







DeepSeek V3 已经正式发布,而且毫不犹豫的把模型与技术报告全开源,不但用600刀完成了老美1个亿才能搞定的模型训练,而且训练出的模型还碾压GPT-4o、Claude Sonnet这些之前号称非常牛X的模型。
所以,最近掀起了全球关于deepseek研究和谈论的热潮。
这也是国产AI在国际上掀起的一次最大的巨浪。
而且,标志着,中国,在AIGC领域,不再是紧随其后,而是开始步入了,遥遥领先!!!
所以说,deepseek的成功,有非常重大的意义。洋哥非常有眼光,号召大家针对deepseek写复盘总结。
自从deepseek出来之后,我已经连续用它做了很多事情,也写了几篇文章了,都放到星球里了。
这篇文章,为大家分享如果进行deepseek的本地部署。
deepseek的牛逼之处
deepseek 通过近 600 万美刀的成本,加上 2000 张显卡,实现了 openai 上亿成本的效果
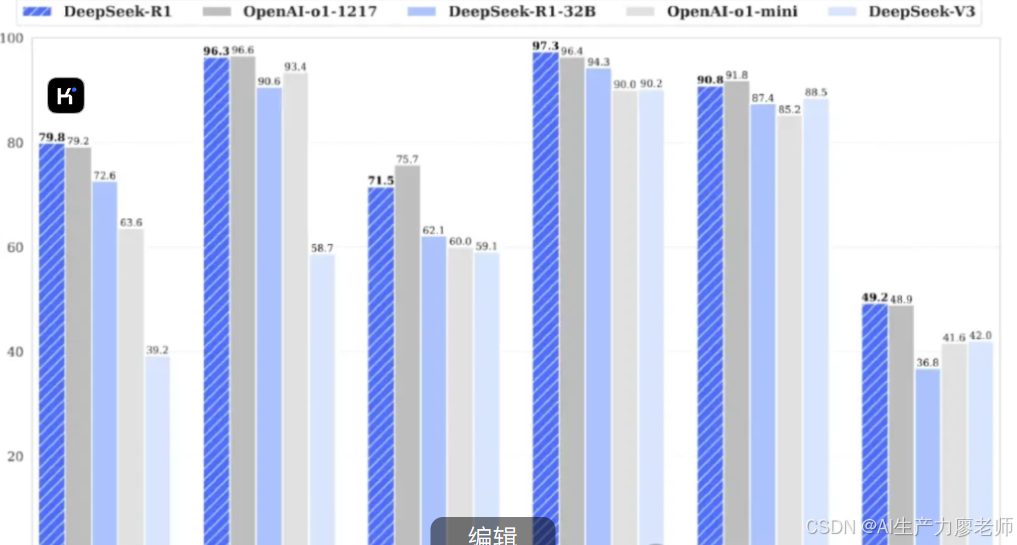
DeepSeek-R1 是一款非常厉害的 AI 模型,到底厉害在什么地方呢?虽然下面的内容有一点专业,但我尽量用大白话给大家解释清楚,我觉得我们了解一个模型,就应该知道一些它的核心特点,不然就是人云亦云。
可以用以下几点来概括:
- 训练方法更聪明,成本更低:
DeepSeek-R1 没有用传统的训练方式,而是采用了强化学习(RL)。这种方法不仅省钱,还能让模型自己学会更复杂的推理能力。比如,它在数学和编程任务中表现得特别出色,能够解决很多复杂的问题。
- 性能超强,媲美顶级模型:
在各种权威测试中,DeepSeek-R1 的表现和 OpenAI 的顶级模型不相上下,甚至更好。比如,在 AIME 2024 测试中,它的准确率达到了 79.8%;在 MATH-500 测试中,更是高达 97.3%。在编程测试中,它的水平甚至超过了大多数人类程序员。
- 开源且便宜,人人都能用:
DeepSeek-R1 是开源的,采用了 MIT 许可证,这意味着任何人都可以自由使用、修改和优化它。而且它的使用成本非常低,每百万代币的输入费用只要 0.55 美元,输出费用也只要 2.19 美元,比 OpenAI 便宜很多,让更多人和企业都能用得起 AI 技术。
- 多阶段训练,推理能力更强:
DeepSeek-R1 还采用了多阶段的训练方法,结合了冷启动数据、强化学习和监督数据。这让它在处理复杂任务时表现得更好,尤其是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









