










(public)mask-rcnn学习笔记 (网络结构理解-数据集制作-源码调试 )
(网络结构理解-数据集制作-源码调试
))
一、网络结构理解
Mask-RCNN[24]是由 He K 在 2018 年提出的,其在改进后的 Faster-RCNN[23]中增加了 Mask
Branch,即融合了经典的语义分割算法 Fully Convolutional Networks (FCN)
[26],实现了在一个网络中同时做目标检测和实例分割的功能。
在对 Faster- RCNN[23]的改进中,Mask-RCNN[24]将原有的 ROI Pooling 步骤替换成了 RoI
Align, 具体而言是将对 RPN ROIs 的两次量化操作(由图像坐标计算 feature map 坐标、由 feature map
坐标计算 ROI feature 坐标)替换成双线性插值,意在解决量化操作中像素取整带来的像素位置偏差,进而实现更加精确得确定目标轮廓。
除此之外,在 feature map 的获取上,与 Faster-RCNN[23]不同的是,Mask-RCNN[24]采用Feature
Pyramid Networks(FPN)[29]与 Residual Network(ResNet)[30]相结合的思路,生成多尺度
feature
map。FPN[29]的使用使得网络在特征语义信息比较少但是目标位置准确的低层特征,和特征语义信息比较丰富但是目标位置比较粗略的高层特征上都进行了预测,保证了针对多尺度目标识别与分割任务的有效实现。
而ResNet[17-30]通过建立输出 y 与输入 x 的差(即 y-x)与输入 x
的关系,并增加一个恒等映射,跳过本层或多层运算,同时在后向传播过程中,下一层网络梯度直接传递给上一层,来解决深层网络梯度消失的问题(网络深度增加到一定程度,后向传播时无法把梯度反馈到前面网络层,前面网络参数无法更新,导致训练变差)。
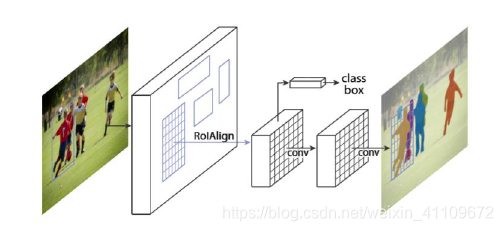
在 Mask-RCNN[24]中,对于一副任意大小的图像,输入网络后,首先通过参数设定对图片进行有选择得裁剪和填充,其次经过深度残差网络得到
5 个尺度的feature map。随后同 Faster-RCNN[23]中的 RPN 的操作一致,在 feature map 的基础上得到
RPN RoIs,经过 RoI Align
后,网络分为两个分支,两个分支均为FCN[24],其中的一个分支得到类别判定及位置回归;另一个分支用以实现 mask
部分的目标分割。网络的具体结构如图所示。
整个网络的 loss 采用三部分 loss 之和,即 :
L=L_class+L_boxes+L_mask[24]
L_class 与 L_boxes 的计算与 Faster-RCNN[23]中一致,L_mask 采用sigmoid 计算。
二、数据集制作
1、labelme/VIA(VGG Image Annotator)
- 当制作自己的数据集的时候,图片的大小一定要记得修改,长宽都要修改为修改为2的6次方的倍数,不然训练的时候会报错,来看源代码:

- 点选目标轮廓即可
(无需再标定 bounding box:这里我们不使用数据集本身提供的bbox坐标数据,取而代之的是通过mask计算出bbox,这样可以在不同的数据集下对bbox使用相同的处理方法) - 同一张影像存在多个同类对象时,需用序号加以区分 xxx_1 xxx_2 or xxx1 xxx2
- 类别名不应具有包含关系以及含有阿拉伯数字 eg: window windowblack…
- 文件夹构造:
pic:原图像
json:labelme标定生成的标记文件
labelme_json :将原始json标记数据转换成对应文件夹后的存储位置 cv2_mask: 将16bit图像转换为8bit图像,便于opencv读取
(ps:若你生成的label.png文件是彩色的他就是默认的八位的编码的了!主要是labelme 版本升级了,截止到我写博文(2019.02)为止 labelme 已经升级,升级后的版本 生成的 label.png文件就已经是 八位编码的!!!!也就是说,我们不需要在进行复杂的编码转换!)
对应的文件组织格式如下:


5. 将批量json文件转为对应文件夹:
#step1 cmd切换到labelme_json_to_dataset.exe所在文件夹
cd E:\install\Anaconda3\envs\common\Scripts
#step2 批量操作,将.json文件转换为对应文件夹
for /r D:\xxx\mask-rcnn\Mask_RCNN-master\train_data2\json %i in (*.json) do labelme_json_to_dataset %i
# D:\xxx\mask-rcnn\Mask_RCNN-master\train_data2\json为.json文件所在文件夹
#step3将生成的文件夹
#(D:\xxx\mask-rcnn\Mask_RCNN-master\train_data2\json下)
#剪切到labelme_json文件夹下
#(D:\xxx\mask-rcnn\Mask_RCNN-master\train_data2\lableme_json)
- 将16bit图像转换为8bit图像,便于opencv读取
def img_16to8(src_dir,dest_dir):
from PIL import Image
import numpy as np
import shutil
import os
for child_dir in os.listdir(src_dir):
new_name = child_dir.split('_')[0] + '.png'
old_mask = os.path.join(os.path.join(src_dir, child_dir), 'label.png')
img = Image.open(old_mask)
img = Image.fromarray(np.uint8(np.array(img)))
new_mask = os.path.join(dest_dir, new_name)
img.save(new_mask)
if __name__ == '__main__':
src_dir = r'D:\xxx\mask-rcnn\train_data\labelme_json'
dest_dir = r'D:\xxx\mask-rcnn\train_data\cv3_mask'
img_16to8(src_dir,dest_dir)
三、源码调试
1、网络训练
(1)、训练源码
(根据train_shapes.ipynb文件进行更改,链接1、链接2)
- 设置GPU使用配置
# 指定第一块GPU可用
os.environ["CUDA_VISIBLE_DEVICES"] = "0" #指定GPU的第二种方法
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC' #A "Best-fit with coalescing" algorithm, simplified from a version of dlmalloc.
config.gpu_options.per_process_gpu_memory_fraction = 0.88#定量
#config.gpu_options.allow_growth = True #按需
set_session(tf.Session(config=config))
# In[3]:
#check whether or not use GPU
import tensorflow as tf
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
#查看keras认得到的GPU
from keras import backend as K
K.tensorflow_backend._get_available_gpus()
- 设置类别数
#TODO
NUM_CLASSES = 1 + 2 # background + 3 shapes
- 根据实验数据设置图片尺寸
#todo
# IMAGE_MIN_DIM = 320
# IMAGE_MAX_DIM = 384
IMAGE_MIN_DIM = 1024
IMAGE_MAX_DIM = 1024
- 添加类别id:注意,虽然在同一张影像中出现同类对象时采用数字标签用以区分,但不改变类别id,即xxx_1\xxx_2都属于同一个id:xxx
#todo
self.add_class("shapes", 1, "lampone") # 黑色素瘤
self.add_class("shapes", 2, "lamptwo")
#self.add_class("shapes", 3, "white")
- 更改load_mask函数
for i in range(len(labels)):
if labels[i].find("lampone") != -1:
# print "box"
labels_form.append("lampone")
elif labels[i].find("lamptwo")!=-1:
#print "column"
labels_form.append("lamptwo")
# elif labels[i].find("white")!=-1:
# #print "package"
# labels_form.append("white")
- 增加训练过程中的callbacks
(2)、测试
(根据demo.py文件进行修改,参考链接:链接1)
- 更改model路径及名称
model_folder_name ="shapes20200407T1051"
model_name ="mask_rcnn_shapes_0080.h5
- 更改类别数
NUM_CLASSES = 1 + 4 # background + 3 shapes
- 更改图像大小
IMAGE_MIN_DIM = 1024
IMAGE_MAX_DIM = 1024
- 更改配置
STEPS_PER_EPOCH = 400
- 添加类别名称,注意,BG表示背景,不可去除
class_names = ['BG', 'lampone','lamptwo','trafficlightbig','guideboardbig']
- 遍历待预测的图片进行预测并输出结果
- 遍历image文件夹下图片(未标定)
#遍历待预测图片 /home/xxx/xxx/mask-rcnn/Mask_RCNN/image文件夹下
filelist = os.listdir(IMAGE_DIR)
for item in filelist:
srcImg = os.path.join(IMAGE_DIR, item)
image = skimage.io.imread(srcImg)
a=datetime.now()
# Run detection
results = model.detect([image], verbose=1)
b=datetime.now()
# Visualize results
print(item,"\n","cost time:",(b-a).seconds)
r = results[0]
#todo: moderfy the mrcnn/visualize.py display_instances
#save imgs-results
visualize.display_instances(image,item,model_folder_name,model_name,r['rois'], r['masks'], r['class_ids'],class_names, r['scores'])
- 遍历val数据集(已标定)
#遍历val数据影像进行测试
dataset_root_path = os.path.join(ROOT_DIR, "train_data2/")
img_floder = dataset_root_path + "pic"
imglist = os.listdir(img_floder)
count_all = count = len(imglist)
#设置训练数据集与验证集的比例
val_pro=0.1
count_val = round(count_all*val_pro)
count_str = range(count_all - count_val, count_all)
for i in count_str:
srcImg = imglist[i]
srcImg = os.path.join(img_floder, imglist[i])
image = skimage.io.imread(srcImg)
a = datetime.now()
# Run detection
results = model.detect([image], verbose=1)
b = datetime.now()
# Visualize results
print(imglist[i], "\n", "cost time:", (b - a).seconds)
r = results[0]
# todo: moderfy the mrcnn/visualize.py display_instances
# save imgs-results
visualize.display_instances(image,imglist[i],model_folder_name,model_name,r['rois'], r['masks'], r['class_ids'],class_names, r['scores'])
备注 对visualize.display_instances函数进行更改以批量保存预测结果,参考链接:链接
- 添加参数
def display_instances(image,imgname, model_folder_name,model_name,boxes, masks, class_ids, class_names,
scores=None, title="",
figsize=(16, 16), ax=None,
show_mask=True, show_bbox=True,
colors=None, captions=None):
- 更改部分代码
if auto_show:
#todo
#folder_path =os.path.join(model_folder_name,model_name)
plt.savefig(ROOT_DIR+"/test_results/"+imgname)
#plt.show()
(3)、计算mAP
四、其他
1、vim
更改:insert
退出更改:ese
保存更改:wq or :q


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









