




 交叉验证是评估机器学习模型的重要手段,包括LOOCV(Leave-One-Out)、K折验证和分层K折验证。LOOCV对每个实例进行单独验证,但计算量大;K折验证通过划分多份验证集平衡训练和验证,而分层K折保持类别比例。时间序列交叉验证适用于时间序列数据,避免了时间顺序带来的影响。
交叉验证是评估机器学习模型的重要手段,包括LOOCV(Leave-One-Out)、K折验证和分层K折验证。LOOCV对每个实例进行单独验证,但计算量大;K折验证通过划分多份验证集平衡训练和验证,而分层K折保持类别比例。时间序列交叉验证适用于时间序列数据,避免了时间顺序带来的影响。
在机器学习的监督学习中,通常我们会有一个数据集A,但是在我们训练模型的时候,不可能把数据集A全部拿来训练模型,因为,如果这样做了,我们就没有办法验证和评估我们模型的表现。
要想解决这个问题,我们就需要从我们的数据集A中,取出一部分,来验证我们模型在没有见过的数据集上的表现。那么就有一个问题,我们该从这个数据集A中取出来多少数据做验证呢?因为我们知道,在机器学习领域,影响模型表现的三要素:算法,算力,数据。
在算法和算力相同的大前提下,当然是数据量越多越好,然而现在我们又必须取出一部分数据来验证我们的模型,这个问题就比较难了。
1. LOOCV
因此,就有人提出了LOOCV。即(leave-one-out cross-validation)。在这里,LOOCV将数据集拆分为训练集(Train)和验证集(Validation)。但是值得注意的是,在LOOCV里面,只在数据集A中拿出来了一条数据(one instance)作为Validation。如果我们的数据集A中有n条instance,那么用LOOCV划分后,我们的Train中有n-1条instance,Validation中只有1条instance。
总结LOOCV的优缺点:
优点:
- 不受测试集和验证集划分方法的影响,因为每一个数据都单独做过测试集
- 其用了n-1条instance训练模型,也机会用到了所有的数据,保证了模型的bias更小
缺点: - 计算量过大
2. K者交叉验证
因为LOOCV存在的问题,所以有人提出了K折交叉验证。K折交叉验证和LOOCV的不相同的地方在于:
4. K折交叉验证划分的验证集不是只有一条instance,而是有多条,具体大小,由K值决定。一般来说,k值越大,训练集条数越多。
如果,我们将K取为10,那么我们利用10折交叉验证的步骤就是:
5. 将数据集A分成10份
6. 不重复采样,每次抽取其中一份做验证集,其余9分做训练集,之后计算该模型在测试集上的MAE
7. 将10次的MSE取平均后得到最后的MSE
其实,也可以将LOOCV理解成为一种特殊的K-fold Cross Validation。
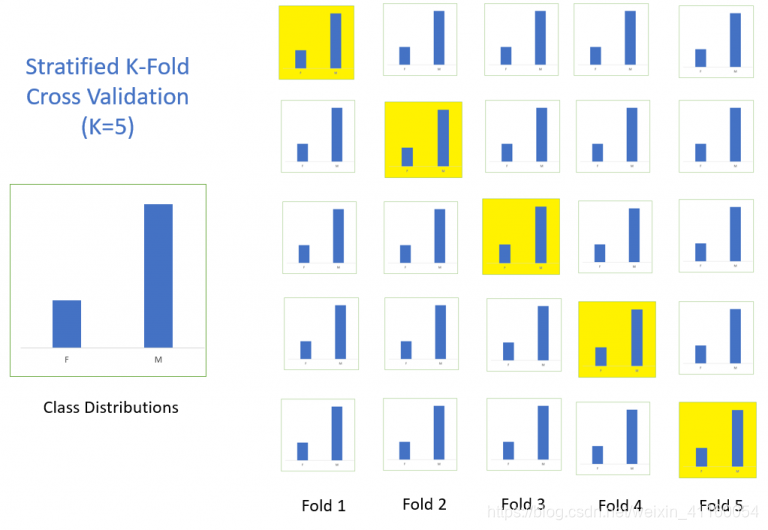
3. 分层K折交叉验证(Stratified k-fold cross validation)
Stratification,重新划分数据集,但是确保新的数据集和原始数据集中样本的分布是一致的。
比如,在二分类问题中,如果原始数据集中正负样本各占一半。那么,在我们划分数据的时候,我们应该确保每次划分的数据集中正负样本各占一半。
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









