






1. 前端开发中常见的拖拽排序效果视频:https://www.bilibili.com/video/BV1Jm4y1M79D/?spm_id_from=333.880.my_history.page.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70
2.axios请求二次封装都做些什么视频:https://www.bilibili.com/video/BV1fg4y1M7pe/?spm_id_from=333.880.my_history.page.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70
3.Vue axios 前端接口请求封装API视频:https://www.bilibili.com/video/BV18R4y1J7sm/?spm_id_from=333.880.my_history.page.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70
4.项目上线打包优化:https://www.bilibili.com/video/BV1z34y1T7ez/?spm_id_from=333.788&vd_source=5c584bd3b474d579d0bbbffdf0437c70
5.使用nginx部署vue项目及常见问题:https://www.bilibili.com/video/BV1x84y1k7qf/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70
6.es6 class的使用参考文章:https://juejin.cn/post/6964312782552432670
7.图片加水印:https://juejin.cn/post/6844903645155164174(网页加水印)
https://juejin.cn/post/7236286358389047354
8.开发中的难点亮点:https://juejin.cn/post/7074573053979525151
9.react hooks的学习视频:https://www.bilibili.com/video/BV1ZB4y1Z7o8/?spm_id_from=333.337.search-card.all.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70 , https://www.bilibili.com/video/BV1sV411c7u9/?spm_id_from=autoNext&vd_source=5c584bd3b474d579d0bbbffdf0437c70
10.react开发中,结合useState(list)给数组排序可以使用 lodash这个库来使用。lodash官网:lodash.com / lodash.com/docs/
11.react开发中,className动态添加类名可以加载classnames包:使用方法在下面
12.vue自定义指令与修饰符文章:https://blog.youkuaiyun.com/m0_71485750/article/details/126175776
13.react全家桶+底层原理:https://www.bilibili.com/video/BV17e411r7TH/?spm_id_from=333.337.search-card.all.click&vd_source=5c584bd3b474d579d0bbbffdf0437c70
上述11点,使用classnames包的方法
1.命令安装classnames包
npm install classnames
2.在组件中引入
import classNames from 'classname';
3.在组件内使用, ‘’包裹的是静态的class,
{
// active是动态的class名,值是判断条件,是否需要加active这个class
active: type === item.type
}包裹的是动态的class
从这样的:nav-item为静态class类名,active为动态class类名
<span className={`nav-item ${type === item.type && 'active'}`}>span...</span>
变成这样:
<span className = {classNames('nav-item', {
active: type === item.type
})}>span...</span>
1、webpack是什么?
webpack是一个用于现代javascript应用程序的 静态模块打包工具。当webpack处理应用程序时,它会在内部从一个或多个入口点构建一个依赖图,然后将项目中所需的每一个模块组合成一个或多个包(bundles),他们均为静态资源,用于展示内容。
2、webpack中loader和plugin的作用是什么?
loader: loader让webpack能够去处理那些非javescript文件(webpack自身只理解javascript)
plugins:插件(plugins)可以用于执行范围更广的任务。插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量等。
3、说一下原型链和继承?
(1)每个构造函数都有一个原型对象,原型对象都包含指向构造函数的指针,而实例都包含一个指向原型对象的内部指针(proto)
(2)一个对象会指向一个原型,原型对象会有自己的原型,以此类推,构成原型链
(3)实例使用方法和属性时,会先从构造函数内部找,找不到再去原型对象上找,还找不到就去原型对象的原型上找,直到(原型对象的原型为null) Object.prototype.proto===null,停止寻找
继承:(4)继承是指能够访问另外一个对象中的方法和属性。
4、js去重你能想到多少种方法?
(1)Array.from(new Set(array))
(2)newArray.filter 返回[item]/newArray.find 返回item项
(3)newArray.include(旧item) 返回true/false
(4)使用对象属性名的唯一性来保证不重复 let obj = {} if(!obj[array[i]]) { result[array[i]] = true } Object.keys(obj);
(5)使用indexOf(item) === -1, newArray.indexOf(arr1[i]) === -1
(6)使用Map数据结构去重: let map = new Map(); if (map.has(array[i])) {map.set(array[i], true)}
5、js中this的指向
(1)全局环境下指向widow,严格模式下undenfind, 函数也指向window。
(2)对象内部方法的this指向调用这些方法的对象,也就是谁调用就指向谁。
(3)箭头函数中的this指向于函数作用域所用的对象。
(4)构造函数中的this是指向实例
更改this指向:call / apply / bind()方法
6、promise的用法?你在什么情况下会使用promise?
用法(Promise对象是一个构造函数,用来生成Promise实例)
let p = function () {return new Promise((resolve,reject) => {resolve(‘需要返回出去的值’)})}
p.then(data => {})
7、node是如何处理高并发的
(1)事件循环机制:
Node.js采用事件驱动机制,通过事件轮询的方式实现异步I/O操作。当有异步I/O操作完成时,会将对应的事件加入到事件队列中,由事件循环机制负责调度执行。事件循环机制是Node.js实现高并发的核心,它能够充分利用CPU资源,减少I/O的阻塞等待时间,提高了处理请求的效率。
(2)非阻塞I/O:
Node.js采用非阻塞I/O,避免了I/O的阻塞等待时间,从而提高程序的并发性能。非阻塞I/O是指在进行I/O操作时,不会阻塞后续代码的执行,而是在后台等待I/O操作完成后立即返回结果。这种方式可以减少线程切换的开销,提高了整个应用程序的执行效率。
(3)事件驱动回调函数:
Node.js采用事件驱动回调函数,使得应用程序能够及时响应用户的请求。通过这种方式,当用户请求进入系统时,会获取一个事件处理器,并注册一个回调函数,当事件处理器产生事件时,会自动调用注册的回调函数进行处理。这种方式能够提高系统的响应速度和处理能力。
(4)内置异步模块:
Node.js内置的异步模块也是实现高并发的关键。Node.js提供了各种内置的异步模块,例如HTTP、HTTPS、FS、Net等,这些模块都是通过事件循环机制结合非阻塞I/O实现的,可以在高并发的情况下高效地处理请求。
(5)Cluster模块:
Cluster是Node.js中用于多进程处理的模块。该模块可以启用多个子进程来处理请求,从而提高应用程序的并发性能。每个子进程都是独立的,因此可以充分利用CPU资源,提高系统的处理能力。使用Cluster模块可以有效地解决单线程模型下的瓶颈问题,使得系统能够更加高效地处理大量的请求。
8、介绍一下node中require模块的加载机制
模块在第一次加载后会被缓存。这也意味着多次调用require()不会导致模块的代码被多次执行。
(1)内置模块的加载优先级最高:例如,require(‘fs’) 始终返回内置的 fs 模块,即使在 node_modules 目录下有名字相同的包也叫做 fs。
(2)自定义模块的加载机制:
使用 require() 加载自定义模块时,必须指定以 ./ 或 …/ 开头的路径标识符。在加载自定义模块时,如果没有指定 ./ 或 …/ 这样的路径标识符,则 node 会把它当作内置模块或第三方模块进行加载。
同时,在使用 require() 导入自定义模块时,如果省略了文件的扩展名,则 Node.js 会按顺序分别尝试加载以下的文件:
1.按照确切的文件名进行加载
2.补全 .js 扩展名进行加载
3.补全 .json 扩展名进行加载
4.补全 .node 扩展名进行加载
5.加载失败,终端报错
(3)第三方模块的加载机制:如果传递给 require() 的模块标识符不是一个内置模块,也没有以 ‘./’ 或 ‘…/’ 开头,则 Node.js 会从当前模块的父目录开始,尝试从 /node_modules 文件夹中加载第三方模块。
例如,假设在 ‘C:\Users\itheima\project\foo.js’ 文件里调用了 require(‘tools’),则 Node.js 会按以下顺序查找:
C:\Users\itheima\project\node_modules\tools
C:\Users\itheima\node_modules\tools
C:\Users\node_modules\tools
C:\node_modules\tools
(4)目录作为模块:当把目录作为模块标识符,传递给 require() 进行加载的时候,有三种加载方式:
在被加载的目录下查找一个叫做 package.json 的文件,并寻找 main 属性,作为 require() 加载的入口
如果目录里没有 package.json 文件,或者 main 入口不存在或无法解析,则 Node.js 将会试图加载目录下的 index.js 文件。
如果以上两步都失败了,则 Node.js 会在终端打印错误消息,报告模块的缺失:Error: Cannot find module ‘xxx’
9、闭包的作用是什么?你能举个使用闭包的例子吗?
(1)延长局部变量的寿命
(2)使外部能够访问到函数内部的变量
例子: 如果一个属性是全局变量,不想让人直接访问,局部变量又访问不到时,暴露一个函数让间接访问;
function(){
var lives = 50
window.奖励一条命 = function(){ // 简明起见,用了中文
lives += 1
}
window.死一条命 = function(){
lives -= 1
}
}()
10、当在浏览器输入url后,发生了些什么?
(1)URL 解析:浏览器首先对 URL 解析,解析出协议、域名、端口、资源路径、参数等。
(2)DNS 域名解析:首先需要将一个域名转化为相应的 IP 地址
(3)建立TCP连接
(4)发送HTTP请求:当浏览器与服务器建立连接后,就可以进行数据通信过程,浏览器会给服务器发送一个 HTTP 请求报文,请求报文包括请求行、请求头、请求空行和请求体。在请求行中会指定方法、资源路径以及 HTTP 版本,其中资源路径是指定所要操作资源在服务器中的位置,而方法是指定要对这个资源做什么样的操作。
(5)服务器对请求进行处理并作出响应
(6)浏览器解析渲染页面
(7)断开TCP连接
注意:
浏览器为了提升性能,在 URL 解析之后,实际会先查询是否有缓存,如果缓存命中,则直接返回缓存资源。
如果是 HTTPS 协议,在建立 TCP 连接之后,还需要进行 SSL/TLS 握手过程,以协商出一个会话密钥,用于消息加密,提升安全性。
11、说下vue的生命周期
Vue的生命周期钩子函数主要包括:
- 1.beforeCreate(): 在实例初始化之后调用, data和methods都还没有初始化完成, 通过this不能访问
- 2.created(): 此时data和methods都已初始化完成, 可以通过this去操作, 可以在此发ajax请求
- 3.beforeMount(): 模板已经在内存中编译, 但还没有挂载到页面上, 不能通过ref找到对应的标签对象
- 4.mounted(): 页面已经初始显示, 可以通过ref找到对应的标签, 也可以选择此时发ajax请求
- 5.beforeUpdate(): 在数据更新之后, 界面更新前调用, 只能访问到原有的界面
- 6.updated(): 在界面更新之后调用, 此时可以访问最新的界面
- 7.beforeDestroy(): 实例销毁之前调用, 此时实例仍然可以正常工作
- 8.destroyed(): Vue 实例销毁后调用, 实例已经无法正常工作了
- 9.deactivated():组件失活, 但没有死亡
- 10.activated(): 组件激活, 被复用
- 11.errorCaptured(): 用于捕获子组件的错误,return false可以阻止错误向上冒泡(传递)
- 我们通常在created()/mounted()进行发送ajax请求,启动定时器等异步任务,而在beforeDestory()做收尾工作,如: 清除定时器操作。
不过需要注意的是mounted生命周期钩子中并不代表界面已经渲染成功,因为 mounted 不会保证所有的子组件也都一起被挂载。如果你希望等到整个视图都渲染完毕,可以在 mounted 内部使用 vm.$nextTick。
js面试题:
<div ref="text"></dev>
beforeMouted() {
console.log(this.$refs.text); // 会打印什么
}
mouted() {
console.log(this.$refs.text); // 会打印什么
}
12、怎样判断在屏幕的可视化区域
- offsetTop、scrollTop
- getBoundingClientRect
- Intersection Observer
<body>
<div class="box1">
<!-- offsetTop, scrollTop -->
<!-- getBoundingClientRect -->
<!-- IntersectionObserver -->
</div>
<div class="box2" id="box2">123456</div>
<style>
.box1 {
height: 1000px;
}
</style>
</body>
<script>
console.log(window.innerHeight)
console.log(document.getElementById('box2').offsetTop)
console.log(document.documentElement.scrollTop)
console.log(document.getElementById('box2').getBoundingClientRect())
// 方法一:offsetTop - scrollTop <= window.innerHeight;
function isInViewPortOfOne(el) {
// viewPortHeight 兼容所有浏览器写法
const viewPortHeight = window.innerHeight || document.documentElement.clientHeight || document.body.clientHeight;
const offsetTop = el.offsetTop;
const scrollTop = document.documentElement.scrollTop;
const top = offsetTop - scrollTop;
return top <= viewPortHeight;
}
// 方法二:getBoundingClientRect
// {
// top, // 元素顶部距离屏幕顶部的距离
// bottom, // 元素底部距离屏幕顶部的距离
// left, // 元素左边距离屏幕左边的距离
// right, // 元素右边距离屏幕右边的距离
// x,
// y,
// width,
// height, // 元素的宽和高
// }
/**
* 1.top 大于等于0
* 2.left大于等于0
* 3.bottom小于等于视窗高度
* 4.right小于等于视窗宽度
*/
function isInViewPortOfOne(el) {
const viewWidth = window.innerWidth || document.document.clientWidth;
const viewHeight = window.innerHeight || document.document.clientHeight;
const {
top,
right,
bottom,
left,
} = el.getBoundingClientRect();
return (
top >= 0 &&
left >= 0 &&
right <= viewWidth &&
bottom <= viewHeight
)
}
// 以上方法可以实现,但是需要监听浏览器滚动,需要有大量计算
// 方法三:Intersection Observer 浏览器原生提供的构造函数,接收两个参数,callback和options
// callback会触发两次,元素刚进入可视区域时,元素完全看不到时
const intersectionObserver = new IntersectionObserver(function (entries) {
if (entries[0].intersectionRatio <= 0) return; // 小于0完全不可见,0-1部分可见,大于等于1完全可见
console.log('已经进入可视区域');
})
// 开始观察,监听元素
intersectionObserver.observe(document.getElementById('box2'));
// 停止观察
intersectionObserver.unobserve(document.getElementById('box2'));
// 关闭观察器
intersectionObserver.disconnect();
</script>
13、说下如下代码的值
let a= {
name: 'A',
fun: function() {
console.log(this.name);
}
}
console.log(a.fun()); // A
console.log(a.fun.call({name: 'B'})); // B
let f1 = a.fun();
console.log(f1); // A
console.log(typeof undefined) // undefined
console.log(typeof null) // object
console.log(typeof console.log) // function
console.log(typeof [1, 2, 3]) // object
console.log(typeof '123') // string
console.log(typeof 123) // number
13.promise用过什么方法?
promise.all
promise.resolve
promise.reject
promise.race 与 all的区别
promise还有async和await
面试题:Promise.all一个请求失败也能得到其余正确的请求结果
参考文章:https://blog.csdn.net/qq_43592064/article/details/130829067
Promise.all默认只要有一个错误就直接返回错误。promise.all中任何一个promise 出现错误的时候都会执行reject,导致其它正常返回的数据也无法使用
Promise.all(
[
Promise.reject({ code: 500, msg: "服务异常" }),
Promise.resolve({ code: 200, list: [] }),
Promise.resolve({ code: 200, list: [] })
].map(p => p.catch(e => e))
)
.then(res => {
console.log("res=>", res);
})
.catch(error => {
console.log("error=>", error);
});
res=> [ { code: 500, msg: '服务异常' },
{ code: 200, list: [] },
{ code: 200, list: [] } ]
核心内容是map方法,map的每一项都是promise,catch方法返回值会被promise.reslove()包裹,这样传进promise.all的数据都是resolved状态的。
// 使用Promise.all 其中id为69的商品,返回失败,会导致整个Promise接受到reject状态.
// 所以进行改造, p catch 得到的err 为返回失败抛出的信息, 进行置空
.map(p => p.catch(err => '')))
14.ajax,axios请求应该放在created里还是mounted里?放在creacted里会造成什么影响?
参考视频
vue的created和mounted是同步执行,会先执行created里面的同步代码,然后把请求当成微任务挂起(先发送请求padding状态),然后再执行mounted里的同步代码,mounted里的代码执行完毕后,会渲染页面。请求结果才接收到,当收到结果后有更新data里面的数据,那么会再渲染一次。
看一下代码
<template>
<div>
<ul>
<li v-for="item in cityList" :key="item.id">{{item.name}}</li>
</ul>
</div>
</template>
<script>
export default {
data() {
cityList: [],
},
created() {
conslole.log('created');
alert('created'); // 会阻止后续代码运行
this.getCityList();
},
mounted() {
conslole.log('mounted');
alert('mounted'); // 会阻止后续代码运行
},
methods: {
async getCityList() {
const res = await axions({...});
this.cityList = res.data.list;
}
}
}
</script>
执行上面代码顺序为:
conslole.log(‘created’);
alert(‘created’);
this.getCityList();发送请求,但是请求状态为padding,挂起等待状态
再执行mounted的代码
conslole.log(‘mounted’);
alert(‘mounted’); // mounted代码执行完毕加载页面,组件首次渲染
最后this.getCityList();请求执行完毕获取数据,组件重新渲染,刷新页面,所以会刷新两次页面
另外观点:参考文章:https://blog.youkuaiyun.com/dongwei666/article/details/126364290
总结:如果无需操作dom,可以在created里面进行请求,数据与dom同步渲染,减少渲染次数,但是不可过多请求,否则屏幕将会出现白屏
如果有dom操作就在mounted里面请求,也不可过多请求,否则渲染次数过多
15.怎么验证用户有没有登录?路由守卫怎么设置?
- 直接在配置路由的地方设置beforeEnter()方法
export default new Router({
routes: [
{
path: '/login',
name: 'login',
component: Login
},
{
path: '/register',
name: 'register',
component: Register, // component: () => import 'xxx/xx.vue'
beforeEnter(to, from, next) {
console.log(to);
console.log(from);
console.log(next);
next(); // 放行,必须有,否则跳不到页面
next(false); // 禁止跳转路由点击无效
if (from.path === '/login') {
next(); // 如果从登录页面来的注册页面就放行跳到注册页面
} else {
// 重定向
next('/login'); // 如果不是,重定向到登录页面
}
}
}
]
})
- 使用router.beforeEach()方法
const router = new Router({
router: [
{
path: '/login',
name: 'Login',
component: 组件/ import 'xx/xx.vue'
}
]
})
router.beforeEach((to,from, next) => {
...
next();
})
16.说下原型和原型链
-
什么是原型?
在js中,每个构造函数内部都有一个prototype属性,该属性的值是个对象,该对象包含了该构造函数所有实例共享的属性和方法。当我们通过构造函数创建对象的时候,在这个对象中有一个指针,这个指针指向构造函数的prototype的值,我们将这个指向prototype的指针称为原型。或者用另一种简单却难理解的说法是:js中的对象都有一个特殊的[[Prototype]]内置属性,其实这就是原型。(简单来说原型就是对象或者函数下面的prototype属性) -
如何获取对象原型值?
- 在浏览器上可以使用__proto__,例如
a.__proto__ - 推荐使用Object.getPrototypeOf(a)
- 原型链?
JS的每个函数在创建的时候,都会生成一个属性prototype,这个属性指向一个对象,这个对象就是此函数的原型对象。该原型对象中有个属性为constructor,指向该函数。这样原型对象和它的函数之间就产生了联系。
17.new关键字做了什么?
构造函数创建一个实例的过程
- 创建一个新对象
- 将构造函数的作用域赋值给新对象(这样this就指向了新对象)
- 执行构造函数中的代码(为新对象添加实例属性和实例方法)
- 返回新对象
18. watch与computed的区别?
功能上:
- computed是计算属性,watch是监听一个值的变化,然后执行对应的回调。
- 是否调用缓存:computed中的函数所依赖的属性没有发生变化,那么调用当前的函数的时候会从缓存中读取,而watch在每次监听的值发生变化的时候都会执行回调。
- 是否调用return:computed中的函数必须要用return返回,watch中的函数不是必须要用return。
- computed默认第一次加载的时候就开始监听;watch默认第一次加载不做监听,如果需要第一次加载做监听,添加immediate属性,设置为true(immediate:true)
- 区别总结:
computed支持缓存,相依赖的数据发生改变才会重新计算;watch不支持缓存,只要监听的数据变化就会触发相应操作
computed不支持异步,当computed内有异步操作时是无法监听数据变化的;watch支持异步操作
computed属性的属性值是一函数,函数返回值为属性的属性值,computed中每个属性都可以设置set与get方法。watch监听的数据必须是data中声明过或父组件传递过来的props中的数据,当数据变化时,触发监听器
使用场景:
computed----当一个属性受多个属性影响的时候,使用computed-----购物车商品结算。watch–当一条数据影响多条数据的时候,使用watch-----搜索框.
19. px, rpx, em, rem有什么不同?
参考文档:https://zhuanlan.zhihu.com/p/156940153
- px: 相对长度单位。像素px是相对于显示器屏幕分辨率而言的。
- rpx: 其实是微信对于rem的一种应用的规定,或者说一种设计的方案,官方上规定屏幕宽度为20rem,规定屏幕宽为750rpx。
所以在微信小程序中1rem=750/20rpx。 - em: 相对长度单位。相对于当前对象内文本的字体尺寸。如当前对行内文本的字体尺寸未被人为设置,则相对于浏览器的默认字体尺寸。浏览器默认的字号是16px。所有未经调整的浏览器都符合: 1em=16px。
em的特点:
em的值并不是固定的;
em会继承父级元素的字体大小。
因为这两个特点,所以我们用em的时候,需要注意三点:
body选择器中声明Font-size=62.5%;
将你的原来的px数值除以10,然后换上em作为单位;
重新计算那些被放大的字体的em数值。避免字体大小的重复声明。 - rem: rem是相对于根元素,也就是说,我们只需要在根元素确定一个参考值,其他子元素的值可以根据这个参考值来转换。具体这个参考值设置为多少,完全可以根据我们自己的需求来定。
用法:
rem用法:以html根元素设置参考值
html {
font-size: 10px;
}
div {
font-size: 4rem; /* 40px */
width: 20rem; /* 200px */
height: 20rem;
}
p {
font-size: 2rem; /* 20px */
width: 10rem;
height: 10rem;
border: solid 1px blue;
}
20. react中class组件与函数组件有什么不同?
- 定义方式不同:
class组件定义:class Xxx extends React.Compont {} 继承React.Component,且需要创建render方法来返回元素。
函数组件: function Xxx() {} 函数组件名字必须大写 - class:
- 有组件实例
- 有生命周期
- 有 state 和 setState
- 有ref
- 函数组件:
- 没有组件实例
- 没有生命周期, 需要使用hook的 useEffect
hooks函数组件的缺点: 没法保存state, 如需保存state,则需要使用useRef(); - 没有 state 和 setState,只能接收 props
- 函数组件是一个纯函数,执行完即销毁,无法存储 state
- 没有ref,但可以在函数组件内部使用 ref 属性,只要它指向一个 DOM 元素或 class 组件。
class 组件存在的问题:
大型组件很难拆分和重构,变得难以测试
相同业务逻辑分散到各个方法中,可能会变得混乱
复用逻辑可能变得复杂,如 HOC 、Render Props
所以 react 中更提倡函数式编程,因为函数更灵活,更易拆分,但函数组件太简单,所以出现了hook,hook就是用来增强函数组件功能的。
21. 原生小程序和uniapp小程序中有哪些生命周期钩子
参考:http://jerryzou.com/posts/cookie-and-web-storage/
原生小程序生命周期构子:
- onLoad :页面加载时触发
- onShow : 页面显示时触发 , 包括页面初次加载 , 从其他页面返回到当前页面
- onReady : 页面初次渲染完成时触发
- onHide : 页面隐藏时触发 , 当跳转到其他页面,关闭当前页面触发
- onUnload:页面卸载时触发,当页面销毁时触发。
- onPullDownRefresh : 下拉刷新时触发
- onReachBottom:滚动到页面底部时触发。
- onShareAppMessage:点击页面转发按钮时触发。
- onPageScroll:页面滚动时触发。
- onTabItemTap:点击底部tab栏时触发。
uniapp小程序生命周期钩子:
- onLoad:页面加载时触发。
- onReady:页面初次渲染完成时触发。
- onShow:页面显示时触发,包括页面初次加载、从其他页面返回到当前页面。
- onHide:页面隐藏时触发,当跳转到其他页面、关闭当前页面时触发。
- onUnload:页面卸载时触发,当页面销毁时触发。
- onPullDownRefresh:下拉刷新时触发。
- onReachBottom:滚动到页面底部时触发。
- onShareAppMessage:点击页面转发按钮时触发。
- onResize:页面尺寸变化时触发。
- onTabItemTap:点击底部tab栏时触发。
22. cookie、sessionStorage、localStorage的区别
- cookie: 由服务器生成,大小限制为4KB左右, cookie在与服务器端通信每次都会携带在HTTP头中,可设置失效时间
- sessionStorage:在客户端生成,它只是可以将一部分数据在当前会话中保存下来,刷新页面数据依旧存在。但当页面关闭后,sessionStorage 中的数据就会被清空。
- localStorage:在客户端生成,localStorage除非被清除,否则会永久保存
三者异同
cookie 一般由服务器生成,可设置失效时间。如果在浏览器端生成Cookie,默认是关闭浏览器后失效,存放数据大小一般4K左右,而sessionStorage与localStorage大小在5兆左右,在客户端生成,localStorage除非被清除,否则会永久保存,sessionStorage仅在当前会话下有效,关闭页面或浏览器后被清除,cookie在与服务器端通信每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题,而sessionStorage与localStorage仅在客户端(即浏览器)中保存,不参与和服务器的通信。
- cookie由服务端生成,用于标识用户身份;而两个storage用于浏览器端缓存数据
- 三者都是键值对的集合
- 一般情况下浏览器端不会修改cookie,但会频繁操作两个storage
- 如果保存了cookie的话,http请求中一定会带上;而两个storage可以由脚本选择性的提交
- 会话的storage会在会话结束后销毁;而local的那个会永久保存直到覆盖。cookie会在过期时间之后销毁。
- 安全性方面,cookie中最好不要放置任何明文的东西。两个storage的数据提交后在服务端一定要校验(其实任何payload和qs里的参数都要校验)。
23. vue3新特性
参考文章:https://juejin.cn/post/6968094627375087653
- 创建app实例方式从原来的new Vue()变为通过createApp函数进行创建;这样带来的变化就是以前在全局配置的组件(Vue.component)、指令(Vue.directive)、混入(Vue.mixin)和插件(Vue.use)等变为直接挂载在实例上的方法;我们通过创建的实例来调用,带来的好处就是一个应用可以有多个Vue实例,不同实例之间的配置也不会相互影响
const app = createApp(App)
app.use(/* ... */)
app.mixin(/* ... */)
app.component(/* ... */)
app.directive(/* ... */)
- 周期函数钩子变化:新增setup钩子函数,在beforeCreate之前执行,将beforeDestroy改名为beforeUnmount,destroyed改名为unmounted
- vue3新增了生命周期钩子,我们可以通过在生命周期函数前加on来访问组件的生命周期:
onBeforeMount
onMounted
onBeforeUpdate
onUpdated
onBeforeUnmount
onUnmounted
onErrorCaptured
onRenderTracked
onRenderTriggered
使用:
import { onBeforeMount, onMounted } from "vue";
export default {
setup() {
console.log("----setup----");
onBeforeMount(() => {
// beforeMount代码执行
});
onMounted(() => {
// mounted代码执行
});
},
}
响应式API:
- ref/reactive
24. 怎么让元素垂直居中
知道父元素高度的:
- 方法一:使用transform来位移元素
<body>
<div class="box">
<div class="box-child">123456</div>
</div>
<style>
.box {
position: relative;
width: 300px;
height: 300px;
}
.box-child {
position: absolute;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
}
</style>
</body>
- 方法二:使用display: flex布局
<body>
<div class="box">
<div class="box-child">123456</div>
</div>
<style>
.box {
display: flex;
justify-content: space-around/center; // space-around/center都可以
align-items: center;
width: 300px;
height: 300px;
}
</style>
</body>
- 方法三:表格,display: table-cell;此元素会作为一个表格单元格显示 类似于td th
<body>
<div class="box">
<div class="box-child">123456</div>
</div>
<style>
.box {
display: table-cell;
text-align: center;
vertical-align: middle;
width: 300px;
height: 300px;
}
.box-child {
vertical-align: middle;
display: inline-block;
}
</style>
</body>
- 方法四:使用postion和margin:auto来设置
注意:此方法需要设置子元素宽高,width,height
<body>
<div class="box">
<div class="box-child">123456</div>
</div>
<style>
.box {
position: relative;
width: 300px;
height: 300px;
}
.box-child {
position: absolute;
width: 50px;
height: 50px;
left: 0;
right: 0;
top: 0;
bottom: 0;
margin: auto;
}
</style>
</body>
- 方法五:子元素设置display: inline-block,父元素设置text-align: center且line-height等于height
将子元素设为行内块元素,父元素设置左右居中,同时通过让父元素的line-height属性等于height属性实现子元素上下居中。
<body>
<div class="box">
<div class="box-child">123456</div>
</div>
<style>
.box {
width: 100vw;
height: 100vh;
line-height: 100vh;
text-align: center;
}
.box-child {
display: inline-block;
}
</style>
</body>
25.如何渲染10万条数据?
- 虚拟列表的方式,getBoundingClientRect判断滚动条是往上还是往下,只渲染可视区域
- 时间分片:window.requestAnimationFrame和document.createDocumentFragment
<script>
<ul id="box"></ul>
const ul = document.getElementById('box');
const totalNum = 1000000;
const onceNum = 20;
const page = totalNum / onceNum
let index = 0;
function loop(curTotal, curIndex) {
if (curTotal <= 0) {
return false;
}
const pageCount = Math.min(curTotal, onceNum);
window.requestAnimationFrame(() => {
let fragment = document.createDocumentFragment();
for (let i = 0; i < pageCount; i++) {
let li = document.createElement('li');
li.innerText = curIndex + i + ':' + ~~(Math.random() * total);
fragment.appendChild(li)
}
ul.appendChild(fragment);
loop(curTotal - pageCount, curIndex + pageCount);
})
}
loop(totalNum, index);
</script>
26.localStorage与sessionStorage的大小是多大?超出了怎么办?indexedDB有了解吗?
大小都在5MB左右
localstorage存储不是5m 是每个域5m 超了申请其他的域/修改ng配置 postmessge通信往其他域上存取,或者清除不需要的存储,压缩或减少体积,或者使用indexedDB
indexedDB参考文章:
https://juejin.cn/post/7026900352968425486
https://juejin.cn/post/7249386837369159735?from=search-suggest
27.keep-alive有了解吗?
keep-alive作为一种vue的内置组件,主要作用是缓存组件状态。当需要组件的切换时,不用重新渲染组件,避免多次渲染,就可以使用keep-alive包裹组件。
参考文章:https://juejin.cn/post/7091490734041219086
28.协商缓存,强缓存有了解吗?
- 强缓存:浏览器不会像服务器发送任何请求,直接从本地缓存中读取文件并返回Status Code: 200 OK
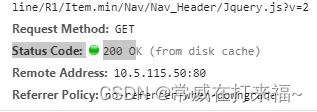
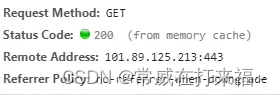
200 form memory cache : 不访问服务器,一般已经加载过该资源且缓存在了内存当中,直接从内存中读取缓存。浏览器关闭后,数据将不存在(资源被释放掉了),再次打开相同的页面时,不会出现from memory cache。
200 from disk cache: 不访问服务器,已经在之前的某个时间加载过该资源,直接从硬盘中读取缓存,关闭浏览器后,数据依然存在,此资源不会随着该页面的关闭而释放掉下次打开仍然会是from disk cache。
优先访问memory cache,其次是disk cache,最后是请求网络资源
- 协商缓存: 向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;

参考文章:https://juejin.cn/post/6844903838768431118
29. DNS域名解析是在哪一步操作?
- 浏览器先检查自身缓存中有没有被解析过的这个域名对应的IP地址,如果有解析结束,同时域名被缓存的时间也可通过TTL属性来设置。
- 如果浏览器缓存中没有命中(没有),浏览器会检查操作系统缓存中有没有对应的已解析的结果。而操作系统也有一个域名解析的过程,在windows中可通过C盘里面一个叫做hosts的文件来设置,如果你在这里指定一个域名对应的IP地址,那浏览器会首先使用这个IP地址。但是这种操作系统级别的域名解析过程也被很多黑客利用,通过修改你的hosts文件里的内容吧特定的域名解析到他指定的IP地址还是那个,造成所有的域名劫持。所以在window7中将hosts文件设置成了readonly,防止恶意篡改
- 如果还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析和这个域名,这个服务器一般在你的城市的某个角落,距离不是很远,而且这台服务器的性能很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。浏览器(主机)向其本地域名服务器进行的是递归查询。
- 本地域名服务器采用迭代查询,它先向下一个根域名服务器查询
- 根域名服务器如果有查询的IP的值则返回,没有命中,则告诉本地域名服务器,下一次查询的顶级域名服务器的IP的值
- 本地域名服务器向收到的顶级域名服务器进行查询
- 顶级域名服务器如果有查询的IP地址则返回,没有命中,则告诉本地域名服务,下一次查询的权限域名服务器的IP的地址
- 本地域名服务器向权限域名服务器进行查询
- 权限域名服务器告诉本地域名服务器,所查询的IP地址
- 本地域名服务器最后把查询的结果告诉浏览器(主机)。
原文链接:https://blog.youkuaiyun.com/qq_37288477/article/details/86582130
30. script上的defer, async有什么区别?
- 二者都是异步去加载外部JS文件
- async是在外部JS加载完成后,浏览器空闲时,Load事件触发前执行;而Defer是在JS加载完成后,整个文档解析完成后执行。
- defer更像是将script标签放在body之后的效果,但是它由于是异步加载JS文件,所以可以节省时间。
参考文章: https://zhuanlan.zhihu.com/p/30898865
31.低代码有了解吗?
参考文章:https://zhuanlan.zhihu.com/p/559966882
32.浏览器渲染优化
- (1)针对javascript:javascript会阻塞HTML的解析,也会阻塞css的解析。因此我们可以对javascript的加载方式进行改变来进行优化:
1. 尽量将javascript文件放在body的最后
2. body中间尽量不要写<script>标签
3. <script>标签的引入资源方式有三种,一种就是我们常用的直接引入,还有两种就是使用async属性和defer属性来异步引入,
两者都是去异步加载外部的js文件,不会阻塞dom的解析(尽量使用异步加载),三者的区别如下:
*script立即停止页面渲染去加载资源文件,当资源加载完毕后立即执行js代码,js代码执行完毕后继续渲染页面;
*async是在下载完成之后,立即异步加载,加载好后立即执行,多个带async属性的标签,不能保证加载的顺序;
*defer是在下载完成后,立即异步加载。加载好后,如果dom树还没构建好,则先等dom树解析好再执行;如果dom树已经准备好,
则立即执行。多个带defer属性的标签,按照顺序执行。
- (2)针对css:使用css有三种方式:使用link,@import,内联样式,其中link和@import都是导入外部样式。它们之间的区别:
*link: 浏览器会派发一个新等线程(http线程)去加载资源文件,于此同时GUI渲染线程会继续向下渲染代码
*@import: GUI渲染线程会暂时停止渲染,去服务器加载资源文件,资源文件没有返回之前不会继续渲染(阻碍浏览器渲染)
*style: GUI直接渲染
外部样式如果长时间没有加载完毕,浏览器为了用户体验,会使用浏览器的默认样式,确保首次渲染的速度。所有css一般写在heard中,让浏览器尽快发送请求去获取css样式。所以,再开发过程中,导入外部样式使用link,而不用@import。如果css少,尽可能采用内嵌样式,直接写在style标签中。
- (3)针对DOM树,CSSOM树:可以通过以下几种方式来减少渲染的时间:
*HTML文件的代码层级尽量不要太深
*使用语义化的标签,来避免不标准语义化的特殊处理
*减少CSS代码的层级,因为选择器是从左向右进行解析的
- (4)减少回流与重绘
*操作DOM树时,尽量在低代码层级的DOM节点进行操作
*不要使用table布局,一个小的改动可能会使整个table进行重新布局
*使用css的表达式
*不要频繁操作元素的样式,对于静态页面,可以修改类名,而不是样式
*使用absolute或者fixed,使元素脱离文档流,这样他们发生变化就不会影响其他元素
*避免频繁操作DOM,可以创建一个文档片段docmentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中
*将元素先设置display:none,操作结束后再把它显示出来。因为display属性为none的元素上进行的DOM操作不会引发回流和重绘。
*将DOM的多个读操作(或者写操作)放在一起,而不是读写操作穿插着写。这得益于浏览器的渲染队列机智
浏览器针对页面的回流与重绘,进行了自身的优化-----渲染队列
浏览器会将所有的回流,重绘的操作放在一个队列中,当队列中的操作到了一定的数量或者到了一定的时间间隔,浏览器就会对队列进行批处理。这样就会让多次的回流,重绘变成一次回流重绘。
将多个读操作(或写操作)放在一起,就会等所有的读操作进入队列之后执行,这样,原本应该是触发多次回流,变成了只触发一次回流。

















 7250
7250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









