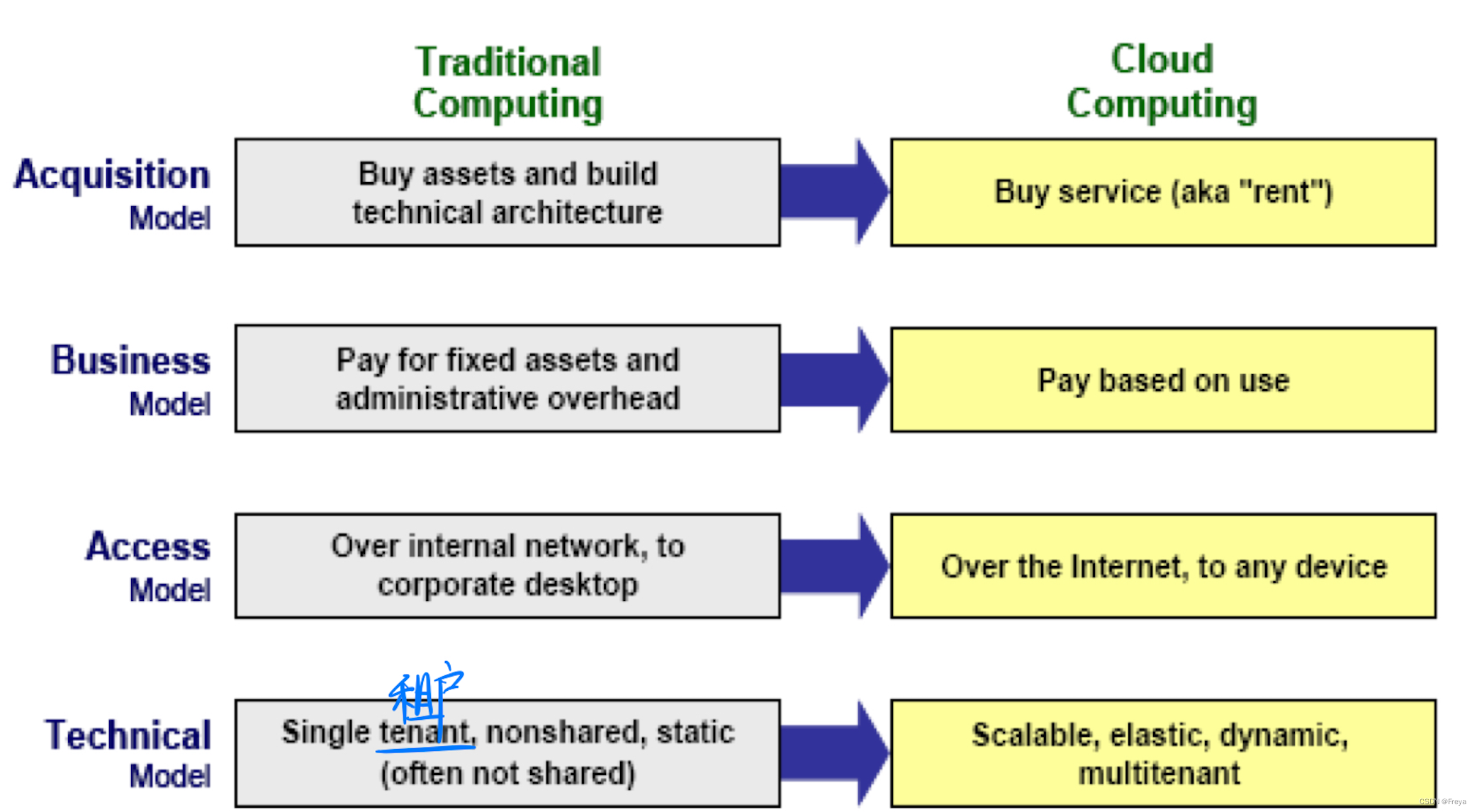
- typical cloud computing architecture slide10 P27
- 两个云计算平台:OpenNebula, OpenStack
4. Big Data Systems
4.1 history, BD定义(5V)slide11 P18
4.2 BDS Architectures
- distribution 分布式架构 slide12 P6
- layered 层级架构 slide12 P7
- BD vs Traditional slide12 P19
4.2 BDS Source
- Industry 4.0: (I)IoT, digital integration, Big Data, AI, etc.
- edge computing slide13 P8
- key techniques slide13 P14
4.3 MapReduce
- 定义:分布式计算框架(思想就是分而治之)
- MapReduce in Hadoop slide14 P27 示例
另一个示例:Finding friends slide14 P30
4.4 Hadoop
-
定义:
Hadoop 是一种分析和处理大数据的软件平台,是一个用 Java 语言实现的 Apache 的开源软件框架,在大量计算机组成的集群中实现了对海量数据的分布式计算。
Hadoop 采用 MapReduce 分布式计算框架,根据 GFS 原理开发了 HDFS(分布式文件系统),并根据 BigTable 原理开发了 HBase 数据存储系统。
-
basic Hadoop architecture slide15 P9
4.5 HDFS
-
定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目 录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务 器有各自的角色。 HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变。 -
HDFS架构
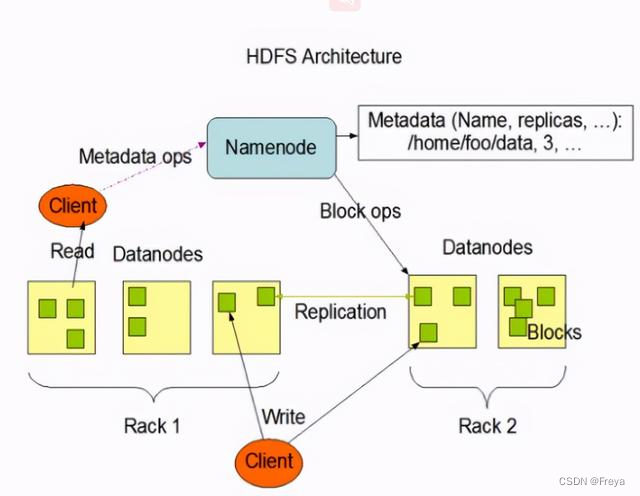

-
Rack awareness slide15 P17
-
重复制丢失副本 slide15 P23
-
Hadoop优缺点
HDFS优点
高容错性 数据自动保存多个副本。它通过增加副本的形式,提高容错性, 某一个副本丢失以后,它可以自动恢复。
适合处理大数据 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据; 某一个副本丢失以后,它可以自动恢复。文件规模:能够处理百万规模以上的文件数量,数量相当之大。
可构建在廉价机器上,通过多副本机制,提高可靠性。
HDFS缺点
不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
无法高效对大量小文件进行存储。存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
不支持并发写入、文件随机修改。 一个文件只能有一个写,不允许多个线程同时写;仅支持数据append(追加),不支持文件的随机修改。
-
Secondary NameNode slide15 P25
-
client从HDFS中读 slide15 P26
-
DataNode从HDFS中读 slide15 P27
-
Hadoop2 slide16 P7
-
YARN slide16 P14
-
App submission in YARN slide16 P17
-
Balancer slide16 P26
4.6 Apache Spark
-
Why
Hadoop MapReduce 是一种用于处理大数据集的编程模型,它采用并行的分布式算法。开发人员可以编写高度并行化的运算符,而不用担心工作分配和容错能力。不过,MapReduce 所面对的一项挑战是它要通过连续多步骤流程来运行某项作业。在每个步骤中,MapReduce 要读取来自集群的数据,执行操作,并将结果写到 HDFS。因为每个步骤都需要磁盘读取和写入,磁盘 I/O 的延迟会导致 MapReduce 作业变慢。
开发 Spark 的初衷就是为了突破 MapReduce 的这些限制,它可以执行内存中处理,减少作业中的步骤数量,并且跨多项并行操作对数据进行重用。借助于 Spark,将数据读取到内存、执行操作和写回结果仅需要一个步骤,大大地加快了执行的速度。Spark 还能使用内存中缓存显著加快在相同数据集上重复调用某函数的机器学习算法的速度,进而重新使用数据。数据重用通过在弹性分布式数据集 (RDD) 上创建数据抽象—DataFrames 得以实现,而弹性分布式数据集是一个缓存在内存中并在多项 Spark 操作中重新使用的对象集合。它大幅缩短了延迟,使 Spark 比 MapReduce 快数倍,在进行机器学习和交互式分析时尤其明显。
-
Spark Core slide17 P14
RDD operations slide17 P18
Spark性能的主要提升是对内存数据的迭代 -
Spark Streaming
traditional vs continuous operator model slide17 P26
discretised streams slide17 P30
DSP benefits slide17 P32
4.7 Apache Storm
hadoop是非常优秀的大数据处理架构,有HDFS和MapReduce的大量存储,有MapReduce的计算,但是不能用来处理流数据完成流计算,只能用于批处理计算。
-
Topologies
Spout:被认为是一个或多个Stream的源头,可以是Mysql等数据库或者网络日志信息等。将这些数据源的信息转换成实际的Tuple流。

Blot:被认为是数据处理逻辑
-
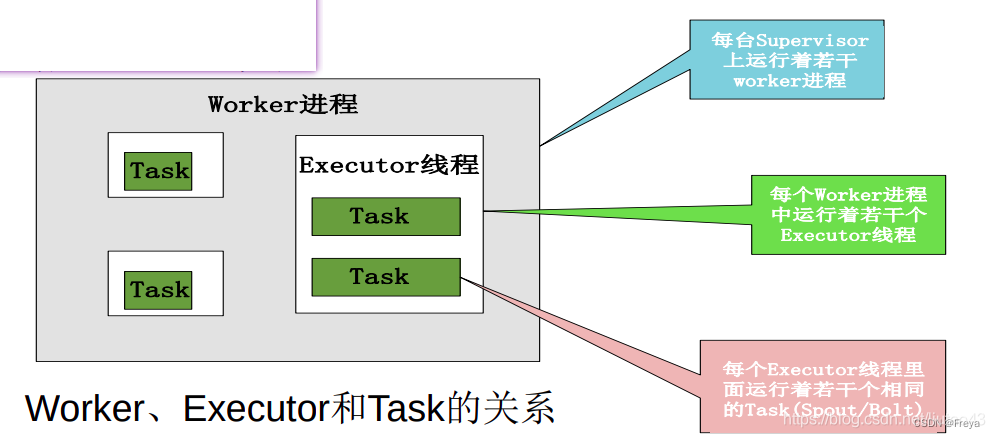
worker, executor, task
Worker进程:Worker由Supervisor负责启动,一个Worker中可以有多个Executor线程,每个Executor线程中又可包含一个或多个Task,Task包括了用户处理逻辑。实际的数据处理是Task完成的。
-
基本架构
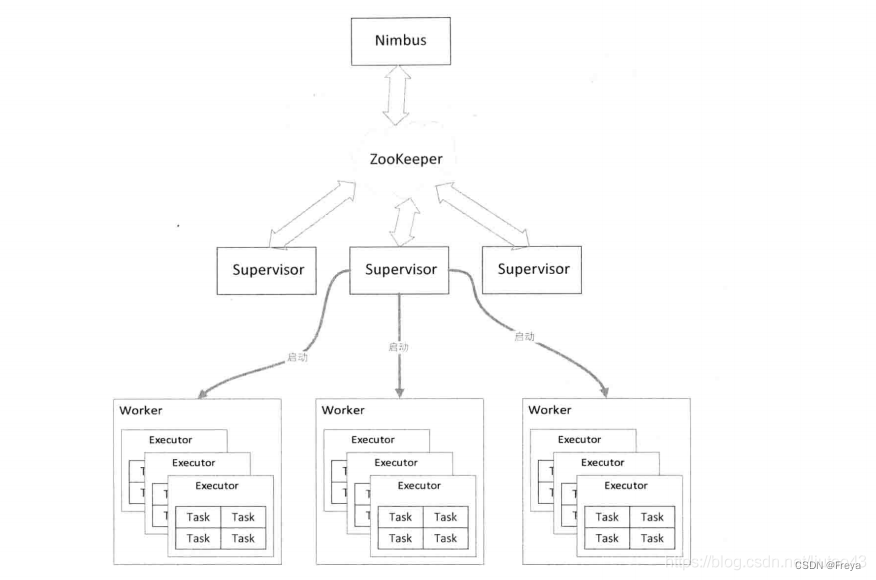
Nimbus是主结点运行的后台进程,负责在集群分发代码,布置任务,监测故障。Supervisor是从结点运行的后台进程,用于监听工作,开始和终止工作进进程。
Nimbus与Supervisor之间的协调工作是通过ZooKeeper来完成,Nimbus和Superviso所在的结点并不直接通信,而是由Zookeeper将其状态信息放入本地磁盘或Zookeeper中,一旦发生故障,会通过ZooKeeper来恢复。就算Nimbus和Supervisor被终止,也可以恢复到以前的状态。
-
Apache Storm工作流程
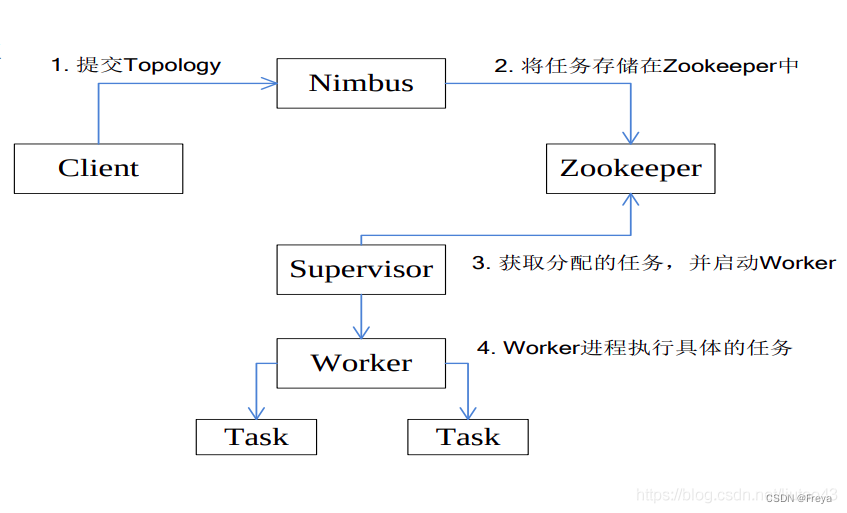 所有Topology任务的提交必须在Storm客户端节点(可以认为自己编写程序所在的机器)上进行,提交到Nimbus
所有Topology任务的提交必须在Storm客户端节点(可以认为自己编写程序所在的机器)上进行,提交到NimbusNimbus节点首先将提交的Topology进行分片,分成一个个Task,通过Zookeeper分配给对应的Supervisor,并将Task和Supervisor映射关系信息表提交到Zookeeper集群上
Supervisor会主动去Zookeeper所在集群上认领自己的Task,通知自己的Worker进程进行Task的处理
Supervisor启动Worker,然后启动相应的Executor处理Task
-
stream grouping
Stream Grouping:定义了消息分发策略,也定义了Blot以什么形式接收数据,告知Topology如何在Spout和Blot之间传送Tuple会这不同Blot之间传送Tuple。每一个Spout和Blot都可以有多个Task,一个Task如何发送Tuple就是由Stream Grouping决定的。
随机分组(Shuffle Grouping, 随机分组 ):保证每一个Blot和Task接收Tuple数量大概一样
根据字段值分配(Fields Grouping, 字段分组 ): 按照相同字段下的值对应的Tuple分配到一个Task中
广播(AllGrouping, 全部分组 ),所有Task都会收到Tuple
全局分组 ( GlobalGrouping,全局分组 ),所有Tuple总是发给同一个Task
不关心数据是如何分组的(None Grouping, 无分组 ),和随机分组类似
直接分组( DirectGrouping, 直接分组 )由自定义逻辑来决定,即由消息发送者决定应该由消息接收者组件的哪个Task来处理该消息。
19年试卷
Q1(a)
facebook功能介绍
batch processing vs stream processing
(b) how to choose big data platforms?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









