







 小熙整理分享以前写的Streams操作代码。先介绍了Stream的概念和分类,接着给出多个实例代码,包括过滤转集合、流生成数据、查找判断、集合转换等操作,还提及流的二次利用、集合排序等内容,最后对部分案例进行改进。
小熙整理分享以前写的Streams操作代码。先介绍了Stream的概念和分类,接着给出多个实例代码,包括过滤转集合、流生成数据、查找判断、集合转换等操作,还提及流的二次利用、集合排序等内容,最后对部分案例进行改进。
小熙最近翻出了以前写的Streams操作代码,感觉功能很强大,所以整理分享下。
一. 介绍:
Stream是什么:
- Stream是一个来自数据源的元素队列并可以进行聚合操作。
- 数据源:流的来源。 可以是集合,数组,I/O channel, 产生器generator 等
- 聚合操作:类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等
Stream的两种分类:
- Stream() 串行化流:串行化执行操作
- parallelStream() 并行化流:流并行处理程序的代替方法,虽然会提高效率,但是高并发时不安全
二. 实例代码:
-
简单的过滤转集合操作(filter、collect):
(1)代码:List<String> list = Arrays.asList("小熙", "小歌", "小熠"); //filter将流中数据按指定规则过滤(借助lambda抒写),collect转集合操作 List<String> filterList = list.stream().filter(l -> !l.equals("小熠")).collect(Collectors.toList()); System.out.println("filterList: "+filterList);(2)结果:
filterList: [小熙, 小歌] -
简单的使用流生成数据并使用map操作每个数据(of、map):
(1)代码:// 使用流的of方法向流中添加object,map在stream流中可以用来遍历每个元素并进行操作 List<String> mapList = Stream.of("小熙", "小歌", "小熠").filter(l -> !l.equals("小熠")).map(i -> i += " 遍历后加上的。").collect(Collectors.toList()); // 方法引用打印结果,java8的新特性之一 mapList.forEach(System.out::println);(2)结果:
小熙 遍历后加上的。 小歌 遍历后加上的。(3)of可以添加多个Object,如图看下源码:

-
简单的使用查找和条件判断语句(findAny()、findFirst()、orElse):
(1)代码:// 过滤后找到符合条件的第一个就返回,如果没有就返回null String s = Stream.of("小熙", "小歌", "小熠").filter(l -> !l.equals("小熠")).findFirst().orElse(null); System.out.println("s: "+s); // 过滤后找到符合条件的第一个就返回,如果没有就返回null String s1 = Stream.of("小熙", "小歌", "小熠").filter(l -> l.equals("没有")).findFirst().orElse(null); System.out.println("s1: "+s1); // 过滤后只要找到符合条件的就返回,没有就返回自定义的数据 String s2 = Stream.of("小熙", "小歌", "小熠").filter(l -> l.equals("没有")).findAny().orElse("没找到,自己定义的"); System.out.println("s2: "+s2);(2)结果:
s: 小熙 s1: null s2: 没找到,自己定义的 -
简单的将list结合转换为map集合(Collectors的groupingBy、counting方法):
(1)代码:// 将list集合的数据生成key,次数为value生成map集合 List<String> list = Arrays.asList("软件工程师", "建筑工程师", "教育老师", "教育老师", "厨师", "律师", "律师", "厨师", "软件工程师", "软件工程师", "软件工程师", "软件工程师", "实在编不下去了"); // 在转集合中,使用Collectors工具类的groupingBy分组生成双链,Function的identity是输入和输出值一致,counting是求和引用了Long的sum方法 Map<String, Long> stringLongMap = list.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting())); // stringLongMap.forEach((h1,h2) -> System.out.println(h1+" : "+h2)); System.out.println("stringLongMap "+stringLongMap);(2)结果:
stringLongMap {实在编不下去了=1, 教育老师=2, 律师=2, 建筑工程师=1, 厨师=2, 软件工程师=5}(3)identity和counting,为验证上述个人描述,请看下图源码:
identity:

counting:
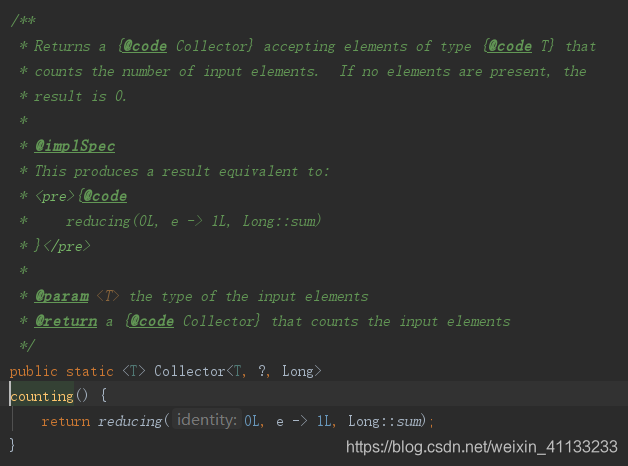
-
将例4的结果按照值排序打印(sorted、forEachOrdered、comparingByValue、reversed):
(1)代码:// 将hashMap按value的次数排序输出 LinkedHashMap<String, Long> stringLongLinkedHashMap = new LinkedHashMap<>(); // 这里小熙使用的是比较器比较,下面的案例使用的是Map中封装的方法 // map集合是双列的,而streams只能操作单列的,所以使用entrySet之后形成键值对单列,之后通过流进行排序(规则采用比较器),使用foreach遍历或加入集合。 stringLongMap.entrySet().stream().sorted((h1,h2) -> h2.getValue().compareTo(h1.getValue())).forEach(h -> System.out.println(h.getKey()+" : "+h.getValue())); // forEachOrdered比forEach多了按序列输出,在多线程高并发时更安全 stringLongMap.entrySet().stream().sorted((h1,h2) -> h1.getValue().compareTo(h2.getValue())).forEachOrdered(h -> stringLongLinkedHashMap.put(h.getKey(),h.getValue())); LinkedHashMap<String, Long> anLiMap = new LinkedHashMap<>(); // 案例,map中封装的排序方法,其中的.reversed()是倒序过来,默认是降序 stringLongMap.entrySet().stream().sorted(Map.Entry.<String,Long>comparingByValue().reversed()).forEachOrdered(h -> anLiMap.put(h.getKey(),h.getValue())); System.out.println("anLiMap: "+anLiMap); System.out.println("stringLongLinkedHashMap: "+stringLongLinkedHashMap);(2)结果:
软件工程师 : 5 教育老师 : 2 律师 : 2 厨师 : 2 实在编不下去了 : 1 建筑工程师 : 1 anLiMap: {软件工程师=5, 教育老师=2, 律师=2, 厨师=2, 实在编不下去了=1, 建筑工程师=1} stringLongLinkedHashMap: {实在编不下去了=1, 建筑工程师=1, 教育老师=2, 律师=2, 厨师=2, 软件工程师=5} -
将对象单链集合转为map集合 (summingInt、summarizingInt)
(1)准备user对象类:class User{ private String name; private Integer age; private Character sex; public User(String name, Integer age, Character sex) { this.name = name; this.age = age; this.sex = sex; } public User() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public Character getSex() { return sex; } public void setSex(Character sex) { this.sex = sex; } @Override public String toString() { return "User{" + "name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}'; } }(2)代码:
List<User> userList = Arrays.asList(new User("小明", 20, '男'), new User("小红", 21, '女'), new User("小熙", 19, '男'), new User("小明", 20, '男'), new User("小红", 21, '女'), new User("小歌", 19, '女'), new User("小明", 20, '男')); // 根据姓名分组为key,个数为value生成map集合 Map<String, Long> collectNameCount = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.counting())); System.out.println("collectNameCount: "+collectNameCount); // 根据姓名分组为key,年龄相加为value生产map集合,summarizingInt是求其他可求的一切和(分类数组)等(比如:{小熙=IntSummaryStatistics{count=1, sum=19, min=19, average=19.000000, max=19}),而summingInt只是求当前引用的和 Map<String, Integer> collectNameAge = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.summingInt(User::getAge))); // Map<String, IntSummaryStatistics> collectNameAge = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.summarizingInt(User::getAge))); // 其他条件的获取是直接根据值的get方法 // System.out.println("collectNameAge: "+collectNameAge.get("小熙").getAverage()); // System.out.println("collectNameAge: "+collectNameAge.get("小熙").getCount()); System.out.println("collectNameAge: "+collectNameAge);(3)结果:
collectNameCount: {小熙=1, 小明=3, 小歌=1, 小红=2} collectNameAge: {小熙=19, 小明=60, 小歌=19, 小红=42} -
案例6的默认分组和较难的将value改为属性的set集合(mapping)
(1)代码:// 分组时只写一个条件他的value就是对应的对象(默认分组) Map<String, List<User>> collect = userList.stream().collect(Collectors.groupingBy(User::getName)); System.out.println("collect: "+collect); // 使用mapping将value结果List<User>转为Set<String> Map<String, Set<Character>> stringSetMap = userList.stream().collect(Collectors.groupingBy(User::getName, Collectors.mapping(User::getSex, Collectors.toSet()))); System.out.println("stringSetMap: "+stringSetMap);(2)结果:
collect: {小熙=[User{name='小熙', age=19, sex=男}], 小明=[User{name='小明', age=20, sex=男}, User{name='小明', age=20, sex=男}, User{name='小明', age=20, sex=男}], 小歌=[User{name='小歌', age=19, sex=女}], 小红=[User{name='小红', age=21, sex=女}, User{name='小红', age=21, sex=女}]} stringSetMap: {小熙=[男], 小明=[男], 小歌=[女], 小红=[女]} -
流的二次利用问题(Supplier)
(1)不使用新特性的代码:Set<String> collect = StreamTest.getStringStream().collect(Collectors.toSet()); System.out.println(collect); List<String> stringList = StreamTest.getStringStream().filter(s -> s != null).collect(Collectors.toList()); System.out.println(stringList); /** * 自己创建streams,of是将数据放入到流中。 * 注意代码是从上往下输出,所以流被使用转换后就是关流了,之后再使用是会报错的(使用forEach之后流就被关闭了,而不像map返回值是流还可以使用) * @return */ private static Stream<String> getStringStream(){ return Stream.of("香蕉", "苹果", null, "葡萄", "香蕉"); }结果:
[null, 香蕉, 苹果, 葡萄] [香蕉, 苹果, 葡萄, 香蕉](2)使用新特性返回新的流的代码:
// 可以使用Supplier封装流,由方法返回,每次使用get()方法是获取新的流,不用担心流被关闭,再次使用报错的问题 Supplier<Stream<String>> stringStream =() -> Stream.of("香蕉", "苹果", null, "葡萄", "香蕉"); stringStream.get().forEach(System.out::print); System.out.println(); // stringStream.get()第二次获取这个流 List<String> collect1 = stringStream.get().distinct().filter(f -> f != null).collect(Collectors.toList()); System.out.println(collect1);结果:
香蕉苹果null葡萄香蕉 [香蕉, 苹果, 葡萄] -
HashMap集合使用流按value排序,返回LinkedHashMap(toMap、LinkedHashMap::new)
(1)代码:HashMap<String, Integer> stringIntegerHashMap = new HashMap<>(); stringIntegerHashMap.put("第一个",1); stringIntegerHashMap.put("第三个",3); stringIntegerHashMap.put("第二个",2); // 这个是使用map封装的方法,stream操作的都是单列的,所以使用entrySet转为set进行操作 // LinkedHashMap<String, Integer> linkedHashMap = stringIntegerHashMap.entrySet().stream().sorted(Map.Entry.<String,Integer>comparingByValue().reversed()).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (m1, m2) -> m1, LinkedHashMap::new)); LinkedHashMap<String, Integer> linkedHashMap = stringIntegerHashMap.entrySet().stream().sorted((m1,m2) -> m2.getValue().compareTo(m1.getValue())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> newValue, LinkedHashMap::new)); System.out.println("stringIntegerHashMap: "+stringIntegerHashMap); System.out.println("linkedHashMap: "+linkedHashMap);(2)结果:
stringIntegerHashMap: {第二个=2, 第三个=3, 第一个=1} linkedHashMap: {第三个=3, 第二个=2, 第一个=1} -
将list集合转化为Map<Object,List>类型(object是唯一的区分,为bean时需要重写hashCode和equal)
(1)代码:Student student1 = new Student().setId(1).setAge("12").setName("xiao"); Student student2 = new Student().setId(2).setAge("14").setName("xi"); Student student3 = new Student().setId(3).setAge("12").setName("ge"); List<Student> list = new ArrayList<>(); list.add(student1); list.add(student2); list.add(student3); Map<String, List<Student>> collect = list.stream().collect(Collectors.toMap(Student::getAge, p -> com.google.common.collect.Lists.newArrayList(p), (List<Student> value1, List<Student> value2) -> { value1.addAll(value2); return value1; })); System.out.print(collect);(2)结果
{12=[Student(id=1, name=xiao, age=12, stringList=null), Student(id=3, name=ge, age=12, stringList=null)], 14=[Student(id=2, name=xi, age=14, stringList=null)]} -
使用新特性把map集合的排序放到方法里(predicate、test)
(1)代码:HashMap<Integer, String> stringIntegerHashMap2 = new HashMap<>(); stringIntegerHashMap2.put(1, "第一个"); stringIntegerHashMap2.put(3, "第三个"); stringIntegerHashMap2.put(2, "第二个"); stringIntegerHashMap2.put(5, "第五个"); stringIntegerHashMap2.put(7, "第七个"); System.out.println(orderByMapValue(stringIntegerHashMap2, x -> !x.contains("第一个"))); // System.out.println(orderByMapValue(stringIntegerHashMap2, x -> ! x.isEmpty())); /** * java8新增了predicate对于集合的操作,这里的Map是接收操作集合,Predicate是接收抒写的规则(一般由lambda表达式表示) * 使用predicate的test判断map集合中的值是否符合predicate抒写接收的集合,不符合则去掉 * @param map * @param predicate * @param <K> * @param <V> * @return */ private static <K, V> Map<K, V> orderByMapValue(Map<K, V> map, Predicate<V> predicate){ return map.entrySet().stream().filter(x -> predicate.test(x.getValue())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); }结果:
{2=第二个, 3=第三个, 5=第五个, 7=第七个} -
简单的合并操作的例子(flatMap、distinct)
(1)代码:// map返回的是结果集。flatMap对于过滤之后的流的返回值必须是List,flatMap = map + flatten ;:这个过程就像是先 map, 然后再将 map 出来的这些列表首尾相接 (flatten). List<Character> collect2 = Stream.of("Hello", "World").map(x -> x.chars().mapToObj(m -> (char)m).toArray(Character[]::new)).flatMap(Arrays::stream).distinct().collect(Collectors.toList());(2)结果:
[H, e, l, o, W, r, d] -
一些简单的操作(ints、limit、count、asDoubleStream),还有些其他就不一一列举了可以自己试试。
(1)代码:Random random = new Random(); // ints()将整数转为整数流,limit(10)用于获取指定数量的流(这里指定的是10),forEach遍历循环,System.out::println是方法引用,打印出每个输出结果 random.ints().filter(i -> i > 0).limit(10).forEach(System.out::println); System.out.println("-------------------------------------------------------------"); //sorted不加规则是对数字的默认排序升序 random.ints().limit(10).sorted().forEach(System.out::println); // asDoubleStream是转为小数流 System.out.println("小数流:"+random.ints().asDoubleStream().toString()); List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl"); // 获取空字符串的数量,首先将集合类转为流对象,接着调用过滤方法,使用lambda表达式实现过滤操作,最后调用count方法记过滤总数。 long count = strings.stream().filter(string -> string.isEmpty()).count();(2)结果:
1831460325 1546385841 239482659 1499769037 1528085245 2008714968 1479666337 757999235 633410750 1577005330 ------------------------------------------------------------- -1726358906 -908906473 -607832126 -431525710 208558632 270290119 480869356 689261800 1075369668 1610424647 小数流:java.util.stream.IntPipeline$2@1603dc2f 空字符的数量:2 -
看了以上的介绍,小熙自己改进下案例11的操作,有兴趣的可以自己尝试写下
(1)简单的改进:将字符串list集合改成双列 map<Character, Long>,字母为key,次数为value,按次数大到小排序(2)代码:
Map<Character, Long> collect2 = Stream.of("Hello", "World").map(x -> x.chars().mapToObj(m -> (char)m).toArray(Character[]::new)).flatMap(Arrays::stream).collect(Collectors.groupingBy(Function.identity(),Collectors.counting())); collect2 = collect2.entrySet().stream().sorted((x,y) -> y.getValue().compareTo(x.getValue())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new)); System.out.println(collect2);(3)结果:
{l=3, o=2, r=1, d=1, e=1, W=1, H=1}
这一篇,总结了不少小熙最近整合的Streams的操作,当然也有摸索不对之处,欢迎联系指正,如果感兴趣可以自行搜索下这一特性。
这一篇写的较长,Reduce放在下一篇介绍,有兴趣可以看看。

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









